







围绕 transformers 构建现代 NLP 开发环境
本文将从“样本处理”,“模型开发”,“实验管理”,“工具链及可视化“ 几个角度介绍基于 tranformers 库做的重新设计,并简单聊聊个人对“软件2.0”的看法。
在 Apache Spark 中利用 HyperLogLog 函数实现高级分析
预聚合是高性能分析中的常用技术,通过预先聚合降低纬度,从而在查询时大幅减少计算量,提升响应速度。本文介绍了 spark-alchemy 这个开源库中的 HyperLogLog 这一个高级功能,并且探讨它是如何解决大数据中数据聚合的问题。
什么是阿里云数加大数据计算服务MaxCompute?
MaxCompute简介 大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
ComputeColStats UDF中 近似算法的介绍
一,前面的话 表和列的统计信息对CBO的结果有着极大地影响,能够高效和准确的收集统计信息是极其重要的。但高效和准确是矛盾的,更准确的统计信息往往需要更多的计算,我们能做的是在高效和准确之间找到更好的平衡。
深度语义模型以及在淘宝搜索中的应用
传统的搜索文本相关性模型,如BM25通常计算Query与Doc文本term匹配程度。由于Query与Doc之间的语义gap, 可能存在很多语义相关,但文本并不匹配的情况。为了解决语义匹配问题,出现很多LSA,LDA等语义模型。
阿里巴巴大数据实践之数据建模
随着DT时代互联网、智能设备及其他信息技术的发展,数据爆发式增长,如何将这些数据进行有序、有结构地分类组织和存储是我们面临的一个挑战。 为什么需要数据建模 如果把数据看作图书馆里的书,我们希望看到它们在书架上分门别类地放置;如果把数据看作城市的建筑,我们希望城市规划布局合理;如果把数据看作电脑文件和文件夹,我们希望按照自己的习惯有很好的文件夹组织方式,而不是糟糕混乱的桌面,经常为找一个文件而不知所措。
基于阿里云 MaxCompute 构建企业云数据仓库CDW的最佳实践建议
通过我们背后的指导思想和我们给出的技术解决方案,希望与大家能够一起探索一些新的基于云上的数据仓库构建的最佳实践,从而尽量避免走弯路。这就是我今天想跟大家分享的内容与目的。
离线数据同步神器:DataX,支持几乎所有异构数据源的离线同步到MaxCompute
概述 DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
浅谈PyODPS
在我看来,PyODPS就是阿里云上的Python。值得注意的是,这里的定语“阿里云上的”一定不能精简掉,因为PyODPS不等于单机版的Python!
maxcompute 2.0复杂数据类型之array
1. 含义 类似于Java中的array。有序、可重复。 2. 场景 什么样的数据,适合使用array类型来存储呢?这里列举了几个我在开发中实际用到的场景。 2.1 标签类的数据 为什么说标签类数据适合使用array类型呢?(1)标签一般是一个只有key、没有value的结构;(2)标签的数量(枚举值个数)会非常多;(3)标签的变化会比较频繁;(4)标签会过期;因此,比起“创建多个字段”、“使用指定分隔符分隔的字符串”、“使用map”等方法,使用array是更合适的。
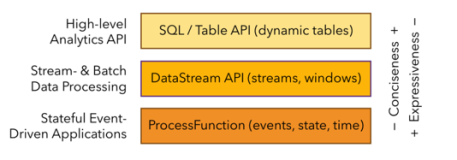
Apache Flink 零基础入门(七):Table API 编程
本文主要包含三部分:第一部分,主要介绍什么是 Table API,从概念角度进行分析,让大家有一个感性的认识;第二部分,从代码的层面介绍怎么使用 Table API;第三部分,介绍 Table API 近期的动态。
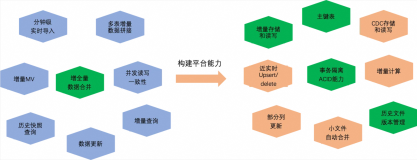
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。

官宣|Apache Paimon 毕业成为顶级项目,数据湖步入实时新篇章!
Apache Paimon 在构建实时数据湖与流批处理技术领域取得了重大突破,数据湖步入实时新篇章!
基于阿里云PAI平台搭建知识库检索增强的大模型对话系统
基于原始的阿里云计算平台产技文档,搭建一套基于大模型检索增强答疑机器人。本方案已在阿里云线上多个场景落地,将覆盖阿里云官方答疑群聊、研发答疑机器人、钉钉技术服务助手等。线上工单拦截率提升10+%,答疑采纳率70+%,显著提升答疑效率。
阿里云 MaxCompute MaxFrame 开启免费邀测,统一 Python 开发生态
阿里云 MaxCompute MaxFrame 正式开启邀测,统一 Python 开发生态,打破大数据及 AI 开发使用边界。
flink cdc 同步问题之报错org.apache.flink.util.SerializedThrowable:如何解决
Flink CDC(Change Data Capture)是一个基于Apache Flink的实时数据变更捕获库,用于实现数据库的实时同步和变更流的处理;在本汇总中,我们组织了关于Flink CDC产品在实践中用户经常提出的问题及其解答,目的是辅助用户更好地理解和应用这一技术,优化实时数据处理流程。

官宣|Apache Flink 1.19 发布公告
Apache Flink PMC(项目管理委员)很高兴地宣布发布 Apache Flink 1.19.0。

官宣|阿里巴巴捐赠的 Flink CDC 项目正式加入 Apache 基金会
本文整理自阿里云开源大数据平台徐榜江 (雪尽),关于阿里巴巴捐赠的 Flink CDC 项目正式加入 Apache 基金会。

Flink CDC 3.0 正式发布,详细解读新一代实时数据集成框架
Flink CDC 于 2023 年 12 月 7 日重磅推出了其全新的 3.0 版本 ~

odps是什么?
ODPS(Open Data Processing Service),原是阿里云从 09年开始自研的大规模批量计算引擎,2016 年更名为MaxCompute。2022云栖大会上,阿里云ODPS全新升级为一体化大数据平台,存储、调度、元数据一体化融合 ,从 Processing 升级为 Platform,即 Open Data Platform and Service。提供了离线计算、实时交互式分析、机器学习等可扩展的智能计算引擎,满足用户多元化数据计算需求。

阿里云实时计算Flink的产品化思考与实践【下】
本文整理自阿里云高级产品专家黄鹏程和阿里云技术专家陈婧敏在 FFA 2023 平台建设专场中的分享。

基于OceanBase+Flink CDC,云粒智慧实时数仓演进之路
本文讲述了其数据中台在传统数仓技术框架下做的一系列努力后,跨进 FlinkCDC 结合 OceanBase 的实时数仓演进过程。

活动预告?|?5月16日?Streaming?Lakehouse?Meetup?·?Online?与你相约!
5月16日?Streaming?Lakehouse?Meetup?·?Online?与你相约!
MaxCompute( 原名ODPS)大数据容灾方案与实现(及项目落地实例)专有云
一,背景与概述? ? 复杂系统的灾难恢复是个难题,具有海量数据及复杂业务场景的大数据容灾是个大难题。? ? MaxCompute是集团内重要数据平台,是自主研发的大数据解决方案,其规模和稳定性在业界都是领先的。

Python与NoSQL数据库(MongoDB、Redis等)面试问答
【4月更文挑战第16天】本文探讨了Python与NoSQL数据库(如MongoDB、Redis)在面试中的常见问题,包括连接与操作数据库、错误处理、高级特性和缓存策略。重点介绍了使用`pymongo`和`redis`库进行CRUD操作、异常捕获以及数据一致性管理。通过理解这些问题、易错点及避免策略,并结合代码示例,开发者能在面试中展现其技术实力和实践经验。
Flink CDC产品常见问题之读分布式mysql报连接超时如何解决
Flink CDC(Change Data Capture)是一个基于Apache Flink的实时数据变更捕获库,用于实现数据库的实时同步和变更流的处理;在本汇总中,我们组织了关于Flink CDC产品在实践中用户经常提出的问题及其解答,目的是辅助用户更好地理解和应用这一技术,优化实时数据处理流程。
一键生成视频,用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。
CVPR 2023 | 主干网络FasterNet 核心解读 代码分析
本文分享来自CVPR 2023的论文,提出了一种快速的主干网络,名为FasterNet。核心算子是PConv,partial convolution,部分卷积,通过减少冗余计算和内存访问来更有效地提取空间特征。
【教程】5分钟在PAI算法市场发布自定义算法
概述 在人工智能领域存在这样的现象,很多用户有人工智能的需求,但是没有相关的技术能力。另外有一些人工智能专家空有一身武艺,但是找不到需求方。这意味着在需求和技术之间需要一种连接作为纽带。 今天PAI正式对外发布了“AI市场”以及“PAI自定义算法”两大功能,可以帮助用户5分钟将线下的spark算法或是pyspark算法发布成算法组件,并且支持组件发布到AI市场供更多用户使用。
人工智能平台PAI产品使用合集之如何通过通用文本标记解决方案文档与PAI机器学习平台一起使用
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
人工智能平台PAI产品使用合集之机器学习PAI EasyRec训练时,怎么去除没有意义的辅助任务的模型,用于部署
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
AIGC创作活动 | 跟着UP主秋葉一起部署AI视频生成应用!
本次AI创作活动由 B 站知名 AI Up 主“秋葉aaaki”带您学习在阿里云 模型在线服务(PAI-EAS)中零代码、一键部署基于ComfyUI和Stable Video Diffusion模型的AI视频生成Web应用,快速实现文本生成视频的AI生成解决方案,帮助您完成社交平台短视频内容生成、动画制作等任务。制作上传专属GIF视频,即有机会赢取乐歌M2S台式升降桌、天猫精灵、定制保温杯等好礼!

数据中台的智能进化—阿里巴巴十二年数据平台发展历程
从2016年诞生起,“中台”概念就一路火热至今,对互联网与金融行业数字化转型产生了极为深远的影响。 作为“中台”概念的提出者和先行者,阿里巴巴用12年的实践探索了中台能力建设和数据应用。在不断升级和重构的过程中,阿里巴巴的中台建设经历了从分散的数据分析到数据中台化能力整合,再到全局数据智能化的时代。
实践!如何用阿里云的机器学习得出泰坦尼克号沉船事件中谁有更大的概率获救
阿里云机器学习平台该平台沉淀了阿里巴巴的机器学习算法体系和经验,从数据的预处理、到机器学习算法、模型的评估和预测动能。

什么是HTTP代理?HTTP代理的作用?HTTP代理怎么设置?
HTTP代理是一种充当客户端和服务器之间的中间人的服务器。当客户端发起请求时,HTTP代理会拦截请求并将其转发给目标服务器。一旦目标服务器响应,HTTP代理会拦截响应并将其转发回客户端。HTTP代理可以被用于多种场景,例如加强安全、缓存内容以加速访问、访问受限资源等等。在这篇文章中,我们将会讨论HTTP代理的作用、类型以及如何设置它。

Flink DataStream API 批处理能力演进之路
本文由阿里云 Flink 团队郭伟杰老师撰写,旨在向 Flink Batch 社区用户介绍 Flink DataStream API 批处理能力的演进之路。

【最佳实践】esrally:Elasticsearch 官方压测工具及运用详解
由于 Elasticsearch(后文简称 es) 的简单易用及其在大数据处理方面的良好性能,越来越多的公司选用 es 作为自己的业务解决方案。然而在引入新的解决方案前,不免要做一番调研和测试,本文便是介绍官方的一个 es 压测工具 esrally,希望能为大家带来帮助。
ZooKeeper分布式协调服务详解:面试经验与必备知识点解析
【4月更文挑战第9天】本文深入剖析ZooKeeper分布式协调服务原理,涵盖核心概念如Server、Client、ZNode、ACL、Watcher,以及ZAB协议在一致性、会话管理、Leader选举中的作用。讨论ZooKeeper数据模型、操作、会话管理、集群部署与管理、性能调优和监控。同时,文章探讨了ZooKeeper在分布式锁、队列、服务注册与发现等场景的应用,并在面试方面分析了与其它服务的区别、实战挑战及解决方案。附带Java客户端实现分布式锁的代码示例,助力提升面试表现。
人工智能平台PAI产品使用合集之PAI机器学习预置处理器在部署完成后怎么进行调用
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
人工智能平台PAI产品使用合集之SaveV3模块的用法不知道如何解决
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
【玩转数据系列四】听说啤酒和尿布很配?本期教你用协同过滤做推荐
数据挖掘的一个经典案例就是尿布与啤酒的例子。尿布与啤酒看似毫不相关的两种产品,但是当超市将两种产品放到相邻货架销售的时候,会大大提高两者销量。很多时候看似不相关的两种产品,却会存在这某种神秘的隐含关系,获取这种关系将会对提高销售额起到推动作用,然而有时这种关联是很难通过理性的分析得到的。这时候我们需

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
