 开源大数据EMR
开源大数据EMR
开源大数据EMR_个人页
开源大数据EMR


文章
269
问答
74
视频
0
个人介绍
暂无个人介绍
擅长的技术
- Java
- Python
- 前端开发
- Linux
- 数据库

暂无更多信息
2020年07月
-
07.17 22:32:42
 发表了文章
2020-07-17 22:32:42
发表了文章
2020-07-17 22:32:42
Apache Spark 3.0 中的向量化 IO
在 Apache Spark 3.0 中,SparkR 中引入了一种新的向量化(vectorized)实现,它利用 Apache Arrow 直接在 JVM 和 R 之间交换数据,且(反)序列化成本非常小
-
07.17 16:14:01发表了文章
2020-07-17 16:14:01
7月23日社区直播【TFPark: Distributed TensorFlow in Production on Apache Spark】
TFPark是开源AI平台Analytics Zoo中一个模块,它的可以很方便让用户在Spark集群中分布式地进行TensorFlow模型的训练和推断。一方面,TFPark利用Spark将TensorFlow 定义的AI训练或推理任务无缝的嵌入到用户的大数据流水线中,而无需对现有集群做任何修改;另一方面TFPark屏蔽了复杂的分布式系统逻辑,可以将单机开发的AI应用轻松扩展到几十甚至上百节点上。本次分享将介绍TFPark的使用,内部实现以及在生产环境中的实际案例。
-
07.16 12:08:33发表了文章
2020-07-16 12:08:33
大神带练, 0基础Spark训练营限时免费抢报!
Spark5天训练营由Spark 中文社区联合阿里云开发者社区联合打造,持续定期更新。第一期训练营邀请到了全 Apache Spark contributer 阵容,经过半个月对课程的精心打磨今天正式上线!限时免费抢报
-
07.15 21:24:32发表了文章
2020-07-15 21:24:32
SparkSQL中产生笛卡尔积的几种典型场景以及处理策略
本文介绍都有哪些情况会产生笛卡尔积,以及如何事前"预测"写的SQL会产生笛卡尔积从而避免
-
07.14 19:01:58发表了文章
2020-07-14 19:01:58
再出王牌:阿里云 Jindo DistCp 全面开放使用,成为阿里云数据迁移利器
此前 Jindo DistCp 仅限于E-MapReduce产品内部使用,此次全方位面向整个阿里云OSS/HDFS用户放开,并提供官方维护和支持技术,欢迎广大用户集成和使用。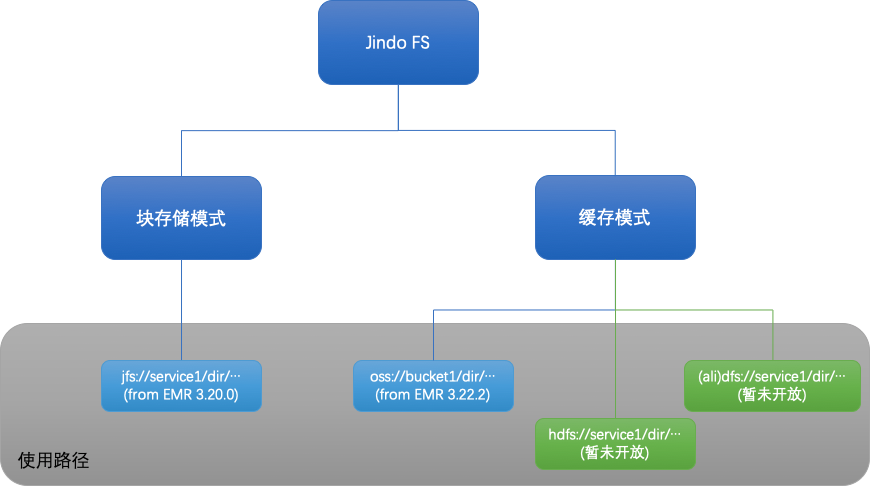
2020年06月
-
06.16 14:10:48发表了文章
2020-06-16 14:10:48
EMR Spark-SQL性能极致优化揭秘 Native Codegen Framework
SparkSQL多年来的性能优化集中在Optimizer和Runtime两个领域。前者的目的是为了获得最优的执行计划,后者的目的是针对既定的计划尽可能执行的更快。
-
06.16 13:46:46发表了文章
2020-06-16 13:46:46
我们欠国内Spark开发者的,用一场掷地有声的中文峰会来还
7月4日-5日,Apache Spark中国技术交流社区举办首次SPARK + AI SUMMIT 2020 中文精华版线上峰会,在北美summit结束第一时间为国内开发者奉上一场技术盛筵。本次活动由阿里云开发者社区牵头,联合阿里云计算平台、Databricks、达摩院、英特尔、领英,在超过覆盖五万开发者的渠道进行投票,票选出了12个最受关注的大会topic进行中文讲解,邀请十几位来自北京、上海、杭州、硅谷的PMC和意见领袖,一一还原英文现场的经典分享。直播间链接 /live/43188
-
06.12 17:14:46发表了文章
2020-06-12 17:14:46
Spark Packages寻宝(一):简单易用的数据准备工具Optimus
本文主要介绍了Optimus项目,作为一个Spark的第三方库,Optimus基于PySpark,为用户提供了一套完整的数据质量探查和数据清理工具集,接口参考Pandas设计,易用且强大,非常适合大规模数据的清理准备工作。限于篇幅,还有很多Optimus的清理接口和Profile功能没有介绍,感兴趣的同学可以访问[Optimus官网](https://hi-optimus.com/)探索更多功能和用法。
-
06.09 17:16:06发表了文章
2020-06-09 17:16:06
6月11日 JindoFS 系列直播【JindoFS 存储策略和读写优化】
本次分享主要介绍数据读写在计算存储分离的场景下所面临的常见问题以及相关的优化手段,并结合应用场景介绍对数据缓存加速的相关技术和策略。
-
06.09 14:49:16发表了文章
2020-06-09 14:49:16
Spark-TFRecord: Spark将全面支持TFRecord
本文中,我们将介绍 Spark 的一个新的数据源,Spark-TFRecord。Spark-TFRecord 的目的是提供在Spark中对原生的 TensorFlow 格式进行完全支持。本项目的目的是将 TFRecord 作为Spark数据源社区中的第一等公民,类似于 Avro,JSON,Parquet等。Spark-TFRecord 不仅仅提供简单的功能支持,比如 Data Frame的读取、写入,还支持一些高阶功能,比如ParititonBy。使用 Spark-TFRecord 将会使数据处理流程与训练工程完美结合。
-
06.08 20:48:51发表了文章
2020-06-08 20:48:51
不通过 Spark 获取 Delta Lake Snapshot
Delta Lake 进行数据删除或更新操作时实际上只是对被删除数据文件做了一个 remove 标记,在进行 vacuum 前并不会进行物理删除,因此一些例如在 web 上获取元数据或进行部分数据展示的操作如果直接从表路径下获取 parquet 文件信息,读到的可能是历史已经被标记删除的数据。
-
06.04 17:36:49发表了文章
2020-06-04 17:36:49
直播 | 阿里、快手、Databricks、网易云音乐...国内外大数据大佬齐聚一堂要聊啥?
6月14日,阿里巴巴计算平台事业部与阿里云开发者社区共同举办的大数据+AI Meetup 系列第一季即将重磅开启,此次 Meetup 邀请了来自阿里巴巴、Databricks、快手、网易云音乐的7位技术专家,集中解读大数据当前热门话题!
-
06.04 16:47:22发表了文章
2020-06-04 16:47:22
阿里云发起首届 Spark “数字人体” AI 挑战赛 — 聚焦上班族脊柱健康
2020年6月4日,首届 Apache Spark AI 智能诊断大赛在天池官网上线。Spark “数字人体” AI 挑战赛——脊柱疾病智能诊断大赛,聚焦医疗领域应用,召集全球开发者利用人工智能技术探索高效准确的脊柱退化性疾病自动诊断。现已面向全社会开放,为所有大数据技术爱好者以及相关的科研企业提供挑战平台,个人参赛或高等院校、科研单位、互联网企业等人员均可报名参赛。本次挑战的目标是通过核磁共振成像来检测和分类脊柱的退行性改变,形成一批创新性强、复用率高的算法案例,并积极推动相关技术的临床应用,用科技造福医疗事业,鼓励人工智能与疾病预防深度融合的应用落地,由点到面驱动国内人工智能医疗产业发展。
2020年05月
-
05.21 19:52:18发表了文章
2020-05-21 19:52:18
首届 Apache Spark AI智能诊断大赛重磅来袭!
本次大赛将由阿里云计算有限公司、英特尔(中国)有限公司联合主办,湘雅医院、浙江大学附属第二附属医院、解放军301医院作为指导单位,唯医骨科共同合作,全程有资深技术专家提供技术指导。本次挑战的目标是通过核磁共振成像来检测和分类脊柱的退行性改变,形成一批创新性强、复用率高的算法案例,并积极推动相关技术的临床应用,用科技造福医疗事业,鼓励人工智能与疾病预防深度融合的应用落地,由点到面驱动国内人工智能医疗产业发展,向公众真正意义上展示大数据AI在整个社会不可替代的价值。
-
05.20 13:34:25发表了文章
2020-05-20 13:34:25
SparkSQL与Hive metastore Parquet转换
Spark SQL为了更好的性能,在读写Hive metastore parquet格式的表时,会默认使用自己的Parquet SerDe,而不是采用Hive的SerDe进行序列化和反序列化
-
05.18 22:10:31发表了文章
2020-05-18 22:10:31
物化视图在 SparkSQL 中的实践
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中的实现及应用。
-
05.14 12:52:35发表了文章
2020-05-14 12:52:35
招聘!招聘!招聘!计算平台解决方案架构师专场
为了帮助客户更加高效地使用大数据产品,发挥数据价值,现计算平台招募大数据及AI产品解决方案架构师,欢迎在北京、杭州的同学加入我们!
-
05.14 12:32:57发表了文章
2020-05-14 12:32:57
Spark + AI Summit 2020 中文议题有奖征集
北美 Spark + AI Summit 2020 盛会在即,Apache Spark 中国技术交流社区在此诚邀各位,代表国内开发者选择您最希望听到的主题,届时社区将联合国内顶尖技术专家一一展开中文形式分享。
-
05.12 11:02:42发表了文章
2020-05-12 11:02:42
5月14日Apache Spark中国社区技术直播【Analytics Zoo上的分布式TensorFlow训练AI玩FIFA足球游戏】
近年来,由于对通用人工智能研究的潜在价值,训练AI玩游戏一直是一个火热的研究领域。FIFA实时视频游戏场景复杂,需要结合图像,强化学习等多种不同的AI技术,同时也要求agents响应有实时性,因此是一个非常好的试验场,可以用来探索不同类型的AI技术。本次分享主要介绍我们在训练AI玩FIFA视频游戏方面的一些工作。
-
05.11 12:01:55发表了文章
2020-05-11 12:01:55
EMR Spark-SQL性能极致优化揭秘 RuntimeFilter Plus
在 2019 年的打榜测试中,我们基于 Spark SQL Catalyst Optimizer 开发的 RuntimeFilter 优化 对于 10TB 数据 99 query 的整体性能达到 35% 左右的提升。
-
05.07 16:37:33发表了文章
2020-05-07 16:37:33
5月8日 JindoFS 系列直播 第五讲【JindoFS Fuse 支持】
本次直播主要介绍如何利用FUSE的POSIX文件系统接口,像本地磁盘一样轻松使用大数据存储系统, 为云上AI场景提供了高效的数据访问手段。
-
05.06 14:31:21发表了文章
2020-05-06 14:31:21
Hadoop社区比 Ozone 更重要的事情
本文回顾了最近几年Hadoop项目的发展,着重探讨个人对Ozone的看法和理解,不求正确,引玉而已,欢迎业内专家拍砖讨论。
2020年04月
-
04.27 14:45:12发表了文章
2020-04-27 14:45:12
4月29日Spark社区直播【用Analytics-Zoo实现基于深度学习的胸腔疾病AI诊疗辅助】
本次分享主要介绍如何利用Analytics Zoo和NIH胸部X光影像数据集,在Apache Spark集群上实现基于深度学习的胸腔疾病分类,为医生提供端到端的胸腔疾病AI诊疗辅助。
-
04.27 12:21:00发表了文章
2020-04-27 12:21:00
阿里云EMR计算速度提升2.2倍 连续两年打破大数据领域最难竞赛世界纪录!
4月26日,大数据领域权威竞赛TPC-DS公布了最新结果,阿里云作为全球唯一入选的云计算公司获得第一。值得一提的是,去年阿里云EMR首次打破该竞赛纪录,成为全球首个通过TPC认证的公共云产品。今年在这一基础上,EMR的计算速度提升了2.2倍,连续两年打破了这项大数据领域最难竞赛的世界纪录。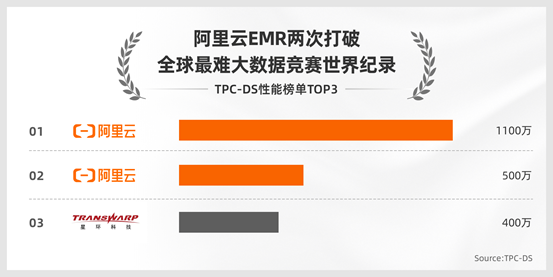
-
04.23 11:45:08发表了文章
2020-04-23 11:45:08
SparkSQL DatasourceV2 之 Multiple Catalog
SparkSQL DatasourceV2作为Spark2.3引入的特性,在Spark 3.0 preview(2019/12/23)版本中又有了新的改进以更好的支持各类数据源。本文将从catalog角度,介绍新的数据源如何和Spark DatasourceV2进行集成。
-
04.21 11:37:04发表了文章
2020-04-21 11:37:04
4月23日JindoFS系列直播【大规模文件元数据下的耗时操作优化】
本次直播主要介绍大数据生态中常见的元数据服务部署形态,并分析大规模文件元数据下在生产环境中可能遇到的问题,以及针对这些问题如何进行优化和调整。
2020年03月
-
03.25 15:45:26发表了文章
2020-03-25 15:45:26
Delta Lake 平台化实践(离线篇)
本文是在 Delta Lake 0.4 与 Spark 2.4 集成、平台化过程中的一些实践与思考
-
03.23 17:23:31发表了文章
2020-03-23 17:23:31
3月26日Spark社区技术直播【Office Depot利用Analytics Zoo构建智能推荐系统的实践分享 】
大量实验结果表明深度学习能更好地帮助商家为用户个性化推荐感兴趣的商品。Office Depot将Analytics Zoo工具包引入到他们的推荐系统中,在Spark集群上分布式训练了各种推荐算法模型,实验结果相比于传统的推荐算法有了十分显著的提升,本次分享主要介绍Office Depot使用Analytics Zoo构建智能推荐系统的实践经验。
-
03.23 11:05:14发表了文章
2020-03-23 11:05:14
通过Job Committer保证Mapreduce/Spark任务数据一致性
通过对象存储系统普遍提供的Multipart Upload功能,实现的No-Rename Committer在数据一致性和性能方面相对于FileOutputCommitter V1/V2版本均有较大提升,在使用MapRedcue和Spark写入数据到S3/Oss的场景中更加推荐使用。
-
03.19 11:58:28发表了文章
2020-03-19 11:58:28
不可不知的Spark调优点
在利用Spark处理数据时,如果数据量不大,那么Spark的默认配置基本就能满足实际的业务场景。但是当数据量大的时候,就需要做一定的参数配置调整和优化,以保证业务的安全、稳定的运行。并且在实际优化中,要考虑不同的场景,采取不同的优化策略。
-
03.17 13:59:36发表了文章
2020-03-17 13:59:36
3月19日JindoFS系列直播【关于 JindoFS 最新的 OTS 方案】
本次直播主要介绍JindoFS的元数据的后端演化。包括JindoFS的架构以及使用场景、JindoFS 元数据的不同的后端支持,以及JindoFS 在云上环境如何支持 OTS 作为元数据后端。
-
03.17 13:55:42发表了文章
2020-03-17 13:55:42
3月19日JindoFS系列直播【关于 JindoFS 最新的 OTS 方案】
本次直播主要介绍JindoFS的元数据的后端演化。包括JindoFS的架构以及使用场景、JindoFS 元数据的不同的后端支持,以及JindoFS 在云上环境如何支持 OTS 作为元数据后端。
-
03.16 12:39:32发表了文章
2020-03-16 12:39:32
Spark 3.0 终于支持 event logs 滚动了
Spark 的 event log 为什么不可以提供类似功能呢?值得高兴的是,即将发布的 Spark 3.0 为我们带来了这个功能(具体参见 SPARK-28594)。当然,对待 Spark 的 event log 不能像其他普通应用程序的日志那样,简单切割,然后删除很早之前的日志,而需要保证 Spark 的历史服务器能够解析已经 Roll 出来的日志,并且在 Spark UI 中展示出来,以便我们进行一些查错、调优等。
-
03.16 09:33:11
 回答了问题
2020-03-16 09:33:11
回答了问题
2020-03-16 09:33:11
怎样进钉钉2个群
赞0 踩0 评论0 -
03.09 10:46:57发表了文章
2020-03-09 10:46:57
Delta Lake,让你从复杂的Lambda架构中解放出来
Linux 基金会的 Delta Lake(Delta.io)是一个给数据湖提供可靠性的开源存储层软件。在 QCon 全球软件开发大会(上海站)2019 的演讲中,Databricks 公司的 Engineering Manager 李潇带我们了解了 Delta Lake 在实际生产中的应用与实践以及未来项目规划,本文便整理自此次演讲。
-
03.08 17:53:11发表了文章
2020-03-08 17:53:11
【译】Databricks使用Spark Streaming和Delta Lake对流式数据进行数据质量监控介绍
本文主要对Databricks如何使用Spark Streaming和Delta Lake对流式数据进行数据质量监控的方法和架构进行了介绍,本文探讨了一种数据管理架构,该架构可以在数据到达时,通过主动监控和分析来检测流式数据中损坏或不良的数据,并且不会造成瓶颈。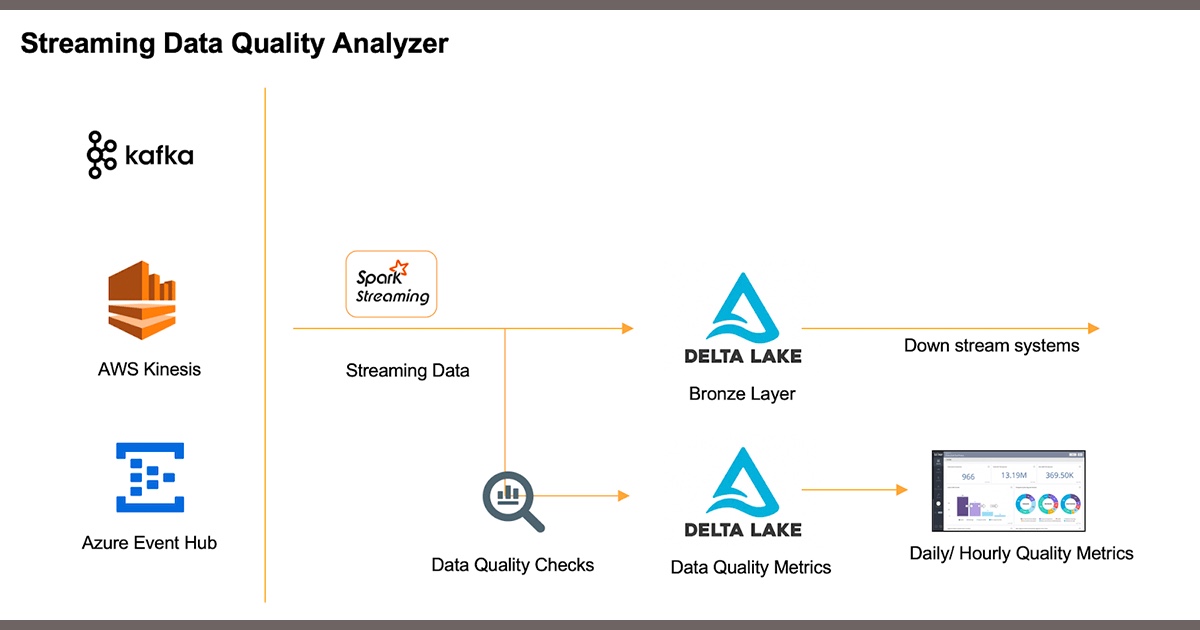
-
03.08 17:19:02发表了文章
2020-03-08 17:19:02
【译】Delta Lake 0.5.0介绍
本文主要对Delta Lake最新发布的0.5.0版本进行了介绍,介绍了如何使用Presto读取Delta表以及Delta Lake 0.5.0在并发性上的提升。 -
03.05 17:09:00发表了文章
2020-03-05 17:09:00
Delta Lake - 数据湖的数据可靠性
Delta Lake 是一个开源的存储层,为数据湖带来了可靠性。Delta Lake 提供了ACID事务、可伸缩的元数据处理以及统一的流和批数据处理。它运行在现有的数据湖之上,与 Apache Spark API完全兼容。
-
03.02 13:05:59发表了文章
2020-03-02 13:05:59
核桃编程Delta Lake实时数仓应用实践
本文简述了核桃编程应用EMR建设Delta Lake实时数仓的实践。
2020年02月
-
02.28 13:34:49发表了文章
2020-02-28 13:34:49
Apache iceberg:Netflix 数据仓库的基石
Apache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。
-
02.27 14:01:43发表了文章
2020-02-27 14:01:43
深入探讨HBASE
本文阐述了HBase集群、内部存储中的主要角色,以及存储过程中与hdfs的交互。
-
02.26 13:13:32发表了文章
2020-02-26 13:13:32
Apache Kylin 云原生架构的思考及规划
在 1 月 4 号 ECUG 技术大会的分享中,Kyligence 的 CEO Luke Han 为大家带来了主题为《Apache Kylin 云原生架构的思考及规划》的精彩演讲,分享了 Kylin 如何拥抱云原生这一趋势。以下为演讲实录。
-
02.24 10:19:52发表了文章
2020-02-24 10:19:52
浅析Hive/Spark SQL读文件时的输入任务划分
本文最后留个思考题给读者们:如何设置参数彻底关闭Spark SQL data source表的文件合并? 积极回答问题即可获得社区礼物。
-
02.24 10:12:05发表了文章
2020-02-24 10:12:05
使用 Jupyter Notebook 运行 Delta Lake 入门教程
因为官方教程是基于商业软件 Databricks Community Edition 构建,虽然教程中使用的软件特性都是开源 Delta Lake 版本所具备的,但是考虑到国内的网络环境,注册和使用 Databricks Community Edition 门槛较高。所以本文尝试基于开源的 Jupiter Notebook 重新构建这个教程。
-
02.21 11:27:26发表了文章
2020-02-21 11:27:26
解析SparkStreaming和Kafka集成的两种方式
spark streaming是基于微批处理的流式计算引擎,通常是利用spark core或者spark core与spark sql一起来处理数据。在企业实时处理架构中,通常将spark streaming和kafka集成作为整个大数据处理架构的核心环节之一。
-
02.20 13:25:02发表了文章
2020-02-20 13:25:02
Python搭建新冠肺炎预测模型全解读
新冠病毒疫后复工成为当务之急,然而病毒尚未消散,风险权衡面临不确定因素。传统机器学习模型虽然可以精确拟合历史数据,但由于脱离疾病传播机理,外推预测的可靠性低。与以往的疾病传播模型不同,南栖仙策的模型对病情的发展进行建模,能够更好的模拟潜伏期、无症状感染者。
-
02.19 14:16:17发表了文章
2020-02-19 14:16:17
在家办公这些天整理的Kafka知识点大全
Kakfa 广泛应用于国内外大厂,例如 BAT、字节跳动、美团、Netflix、Airbnb、Twitter 等等。今天我们通过这篇文章深入了解 Kafka 的工作原理。
-
02.18 13:06:44发表了文章
2020-02-18 13:06:44
环形缓冲区-Hadoop Shuffle过程中的利器
环形队列广泛用于网络数据收发,和不同程序间数据交换(比如内核与应用程序大量交换数据,从硬件接收大量数据)均使用了环形队列。
-
02.14 18:21:04发表了文章
2020-02-14 18:21:04
Data Lake 三剑客——Delta、Hudi、Iceberg 对比分析
定性上讲,三者均为 Data Lake 的数据存储中间层,其数据管理的功能均是基于一系列的 meta 文件。meta 文件的角色类似于数据库的 catalog/wal,起到 schema 管理、事务管理和数据管理的功能。
-
发表了文章
2020-07-17
Apache Spark 3.0 中的向量化 IO
-
发表了文章
2020-07-17
7月23日社区直播【TFPark: Distributed TensorFlow in Production on Apache Spark】
-
发表了文章
2020-07-16
大神带练, 0基础Spark训练营限时免费抢报!
-
发表了文章
2020-07-15
SparkSQL中产生笛卡尔积的几种典型场景以及处理策略
-
发表了文章
2020-07-14
再出王牌:阿里云 Jindo DistCp 全面开放使用,成为阿里云数据迁移利器
-
发表了文章
2020-06-16
EMR Spark-SQL性能极致优化揭秘 Native Codegen Framework
-
发表了文章
2020-06-16
我们欠国内Spark开发者的,用一场掷地有声的中文峰会来还
-
发表了文章
2020-06-12
Spark Packages寻宝(一):简单易用的数据准备工具Optimus
-
发表了文章
2020-06-11
直播 | Delta Lake 如何帮助云用户解决数据实时入库问题
-
发表了文章
2020-06-09
6月11日 JindoFS 系列直播【JindoFS 存储策略和读写优化】
-
发表了文章
2020-06-09
Spark-TFRecord: Spark将全面支持TFRecord
-
发表了文章
2020-06-08
不通过 Spark 获取 Delta Lake Snapshot
-
发表了文章
2020-06-04
直播 | 阿里、快手、Databricks、网易云音乐...国内外大数据大佬齐聚一堂要聊啥?
-
发表了文章
2020-06-04
阿里云发起首届 Spark “数字人体” AI 挑战赛 — 聚焦上班族脊柱健康
-
发表了文章
2020-05-21
首届 Apache Spark AI智能诊断大赛重磅来袭!
-
发表了文章
2020-05-20
SparkSQL与Hive metastore Parquet转换
-
发表了文章
2020-05-19
5月21日 Spark 社区直播【Spark on Zeppelin】
-
发表了文章
2020-05-18
物化视图在 SparkSQL 中的实践
-
发表了文章
2020-05-14
招聘!招聘!招聘!计算平台解决方案架构师专场
-
发表了文章
2020-05-14
Spark + AI Summit 2020 中文议题有奖征集
滑动查看更多
-
回答了问题
2020-03-16
怎样进钉钉2个群
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2019-07-17
请教一下,delta是不是可以理解为,是基于hdfs的行级别的数据库?然后对于更新数据对于hdfs产生小文件的解决方案是他会提供merge机制?
是的,可以大致这样理解。是行级别的,但下面存储格式基本上还是以 Parquet/ORC 列式为主;delta 小文件要及时合并的,否则性能很差。数据库这个提法不一定好,因为并不会用于 OLTP;可以说是数据仓库,OLAP 场景为主的。关于这个区别,我的一篇文章里面讲得比较细。可以看看。
https://yq.aliyun.com/articles/699919?spm=a2c4e.11153959.0.0.4f427507ntu6fX赞0 踩0 评论0 -
 提交了问题
2019-05-05
提交了问题
2019-05-05
请教一下,delta是不是可以理解为,是基于hdfs的行级别的数据库?然后对于更新数据对于hdfs产生小文件的解决方案是他会提供merge机制?
-
回答了问题
2019-07-17
workflow这个功能很期待,想问下他的工作流之间的依赖关系是怎么建立的,是用户自己定义么?
这个问题很高级,你们是不是已经在玩了?不过工作流的定义过程里面,必然会形成各个工作流节点之间的依赖关系,定义工作流本身就是定义各个节点和他们之间的上下游关系,也就形成了这些依赖关系。如果你问的是多个工作流之间是不是还可以形成更高层次的依赖关系,我没有深入去看,感觉目前还比较早一点,不一定已经支持了。
赞1 踩0 评论0 -
提交了问题
2019-05-05
workflow这个功能很期待,想问下他的工作流之间的依赖关系是怎么建立的,是用户自己定义么?
-
回答了问题
2019-07-17
spark 与 tensorflow 结合有没有方案?
分享里面(4月28日钉钉群分享)提到的 Hydrogen 项目就是要系统支持这些深度学习框架的。Spark 3.0 会包含进去。你找到相关 SPIP,JIRA 和 PPT 挖一下。
赞0 踩0 评论0 -
提交了问题
2019-05-05
spark 与 tensorflow 结合有没有方案?
-
回答了问题
2019-07-17
E-MapReduce 集群 header 节点有公网 IP,存在安全风险,是否可以通过 ECS 控制台关闭公网 IP,关闭公网 IP 是否会对 E-MapReduce 服务产生影响?
如果您没有使用 EMR 的统一元数据库功能,可以关闭公网 IP。
 赞0 踩0 评论0
赞0 踩0 评论0 -
提交了问题
2019-04-26
E-MapReduce 集群 header 节点有公网 IP,存在安全风险,是否可以通过 ECS 控制台关闭公网 IP,关闭公网 IP 是否会对 E-MapReduce 服务产生影响?
-
回答了问题
2019-07-17
-
提交了问题
2019-04-26
如何登陆 Core 节点,并进行 root 权限操作
-
回答了问题
2019-07-17
E-Mapreduce 主节点不允许安装其它软件?
理论上可以在不破坏集群环境的前提下安装。但是这些软件的运行可能会影响到集群的稳定可靠性,不建议进行此类操作。
赞0 踩0 评论0 -
提交了问题
2019-04-26
E-Mapreduce 主节点不允许安装其它软件?
-
回答了问题
2019-07-17
已有/现存 ECS 是否可以用到 EMR 集群中
目前还不能支持,用户要创建 EMR 集群需要在 EMR 控制台上来创建 ECS。
赞1 踩0 评论0 -
提交了问题
2019-04-26
已有/现存 ECS 是否可以用到 EMR 集群中
-
回答了问题
2019-07-17
自动续费
EMR 支持自动续费操作,支持 EMR 和 ECS 的自动续费。
赞0 踩0 评论0 -
提交了问题
2019-04-26
自动续费
-
回答了问题
2019-07-17
集群续费问题
续费操作请参考集群续费。经常会有用户反馈续费了但是还是会通知说没有续费。这是因为 EMR 现在有 2 块,一块是 EMR,一块是 ECS,大部分的用户都只是续费了 ECS 而没有续费 EMR。您可以打开续费界面查看 ECS 和 EMR 到期时间。
赞0 踩0 评论0 -
提交了问题
2019-04-26
集群续费问题
-
回答了问题
2019-07-17
创建集群失败,构建失败 "The specified instance Type exceeds the maximum limit for the PostPaid instances. "
一般是用户的按量节点数量的上限到了。ECS 根据不同用户,按量节点上限是不一样的。需要用户去申请加大。如果确认不是上述的原因,还有一种可能是用户是没有创建的机型的权限,需要去 ECS 开通这个机型的使用权限。
赞0 踩0 评论0
滑动查看更多
暂无更多信息