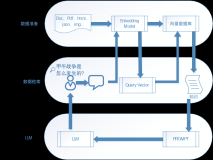
1. SVD技术介绍
Stable Video Diffusion(以下简称 SVD),是一个图像到视频模型模型,能够以每秒 3 到 30 帧的可自定义的帧率生成 14 帧和 25 帧的视频。去年 11 月,Stability.AI 发布了它的 1.0 版本。
而这个1.1版本的模型经过训练,可在 1024x576 的分辨率下生成 25 帧。总体上他是一个生成短视频,类似gif形式的一个模型,而这个也是目前来说开源并且在直接生成视频的模型效果比较好的一个了。
还有一点需要注意,这个 SVD 和我们常用的生成视频类的操作,比如它和 AnimateDiff 相比,这是不一样的技术。但他们也可以同时放在一起使用,比如我们先用 SVD 生成一个视频,hires提升分辨率后再用 AnimateDiff 重绘等等,这又是后话了。
2. 资源领取
点击 领取 PAI-EAS 免费试用 1 个月 A10/V100 资源。注意这个免费每日是有一定限额的,先到先得哦~

等待开通完成,点击前往控制台
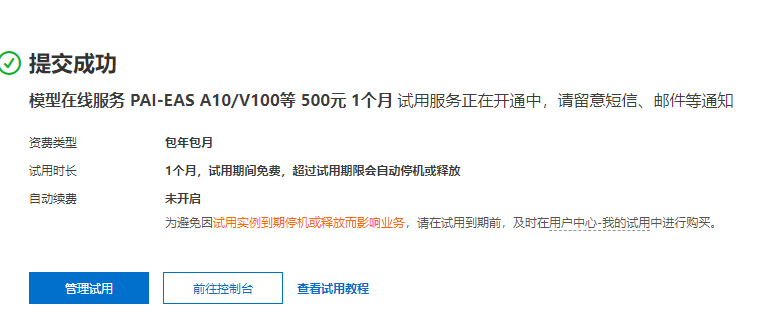
如果免费额度用完了,可以购买 PAI-EAS 59元抵扣200元资源包

来到 PAI 控制台后,推荐大家在这里切换区域为 华北 2(北京),组合开通勾选OSS的选项,因为已经开通过所以默认勾上了。然后等待部署,部署完成后就可以前往默认工作空间。
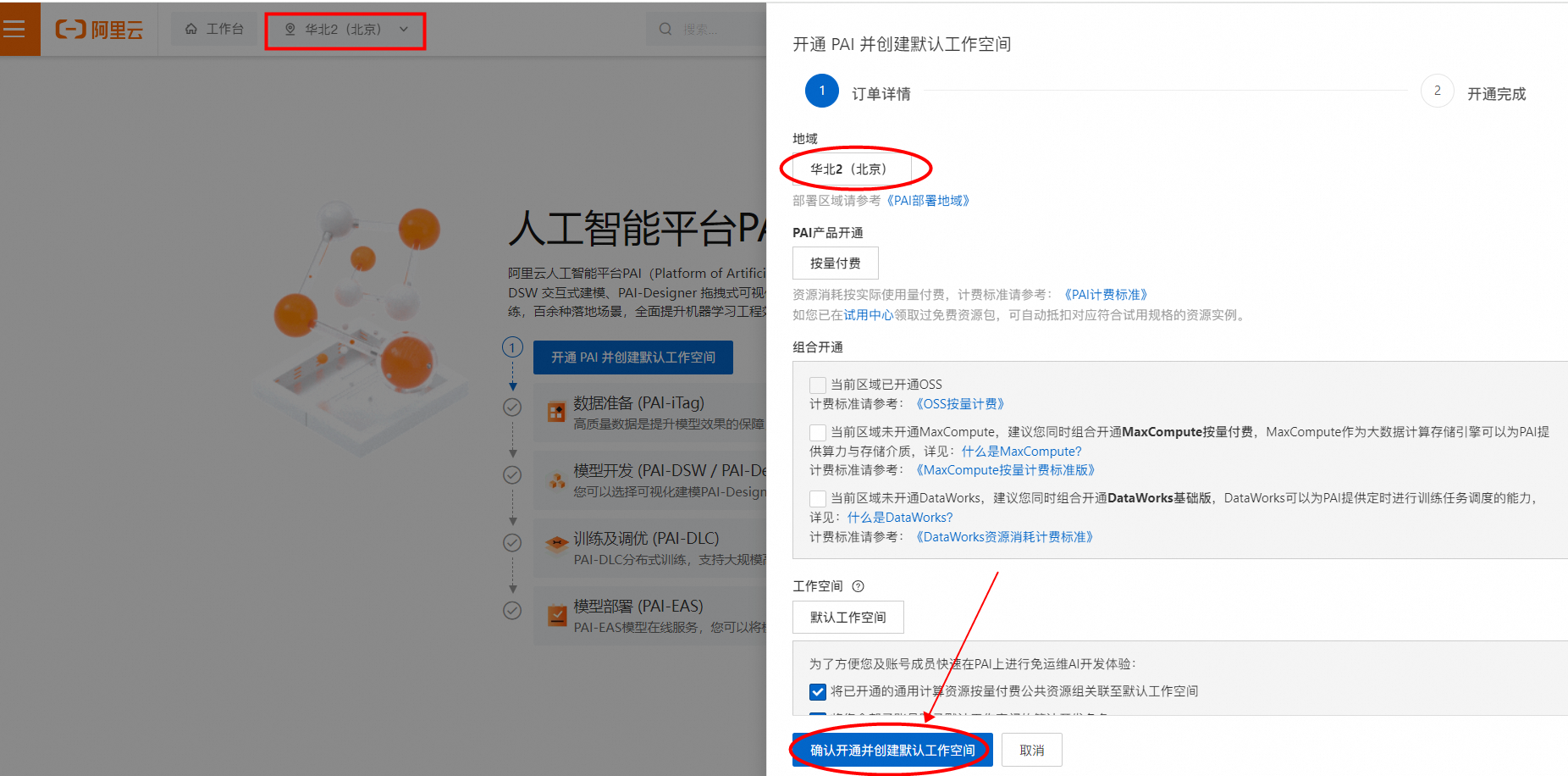
找到左侧的 EAS 服务来部署一个实例。首次使用的时候我们需要先开通授权一下服务。
3. 部署ComfyUI
点击部署服务,自定义部署。

自定义输入实例名称,然后在镜像内找到comfyui,版本选择0.3。

在下面选择资源信息,注意这里非常重要,需要选择试用活动的GPU,推荐大家选择A10的GPU,如果缺货也可以选择 V100、T4 等。

选择完成,都配置好后,我们点击部署,等待部署完成。由于这个镜像预制好了很多节点,所以部署可能要等上几分钟到10分钟左右。如果觉得等了很久也可以点进去服务日志查看日志输出,部署情况。等到看到这行“运行中”,即为部署完成了,我们就可以直接进入ComfyUI了。
4. 启动ComfyUI进行模型推理
- 单击目标服务的服务方式列下的查看Web应用。

2. 在WebUI页面进行模型推理验证。
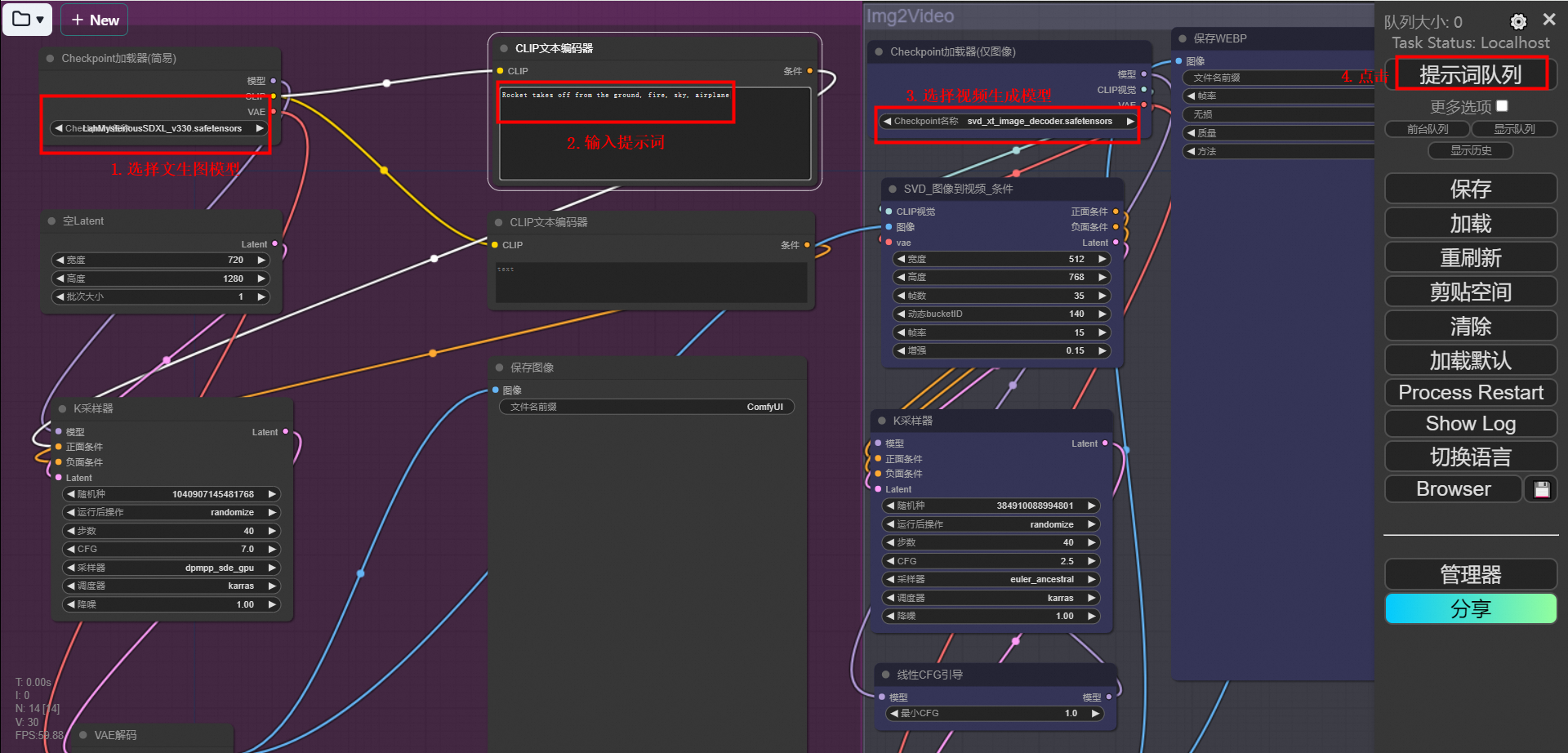
我们前面提到了SVD是一个图片生成视频的模型,所以这里左侧是一个文生图的工作流,首先生成了一张图片。然后再把这张图片输入到右侧的SVD模型,进行视频生成。
根据需要,选择文生图的模型和图生视频的模型,本方案使用默认配置。然后在CLIP文本编码器中输入Prompts,修改长宽为16:9(例如384:216),单击提示词队列, 等待工作流运行完成即可获得AI生成的视频。

3. 请在【合并为视频】将视频改为GIF格式,视频生成后,右键单击生成的视频,选择 Save preview保存图像,即可将生成的GIF格式视频保存到本地,通过活动页【提交作品】参与活动!


5. ComfyUI 参数讲解
左侧的文生图可以调节模型,分辨率。然后是正负prompt,采样时候的种子,采样器等等。都可以随意修改。

然后来看SVD这边的参数。首先就是这个SVD 图像到视频的条件。设置宽、高,这个是视频的分辨率,不要调的太大。然后是帧数,就是一共生成多少帧。动态bucketid这个值越大,画面运动幅度越大。帧率就不用多说了。

然后是这个线性CFG引导。这个摆的位置有些靠下,其实他是在模型和k采样器之间的。他的作用是在不同的帧之间,按线性来缩放CFG值,他会从这个最小CFG值随着帧数按线性增大到K采样器设置的值。比如我们这个节点设置了为1,那么实际上的CFG就是跟随帧数从1变化到2.5。

整体来说,这个工作流就是一个入门的文生视频工作流,如果我们有需要,也可以把生成图像部分换为自己的一个图像输入,就是最原本的SVD图生视频了。
那么后续还有没有更高级的玩法呢?当然有,这里采样器输出的是每一帧的图像,我们当然也可以为他接上高清修复的流程,让他能放大,再接个其他的重绘流程都是可以的。后续就留给大家任意发挥了~
6. 常见问题
更多操作问题可参考
答疑群:加入【PAI-AIGC活动答疑群】搜索钉群: 52485000325