2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
摘要:本文整理自阿里云开源大数据平台徐榜江 (雪尽),关于阿里巴巴捐赠的 Flink CDC 项目正式加入 Apache 基金会,内容主要分为以下四部分:
1、Flink CDC 新仓库,新流程
2、Flink CDC 新定位,新玩法
3、Flink CDC 捐赠契机
4、Flink CDC 未来规划
在2023年12月举行的 Flink Forward Asia 大会上,阿里巴巴正式宣布将 Flink CDC项目捐赠给Apache基金会,作为 Apache Flink 的官方子项目。在接下来的三个月中,阿里巴巴与 Flink CDC 社区的开发者们共同完成了一系列捐赠事宜,包括社区捐赠投票、版权签署、仓库迁移、代码整理、文档迁移、工作项(issue)迁移和持续集成(CI)迁移等。至此,Flink CDC 的全部捐赠流程已正式完成。

Flink CDC 新仓库,新流程
新仓库
随着 Flink CDC 的捐赠流程完成,社区原有代码仓库和文档网站将不再使用,请大家移步 Apache 基金会下的仓库和文档网站。
代码仓库已经从http https://github.com/ververica/flink-cdc-connectors
文档网站已经从 https://ververica.github.io/flink-cdc-connectors
迁移到 https://nightlies.apache.org/flink/flink-cdc-docs-master/
新流程
作为Apache Flink的官方子项目,Flink CDC的后续开发将严格遵循Apache Flink社区的规范。工作项和缺陷将通过Flink Jira管理,而社区开发讨论和交流则逐步从钉钉群转移至Flink社区邮件列表。
工作项的管理和缺陷管理会在 Flink JIRA上进行,请大家在开 issue 时,模块名选择 Flink CDC。
Flink JIRA 地址:https://issues.apache.org/jira/projects/FLINK/issue
开发相关的工作项讨论会在 Flink dev 邮件列表中进行,用户答疑和交流将会在 Flink user(英文用户)和Flink user-zh(中文用户)邮件列表中进行,欢迎大家参考Flink邮件列表订阅指南按需订阅,参与社区开发和交流。
Flink 邮件列表订阅指南:https://flink.apache.org/what-is-flink/community/#mailing-lists
Flink CDC 新定位,新玩法
新定位
Flink CDC 是一个分布式的端到端实时数据集成工具。数据源不再局限于数据库,支持多种数据源,同时支持写出到多种下游系统,提供完整的端到端数据集成能力。对于离线数据集成场景,Flink CDC 也将在后续版本支持离线数据集成。
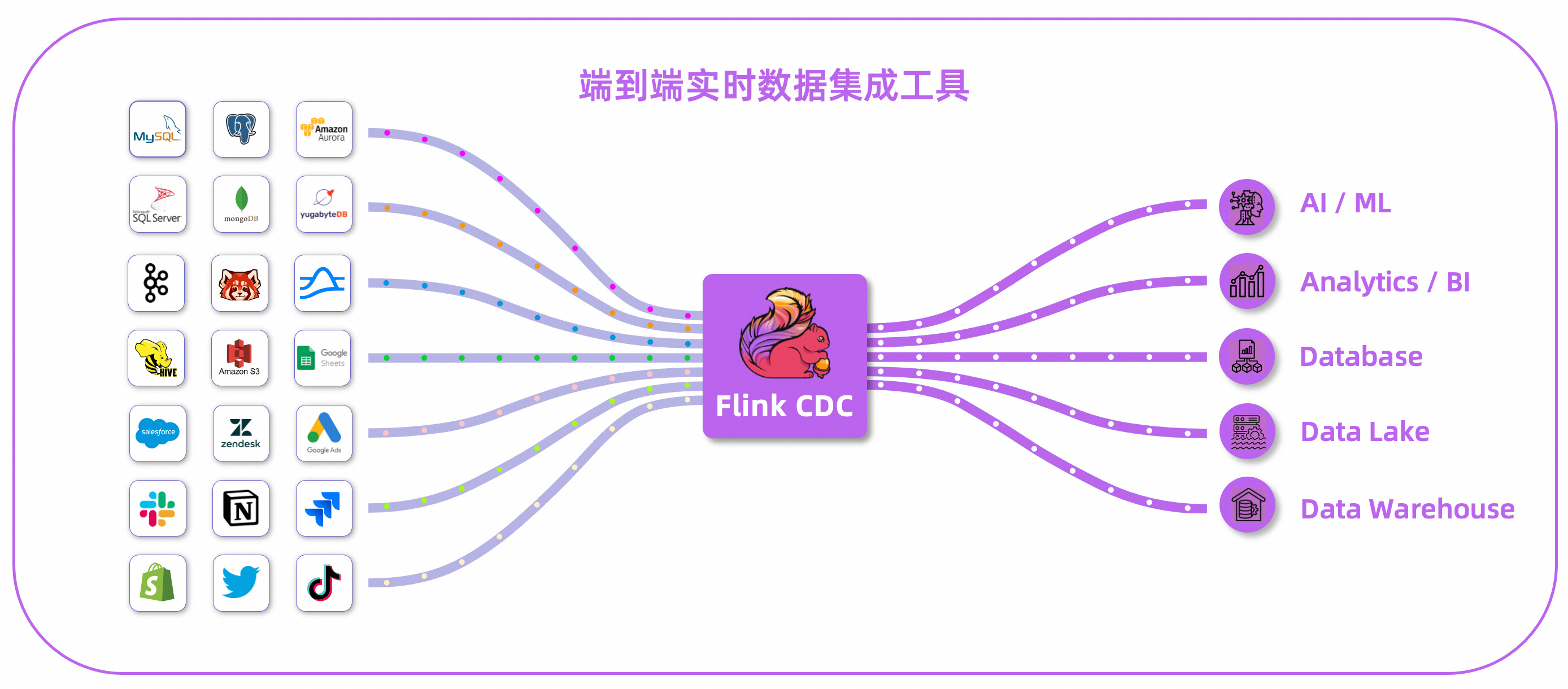
新玩法
Flink CDC 创新性地通过 YAML 这种简洁的 API 来描述数据集成的业务需求,为数据集成用户带来优雅的开发体验。下述例子描述了 Flink CDC 将 MySQL 整库同步到 Doris,Flink CDC 会根据上游表结构推导下游 Doris 表结构并在下游自动建表后开始数据同步,数据同步过程中,上游 MySQL 中表结构变更默认会自动同步到下游 Doris。
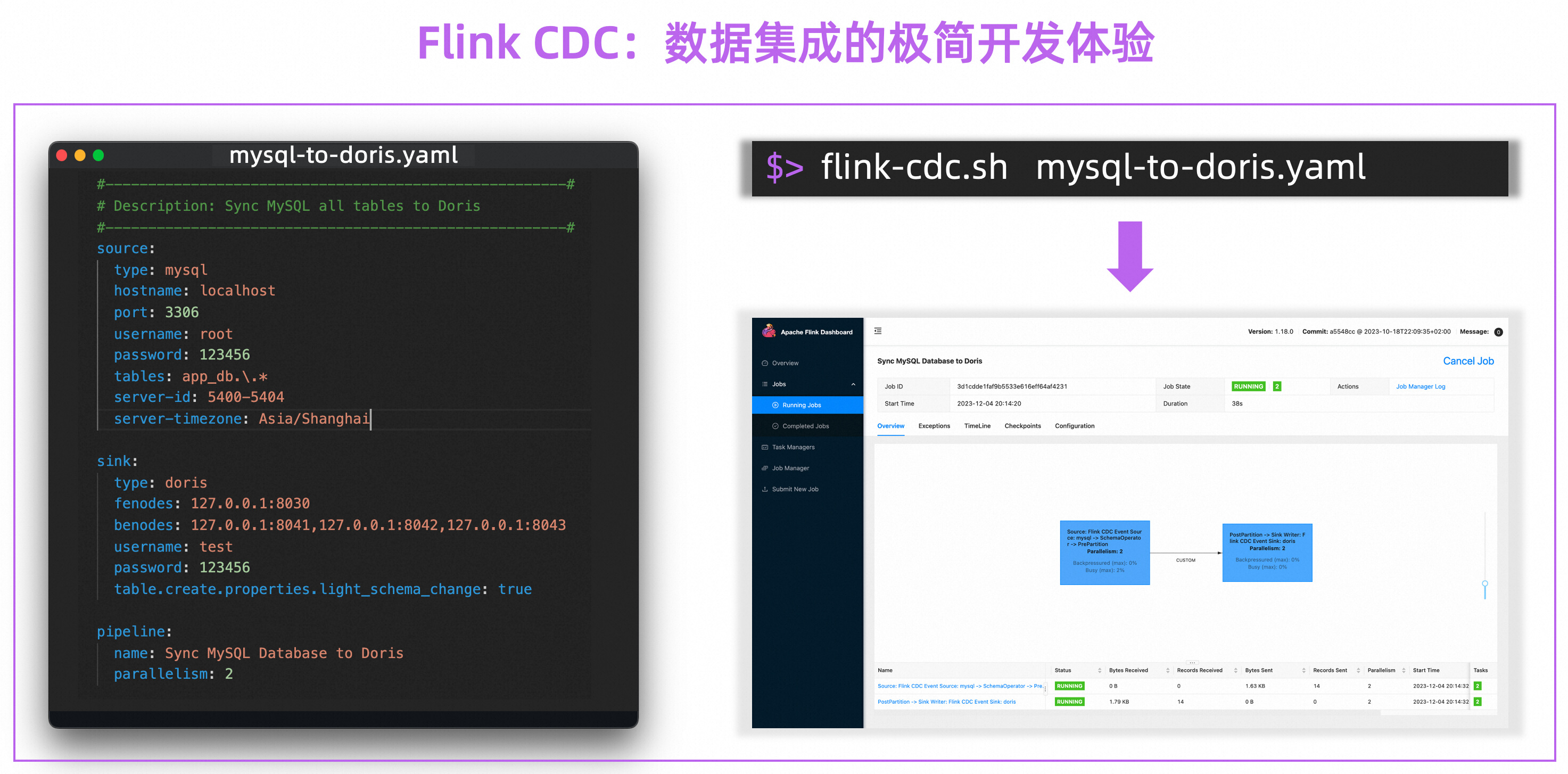
在这极简的 YAML 背后是 Flink CDC 优秀的框架设计和优雅的封装。Flink CDC 框架会解析用户的 YAML 文件生成深度定制化的 Flink 算子并自动编排,算子之间使用高性能的数据结构,框架层面支持了 Schema Evolution、整库同步、分库分表同步等高级功能,现在这些功能用户只需要理解 YAML 就能实现按需启用,无需使用 Java 开发 DataStream 应用。
Flink CDC 捐赠契机
Flink CDC 是阿里巴巴旗下 Ververica 公司于 2020 年 7 月在 Github 上开源的一个数据集成项目,在过去的三年多时间里,在云邪、雪尽、孙家宝、阮航、龚中强、任庆盛、川粉等社区 maintainer 成员带领下,Flink CDC 陆续推出了2.0 和 3.0 两个重要版本,其中 2.0 版本支持了全增量一体化、无锁读取、并行读取等核心功能, 3.0 版本支持了端到端数据集成、Schema Evolution 等核心特性。凭借这些核心特性,Flink CDC 简化了用户数据集成链路,社区也取得了高速的发展,目前社区 Github star 超过 5k,社区用户群破万,Flink CDC 技术也在国内外多个行业落地。
在社区发展过程中,我们也发现了项目发展的两大限制,一是技术原因:一些 Flink CDC 的底层功能开发依赖于 Flink 的 public API 修改,而 Flink API 开发和管理非常严谨,作为一个周边生态项目去推动 Flink 社区改动现有 public API 的流程比较复杂,推动也较慢。二是社区共建原因:虽然项目使用的是非常友好的 Apache License V2 开源协议,但项目版权归属于 Ververica 公司,对于一些注重版权的企业和开发者,在参与 Flink CDC 开源社区共建时有一些担忧。针对这些发展限制,考虑到项目的长期发展,来自阿里巴巴、Ververica、蚂蚁、XTransfer、大健云仓的社区维护成员内部进行了多次讨论,最终决定将该项目捐赠给 Apache 基金会作为 Apache Flink 的官方子项目,这样的好处是不仅可以让 Flink CDC 所需的 Flink API 演进能够在 Flink 社区获得更快的响应,同时也能消除企业和开发者对社区共建的版权担忧。
Flink CDC 未来规划
Flink CDC 捐赠的过程中,社区开发者一直在持续开发 3.1 版本 Roadmap 中规划的功能,可以透露的是多个重点功能已经就绪。因此,预计在4月份,我们将发布进入 Apache 之后的第一个版本 3.1.0, 该版本框架将会支持期待已久的 Transform 操作,包括列裁剪、计算列、表达式计算和常用的内置函数等,同时 Flink CDC 的连接器生态将会支持重点湖仓,下游系统将会支持写入 Paimon 数据湖和 Kafka 消息队列,敬请期待。
Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可微信扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!

更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
59 元试用 实时计算 Flink 版(3000CU*小时,3 个月内)
了解活动详情:https://free.aliyun.com/?pipCode=sc

