
Deephub

已加入开发者社区518天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

一代宗师
一代宗师



我关注的人
粉丝








技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
公众号 Deephub-IMBA
暂无精选文章
暂无更多信息
2024年05月
-
05.09 11:55:29
 发表了文章
2024-05-09 11:55:29
发表了文章
2024-05-09 11:55:29
论文推荐:用多词元预测法提高模型效率与速度
《Better & Faster Large Language Models via Multi-token Prediction》论文提出了一种多词元预测框架,改善了大型语言模型(LLMs)的样本效率和推理速度。该方法通过一次预测多个词元,而非单个词元,提高了模型在编程和自然语言任务中的性能。实验显示,多词元预测在HumanEval和MBPP任务上性能提升,推理速度最高可提升3倍。此外,自我推测解码技术进一步优化了解码效率。尽管在小模型中效果不明显,但该方法为大模型训练和未来研究开辟了新途径。
-
05.08 11:22:00发表了文章
2024-05-08 11:22:00
号称能打败MLP的KAN到底行不行?数学核心原理全面解析
Kolmogorov-Arnold Networks (KANs) 是一种新型神经网络架构,挑战了多层感知器(mlp)的基础,通过在权重而非节点上使用可学习的激活函数(如b样条),提高了准确性和可解释性。KANs利用Kolmogorov-Arnold表示定理,将复杂函数分解为简单函数的组合,简化了神经网络的近似过程。与mlp相比,KAN在参数量较少的情况下能达到类似或更好的性能,并能直观地可视化,增强了模型的可解释性。尽管仍需更多研究验证其优势,KAN为深度学习领域带来了新的思路。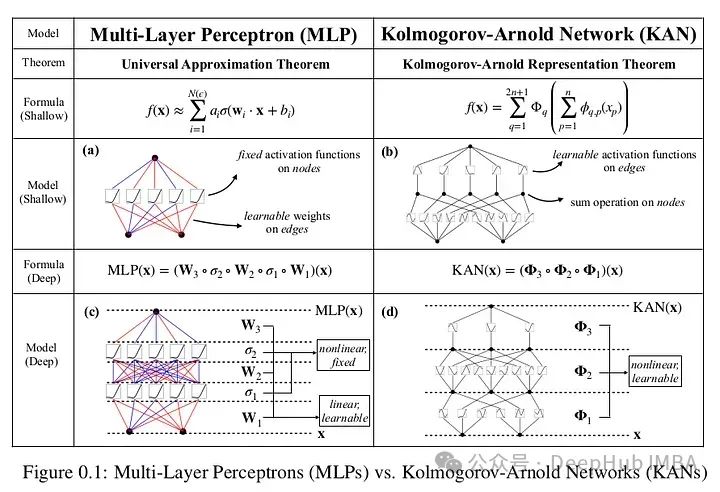
-
05.07 10:50:34发表了文章
2024-05-07 10:50:34
循环编码:时间序列中周期性特征的一种常用编码方式
循环编码是深度学习中处理周期性数据的一种技术,常用于时间序列预测。它将周期性特征(如小时、日、月)转换为网络可理解的形式,帮助模型识别周期性变化。传统的one-hot编码将时间特征转换为分类特征,而循环编码利用正弦和余弦转换,保持时间顺序信息。通过将时间戳转换为弧度并应用sin和cos,每个原始特征只映射到两个新特征,减少了特征数量。这种方法在神经网络中有效,但在树模型中可能需谨慎使用。
-
05.06 10:28:26发表了文章
2024-05-06 10:28:26
LSTM时间序列预测中的一个常见错误以及如何修正
在使用LSTM进行时间序列预测时,常见错误是混淆回归和预测问题。LSTM需将时间序列转化为回归问题,通常使用窗口或多步方法。然而,窗口方法中,模型在预测未来值时依赖已知的未来值,导致误差累积。为解决此问题,应采用迭代预测和替换输入值的方法,或者在多步骤方法中选择合适的样本数量和训练大小以保持时间结构。编码器/解码器模型能更好地处理时间数据。
-
05.05 12:20:56发表了文章
2024-05-05 12:20:56
LLM2Vec介绍和将Llama 3转换为嵌入模型代码示例
通过LLM2Vec,我们可以使用LLM作为文本嵌入模型。但是简单地从llm中提取的嵌入模型往往表现不如常规嵌入模型。
-
05.04 10:49:42发表了文章
2024-05-04 10:49:42
BiTCN:基于卷积网络的多元时间序列预测
该文探讨了时间序列预测中模型架构的选择,指出尽管MLP和Transformer模型常见,但CNN在预测领域的应用较少。BiTCN是一种利用两个时间卷积网络来编码历史和未来协变量的模型,提出于《Parameter-efficient deep probabilistic forecasting》(2023年3月)。它包含多个由扩张卷积、GELU激活函数、dropout和全连接层组成的临时块,有效地处理序列数据。实验表明,BiTCN在具有外生特征的预测任务中表现优于N-HiTS和PatchTST。BiTCN的效率和性能展示了CNN在时间序列预测中的潜力。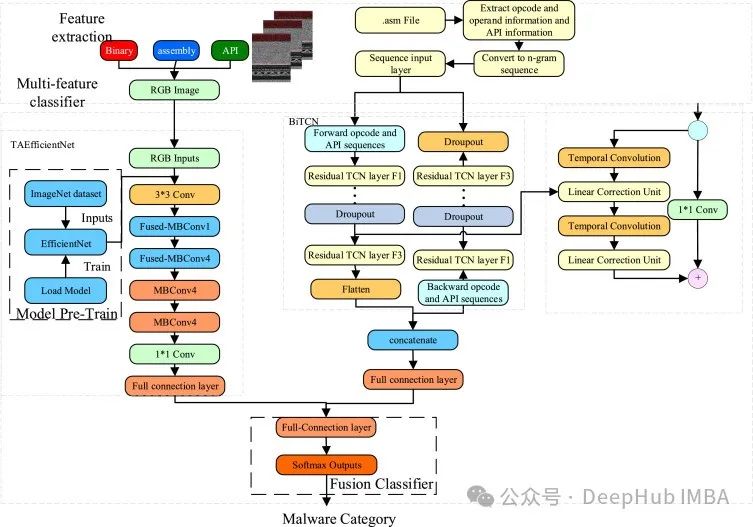
-
05.03 11:17:20发表了文章
2024-05-03 11:17:20
整合文本和知识图谱嵌入提升RAG的性能
本文介绍了如何结合文本嵌入和知识图谱嵌入来提升RAG(检索式生成模型)的性能。文本嵌入利用Word2Vec、GloVe或BERT等预训练模型捕捉单词的语义和上下文,而知识图谱嵌入则表示实体和关系,以便更好地理解结构化信息。通过结合这两种嵌入,RAG模型能更全面地理解输入文本和知识,从而提高答案检索和生成的准确性。文章通过代码示例展示了如何生成和整合这两种嵌入,强调了它们在增强模型对模糊性和可变性处理能力上的作用。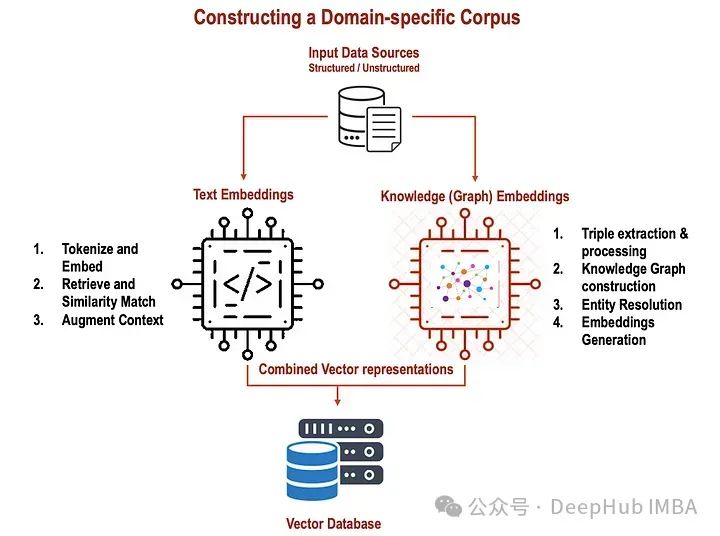
-
05.02 09:48:09发表了文章
2024-05-02 09:48:09
Gradformer: 通过图结构归纳偏差提升自注意力机制的图Transformer
Gradformer,新发布的图Transformer,引入指数衰减掩码和可学习约束,强化自注意力机制,聚焦本地信息并保持全局视野。模型整合归纳偏差,增强图结构建模,且在深层架构中表现稳定。对比14种基线模型,Gradformer在图分类、回归任务中胜出,尤其在NCI1、PROTEINS、MUTAG和CLUSTER数据集上准确率提升明显。此外,它在效率和深层模型处理上也表现出色。尽管依赖MPNN模块和效率优化仍有改进空间,但Gradformer已展现出在图任务的强大潜力。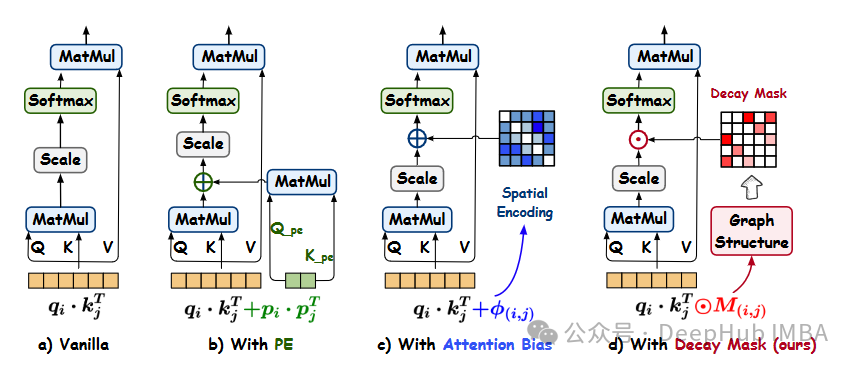
-
05.01 10:06:47发表了文章
2024-05-01 10:06:47
10个使用NumPy就可以进行的图像处理步骤
这篇文章介绍了使用NumPy进行图像处理的10个基本步骤,包括读取图像、缩小图像、水平和垂直翻转、旋转、裁剪、分离RGB通道、应用滤镜(如棕褐色调)、灰度化、像素化、二值化以及图像融合。通过这些简单的操作,读者可以更好地掌握NumPy在图像处理中的应用。示例代码展示了如何实现这些效果,并配有图像结果。文章强调这些方法适合初学者,更复杂的图像处理可使用专门的库如OpenCV或Pillow。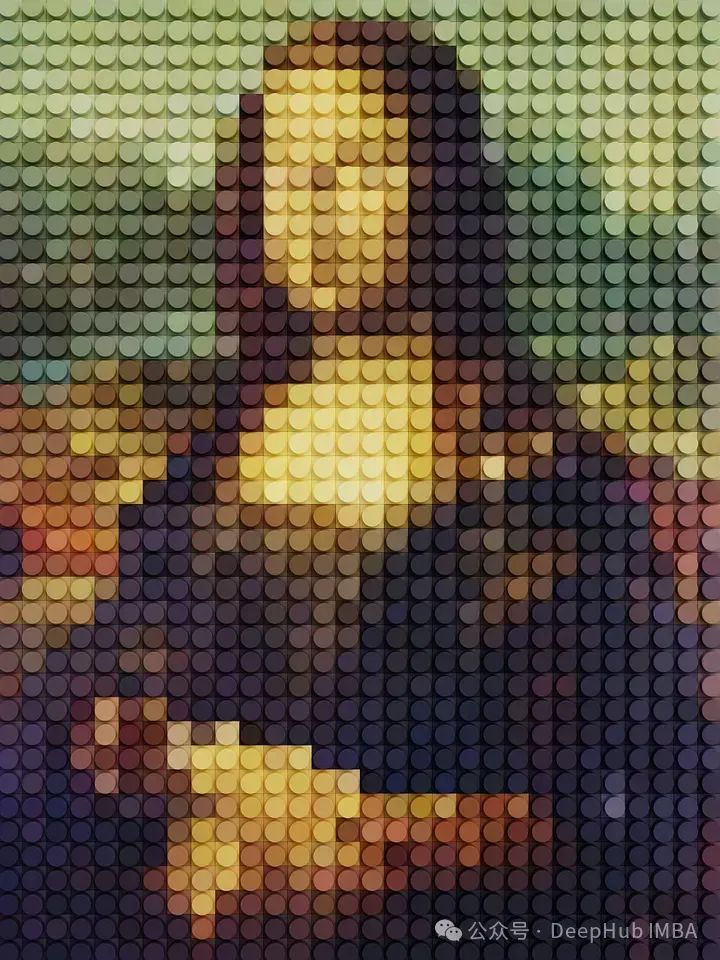
2024年04月
-
04.30 12:31:01发表了文章
2024-04-30 12:31:01
贝叶斯推理导论:如何在‘任何试验之前绝对一无所知’的情况下计算概率
这篇文章探讨了贝叶斯推理的发展历史,从帕斯卡尔和费马的早期工作到托马斯·贝叶斯、皮埃尔-西蒙·拉普拉斯和哈罗德·杰弗里斯的贡献。文章指出,贝叶斯分析经历了从使用均匀先验到发展更为客观的方法,如杰弗里斯先验的过程。它讨论了费雪对逆概率的批评,以及贝叶斯方法在处理不确定性问题上的优势。文章还介绍了如何通过匹配覆盖率来评估先验分布的合理性,并通过几个例子展示了不同先验在二项分布和正态分布问题中的应用。最后,文章提出了贝叶斯分析在统计学中的地位,强调了在缺乏先验知识时建立良好先验的重要性,并讨论了主观性和客观性在统计推理中的角色。
-
04.29 10:50:03发表了文章
2024-04-29 10:50:03
如何准确的估计llm推理和微调的内存消耗
最近发布的三个大型语言模型——Command-R+ (104B参数), Mixtral-8x22b (141B参数的MoE模型), 和 Llama 3 70b (70.6B参数)——需要巨大的内存资源。推理时,Command-R+需193.72GB GPU RAM,Mixtral-8x22B需262.63GB,Llama 370b需131.5GB。激活的内存消耗根据序列长度、批大小等因素变化。文章详细介绍了计算这些模型内存需求的方法,并探讨了如何通过量化、优化器优化和梯度检查点减少内存使用,以适应微调和推理。
-
04.28 15:46:47发表了文章
2024-04-28 15:46:47
通过学习曲线识别过拟合和欠拟合
本文介绍了如何利用学习曲线识别机器学习模型中的过拟合和欠拟合问题。过拟合发生时,模型过于复杂,对训练数据过拟合,导致测试集表现不佳;欠拟合则是因为模型太简单,无法捕获数据模式,训练和测试集得分均低。学习曲线通过绘制训练和验证损失随训练样本增加的情况来辅助判断。对于过拟合,学习曲线显示训练损失低且随样本增加上升,验证损失降低但不趋近训练损失;欠拟合时,训练和验证损失都高,且两者随着样本增加缓慢改善。通过学习曲线,我们可以调整模型复杂度或采用正则化等方法优化模型泛化能力。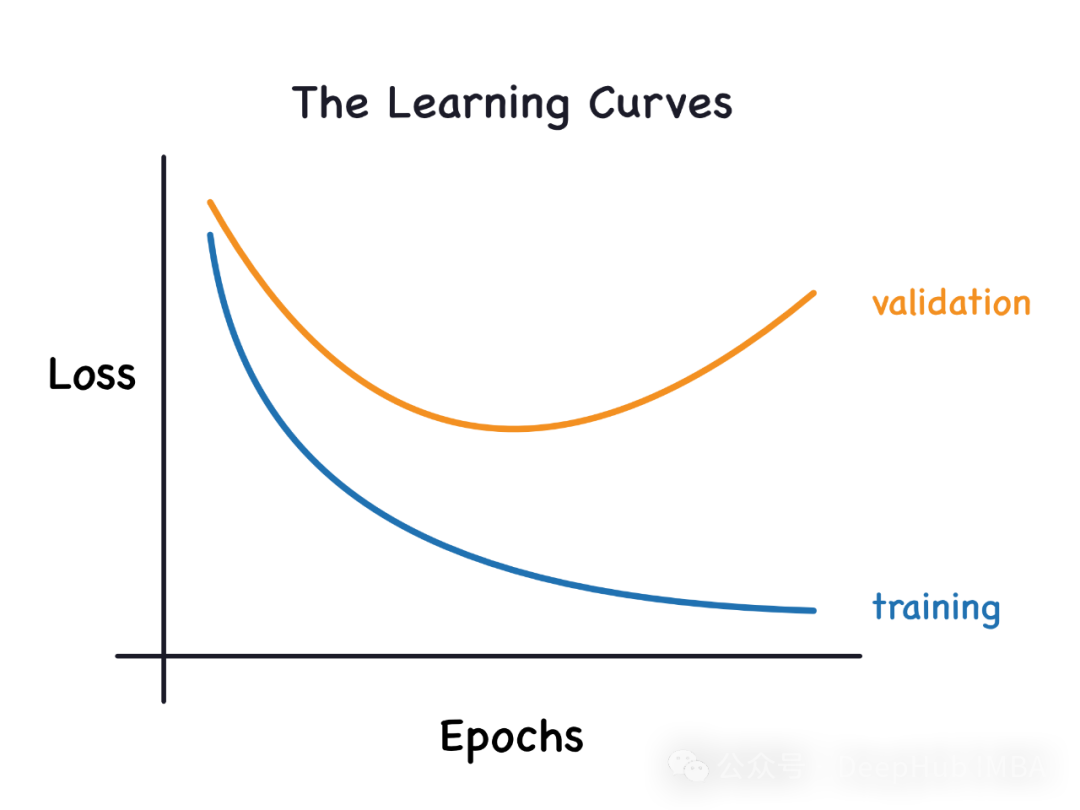
-
04.27 11:30:12发表了文章
2024-04-27 11:30:12
2024年4月计算机视觉论文推荐
四月的计算机视觉研究涵盖多个子领域,包括扩散模型和视觉语言模型。在扩散模型中,Tango 2通过直接偏好优化改进了文本到音频生成,而Ctrl-Adapter提出了一种有效且通用的框架,用于在图像和视频扩散模型中添加多样控制。视觉语言模型的论文分析了CLIP模型在有限资源下的优化,并探讨了语言引导对低级视觉任务的鲁棒性。图像生成与编辑领域关注3D感知和高质量图像编辑,而视频理解与生成则涉及实时视频转游戏环境和文本引导的剪贴画动画。
-
04.26 10:12:35发表了文章
2024-04-26 10:12:35
常用的时间序列分析方法总结和代码示例
该文介绍了时间序列分析的基本方法,以西伯利亚东南部2023年的气象数据为例,包括2米气温、总降水量、地表净太阳辐射和地表压力。首先,导入相关库如pandas、seaborn和xarray,然后展示时间序列的折线图。接着,通过statmodels库进行时间序列的分解,分析趋势、季节性和噪声。文章还讨论了数据的平稳性,使用ADF检验确认所有变量的平稳性,并通过Box-Cox变换尝试改善非正态分布。此外,还展示了自相关和部分自相关图以揭示序列的结构。这些步骤帮助理解数据特性,为后续建模做准备。
-
04.25 11:21:11发表了文章
2024-04-25 11:21:11
开源向量数据库比较:Chroma, Milvus, Faiss,Weaviate
该文探讨了向量数据库在语义搜索和RAG中的核心作用,并介绍了四个开源向量数据库:Chroma、Milvus、Faiss和Weaviate。这些数据库用于存储高维向量,支持基于相似性的快速搜索,改变了传统的精确匹配方法。文章详细比较了它们的特性,如Chroma的易用性,Milvus的存储效率,Faiss的GPU加速,和Weaviate的图数据模型。选择合适的数据库取决于具体需求,如数据类型、性能和使用场景。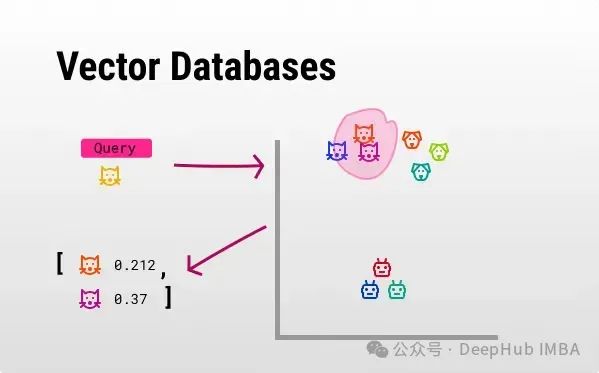
-
04.24 12:13:14发表了文章
2024-04-24 12:13:14
微软Phi-3,3.8亿参数能与Mixtral 8x7B和GPT-3.5相媲美,量化后还可直接在IPhone中运行
Phi-3系列是微软推出的一系列高效语言模型,旨在在移动设备上实现高性能。该系列包括 Phi-3-mini(38亿参数)、Phi-3-small 和 Phi-3-medium,它们在保持紧凑的同时,性能媲美GPT-3.5和Mixtral。模型通过精心筛选的数据集和优化训练策略,如数据最优化和阶段训练,实现高效能。 Phi-3-mini可在iPhone 14上运行,占用约1.8GB内存。这些模型在多个基准测试中展现出色性能,推动了AI在移动设备上的应用,增强了用户隐私和体验。虽然目前仅发布技术报告,但源代码和权重即将开放下载。
-
04.23 10:51:36发表了文章
2024-04-23 10:51:36
Barnes-Hut t-SNE:大规模数据的高效降维算法
Barnes-Hut t-SNE是一种针对大规模数据集的高效降维算法,它是t-SNE的变体,用于高维数据可视化。t-SNE通过保持概率分布相似性将数据从高维降至2D或3D。Barnes-Hut算法采用天体物理中的方法,将时间复杂度从O(N?)降低到O(NlogN),通过构建空间索引树和近似远距离交互来加速计算。在scikit-learn中可用,代码示例展示了如何使用该算法进行聚类可视化,成功分离出不同簇并获得高轮廓分数,证明其在大數據集上的有效性。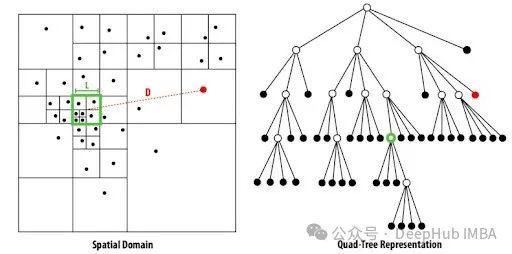
-
04.22 11:02:04发表了文章
2024-04-22 11:02:04
5种搭建LLM服务的方法和代码示例
本文介绍了5种搭建开源大型语言模型服务的方法,包括使用Anaconda+CPU、Anaconda+GPU、Docker+GPU、Modal和AnyScale。CPU方法适合本地低门槛测试,但速度较慢;GPU方法显著提升速度,Docker简化环境配置,适合大规模部署;Modal提供按需付费的GPU服务,适合试验和部署;而AnyScale则以低门槛和低成本访问开源模型。每种方法都有其优缺点,选择取决于具体需求和资源。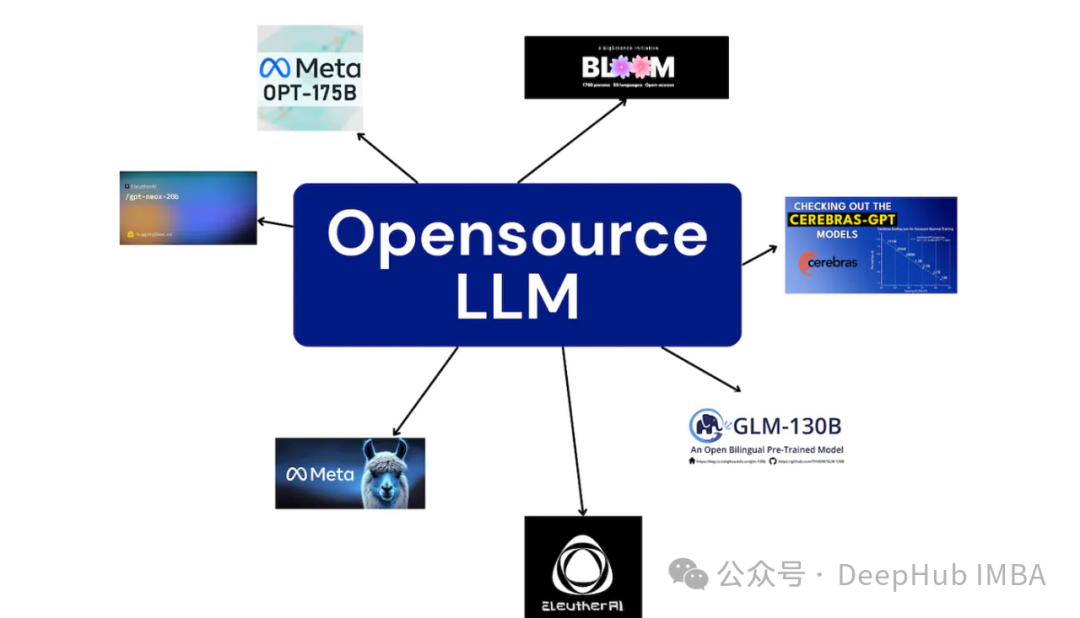
-
04.21 10:04:19发表了文章
2024-04-21 10:04:19
使用ORPO微调Llama 3
ORPO是一种结合监督微调和偏好对齐的新型微调技术,旨在减少训练大型语言模型所需资源和时间。通过在一个综合训练过程中结合这两种方法,ORPO优化了语言模型的目标,强化了对首选响应的奖励,弱化对不期望回答的惩罚。实验证明ORPO在不同模型和基准上优于其他对齐方法。本文使用Llama 3 8b模型测试ORPO,结果显示即使只微调1000条数据一个epoch,性能也有所提升,证实了ORPO的有效性。完整代码和更多细节可在相关链接中找到。 -
04.20 10:46:13发表了文章
2024-04-20 10:46:13
掌握时间序列特征工程:常用特征总结与 Feature-engine 的应用
本文介绍了时间序列特征工程,包括滚动统计量、滞后特征、差分和变换等技术,用于提升机器学习模型性能。文章还推荐了Python库`feature-engine`,用于简化特征提取,如处理缺失值、编码分类变量和进行时间序列转换。示例代码展示了如何使用`feature-engine`提取时间戳信息、创建滞后特征和窗口特征。通过创建管道,可以高效地完成整个特征工程流程,优化数据预处理并提高模型效果。
-
04.19 11:55:23发表了文章
2024-04-19 11:55:23
RAG 2.0架构详解:构建端到端检索增强生成系统
RAG(检索增强生成)旨在通过提供额外上下文帮助大型语言模型(LLM)生成更精准的回答。现有的RAG系统由独立组件构成,效率不高。RAG 2.0提出了一种预训练、微调和对齐所有组件的集成方法,通过双重反向传播最大化性能。文章探讨了不同的检索策略,如TF-IDF、BM25和密集检索,并介绍了如SPLADE、DRAGON等先进算法。目前的挑战包括创建可训练的检索器和优化检索-生成流程。研究表明,端到端训练的RAG可能提供最佳性能,但资源需求高。未来研究需关注检索器的上下文化和与LLM的协同优化。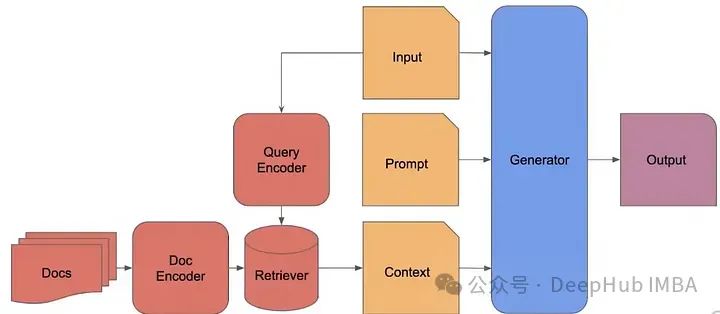
-
04.17 09:51:07发表了文章
2024-04-17 09:51:07
PyTorch小技巧:使用Hook可视化网络层激活(各层输出)
这篇文章将演示如何可视化PyTorch激活层。可视化激活,即模型内各层的输出,对于理解深度神经网络如何处理视觉信息至关重要,这有助于诊断模型行为并激发改进。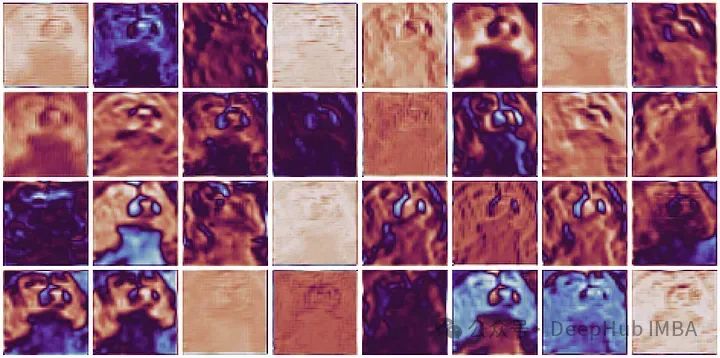
-
04.16 10:04:33发表了文章
2024-04-16 10:04:33
ORPO偏好优化:性能和DPO一样好并且更简单的对齐方法
ORPO是另一种新的LLM对齐方法,这种方法甚至不需要SFT模型。通过ORPO,LLM可以同时学习回答指令和满足人类偏好。
-
04.15 10:02:01发表了文章
2024-04-15 10:02:01
时空图神经网络ST-GNN的概念以及Pytorch实现
本文介绍了图神经网络(GNN)在处理各种领域中相互关联的图数据时的作用,如分子结构和社交网络。GNN与序列模型(如RNN)结合形成的时空图神经网络(ST-GNN)能捕捉时间和空间依赖性。文章通过图示和代码示例解释了GNN和ST-GNN的基本原理,展示了如何将GNN应用于股票市场的数据,尽管不推荐将其用于实际的股市预测。提供的PyTorch实现展示了如何将时间序列数据转换为图结构并训练ST-GNN模型。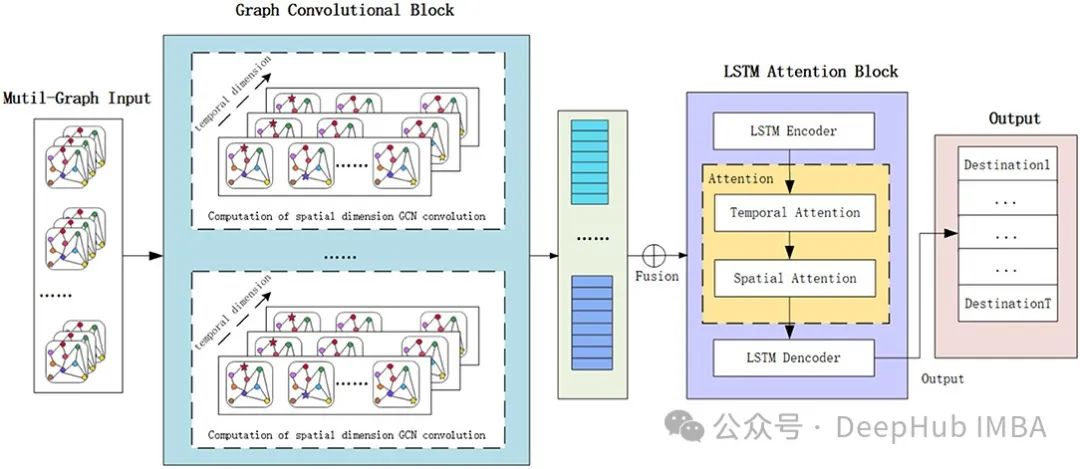
-
04.14 11:33:17发表了文章
2024-04-14 11:33:17
Moirai:Salesforce的时间序列预测基础模型
过去几个月,时间序列基础模型发展迅速,包括TimeGPT、Lag-Llama、Google的TimesFM、Amazon的Chronos和Salesforce的Moirai。本文聚焦于Moirai,这是一个用于时间序列预测的通用模型,尤其强调零样本推理能力。Moirai处理各种数据频率、适应未知协变量并生成概率预测。文章介绍了Moirai的三个关键特性:多尺寸补丁投影层、任意变量注意力和混合分布。此外,还对比了Moirai与Chronos和TimeGPT,发现Moirai在性能上未超越Chronos,后者在数据效率上更优,但不支持多变量预测。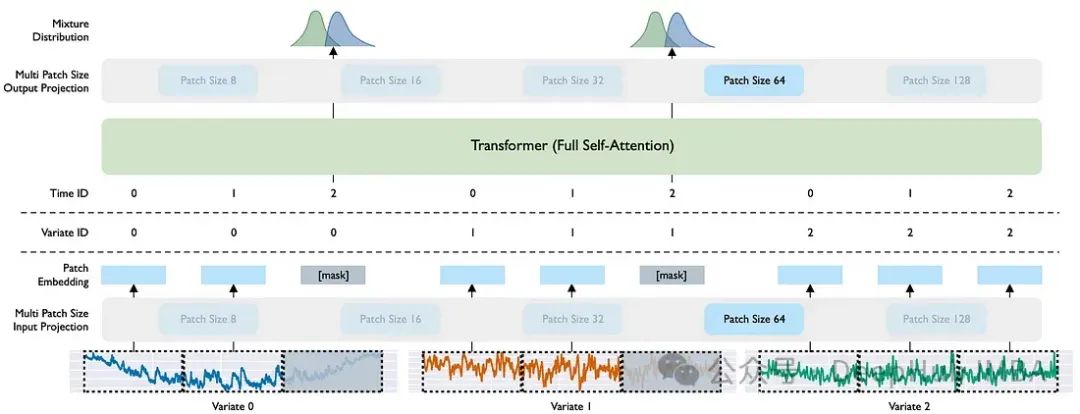
-
04.12 11:43:07发表了文章
2024-04-12 11:43:07
PiSSA :将模型原始权重进行奇异值分解的一种新的微调方法
我们开始看4月的新论文了,这是来自北京大学人工智能研究所、北京大学智能科学与技术学院的研究人员发布的Principal Singular Values and Singular Vectors Adaptation(PiSSA)方法。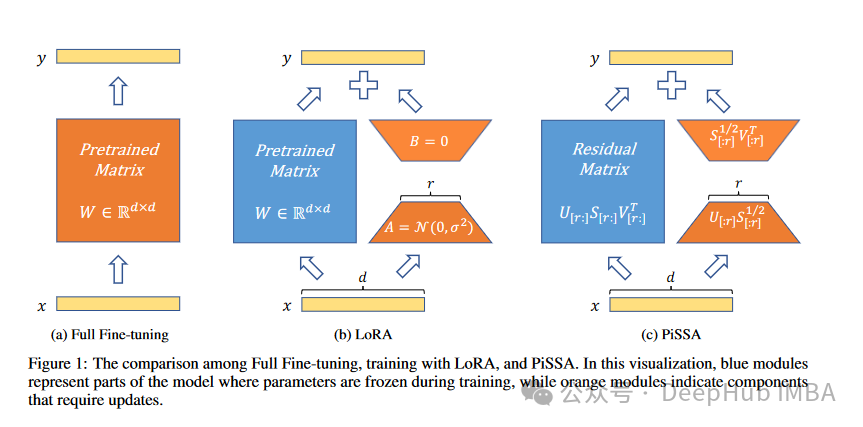
-
04.11 11:33:26发表了文章
2024-04-11 11:33:26
10个大型语言模型(LLM)常见面试问题和答案解析
今天我们来总结以下大型语言模型面试中常问的问题
-
04.10 10:00:58发表了文章
2024-04-10 10:00:58
推测解码:在不降低准确性的情况下将LLM推理速度提高2 - 3倍
在本篇文章我们将详细讨论推测解码,这是一种可以将LLM推理速度提高约2 - 3倍而不降低任何准确性的方法。我们还将会介绍推测解码代码实现,并看看它与原始transformer 实现相比到底能快多少。
-
04.09 11:33:14发表了文章
2024-04-09 11:33:14
?5种常用于LLM的令牌遮蔽技术介绍以及Pytorch的实现
本文将介绍大语言模型中使用的不同令牌遮蔽技术,并比较它们的优点,以及使用Pytorch实现以了解它们的底层工作原理。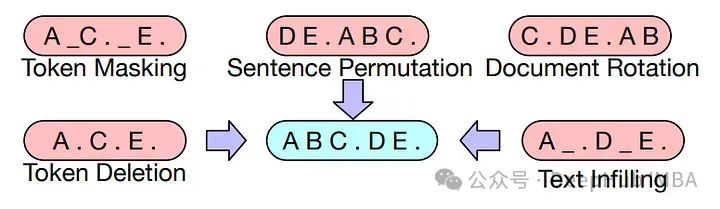
-
04.08 10:07:51发表了文章
2024-04-08 10:07:51
为什么大型语言模型都在使用 SwiGLU 作为激活函数?
SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对他进行详细的介绍。
-
04.07 09:56:45发表了文章
2024-04-07 09:56:45
归一化技术比较研究:Batch Norm, Layer Norm, Group Norm
本文将使用合成数据集对三种归一化技术进行比较,并在每种配置下分别训练模型。记录训练损失,并比较模型的性能。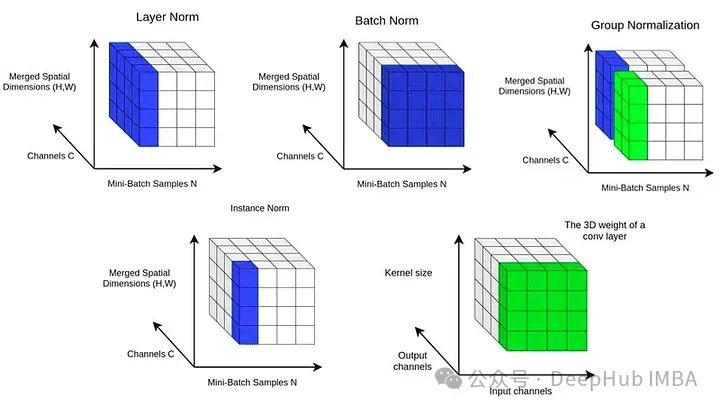
-
04.03 10:12:32发表了文章
2024-04-03 10:12:32
大模型中常用的注意力机制GQA详解以及Pytorch代码实现
GQA是一种结合MQA和MHA优点的注意力机制,旨在保持MQA的速度并提供MHA的精度。它将查询头分成组,每组共享键和值。通过Pytorch和einops库,可以简洁实现这一概念。GQA在保持高效性的同时接近MHA的性能,是高负载系统优化的有力工具。相关论文和非官方Pytorch实现可进一步探究。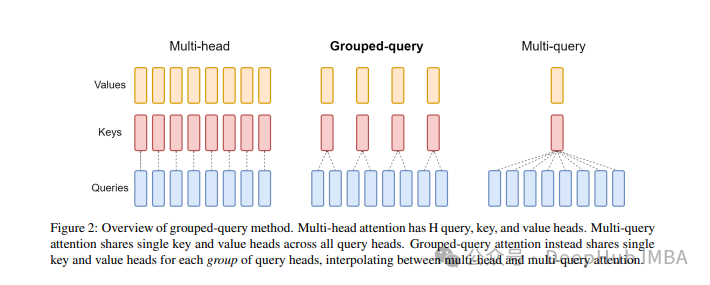
-
04.01 10:24:17发表了文章
2024-04-01 10:24:17
大语言模型中常用的旋转位置编码RoPE详解:为什么它比绝对或相对位置编码更好?
Transformer的基石自2017年后历经变革,2022年RoPE引领NLP新方向,现已被顶级模型如Llama、Llama2等采纳。RoPE融合绝对与相对位置编码优点,解决传统方法的序列长度限制和相对位置表示问题。它通过旋转矩阵对词向量应用角度与位置成正比的旋转,保持向量稳定,保留相对位置信息,适用于长序列处理,提升了模型效率和性能。RoPE的引入开启了Transformer的新篇章,推动了NLP的进展。[[1](https://avoid.overfit.cn/post/9e0d8e7687a94d1ead9aeea65bb2a129)]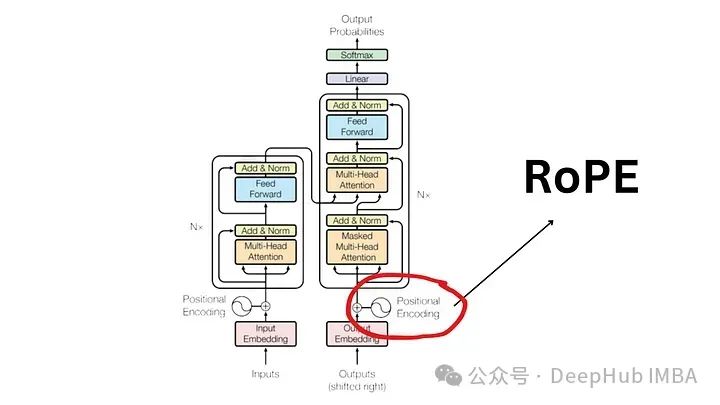
2024年03月
-
03.31 10:34:09发表了文章
2024-03-31 10:34:09
SiMBA:基于Mamba的跨图像和多元时间序列的预测模型
微软研究者提出了SiMBA,一种融合Mamba与EinFFT的新架构,用于高效处理图像和时间序列。SiMBA解决了Mamba在大型网络中的不稳定性,结合了卷积、Transformer、频谱方法和状态空间模型的优点。在ImageNet 1K上表现优越,达到84.0%的Top-1准确率,并在多变量长期预测中超越SOTA,降低了MSE和MAE。代码开源,适用于复杂任务的高性能建模。[[论文链接]](https//avoid.overfit.cn/post/c21aa5ca480b47198ee3daefdc7254bb)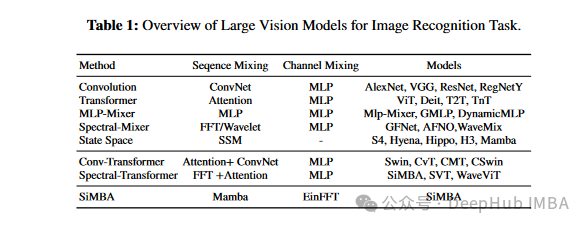
-
03.30 19:40:30发表了文章
2024-03-30 19:40:30
Quiet-STaR:让语言模型在“说话”前思考
**Quiet-STaR** 是一种增强大型语言模型(LLM)推理能力的方法,它扩展了原有的**STaR** 技术,允许LLM为其生成的文本自动生成推理步骤。通过令牌并行抽样和学习的思想令牌,模型能同时预测单词和相关原理。教师强化指导确保输出的正确性。Quiet-STaR提升LLM在句子预测、复杂问题解答和推理基准测试上的表现,降低困惑度,促进更流畅的生成过程。未来研究将探索视觉和符号理由,以及结合可解释AI以提高模型透明度和定制化。[\[arXiv:2403.09629\]](https://arxiv.org/abs/2403.09629) -
03.29 11:57:25发表了文章
2024-03-29 11:57:25
使用MergeKit创建自己的专家混合模型:将多个模型组合成单个MoE
MoE架构通过MergeKit实现新突破,允许整合预训练模型创建frankenMoEs,如FrankenMoE,区别于头开始训练的MoEs。MergeKit工具支持选择专家模型,定义正负提示,并生成MoE配置。
-
03.28 11:19:15发表了文章
2024-03-28 11:19:15
如何开始定制你自己的大型语言模型
2023年,大型语言模型发展迅速,规模更大,性能更强。用户能否定制自己的模型取决于硬件资源。需在功能和成本间找到平衡,可以选择高性能(如40B+参数,适合专业用途,需强大GPU,成本高)或低性能(如7B参数,适合学习和简单应用,GPU成本较低)模型。训练模型可借助HuggingFace的Transformers库,定义数据集并进行训练。训练好的模型可使用Ollama和Open Web UI部署。具备适当GPU是入门基础。
-
03.27 11:02:00发表了文章
2024-03-27 11:02:00
Chronos: 将时间序列作为一种语言进行学习
Chronos框架预训练时间序列模型,将序列值转为Transformer模型的tokens。通过缩放、量化处理,模型在合成及公共数据集上训练,参数量20M至710M不等。优于传统和深度学习模型,展示出色零样本预测性能。使用分类交叉熵损失,支持多模态输出分布学习。数据增强策略包括TSMix和KernelSynth。实验显示大型Chronos模型在概率和点预测上超越多种基线,且微调小型模型表现优异。虽然推理速度较慢,但其通用性简化了预测流程。论文探讨了优化潜力和未来研究方向。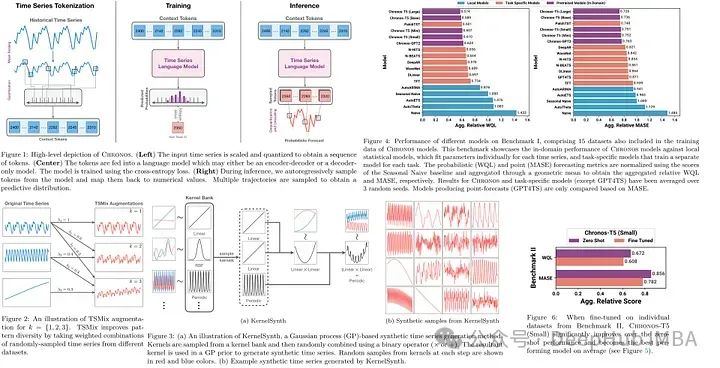
-
03.25 10:01:01发表了文章
2024-03-25 10:01:01
使用GaLore在本地GPU进行高效的LLM调优
GaLore是一种新的优化策略,它通过梯度低秩投影减少VRAM需求,使得大型语言模型(如70亿参数的模型)能在消费级GPU上进行微调,而不减少参数数量。与LoRA相比,GaLore内存效率更高,且性能相当或更优。它在反向传播期间逐层更新参数,降低了计算负荷。虽然GaLore训练时间较长,但它为个人爱好者提供了在有限资源下训练大模型的可能性。相关代码示例和性能对比显示了其优势。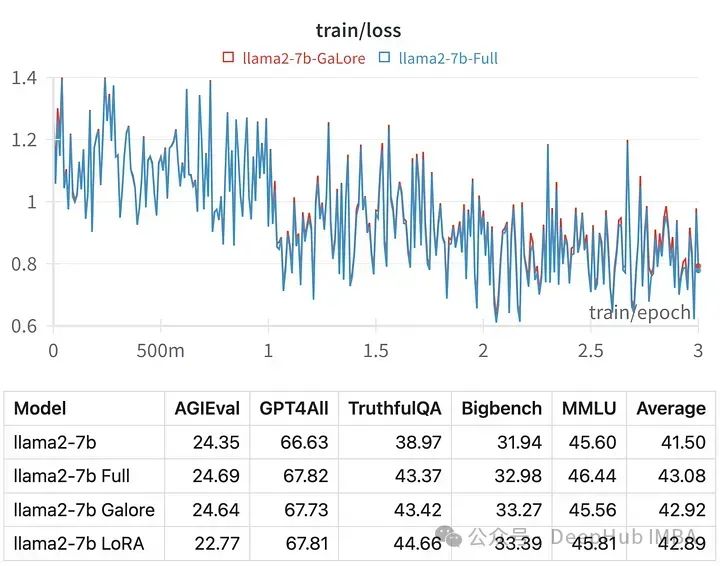
-
03.24 10:12:11发表了文章
2024-03-24 10:12:11
8个常见的数据可视化错误以及如何避免它们
本文揭示了8个数据可视化常见错误:误导色彩对比、过多的数据图表、省略基线、误导性标签、错误的可视化方法、不实的因果关系、放大有利数据和滥用3D图形。强调清晰、准确和洞察力的重要性,提醒制作者避免使用过多颜色、一次性展示大量数据、错误图表类型以及展示无关相关性等。正确可视化能有力支持决策,不应牺牲真实性以追求视觉效果。
-
03.23 13:21:00发表了文章
2024-03-23 13:21:00
BurstAttention:可对非常长的序列进行高效的分布式注意力计算
研究人员探索了提高LLM注意力机制效率的策略,包括FlashAttention(利用SRAM加速)和RingAttention(分布式多设备处理)。新提出的BurstAttention结合两者,优化跨设备计算与通信,减少40%通信开销,使128K长度序列在8×A100 GPU上的训练速度翻倍。论文于3月发布,但实现未公开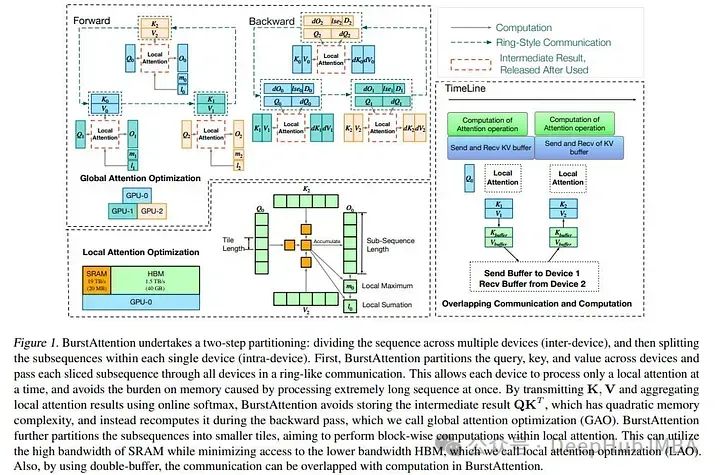
-
03.22 11:31:27发表了文章
2024-03-22 11:31:27
文生图的基石CLIP模型的发展综述
CLIP(Contrastive Language-Image Pre-training)是OpenAI在2021年发布的多模态模型,用于学习文本-图像对的匹配。模型由文本和图像编码器组成,通过对比学习使匹配的输入对在向量空间中靠近,非匹配对远离。预训练后,CLIP被广泛应用于各种任务,如零样本分类和语义搜索。后续研究包括ALIGN、K-LITE、OpenCLIP、MetaCLIP和DFN,它们分别在数据规模、知识增强、性能缩放和数据过滤等方面进行了改进和扩展,促进了多模态AI的发展。 -
03.21 10:15:57发表了文章
2024-03-21 10:15:57
Moment:又一个开源的时间序列基础模型
MOMENT团队推出Time-series Pile,一个大型公共时间序列数据集,用于预训练首个开源时间序列模型家族。模型基于Transformer,采用遮蔽预训练技术,适用于预测、分类、异常检测和输入任务。研究发现,随机初始化比使用语言模型权重更有效,且直接预训练的模型表现出色。MOMENT改进了Transformer架构,调整了Layer norm并引入关系位置嵌入。模型在长期预测和异常检测中表现优异,但对于数值预测的效果尚不明朗。论文贡献包括开源方法、数据集创建和资源有限情况下的性能评估框架。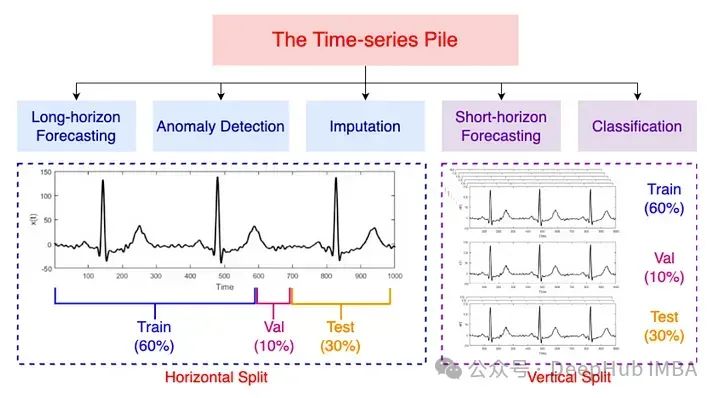
-
03.20 10:52:23发表了文章
2024-03-20 10:52:23
多项式朴素贝叶斯分类器
本文介绍了多项式朴素贝叶斯分类器的工作原理,它基于多项分布而非高斯分布来估计类别概率。在文本分类等多类别问题中,该算法尤其适用。文章详细阐述了多项分布的概念,并通过实例解释了如何估计分布参数,包括使用平滑技巧处理未出现的特征。在分类过程中,使用对数空间计算以避免数值下溢。最后,文章通过scikit-learn展示了如何实际操作多项式朴素贝叶斯分类器。
-
03.19 09:37:45发表了文章
2024-03-19 09:37:45
在16G的GPU上微调Mixtral-8x7B
Mixtral-8x7B是最好的开源llm之一。但是消费级硬件上对其进行微调也是非常具有挑战性的。因为模型需要96.8 GB内存。而微调则需要更多的内存来存储状态和训练数据。比如说80gb RAM的H100 GPU是不够的。 -
03.18 18:18:54发表了文章
2024-03-18 18:18:54
2024年3月的计算机视觉论文推荐
从去年开始,针对LLM的研究成为了大家关注的焦点。但是其实针对于计算机视觉的研究领域也在快速的发展。每周都有计算机视觉领域的创新研究,包括图像识别、视觉模型优化、生成对抗网络(gan)、图像分割、视频分析等。
-
03.17 11:01:24发表了文章
2024-03-17 11:01:24
时间序列预测的零样本学习是未来还是炒作:TimeGPT和TiDE的综合比较
最近时间序列预测预测领域的最新进展受到了各个领域(包括文本、图像和语音)成功开发基础模型的影响,例如文本(如ChatGPT)、文本到图像(如Midjourney)和文本到语音(如Eleven Labs)。这些模型的广泛采用导致了像TimeGPT[1]这样的模型的出现,这些模型利用了类似于它们在文本、图像和语音方面获得成功的方法和架构。
-
03.17 10:59:29发表了文章
2024-03-17 10:59:29
微调大型语言模型进行命名实体识别
大型语言模型的目标是理解和生成与人类语言类似的文本。它们经过大规模的训练,能够对输入的文本进行分析,并生成符合语法和语境的回复。这种模型可以用于各种任务,包括问答系统、对话机器人、文本生成、翻译等。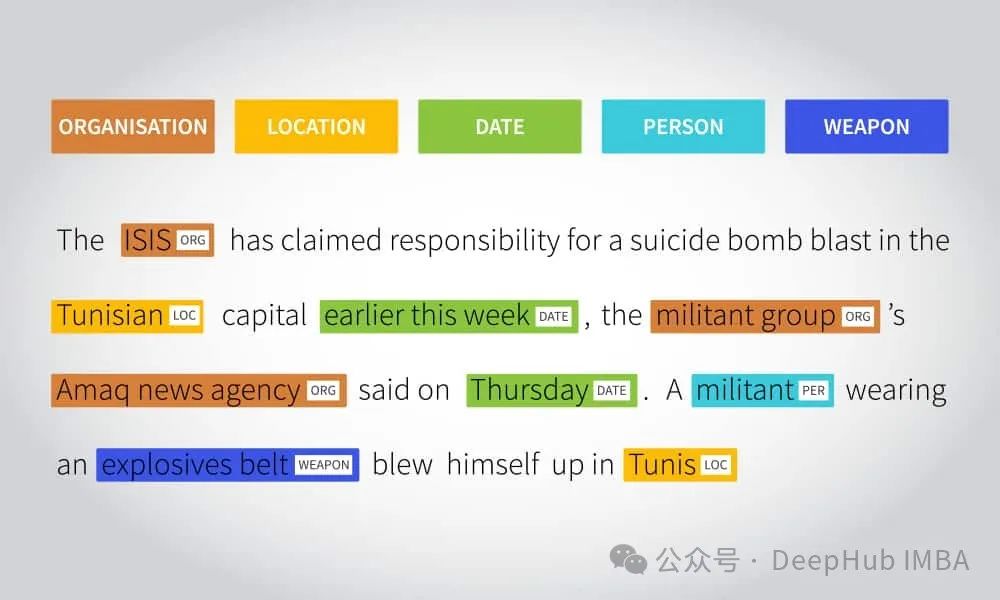
-
03.15 12:11:38发表了文章
2024-03-15 12:11:38
LoRA及其变体概述:LoRA, DoRA, AdaLoRA, Delta-LoRA
LoRA可以说是针对特定任务高效训练大型语言模型的重大突破。它被广泛应用于许多应用中。在本文中,我们将解释LoRA本身的基本概念,然后介绍一些以不同的方式改进LoRA的功能的变体,包括LoRA+、VeRA、LoRA- fa、LoRA-drop、AdaLoRA、DoRA和Delta-LoRA。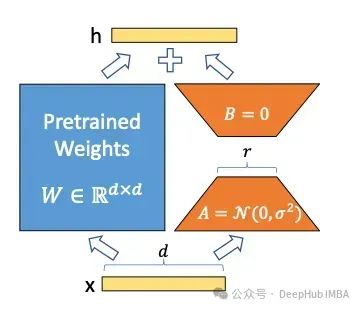
-
03.14 11:32:58发表了文章
2024-03-14 11:32:58
MADQN:多代理合作强化学习
处理单一任务是强化学习的基础,它的目标是在不确定的环境中采取最佳行动,产生相对于任务的最大长期回报。但是在多代理强化学习中,因为存在多个代理,所以代理之间的关系可以是合作的,也可以是对抗,或者两者的混合。多代理的强化学习引入了更多的复杂性,每个代理的状态不仅包括对自身的观察,还包括对其他代理位置及其活动的观察。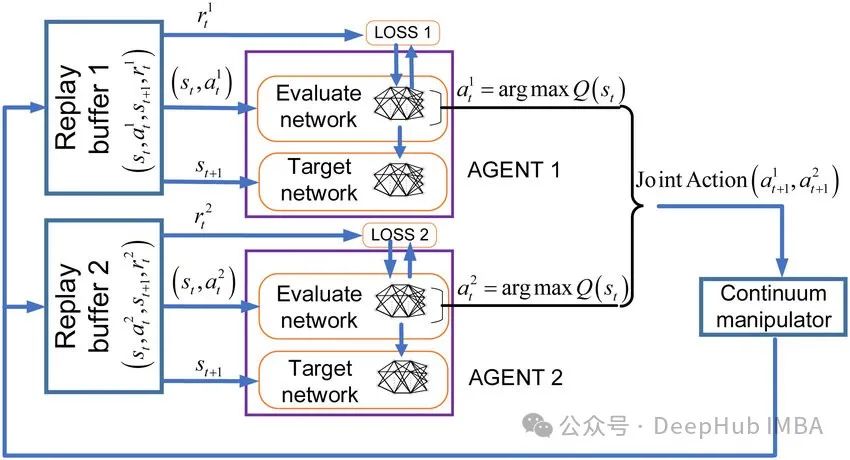
-
发表了文章
2024-05-09
论文推荐:用多词元预测法提高模型效率与速度
-
发表了文章
2024-05-08
号称能打败MLP的KAN到底行不行?数学核心原理全面解析
-
发表了文章
2024-05-07
循环编码:时间序列中周期性特征的一种常用编码方式
-
发表了文章
2024-05-06
LSTM时间序列预测中的一个常见错误以及如何修正
-
发表了文章
2024-05-05
LLM2Vec介绍和将Llama 3转换为嵌入模型代码示例
-
发表了文章
2024-05-04
BiTCN:基于卷积网络的多元时间序列预测
-
发表了文章
2024-05-03
整合文本和知识图谱嵌入提升RAG的性能
-
发表了文章
2024-05-02
Gradformer: 通过图结构归纳偏差提升自注意力机制的图Transformer
-
发表了文章
2024-05-01
10个使用NumPy就可以进行的图像处理步骤
-
发表了文章
2024-04-30
贝叶斯推理导论:如何在‘任何试验之前绝对一无所知’的情况下计算概率
-
发表了文章
2024-04-29
如何准确的估计llm推理和微调的内存消耗
-
发表了文章
2024-04-28
通过学习曲线识别过拟合和欠拟合
-
发表了文章
2024-04-27
2024年4月计算机视觉论文推荐
-
发表了文章
2024-04-26
常用的时间序列分析方法总结和代码示例
-
发表了文章
2024-04-25
开源向量数据库比较:Chroma, Milvus, Faiss,Weaviate
-
发表了文章
2024-04-24
微软Phi-3,3.8亿参数能与Mixtral 8x7B和GPT-3.5相媲美,量化后还可直接在IPhone中运行
-
发表了文章
2024-04-23
Barnes-Hut t-SNE:大规模数据的高效降维算法
-
发表了文章
2024-04-22
5种搭建LLM服务的方法和代码示例
-
发表了文章
2024-04-21
使用ORPO微调Llama 3
-
发表了文章
2024-04-20
掌握时间序列特征工程:常用特征总结与 Feature-engine 的应用
滑动查看更多
暂无更多信息
暂无更多信息