










Linux笔记01 —— Linux初识与Shell汇总(请配合另一篇《Linux笔记02》一起使用)
Linux笔记01 —— Linux初识与Shell汇总(请配合另一篇《Linux笔记02》一起使用)





Hive 拉链表详解及实例
拉链表是一种数据仓库技术,用于处理持续增长且存在时间范围内的重复数据,以节省空间。它在Hive中通过列式存储ORC实现,适用于大规模数据场景,尤其当数据在有限时间内有多种状态变化。配置涉及事务管理和表合并选项。示例中展示了如何从原始订单表创建拉链表,通过聚合操作和动态分区减少数据冗余。增量数据可通过追加到原始表然后更新拉链表来处理。提供的Java代码用于生成模拟的订单增量数据,以演示拉链表的工作流程。

Hive 优化总结
Hive优化主要涉及HDFS和MapReduce的使用。问题包括数据倾斜、操作过多和不当使用。识别倾斜可通过检查分区文件大小或执行聚合抽样。解决方案包括整体优化模型设计,如星型、雪花模型,合理分区和分桶,以及压缩。内存管理需调整mapred和yarn参数。倾斜数据处理通过选择均衡连接键、使用map join和combiner。控制Mapper和Reducer数量以避免小文件和资源浪费。减少数据规模可调整存储格式和压缩,动态或静态分区管理,以及优化CBO和执行引擎设置。其他策略包括JVM重用、本地化运算和LLAP缓存。
Hive 数仓及数仓设计方案
数仓整合企业数据,提供统一出口,用于数据治理。其特点包括面向主题集成和主要支持查询操作。数仓设计涉及需求分析(如咨询老板、运营人员和行业专家)、确定主题指标(如电商的转化率)、数据标准设定、规模与成本计算、技术选型(如Hadoop生态组件)以及数据采集和操作。设计流程涵盖从理解需求到实施SQL函数和存储过程的全过程。

Hive实战 —— 电商数据分析(全流程详解 真实数据)
关于基于小型数据的Hive数仓构建实战,目的是通过分析某零售企业的门店数据来进行业务洞察。内容涵盖了数据清洗、数据分析和Hive表的创建。项目需求包括客户画像、消费统计、资源利用率、特征人群定位和数据可视化。数据源包括Customer、Transaction、Store和Review四张表,涉及多个维度的聚合和分析,如按性别、国家统计客户、按时间段计算总收入等。项目执行需先下载数据和配置Zeppelin环境,然后通过Hive进行数据清洗、建表和分析。在建表过程中,涉及ODS、DWD、DWT、DWS和DM五层,每层都有其特定的任务和粒度。最后,通过Hive SQL进行各种业务指标的计算和分析。

Leetcode第382场周赛
```markdown 给定字符串`s`,计算按键变更次数,即使用不同键的次数,不考虑大小写差异。例如,`"aAbBcC"`变更了2次。函数`countKeyChanges`实现此功能。另外,求满足特定模式子集最大元素数,`maximumLength`函数使用`TreeMap`统计次数,枚举并构建子集,返回最大长度。最后,Alice和Bob玩鲜花游戏,Alice要赢需满足鲜花总数奇数、顺时针在[1,n]、逆时针在[1,m],返回满足条件的(x, y)对数,可通过奇偶性分类讨论求解。 ```

Leetcode第383场周赛
在LeetCode第383场周赛中,选手完成了3道题目。第一题是关于边界上的蚂蚁,蚂蚁根据非零整数数组nums的值移动,返回蚂蚁返回边界上的次数。解题方法是计算数组累加和为0的次数。第二题涉及计算网格的区域平均强度,给定一个灰度图像和阈值,返回每个像素所属区域的平均强度。解题关键在于理解相邻像素和区域定义,并计算平均强度。第三题是恢复单词初始状态的最短时间问题,通过移除前k个字符并添加k个字符,求恢复原词所需的最短时间。解题策略是检查去除前k个字符后的子串是否能作为原词的前缀。
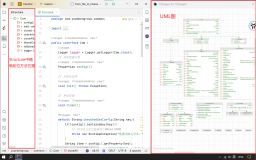
【经验分享】如何在IDEA中快速学习|审查|复习代码工程?
在IDEA中加速工程学习与审查,提升代码质量和维护性,关键操作包括:使用"Structure"浏览工程结构,通过"Find Usages"查找类、方法或变量引用,借助"Show Local Changes As UML"展示UML图。遵循从整体到局部的UML图学习,再到具体代码的详细探索,可系统理解设计理念。详情参考[IDEA UML教程](https://blog.csdn.net/weixin_44701426/article/details/124598053)。
Leetcode第123场双周赛
在LeetCode的第123场双周赛中,参赛者需解决三个问题。第一题涉及根据给定数组构建三角形并判断其类型,如等边、等腰或不等边,代码实现通过排序简化条件判断。第二题要求找出满足差值为k的好子数组的最大和,解决方案利用前缀和与哈希表提高效率。第三题则需要计算点集中满足特定条件的点对数量,解题策略是对点按坐标排序并检查点对是否满足要求。

实现HBase表和RDB表的转化(附Java源码资源)
该文介绍了如何将数据从RDB转换为HBase表,主要涉及三个来源:RDB Table、Client API和Files。文章重点讲解了RDB到HBase的转换,通过批处理思想,利用RDB接口批量导出数据并转化为`List<Put>`,然后导入HBase。目录结构包括配置文件、RDB接口及实现类、HBase接口及实现类,以及一个通用转换器接口和实现。代码中,`RDBImpl`负责从RDB读取数据并构造`Put`对象,`HBaseImpl`则负责将`Put`写入HBase表。整个过程通过配置文件`transfer.properties`管理HBase和RDB的映射关系。

【HBase入门与实战】一文搞懂HBase!
该文档介绍了HBase,一种高吞吐量的NoSQL数据库,适合处理大规模数据。HBase具备快速读写、列式存储和天然支持集群部署的特点,常用于高并发场景。NoSQL与关系型数据库的主要区别在于数据模型、查询语言和可伸缩性。HBase的物理架构包括Client、Zookeeper、HMaster和RegionServer,其中RegionServer管理数据存储。HBase的读写流程利用MemStore和Bloom Filter提高效率。此外,文档还提到了HBase的应用,如时间序列数据、消息传递和内容服务。

IDEA上的Scala环境搭建
本文指导如何搭建Scala开发环境。首先,安装Scala编译器`scala-2.12.10.msi`,通过DOS窗口验证安装成功。然后,在IDEA中,安装Scala插件,创建Maven工程,删除默认包,新建Scala源码包,并在其中创建Scala Object类。接着,配置项目结构,添加Scala SDK,确保Maven、Language Level和Compiler的bytecode版本设置正确。最后,编写并测试基本的Scala代码。
Leetcode 30天高效刷数据结构和算法 Day1 两数之和 —— 无序数组
给定一个无序整数数组和目标值,找出数组中和为目标值的两个数的下标。要求不重复且可按任意顺序返回。示例:输入nums = [2,7,11,15], target = 9,输出[0,1]。暴力解法时间复杂度O(n?),优化解法利用哈希表实现,时间复杂度O(n)。
【经验分享】Typora 设置代码块的默认语言并设置为开机启动
在Typora中设置代码块默认语言为Java(或其他语言)的自动化方法。通过下载AHK(AutoHotkey)软件,创建一个.ahk脚本,设定`Ctrl+Shift+K`快捷键触发代码块并输入指定语言。将脚本改名为.ahk扩展名并运行,确保图标出现在任务栏。要实现开机启动,使用Win+R打开"运行",输入shell:startup并粘贴.ahk文件到启动文件夹。

常用大数据组件的Web端口号总结
这是关于常用大数据组件Web端口号的总结。通过虚拟机名+端口号可访问各组件服务:Hadoop HDFS的9870,YARN的ResourceManager的8088和JobHistoryServer的19888,Zeppelin的8000,HBase的10610,Hive的10002。ZooKeeper的端口包括客户端连接的2181,服务器间通信的2888以及选举通信的3888。

【超全详解】Maven工程配置与常见问题解决指南
检查Maven配置包括验证路径、设置pom.xml与Project Structure的Java版本。基本操作有`clean-compile`、`install`和`package`,其中`install`会将jar包放入本地仓库。获取他人工程后需修改配置、清除缓存、更新依赖等。配置文件应从Maven Repository找寻,选择稳定高版本。创建Maven工程可选archetype如`quickstart`或直接创建Java工程。基本目录结构遵循分层设计原则,常见问题包括假性导包、端口占用、时区问题等,对应解决方案包括删除本地仓库文件、调整系统设置或重新加载项目。


【经验分享】如何快速转化笔记格式为标准的MarkDown格式并进行博客发布,提高生产力?
本文介绍如何将笔记转换为Markdown格式以快速发布博客。通过使用特定的Prompt和AI工具Claude 3 Sonnet,可以将Notepad++笔记转为适合CSDN博客的Markdown格式。转换要求包括:正确标记代码段、调整缩进和格式、使用Markdown标题、列表、链接和图片语法。Claude 3 Sonnet能有效处理格式转换,将转换后的Markdown内容复制到编辑器,即可便捷发布博客。

【简单无脑】自动化脚本一键安装虚拟机下的MySQL服务
该文章提供了在虚拟机上安装MySQL服务的简化方法,特别是针对新手。作者提供了一个自动化脚本`install_mysql.sh`,使得安装过程更简单。用户需要下载`install.rpm`资源,将其放在指定目录下,然后创建并编辑脚本文件,将提供的代码粘贴进去,通过`chmod u+x`授权,最后运行脚本`./install_mysql.sh [rpm文件路径]`来安装MySQL。文章还附有相关图片说明。

何时需要指定泛型:Scala编程指南
本文是Scala编程指南,介绍了何时需要指定泛型类型参数。泛型提供代码重用和类型安全性,但在编译器无法推断类型、需要提高代码清晰度、调用泛型方法或创建泛型集合时,应明确指定类型参数。通过示例展示了泛型在避免类型错误和增强编译时检查方面的作用,强调了理解泛型使用时机对编写高效Scala代码的重要性。

【科研入门】搭建与配置云服务器的论文环境
本文介绍了如何搭建云服务器并配置论文代码环境,以AutoDL平台为例。首先,租用服务器并选择符合代码需求的镜像版本,如Python 3.7、TensorFlow 1.15和PyTorch。接着,启动服务器进入终端,克隆项目代码并使用Conda创建隔离的环境安装所需包。如果需在Pycharm中工作,还需在Pycharm内创建相同环境。最后,根据项目配置安装Tensorflow和PyTorch,遇到缺失包时通过`pip install`补充。完成配置后,可克隆服务器以备后续使用。遇到版本不兼容问题,可调整Conda环境的Python版本。

解决Pycharm安装后无法导入库的问题
解决Pycharm导入库问题:进入Settings,选择Project的`Python Interpreter`,点击Add Interpreter。删除`.venv`文件夹内容,然后关闭并重启Pycharm以初始化新环境,现在可以正常导入库了。


Scala 02——Scala OOP
Scala 是一种纯粹的面向对象编程(OOP)语言,它不支持基本类型,所有数据都作为对象处理,即使在JVM上运行也会自动处理拆装箱。Scala 不包含静态关键字,其“静态”概念体现在类型系统和单例对象中,类型检查都在编译时完成。类型推断、类型预定和动静结合是其特点,例如,Scala 支持协变和逆变,使得泛型编程更加灵活。此外,Scala 的类、继承、抽象类、单例对象和泛型等特性提供了丰富的编程模型。例如,单例对象可以看作静态成员的替代品,同时具备惰性初始化和与类的绑定关系。

Spark安装教程
该教程详细介绍了在Linux环境下安装Spark 3.1.2的步骤。首先,检查JDK版本需为1.8。接着,下载Spark资源并设置环境变量`SPARK_HOME`。配置`spark-env.sh`和`yarn-site.xml`文件,禁用内存检查。然后,重启Hadoop集群,启动Spark集群,并通过`jps -ml`检查Spark Master和Worker。可以通过Web UI访问Spark状态,并使用`spark-shell`测试Scala交互环境及Spark on Yarn。最后,学习如何关闭Spark集群。

ZooKeeper详解
ZooKeeper是大数据组件中的协调器,确保高可用性和一致性。它用于监控主备节点切换(如Hadoop YARN的ResourceManager,HBase的RegionServer,Spark的Master)并实现数据同步。设计基于文件系统和通知机制,通过Znodes的状态变化(创建、删除、更新、子节点变化)进行协调。ZooKeeper使用观察者模式,当Znode变化时,通知客户端。其数据结构为树形,提供CLI工具如`zkCli.sh`进行交互。ZooKeeper有三个默认端口:2181(客户端连接),2888(服务器间同步),3888(选举)。选举采用半数机制,确保集群稳定性。

Scala应用 —— JDBC的创建
这篇文章介绍了如何使用Scala实现JDBC连接。首先,通过在pom.xml添加MySQL JDBC驱动依赖,然后使用`Class.forName()`加载驱动,接着创建连接对象。初始化执行器涉及创建执行器对象和设置参数。执行操作时,根据DML(数据修改语言)和DQL(数据查询语言)返回不同结果。文章提出了一个柯里化的`jdbc`函数,以处理不同操作步骤和多类型结果。结果类型通过枚举和抽象类`Three`的子类来表示,包括异常、DML影响行数和DQL查询结果。最后,展示了`jdbc`方法的实现,以及如何处理结果并转换为具体对象。代码示例中,查询结果被转换为`Test`对象数组并打印。

MySQL常见问题解决和自动化安装脚本
这篇内容包含了两个主要部分:解决MySQL登录问题和处理GPG密钥问题。当MySQL密码正确但无法登录时,可以通过执行SQL命令`ALTER USER`和`flush privileges`来修改和重置密码。对于MySQL安装时的GPG密钥错误,首先需要强制删除旧的MySQL仓库包,导入新的GPG公钥,然后安装MySQL服务器。如果遇到GPG检查错误,可以使用`--nogpgcheck`参数忽略检查来安装。最后,提供了一个自动化安装MySQL的脚本,用于检查旧版本、卸载残留、安装MySQL8并启动服务。

Scala 04 —— Scala Puzzle 拓展
Scala 程序设计探讨了占位符、模式匹配、继承中的成员声明、默认值与重载以及集合操作的一致性。示例展示了 `_` 占位符在函数简洁性上的应用,同时指出它不等同于箭头函数,因为函数体内的副作用可能不同。另外,解释了变量与常量模式,以及在继承中字段初始化的顺序。在集合操作中,`for`循环与`map`的区别在于`for`会过滤不符合模式的元素,而`map`则会引发错误。最后,讨论了如何确保集合类型在操作中保持一致。

【科研入门】评价指标AUC原理及实践
该文介绍了二分类问题的评估指标,特别是AUC的概念和重要性。文章首先讲解了混淆矩阵,包括TP、FP、FN和TN的含义,然后讨论了准确率、精确率和召回率,并指出它们在处理不平衡数据集时的局限性。接着,作者解释了阈值对分类结果的影响以及如何通过调整阈值平衡精确率和召回率。最后,文章重点介绍了ROC曲线和AUC,说明AUC作为衡量模型性能的无参数指标,其值越接近1表示模型性能越好。AUC可以通过计算ROC曲线下的面积或比较样本对的预测得分来求得。

Scala01 —— Scala基础
Scala 是一种基于 JVM 的多范式编程语言,它融合了面向对象和函数式编程的特点。本文档介绍了Scala的基础知识,包括如何搭建开发环境、语言特性、变量和数据类型、程序逻辑、运算符、控制流、集合以及方法和函数的使用。特别强调了Scala集合的重要性,它们作为数据结构支持多种操作,并且有许多内置的算子和库来解决问题。文档还涵盖了如何在IDEA中配置Scala SDK,以及如何使用元组、映射、数组和模式匹配等核心概念。此外,文档还讨论了Scala与Java变量的区别,以及如何通过隐式类和字符串插值等扩展语言功能。

Scala 05 —— 函数式编程底层逻辑
Scala讲座探讨了函数式编程的底层逻辑,强调无副作用和确定性。函数式编程的核心是纯函数,避免读写数据等副作用,将其移至代码边缘处理。函数输入输出应清晰定义,避免模糊参数。函数视为数据范畴间的映射,以范畴论为基础。业务逻辑转化为纯函数式,通过声明式编程实现解耦,关注输入输出而非过程,便于验证和自动编程。将业务逻辑视作流水线,每个函数处理数据,避免全局变量和`var`,优先确保正确性再优化效率。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
