
1. 企业为什么需要向量数据库?
在AIGC时代,企业需要向量数据库扮演什么样的角色?首先看下向量数据库和 LLM的分层,最底下是一个通用大语言模型层,它能回答的问题是一些通用的问题。比如说你让它回答零售的定义是什么,它能够很清晰的告诉你这个答案。
再往上面一层是行业模型,它是模型提供商为行业专门定制的一些行业的大语言模型,比如说它可以对金融、安全或者零售行业去定制一些大语言模型,它会把一些特定的行业知识的语料去喂给这个模型来加强训练。举个例子,行业模型能回答这样的问题,比如说零售行业的具体业务流程是什么,它能够回答得非常精确,这个是普通的大语言模型没法回答的。
在行业模型上面就会进到了企业它自己私有模型的领域,企业私有的模型它也分为两层。第一层是企业专属模型,它是企业通过在行业模型基础之上,用自己的专有的内部知识去 fine-tune 的结果。它能回答的一个问题是,比如说,我们公司的主售的是一些什么样的一些产品。但是 fine-tune 有一个问题,就是 fine-tune 的代价其实是非常高的,并且每一次 fine-tune 的时间比较久,企业无法经常去做这个事情,因为它的 cost 非常高。
在大数据规模爆炸的时代背景下,企业数据知识源源不断地流入,所以这种场景下我们就需要第四层,也就是企业的一个专属知识库,这个专属知识库通常是由向量数据库来实现的,通过向量数据库,它能回答的问题是,比如我们公司最近三天被搜索得最多的产品是什么?以及我们公司最近卖得最火的产品是什么?它有实时性这样一个特性。很多时候你也可以用向量数据库这一层去修正大语言模型的幻觉问题。

这里我举一个具体的例子,在向量数据库增强的场景下,我们是怎么利用向量数据库加大语言模型去做一个智能问答的服务。
大家首先看下面这一部分,下面这一部分讲的是整个数据的导入流程,包括说我们有文档,然后文档进行了切片,切片好以后调用 embeddings 的算法去产生 embeddings,然后把原始内容加上它embeddings后的向量一起存入向量数据库。
当我要进行搜索的时候,因为有可能是个多轮对话的过程,所以我会把过往的聊天的记录加上新问的这个问题,一起扔给 LLM,然后 LLM 会给出一个 summarize 后的一个独立的一个长问题,然后我再拿这个长问题去给它做 embedding,之后到向量数据库里面去搜索,那这样的话我们就会实时搜索出的这个跟这个问题最相关的这些知识的块,然后我再把这个知识的块结合独立问题 (知识块通常是通过 prompt 的这种形式结合独立的问题)投递给 LLM,这时 LLM 就能够给出解答,这个解答其实是包括向量数据库里面存储的这些实时知识的。

2. 阿里云AnalyticDB向量引擎核心技术解密
接下来我们来看一下我们怎么样去实现一个向量数据库。首先介绍一些基础知识,向量数据库要干的到底是个什么事情?其实本质上就是给定一条向量,我们要搜索离它最近的 k 条向量,那最近的这个距离的定义可以是,比如说,内积或者欧氏距离,或者余弦距离。有了距离的定义以后,我们还要定义一些向量的搜索算法。
向量搜索算法总体来说分为两类,第一类就是精准的搜索,比如说像 FLAT,一个向量一个向量地去检索,然后取 top k,召回率会很高,但是它的执行的性能会比较差,因为你要做全局的扫描。大家熟悉的 KD tree 也是这个范畴,就是你能找到最精准的 top k,属于 KNN 算法。
第二类是 approximate nearest neighbor,就是 ANN,那这类算法它可能回答的并不是最精准的 top k 的这些向量,但是这一类算法它的好处是执行效率会比较高。
比如说像 IVF,本质上它把所有的向量扔入到一个向量空间里面去,然后这个向量的空间你可以用 k means 的算法去找出一些中心的点,然后你把所有的向量都归于离它最近的这个中心点,最后当做搜索的时候,其实你只要找到这个中心点,然后在这个中心点的这个小空间里面去搜索 top k 就可以了。当然有可能出现的一些情况是,离你最近的这些点,它并不在同一个所属 k means 的这个中心的空间里面,这时候你可能要扩展一下,去额外找一些相邻的空间,但大体思路上是这样的。
除了 IVF 之外,ANN 中还有一类就是基于树的算法,比如 ANNOY 这个算法,这个是 Spotify 提出的一个算法,本质上它跟这个 IVF 也比较类似,就是你把空间给不断地去切分,然后不断地二分,直到二分到最后一层的树的叶子节点上,它只有少于 k 个向量,这时候构建过程就停止了。基于树的算法也有和 IVF 有同样的问题,就是有可能当你搜索的时候,最后找到那个叶子节点里面并不包含你所需要的所有的这些 top k 的节点,那这个时候你也可以采用一些比如说像加入优先级队列,然后辅助构建一些森林的这些方式,多构建一些树,来达到更好的召回率。
ANN 中的最后一类是图的算法,它其实就是大家都比较熟悉的 NSW 的算法以及 HNSW 的算法。HNSW 其实就是在 NSW 上做多个 NSW 的叠加。那这个 HNSW 我接下来会详细地讲,因为我们实测下来,HNSW 无论是从高维向量的执行效率也好,或者召回率也好,都是比较优秀的。所以我们选择 HNSW 作为我们 AnalyticDB 默认的向量检索的算法。

2.1 HNSW向量检索算法
首先讲一下 NSW 的搜索和插入算法的实现,这里我写了一段伪代码,它其实非常简单,就是你随机选一个节点,然后把它扔入一个优先级队列里面,用来bootstrap。
然后你不断地从这个优先级队列里面去拿节点。然后去看如果说它离你要搜索的节点的距离已经大于所有你已知的这些答案的距离的时候,这时候就做一个贪心的裁剪,不继续搜索下去了。否则的话,我会把它的所有的邻居都标记成已经访问过,并且也加入到这个 candidate 的优先级队列里面去,并且把它们也都加到结果集里面去。 当我完成这个步骤的时候,要么我是把所有的节点都访问过或者裁剪掉了,要么是我达到了规定的访问的节点的个数上限,那这时算法就返回,这样的话我就得到了离这个节点最近的近似的 k 个节点。插入的流程也非常简单,插入的时候其实就是运行一遍找离它最近的 k 个节点的算法,然后跟它们都建立连接就可以了。
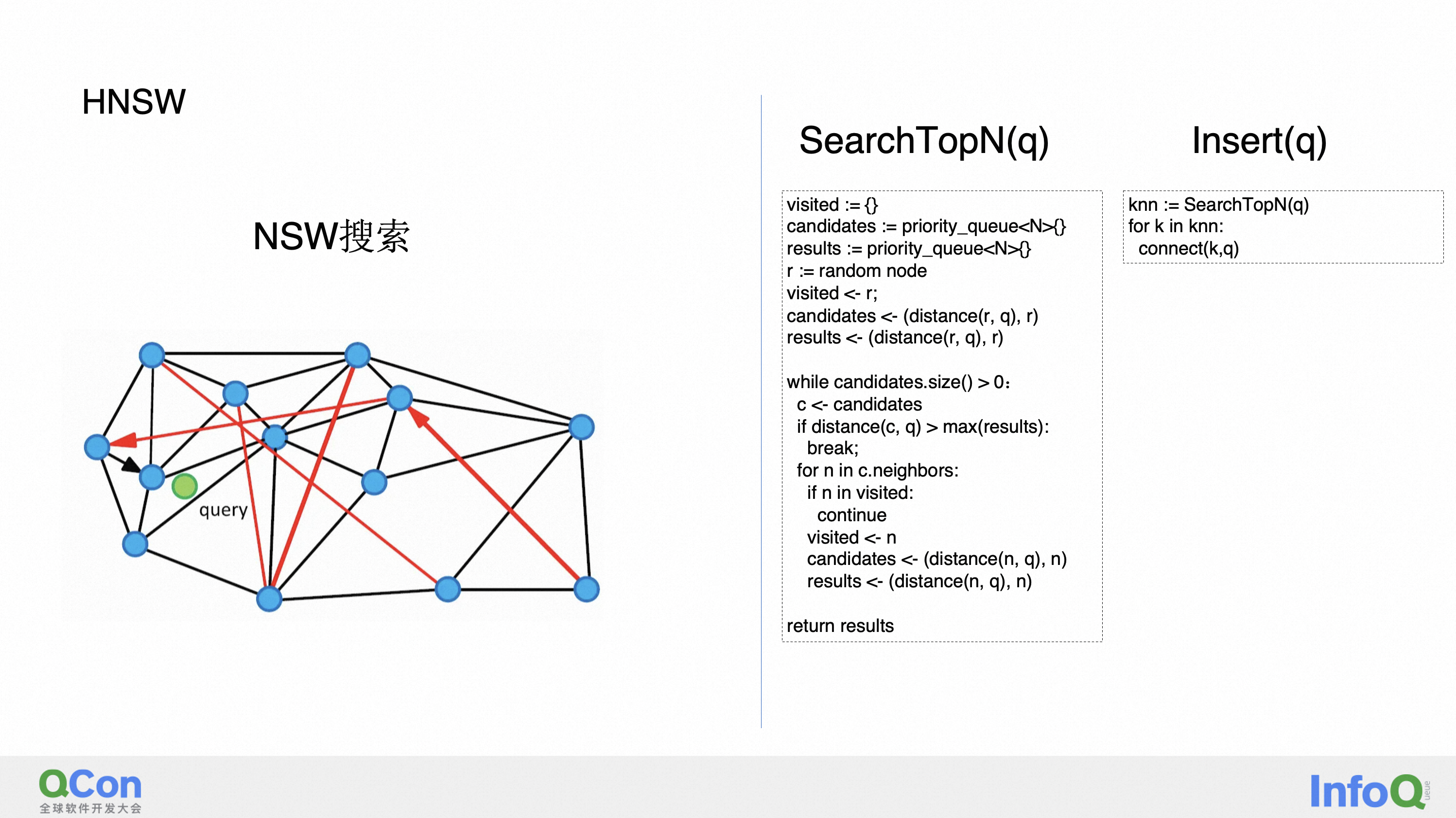
HNSW 本质上是在 NSW 上做一个阶层的叠加,它本质上其实就是一个类似于 skip list 的数据结构,它能通过上面的那些层去加速进到离查询节点最近的那个点的步骤。那具体它是怎么做的?搜索的时候其实非常简单,在搜索的时候我只需要从最顶上开始搜索,然后每一个都搜索离它最近的节点,直到倒数第二层。然后到了倒数第二层之后,就通过那个节点作为最后一层的起始节点,然后在最后一层的这个节点开始去进行 NSW 的查询,具体就是用到前面一页 PPT 讲的那个搜索方法。
那插入的时候它是怎么做的?插入的时候还有些不一样,因为像 skip list 这种数据结构,插入的时候你必须要保证就是我要把这个节点在最底下的 lc 层都插入。这种情况下本质上我相当于是先掷一个硬币,由这个硬币的结果来决定要插入到最高的是哪一层。具体插入的时候,对于上面从最顶层到要插入的这一层的上面一层,算法仍然是一样的,就是找到离它最近的节点,然后从要插入这一层到最底层开始,对于每一层我都会去找它的这个离它最近的 top n 个,那这里跟前面的 NSW 算法不同的是我们多加了称之为 SelectNeighbors 的这个函数。
这个函数的作用是做一些 heuristic 的,也就是启发式的搜索。那引入它是为了避免一个什么问题?它是为了避免就是如这个图所示的,形成的两个 cluster 的孤岛。我们希望这个 HNSW 的图里面这两个 cluster 是连接起来的。那这个时候它采用的算法是什么呢?假如有某一个候选节点,我计算离这个节点到目标节点的距离,那它已经比到之前的某一个添加的节点的距离是更远的话,那我就跳过暂时跳过这个节点,因为这个节点也可以通过那个节点来相连。所以如果你用常规算法的话,这里面的所有的节点都会被加到我的 candidate 里面去,但是如果你用刚才我说的那个算法的话,会跳过一些节点,那这样的话这个比较远的另一个 cluster 的节点它就有机会被加进去,因为对于它来说,它离这个绿色节点的距离比它离其他已经加进去的这些节点距离都要近,所以这个节点会被加入,部分概率上解决了孤岛的问题。

2.2 向量存储设计
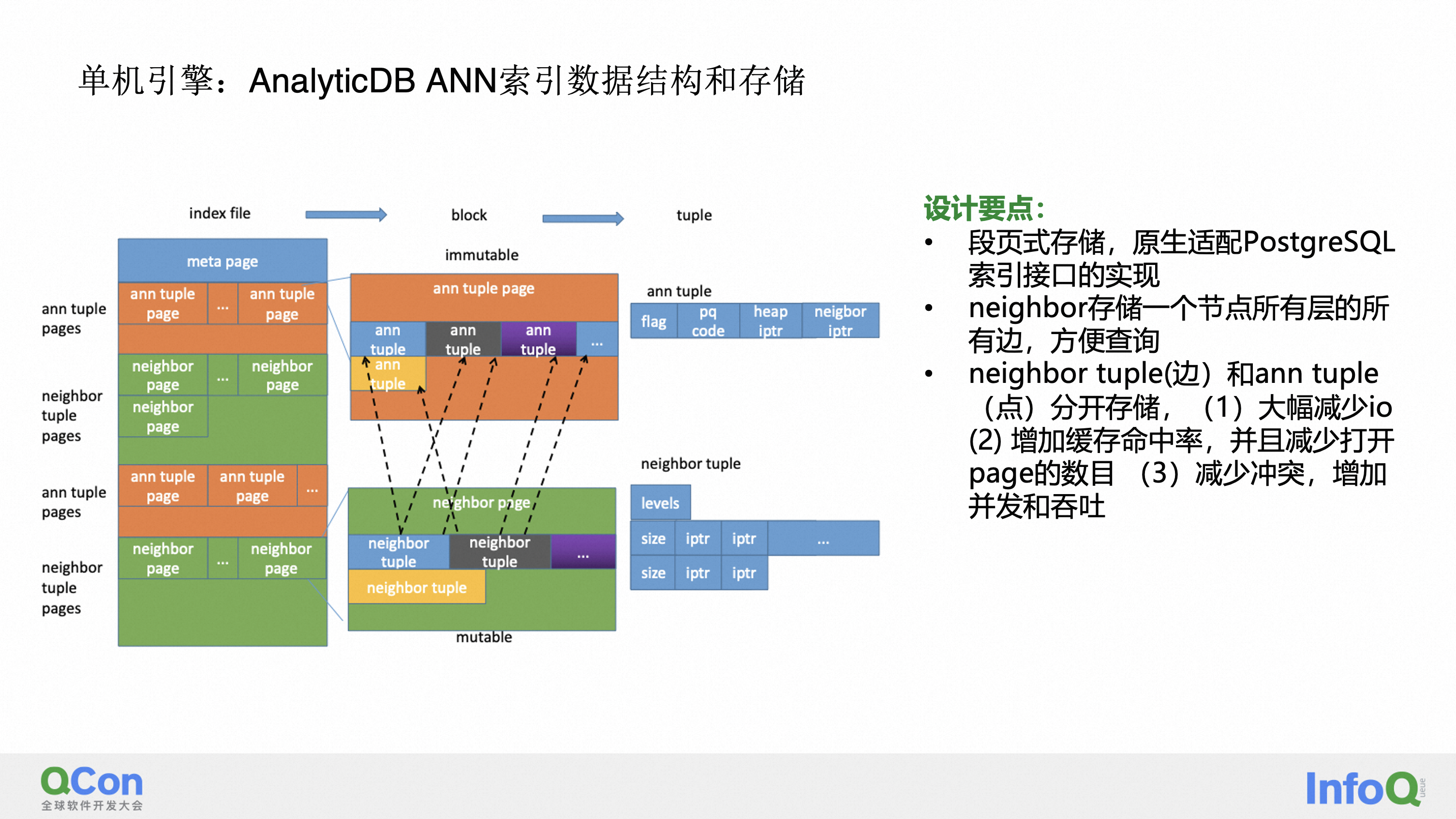
有了刚才介绍的算法之后,我们还需要有一个数据结构以及一个存储方式,去实现向量数据库。大家知道我们 AnalyticDB for PostgreSQL 是基于 PostgreSQL 来改造的,它原生支持 PostgreSQL 的索引接口, PostgreSQL 提供了一个可插拔的索引结构,在这种情况下,我们采取了这种段页式的存储方式,我们把刚才的这个 HNSW 的点和边都分开来进行存储,点它自己有自己的 page,边也有自己的 page,每一个边的 page 是包含了这个点在所有层的以这个点为初始节点的这些边,这样的话方便对所有边进行查询。那之所以我们把点和边分开来存储,它有几个好处:
第一个是说它能很大程度地去节省IO,这是为什么?因为我在搜索的时候我有可能搜到这个点,但是我计算距离以后,我发现这个点不符合过滤的条件,我把它裁剪掉了。那如果采用的是点和边合起来存储的话,相当于是把整个这个节点的边也顺带都读出来了,那这其实是没有意义的,所以说这种做法减少了IO。
第二个是说点和边分开存储,因为点的数据量会比边少很多,这种情况下基本上所有的点的 page 都可以 cache 在内存里面,减少打开 page 的数目。
第三,大家知道为了处理并发的场景,我们对所有的点和边的访问,它都是要加锁的,以 page 为粒度进行加锁,那点和边分开来存储的时候可以减少冲突,增加整个系统的并发量和吞吐。
2.3 高维查询性能优化
有了这个磁盘上的数据结构,再加上刚才描述的算法,我们其实已经有了一个可以跑起来的这样一个向量数据库。但我们在线上运行的时候,发现它有一个问题,它的执行效率并不是很高,尤其是我们碰到了就是现在 AIGC 这种,因为 AIGC 场景下面它都是非常高维度的这些向量,比如说像类似 1536 维的这种向量,那这种情况下它其实执行就比较耗费时间。所以我们做了一个优化,相当于把每一个向量都进行了一个降维,进行了一个编码,称之为 PQ 编码。
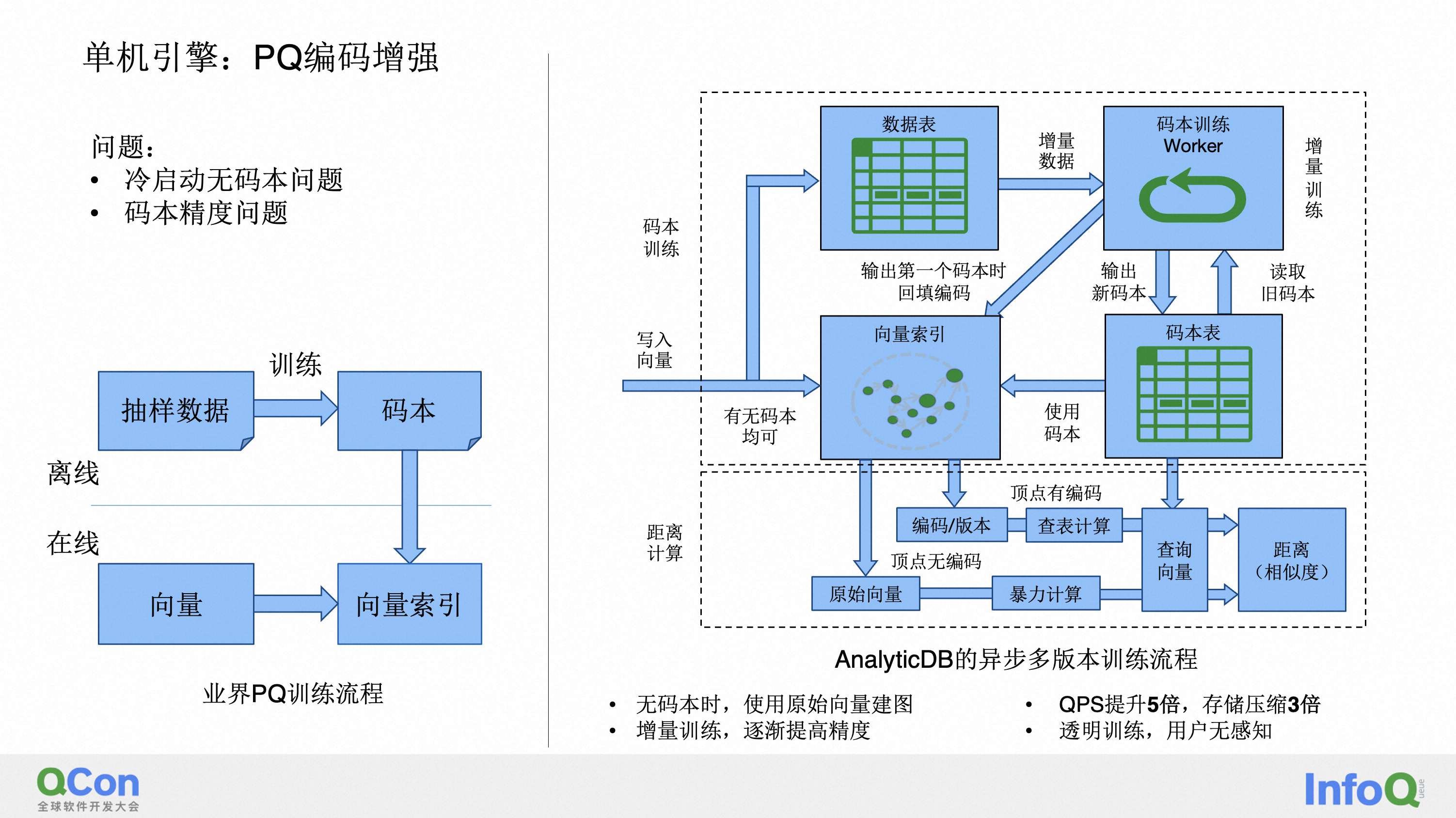
那具体 PQ 是什么意思?它其实理念上非常简单,就是你有一个向量,然后你把它切成 m 块,然后对于每一块你对所有的向量都去做一个 k means,做完之后你去用它归属的离它最近的 k means 节点来替代这个向量的这一部分,然后你对向量的每一部分都做这个操作,那这样的话其实相当于你是把整个向量的维度和精度给减少了。在这种场景下做计算的时候,耗费的 CPU 也少了,整体速度会快很多。并且因为存储的向量的长度也会减少,所以总存储 size 也会减少。但这里其实有一个是鸡和蛋的一个问题,业界的 PQ 码本的训练,其实是用离线的数据去训练好之后,才能够说去做编码。
但是我们作为一个实时的数仓,它的数据都是实时导入的,有可能用户他数据进来的时候,我里面一条数据都没有,所以我们怎么去解决这个先有鸡先有蛋的这个问题?我们采取了一种增量的方式,也就是当你没有任何数据的时候,我们用的是原始的这个向量来进行计算。当达到一个阈值,比如说有 10 万条数据的时候,那我在后台会起一个进程,然后去对这个 10 万条数据去进行码本的计算。当算完这个码本之后,会逐渐地去回填已经写进来的这些向量的数据,与此同时新写进来的这个向量数据也可以用新训练的码本来进行编码。然后我刚刚描述的这个过程,它其实是一个迭代式的过程,也就是说你 10 万条的时候,你可以做这个操作,然后你 30 万条的时候,当你数据的分布变的时候,你可以再进行一次这样的操作,来提升精度,然后比如说 100 万条的时候,当你数据分布已经比较稳定的时候,你还可以再做一次这样的操作。这个的好处是它的精度其实是不断的在提升的,并且这个训练的过程当中,用户是无感的,对查询和写入都是无感的。那我们做了这个优化之后,达到了 QPS 提升 5 倍的效果,并且存储大小压缩到原来的 1/ 3。
2.4 CRUD事务处理
这里再介绍一下删除的实现。大家都知道其实市面上很多的向量数据库它是不支持删除的,但是我们的向量数据库是支持删除的,一个主要的原因是我们是个实时的数据库,所以用户他可以随意地去对它的数据进行删除。
为了减少用户感知的删除延迟,在删除的时候,第一步我们仅仅是去标记删除这个图上的节点,然后标记删除完之后,其实用户的删除操作就返回了。因为用户越删数据他标记删除的点会越积越多,我们不可能永远带着这些点的图去做搜寻。所以定期的当标记删除的点达到一定数目的时候,我们也会起一个后台的进程去做清理的操作。
那第 二、三、四步的操作它要做的是什么?它要做的是首先它会遍历这个图,然后找到所有指向被删除节点的这些边,然后删除这些边,删除这些边以后,就可以正常地去删除这个节点了。但删除完这个节点以后,大家可以看到这个图是有一定的问题的。因为在建 HNSW 索引的时候,我们其实是尽量保证这个图是具备连通性的,但是当你删除完之后,这个图可能就变成两个孤岛这样的样子,那它会对我们的召回率造成影响。这种情况下面我们会进行第四步,它其实是一个补边的过程,就是我们会用一定的算法,如果探测到这个点的入度边或出度边并不是很充足的情况下,会进行一个补边的操作,让它和其他的这个被删节点的周围的边去连接起来,去修复整个图的这个连通性。

2.5 并发查询吞吐优化
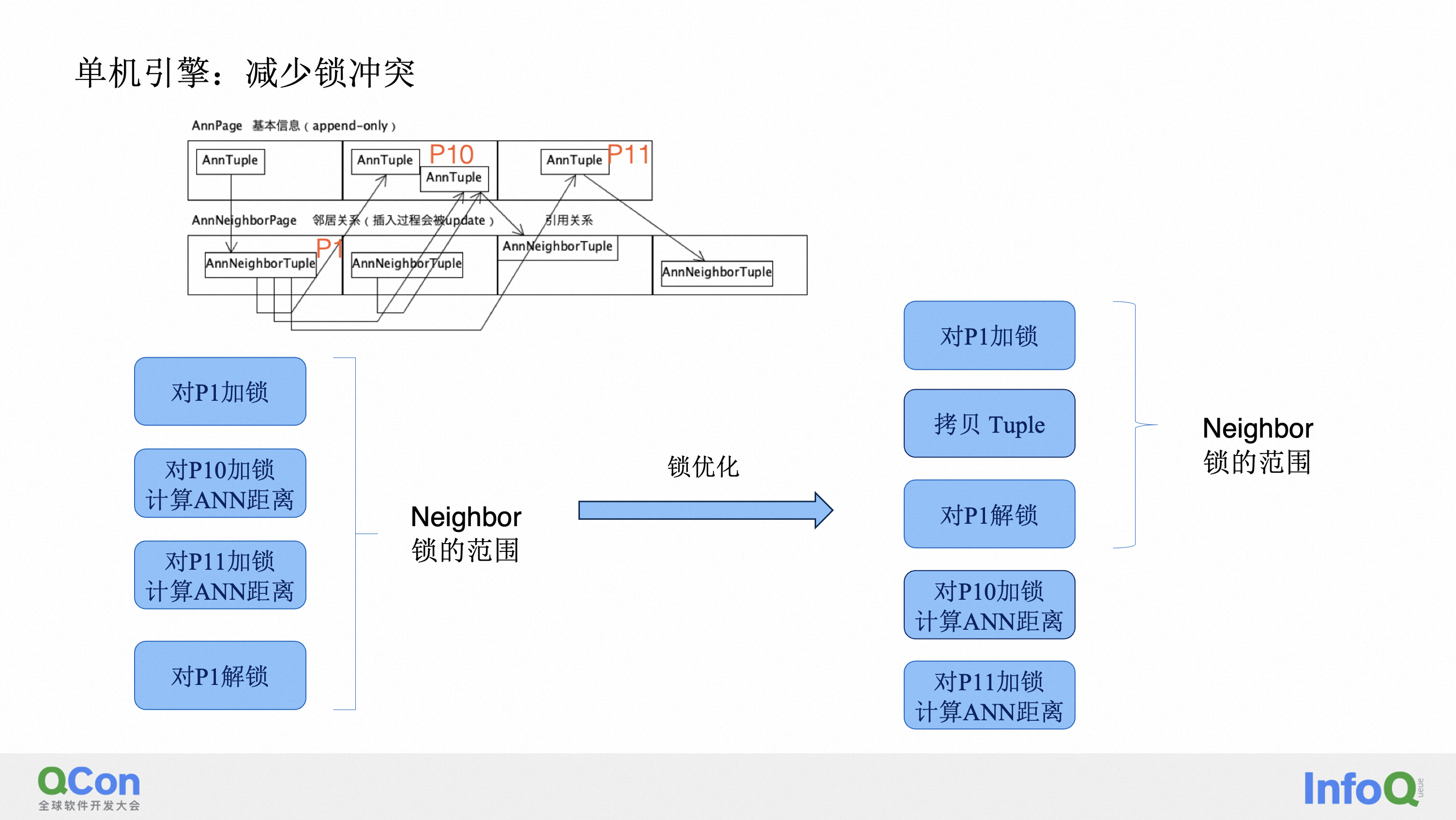
这里再给大家讲一下我们做的一个优化,当然其实我们是做了非常多的优化,今天主要讲我们做的其中的一个优化:减少锁的冲突。那大家知道我做在做这个 HNSW 算法的时候,其实为了保证并发的正确性,是会对这些 page 加锁的。如果直接去实现的话,可能说你对这个 page1 进行一个加锁的操作,那加完锁之后要去找它的相邻边,然后会对这个 page10 和 page11 也去加锁,并且只有计算完之后你才会对 page1 解锁,这里虽然我才画了两个点,但其实这个 page 里面可能有很多很多的点是需要去计算的。然后第二个是可能这里要访问的 page 也非常非常多,这样的加锁方式会导致整个系统的吞吐会下降,因为其他的查询并发可能要等锁。为了缓解这个问题,我们做的操作其实也非常简单,就是说对 page1 加锁之后,把要计算的 tuple 给拷贝出来,然后再解锁,带着无锁的 tuple 去计算向量的距离。对于写写冲突的这种,我们也会做一个 optimistic 的检测来保证写写冲突不会造成写丢失。
2.6 数据分区并行处理
这里再来介绍下分区的并发执行。那大家都知道我们的数据库它是可以分为分区的,比如说有时间的分区,这种情况下,对于每个分区都有一个 HNSW 的索引,每一个索引我都会去取这个 top k 乘以一个放大系数。这个之所以有这个放大系数 (即使不是分区表,我们也会有放大系数),是因为刚才做了这个 PQ 的编码以后,其实会降低它的召回率,所以我要乘以一个放大系数去来就是补充损失的精度。本质上每个分区都是线程的并发去执行,然后执行完之后会首先每个分区都取 top k 乘以这个放大系数。然后第二步会做一个归并的排序,这里所有的归并排序用的是真实的向量距离,所以是一个精排的过程。通过这步我们加速了分区表的 ANN 向量检索的效率。

2.7 分布式架构实现
刚刚讲的都是我们在单机上怎么去实现一个向量引擎,以及在单机上怎么去做一个优化。大家都知道我们 AnalyticDB 是一个分布式的系统,所以它天然地把分布式的这个能力也带入了整个向量数据库里面,AnalyticDB是一个 MPP 的架构,就是数据是通过哈希分片的,通过对我们的分布键去做哈希,会决定每条数据是进到了哪个节点上面。
所以这里的并发力粒度有两个,第一个是节点级别的并发粒度,然后第二个是说在节点内的分区级的并发粒度,所以是节点乘以分区的并发。并且我们为了保证高可靠和高可用的场景,可以认为每个节点上面的 shard 我们都是有主备的,主和被之间是通过 write ahead log 去做同步,所以数据其实我们是存了两份,保证了高可靠。然后当主挂掉宕机的时候,我们会有一个检测系统会自动地把它切到备,整个过程在十秒内完成,所以我们也通过这个架构做到了高可用。最后,除了刚才说的那些距离计算的方法之外,我们也支持集成算法厂商自研的这些距离算法,这些算法通过距离的插件也能够集成到我们的向量数据库里面。
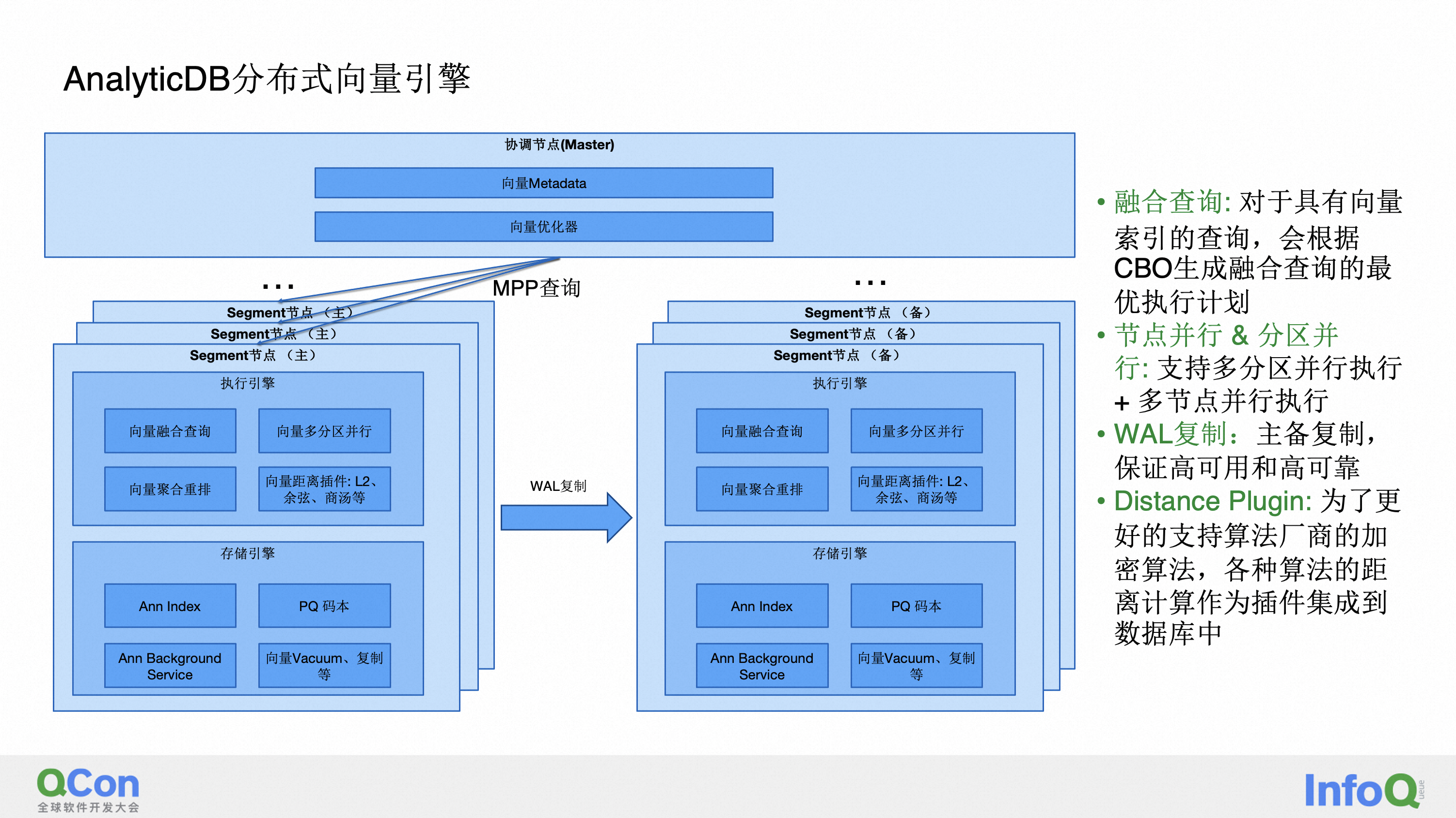
2.8 多模数据融合分析
那下面我详细地讲一下融合查询,融合查询它要解决的是一个什么问题?我们的理念一直是一套数据系统里面,同时去解决结构化和非结构化数据的查询,那我一条 SQL 其实可以同时查向量、并且同时做结构化数据的 filter 等。融合查询要解决的问题就是用尽量高效的执行方式去完成这个SQL的执行。
第一,我们通过 CBO 去 决定选择下面四条路径的哪一条。
第二,HNSW 的 scan 的算子,它具备能够把 filter 或者说 bitmap 给下推到它上面去执行的这个能力。那具体是什么意思?假如说我有一个查询条件,我是查向量的 top k,并且说我有另外一个结构化的 field,比如说满足过滤条件大于 3 或者小于 5 这种,那我会通过我的优化器首先去决定这个结构化数据的筛选率是不是很高。如果说它筛选率非常低的话,也就是说只会筛出几条结构化的数据,那我的执行方式非常简单,就先把这些数据全都取出来,然后对于取出来的这些数据,再进行向量的暴力扫描,这种方式是最高效的。那如果说优化器告诉我它的筛选率并没有那么低,那我会首先执行一个 bitmap 的 index scan,去先过滤这个结构化的这些数据,然后我再把这个 bitmap 给推到我的向量索引里面去执行。
第三,如果说我的筛选率再高一点的话,可能我的 bitmap 都非常大了,那这个时候把整个计算的表达式去推给这个 HNSW scan算子。
第四个场景,是整个 filter 基本上没有起到什么过滤的效果,那这种情况下肯定是先计算 HNSW,然后再 filter,因为这个 filter 它也 filter 不了多少条数据。那大家有可能会问,为什么我不直接就是一直去执行第四个流程呢?这个缺点就是说我有可能 HNSW 算了 top k 条,但是这 top k 条的数据它都是不符合那个 filter 的条件的,那就导致最后会出很少条的数据,不符合用户的查询需求。

3. AIGC应用落地实践
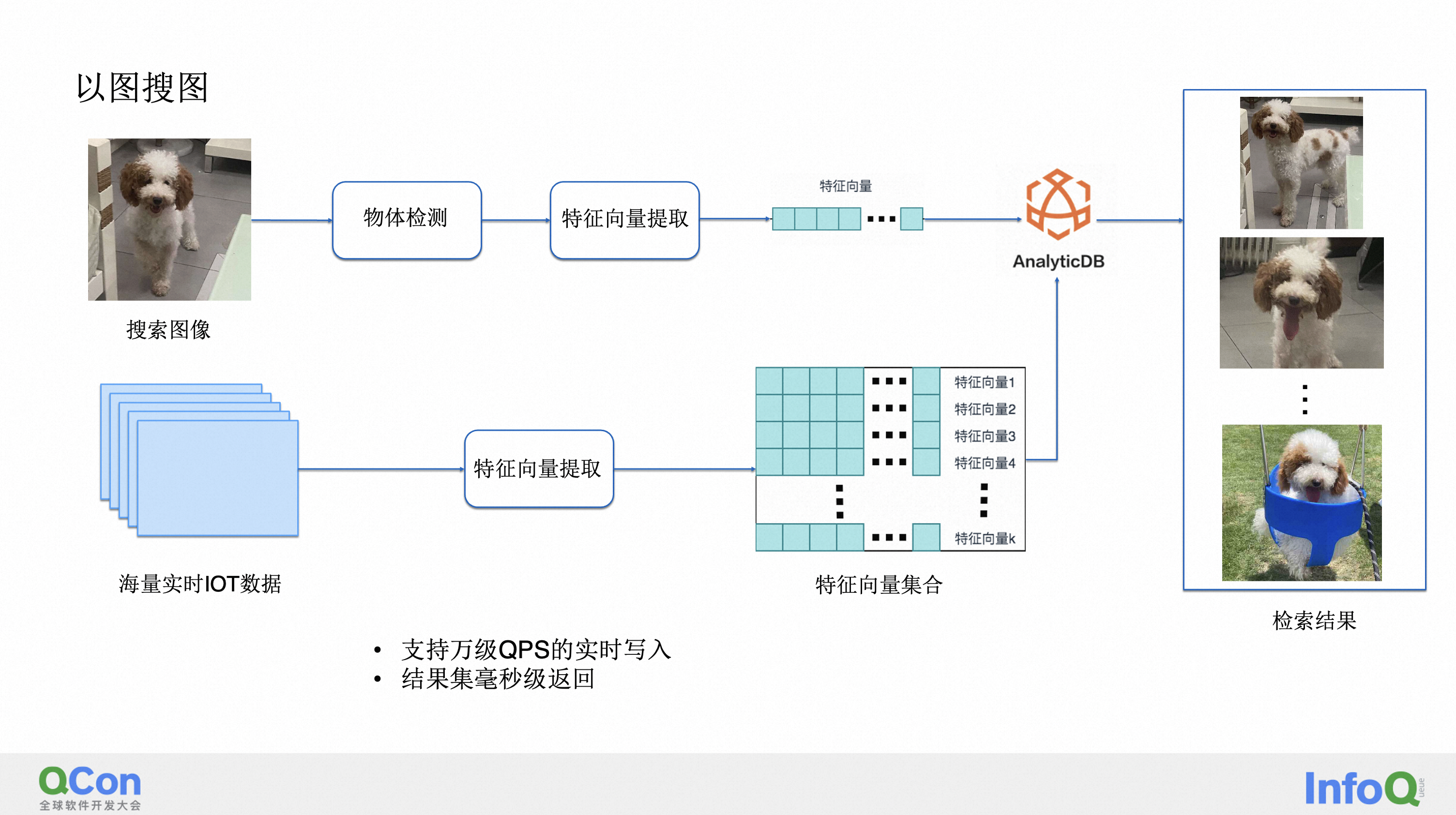
3.1 构建高并发的以图搜图系统
第四部分我来带大家一起看一下,我们具体的一些线上的案例。那第一个案例它其实是一个纯向量检索的以图搜图的这样一个过程。那这里为了脱敏,我其实用的是我家的狗 (它的名字叫史努比)的一张照片,但其实大家可以想象,假如是想要查车牌,或者查人脸的话也是相同的效果,那这里的场景是什么?假如说我有很多 IoT 的设备,它一直在拍照。然后它一直会把这个照片给实时地传到向量数据库里面。那当有一天假如说我的狗丢失了,我想知道我的这条狗它在什么地方。我会把狗的照片给放进向量数据库去搜索,这些相似的照片会在我的整个向量数据库里面以毫秒级的这个速度快速找到。那所以这里想表达的是,第一,我们这个向量数据库是支持万级 QPS 的实时写入的这样一个能力。然后第二,每个查询都可以以毫秒的延迟返回结果。
3.2 端到端的一站式AI服务
在 AIGC 场景下面,尤其是过去半年,我们发现用户他要的其实不仅仅是一个向量数据库的能力,他还要额外的两个能力。
那这额外的两个能力是什么?其实第一个是我刚才已经讲的,就是你有文档进来,他要有能够理解文档的这个能力。这个是什么意思?就是比如说我有一个文档,它是有一级标题、二级标题、三级标题,然后再是正文。那我如果在切分文档的时候去随意切的话,可能正文切到的一段,是属于这个一级标题下面的,但是由于我的切分方式,导致它丢失了它的一级标题的信息,那做检索的时候它的效果可能并不会很好。通过文档理解的这个能力我们能够,比如说把这个一级标题再重新 attach 到这个切好的这个文本上面,能够增加它在语义上面的表达力。
除此之外,客户也需要很好的切分算法,尤其是对于中文要能够有个很好的切分算法。并且说能够有生成 embeddings 的这个能力,那我们都把这些能力给包含到我们的这个向量数据库的一个我们部署的 HTTP 服务里面去。第二部分其实是我们目前正在做的和大语言模型结合的能力,就是我们希望能够在向量数据库里面去 fine-tune 模型,并且说能够去做基于模型的inference。
总而言之就是说我们的理念是说在一套数据系统里面把用户的结构化数据,像这些 structured data,还有像 JSON 文本以及像向量数据都存储在一套数据系统里面,去解决用户所有的数据分析类场景的问题。
3.3 和通义千问的落地实践
这里是我们跟通义千问协作的一个具体的例子,在这套融合的系统里,用户他可以在通义千问里面做自己的模型的 fine-tune,他可以把他的实时数据写入到 AnalyticDB 里面去,然后通过刚才那个流程去做 LLM 加上 AnalyticDB 里面的知识的召回和智能的问答。然后我们同时支持两种部署模式,一种是如果说客户对自己的数据的安全性、敏感性非常 serious 的话,我们采用单租户的这种模式,那还有一种客户并没有那么敏感,那我们也支持多租户的部署模式。然后通过我们数据库的 user 加 schema 的权限隔离,以及通过我们的 resource group 在资源上面做的 CPU、 memory、 IO 的隔离来保证系统的隔离性,所以它是一个类似于 SAAS 的这样一个部署方式。

4. 新一代向量数据库演进趋势
4.1 云原生存算分离架构
最后来讲一下就是我们目前在做的一些工作。第一个是说我们目前在做的向量的存算分离,因为大家刚才听我的描述其实很容易能够理解,我们其实是用本地的存储来存向量的,对于 HNSW 索引我们需要去高频的去做 update 和 delete 这种操作,这对云原生的 append only 或者 write once never modify 的这种类型的 DFS 是非常不友好的。
我们一开始的时候,采取的就是图里面方案一的这种实现方式。因为我们的整个数据写入流程是数据会先写入行存的这个 Delta 表,然后当行存的 Delta 表积累到一定程度的时候,我们会把它下刷到 DFS 上面去,以列存的形式存储,这样能够加速扫描。所以每次下刷成一个fragment,这个时候因为这个 fragment 是 immutable 的,与此同时我们会构建一个小的 HNSW 索引。然后当我查询的时候其实就是把这些索引分别做查询,然后 merge 起来。那如果有 delete 操作的话,我们也是先存在内存里面,然后当你 delete 的个数达到一定量的时候,才跟下面的这些 fragment 去做一个compaction,然后重写这个 fragment。我们发现方案一的问题是永远没有办法达到一个 sweet point:比如说如果你要召回率高的话,你可能每个 HNSW 的召回你都要调得非常高。但是注意这里跟我刚才描述的存算一体的架构不符,在存算一体的架构下我们是一个 shard 一个 HNSW,但这里是一个 fragment 一个 HNSW,所以做了向量检索以后还要合并,那这些非常小的结果合并起来它其实开销是非常高的。但是如果你把这个取 top k 的操作,把这个 k 给调小的话,又会发现这个召回率达不到效果,所以最后我们摒弃了这个方案,然后我们采取了这个方案二的方式。
方案二其实理念非常简单,就是说大家不要被局限于存算分离只能是纯 immutable 的共享存储。 这里我们自己建了一个多租户的存储池,然后这个存储池它会存储 HNSW 点和边的这些 page,并且是多个实例去共享的,所以说它的资源的规划是我们在 region 级别做的,并且它并不会发生很多次的扩缩容。 当有写入的时候,先写入 log keeper 的这个 service 里面,然后 log keeper 会把这些 log 给传给 page server,然后读取的时候 page server 会基于原来的page,然后再去按需地 apply 这个 log,形成新的 page。 计算节点的本地是不存任何数据的。这种做法的好处是,第一是这个性能和之前调的召回率也有保证,然后对于原有代码的入侵性和修改也比较少。

4.2 AI原生的向量数据库
最后讲一下我们的向量数据库是怎么去和灵积的模型去做结合的。本质上用户要去精调一个模型,那这个数据必然是一个清洗完毕后的质量非常高的数据,那这些数据的清洗我们是希望在 AnalyticDB 云原生数仓里面去完成这个操作,与此同时我们还可以去 AnalyticDB 里面去做模型的训练。所以当你写了这条SQL语句以后,我会先执行这个SQL,把 ETL 清洗完的数据写入到 OSS 里面去。然后在具体执行模型训练的时候,我们会去调用灵积服务,让它把这个数据拖进来,然后进行基于某个具体的模型进行微调。比如说这里我选的 base model 是通义千问 v1。然后微调完之后我们可以去触发整个模型的上线和部署,所以说这里我们把模型的微调和上线部署也结合到这个 SQL 语句里面来。 同时,我们也可以通过 AnalyticDB 来做 inference,就是用户可以自己写一个 UDF,然后去调用之前训练并部署完的模型,基于这个模型做 inference。可以看这里的一个具体例子,比如我有一个售后问答的一个服务,那我通过一些人工回答的高质量的售后问答的数据,先去做模型的 fine-tune, fine-tune 完后,如果后面有新的问题进来,我只需要通过调用这个模型就能够自动去给未回答的问题写一个回复,提升了用户的整个使用体验。

更多资讯请关注
AnalyticDB PostgreSQL 版向量能力介绍
https://www.aliyun.com/activity/database/adbpg_vector

