
2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
概述
在理解向量检索之前需要先了解一个概念,什么是向量。向量(Vector),Embedding Vector,在DashVector中,Vector作为Doc(文档)的基础数据单位之一,用于描述各种非结构化数据的特征。说通俗点,向量实际上是一串数字的组合,也就是一个数组,这个数组代表了这段文本的特征。
向量检索服务DashVector是一种支持向量检索的服务。它支持Dense Vector(密集向量)和Sparse Vector(稀疏向量),前者用于模型的高维特征表达,后者用于关键词和词频信息表达。DashVector可以进行关键词感知的向量检索,即Dense Vector和Sparse Vector结合的混合检索。
随着大数据、人工智能和云计算等技术的普及,人们处理和利用大量数据的能力得到了显著提高。这为向量检索服务的出现提供了必要的技术基础。而随着深度学习和自然语言处理技术的突飞猛进,向量检索服务得到了广泛应用。这些技术使得将文本或数据转换成向量表示成为可能,进而进行相似性匹配。
总之,向量检索服务的出现是技术发展、数据处理需求以及提高搜索效率和精度的需求等多种因素共同作用的结果。
试用
本次活动提供了一个月的serverless型产品的试用,前往活动首页可以直接开通,如下:

整个开通过程还是非常简单的,直接命名一个Cluster名称即可,其他保持默认。如下:
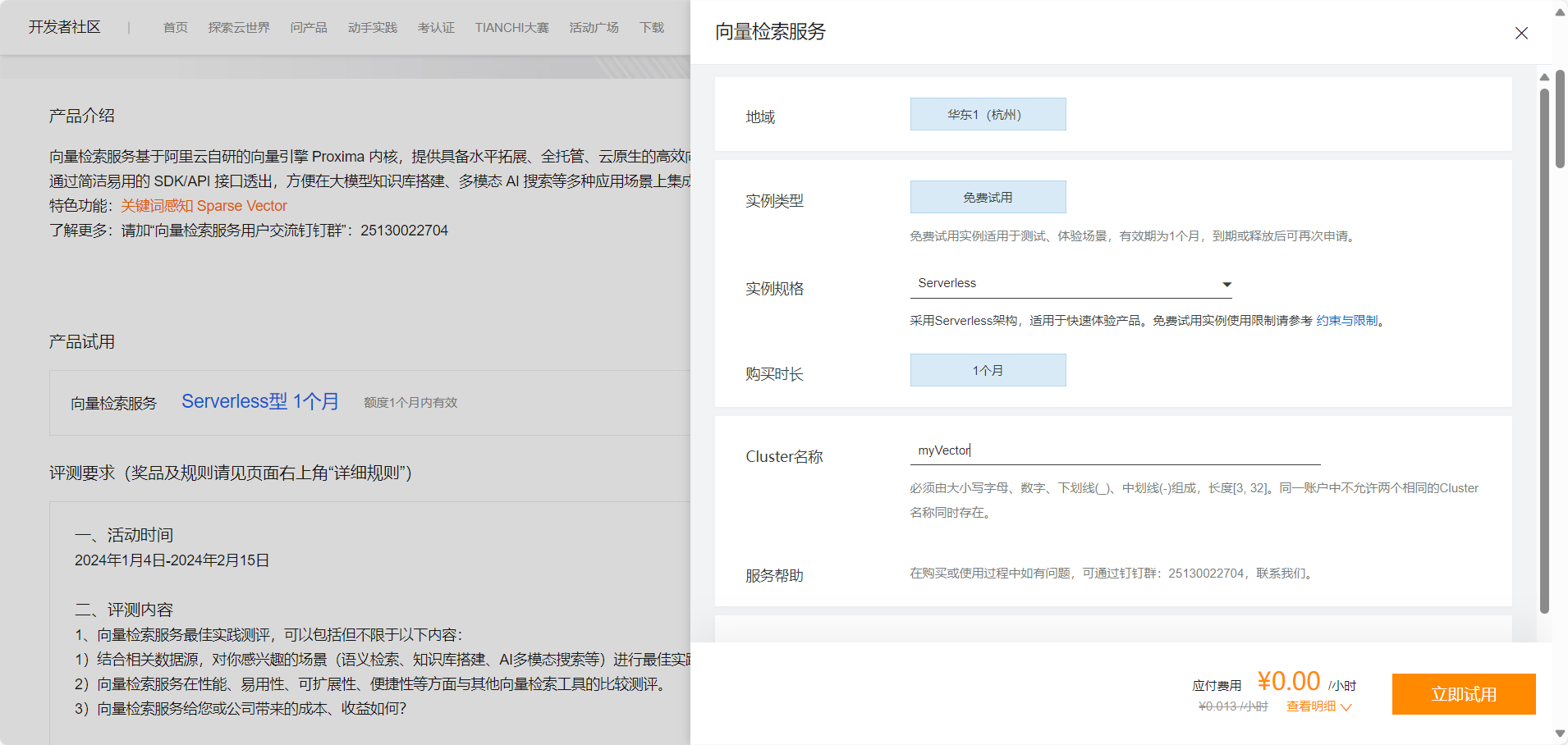
点击立即试用后直接跳转到向量检索服务的控制台首页,如下:
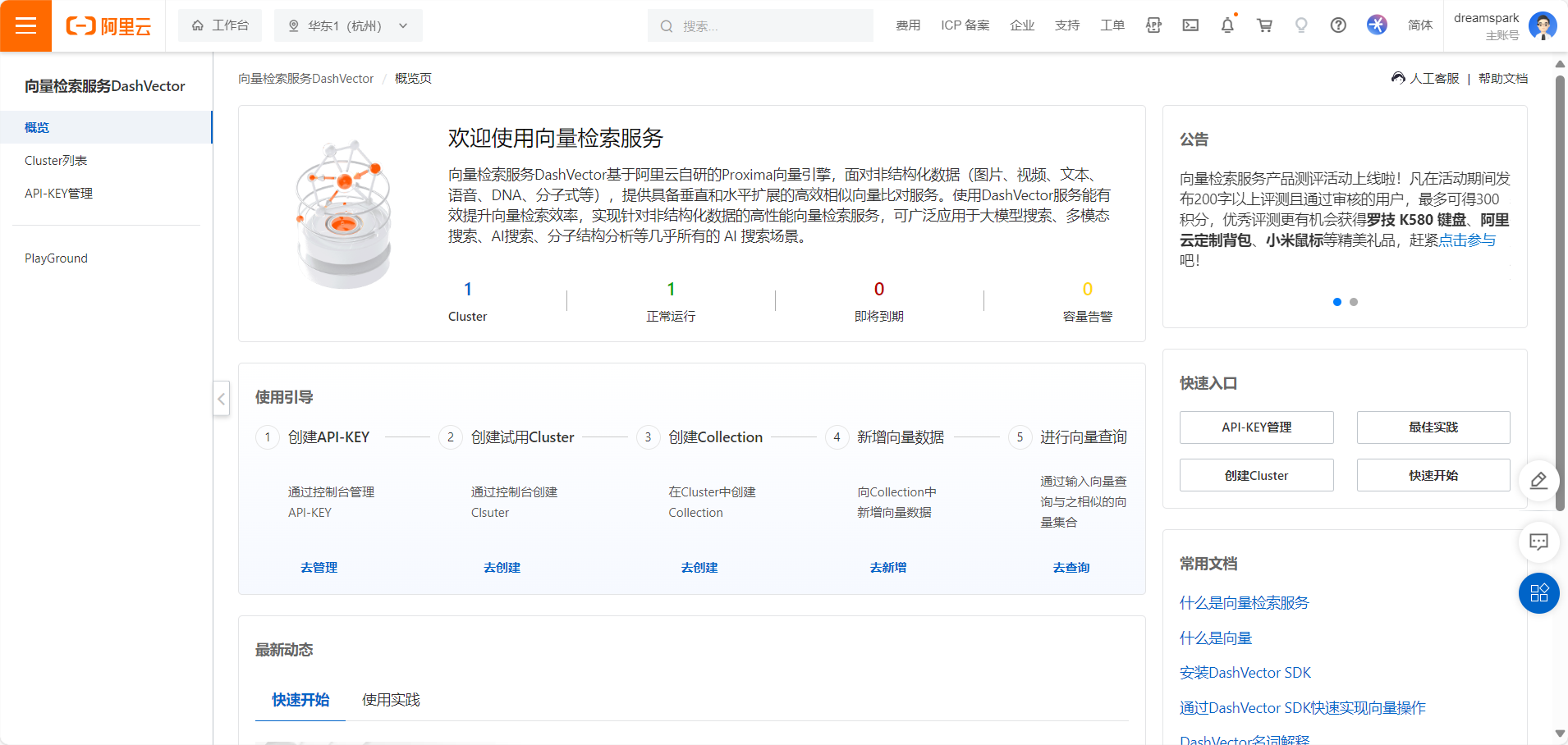
在首页可以很直观地看到,已经有一个Cluster正在运行。点击可以来到Cluster首页。如下:
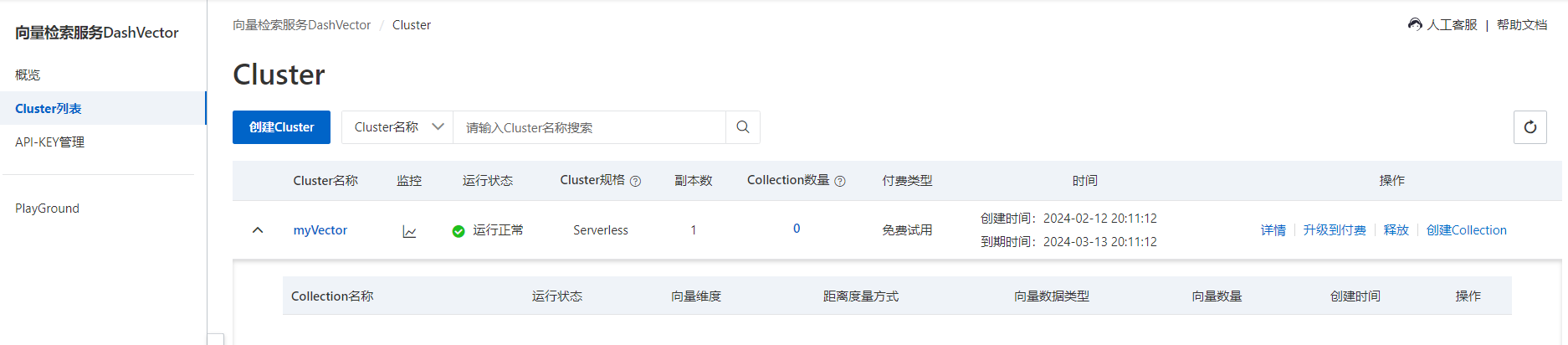
到此,我们已经完成了产品的开通试用,接下来就通过一个实用的例子来体验。
实践
语义搜索
该实验将基于QQ 浏览器搜索标题语料库(QBQTC:QQ Browser Query Title Corpus)进行实时的文本语义搜索,查询最相似的相关标题。这里要借助到DashScope灵积模型服务,那怎么理解DashScope灵积模型呢,说白点就是通过DashScope统一的API和SDK来实现被不同业务系统集成,从而为各领域模型提供开箱即用的能力。
在正式开始体验之前,非常有必要先了解下向量检索服务的使用流程,如下: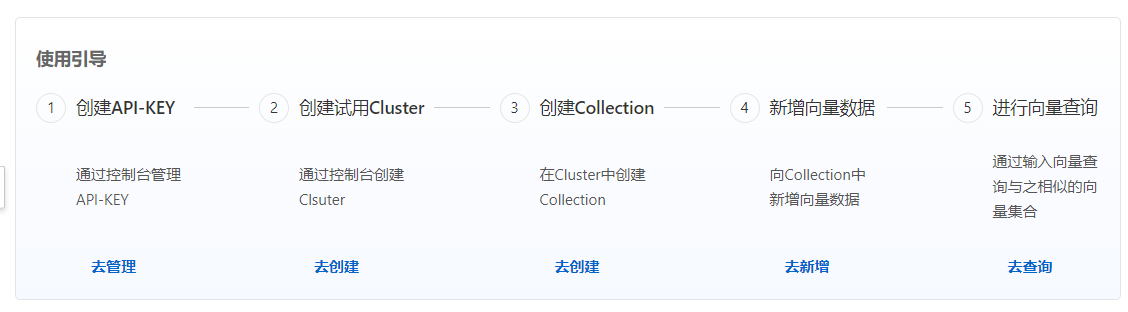
那该实验的第一步就需要开通DashScope灵积模型服务,前往服务控制台,点击去开通,如下:
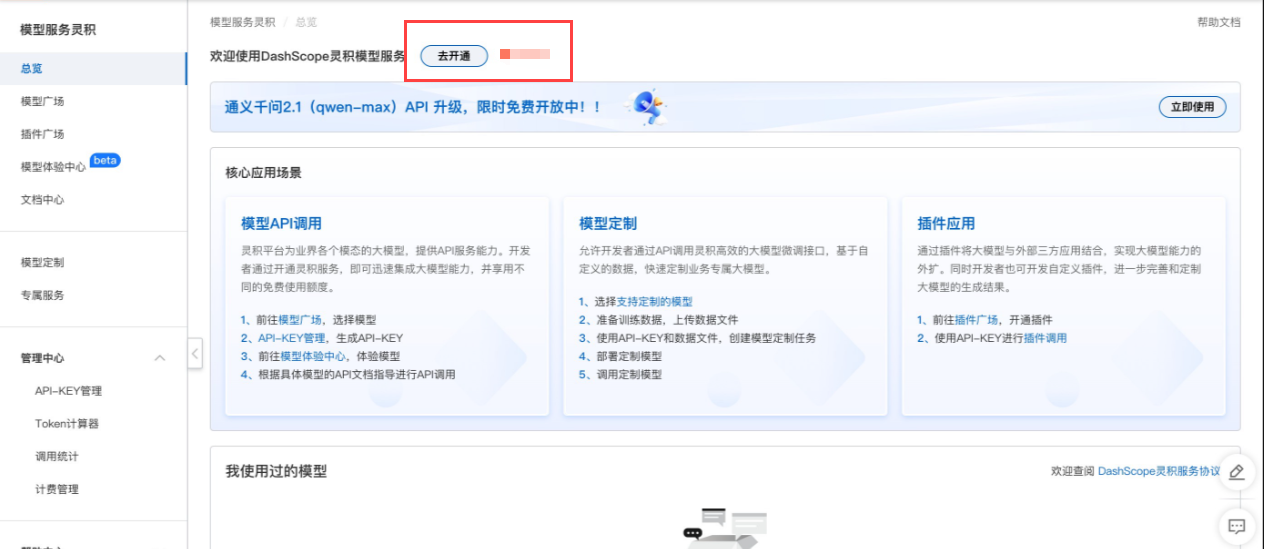
完成后,将会看到如下界面,如下是我之前开通了通义千问的模型服务。如下:

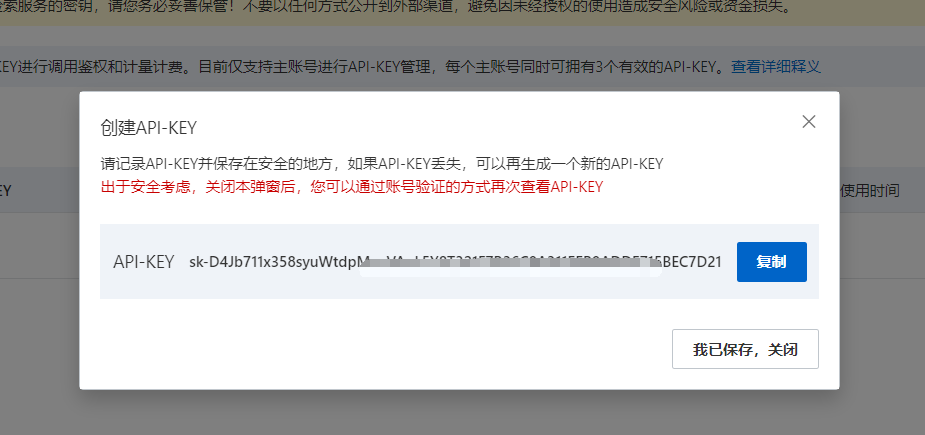
点击左侧的API-KEY管理,点击创建新的API-KEY,如下:
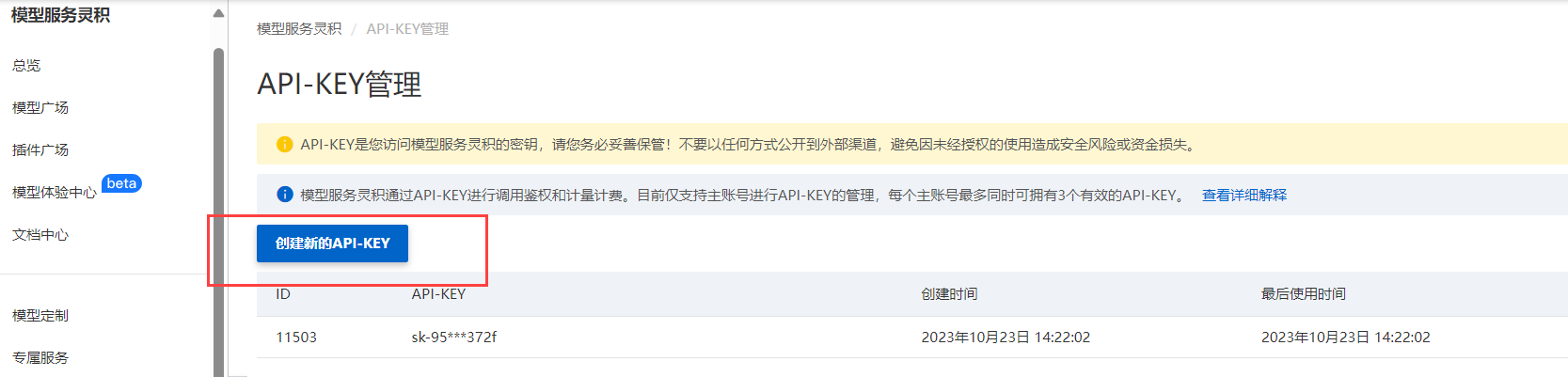
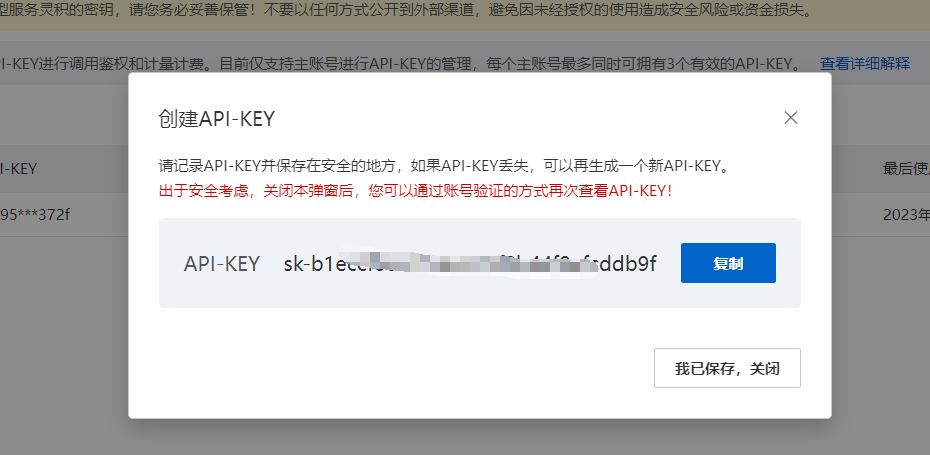
在接下来弹出的API-KEY窗口中复制好新的KEY,如下:
接着来到向量检索服务控制台,点击左侧导航栏的API-KEY管理,点击创建新的API-KEY,如下:
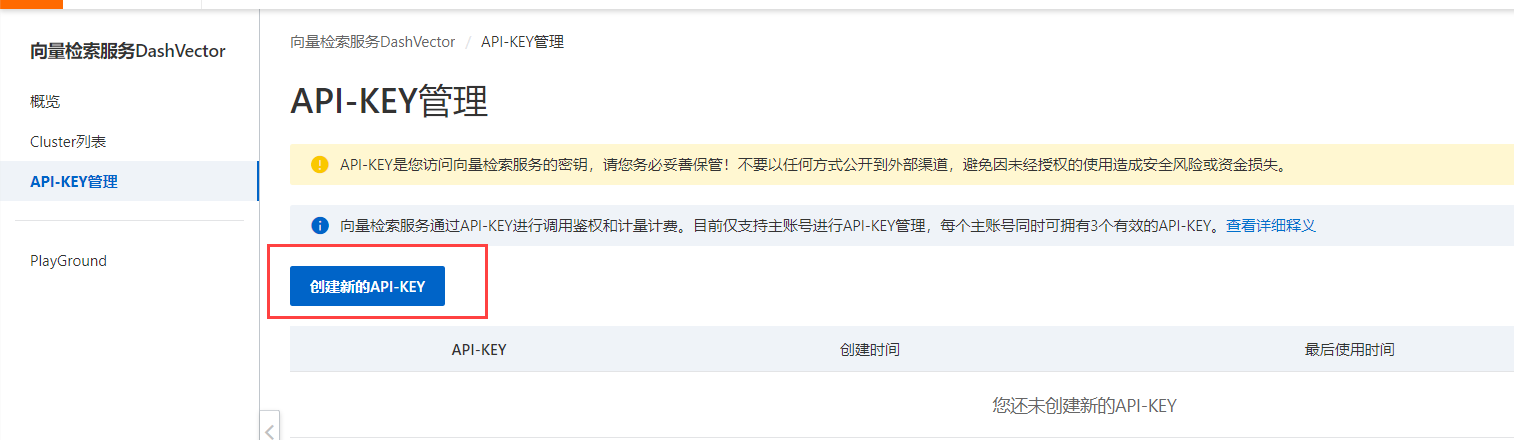
复制好接下来弹窗中的KEY,如下:
有了上面的API-KEY后,接下来需要在你的电脑上安装python环境,这里我就不再赘述了,提供一个比较好的文档链接供参考。最详细的Windows安装Python教程
完成后,可以运行cmd,打开命令行窗口,运行python、pip,验证环境是否可用。如下:
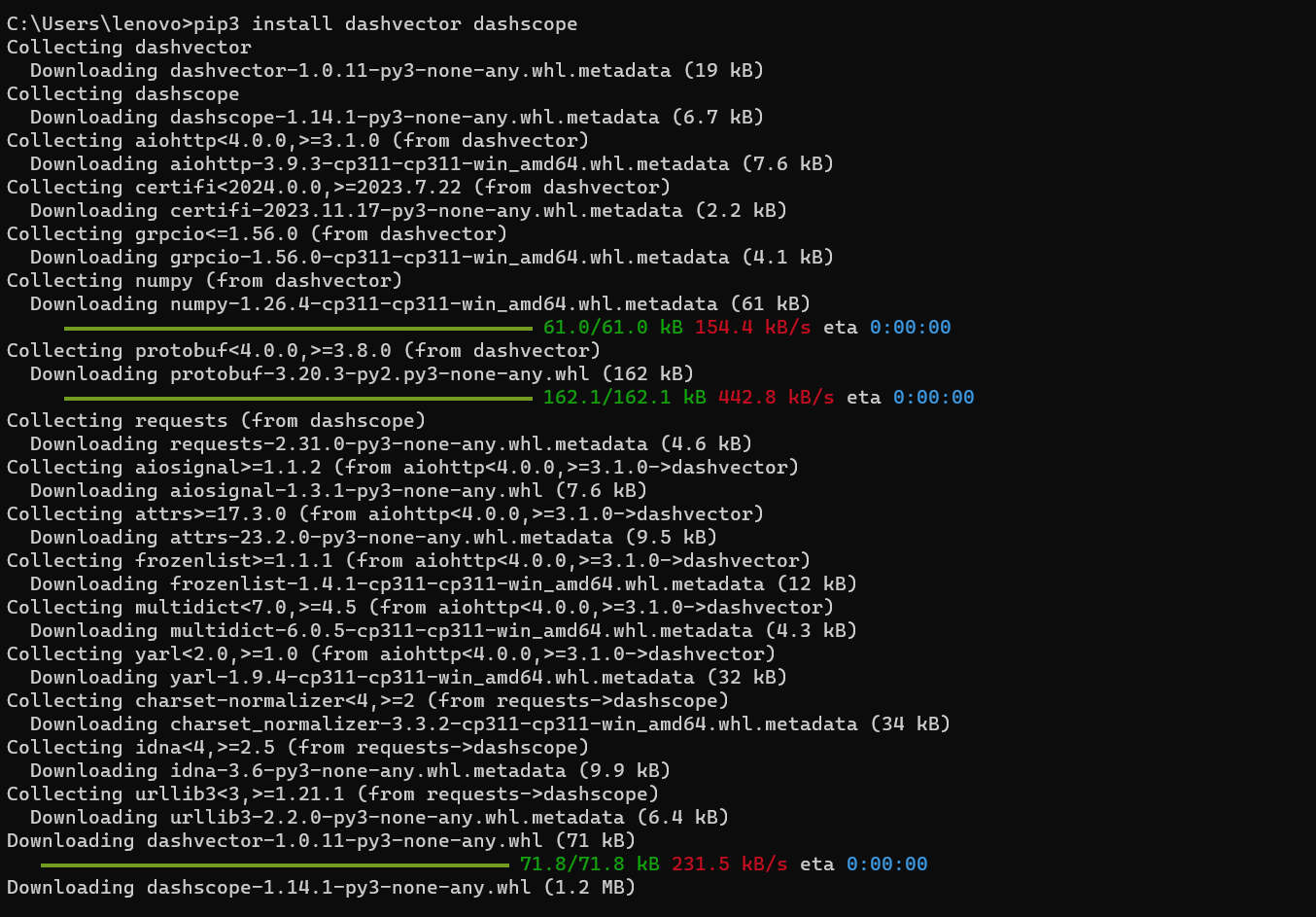
接下来安装初始环境,运行如下命令,如下:
pip3 install dashvector dashscope
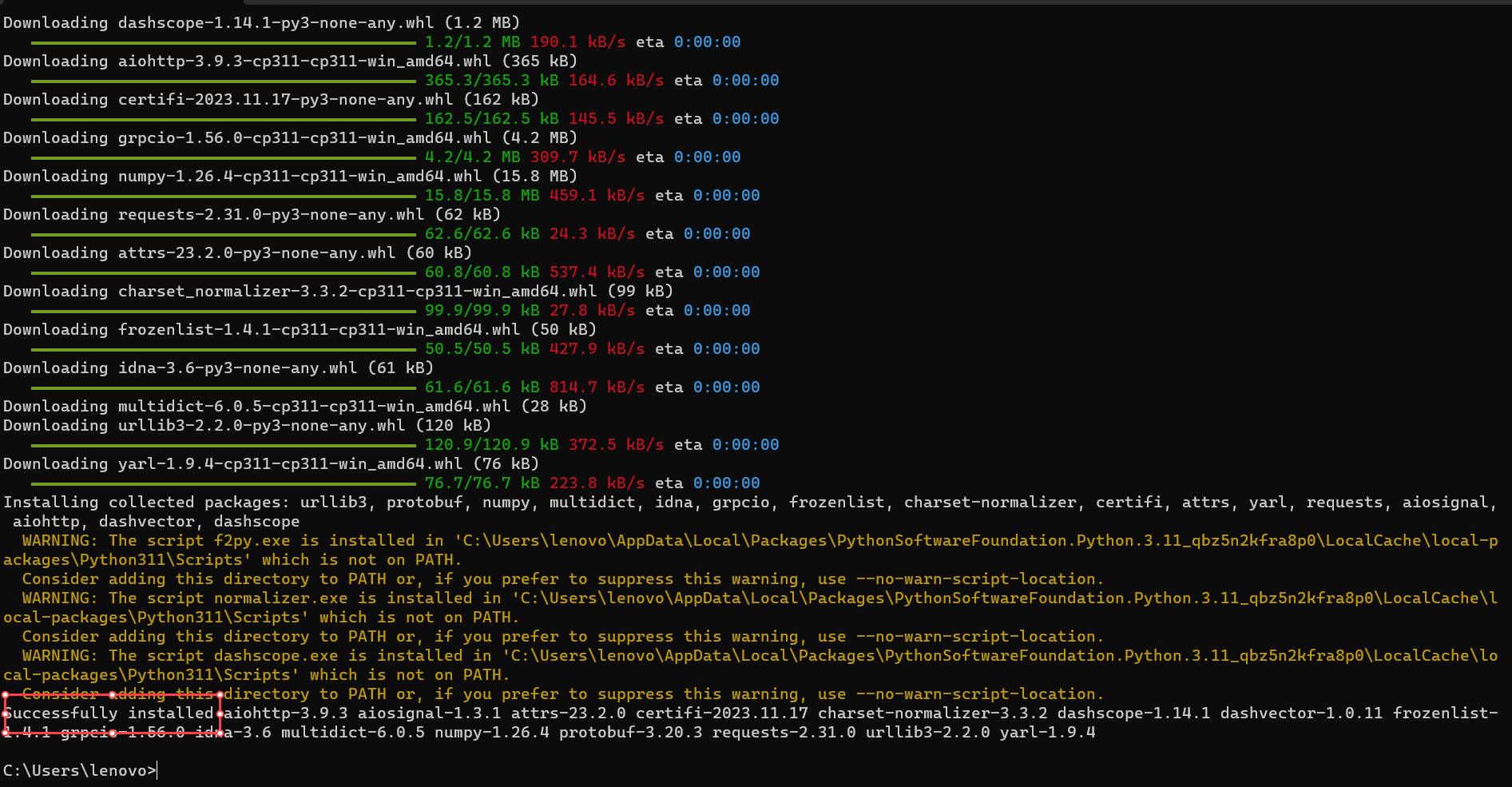
大概运行一分钟左右,直到出现Successfully installed字样,就表明环境安装完成。如下:
推荐Python3.7 及以上版本。这里如果大家不注意python版本的话,安装过程中会出现报错,提示版本过低,需要执行如下命令进行在线升级python版本,命令如下:
python.exe -m pip install --upgrade pip
有了初始环境,接着要准备数据,这里需要电脑安装git工具,可以自行前往git官网,选择电脑操作系统对应版本进行安装。这里提供一个非常实用的文档参考,点击前往Git 安装和配置教程:Windows - Mac - Linux 三平台详细图文教程,带你一次性搞 Git 环境
完成后,在cmd窗口通过git -v可以查看,如下:

通过如下命令获取数据。如下:
git clone https://github.com/CLUEbenchmark/QBQTC.git
由于数据源来自与github,如果网络不稳定的话,需要多试几次。接下来通过git bash窗口,运行如下命令:
wc -l QBQTC/dataset/train.json
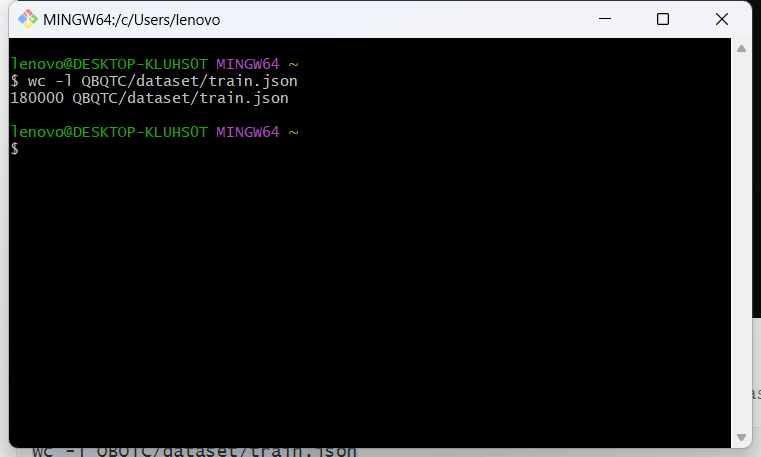
图上显示数据集train.json文件有180000行数据。当然这里也可以通过cat命令,获取到train.json文本中的内容。如下:
从train.json文本内容中可以很直观地看到,数据集中的训练集(train.json)其格式为 json:
{
"id":179975,
"query":"2022年羊年运势及运程",
"title":"属羊2022年运势及运程2022年属羊人的全年每月运势详解2022年生肖运势祥安阁风水网",
"label":"2"
}
接下来将从这个数据集中提取title,方便后续进行embedding并构建检索服务。python代码如下:
import json
def prepare_data(path, size):
with open(path, 'r', encoding='utf-8') as f:
batch_docs = []
for line in f:
batch_docs.append(json.loads(line.strip()))
if len(batch_docs) == size:
yield batch_docs[:]
batch_docs.clear()
if batch_docs:
yield batch_docs
将上述代码另存为title.py文件并拖入cmd窗口,并执行。
接下来通过调用灵积模型服务的API-KEY来获取通用文本向量,也就是embedding向量。python代码如下:
import dashscope
from dashscope import TextEmbedding
#这里填入上述获取到的灵积模型服务API-KEY
dashscope.api_key='sk-b1eccf0ce17c**********0efcddb9f'
def generate_embeddings(text):
rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,
input=text)
embeddings = [record['embedding'] for record in rsp.output['embeddings']]
return embeddings if isinstance(text, list) else embeddings[0]
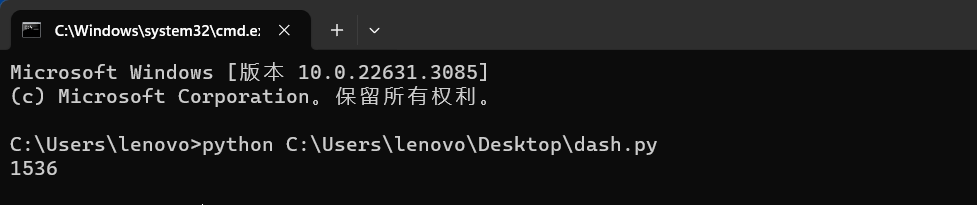
# 查看下embedding向量的维数,后面使用 DashVector 检索服务时会用到,目前是1536
print(len(generate_embeddings('hello')))
运行上述代码,获取结果如下:
接下来将如下python代码实现向量检索服务构建检索,实现向量的入库。也就是把QBQTC训练数据集里的title内容都写到DashVector服务上的集合里。代码如下:
from dashvector import Client, Doc
# 初始化 DashVector client
client = Client(
#这里填入向量检索服务的API-KEY
api_key='sk-D4Jb711x358syu***********Y8T321F7B36C9A311EEB9ADDE715BEC7D21',
#这里填入向量检索服务Cluster的endpoint
endpoint='vrs-cn-o493lxh*******.dashvector.cn-hangzhou.aliyuncs.com'
)
# 指定集合名称和向量维度
rsp = client.create('sample', 1536)
collection = client.get('sample')
assert collection
batch_size = 10
for docs in list(prepare_data('QBQTC/dataset/train.json', batch_size)):
# 批量 embedding
embeddings = generate_embeddings([doc['title'] for doc in docs])
# 批量写入数据
rsp = collection.insert(
[
Doc(id=str(doc['id']), vector=embedding, fields={
"title": doc['title']})
for doc, embedding in zip(docs, embeddings)
]
)
assert rsp
向量入库的这段代码运行需要耗费两小时,可以在向量检索服务控制台查看入库的向量数量,如下:
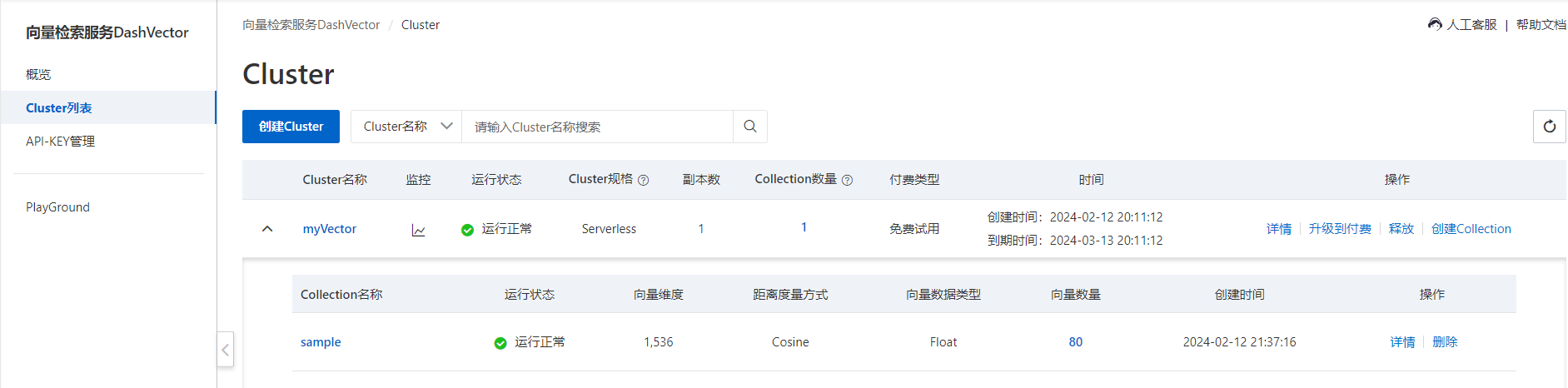
此时还可以通过查看Cluster详情获取到向量的用量统计,向量有关的信息。如下:

还可以对向量数据进行更删改查等操作,如下:
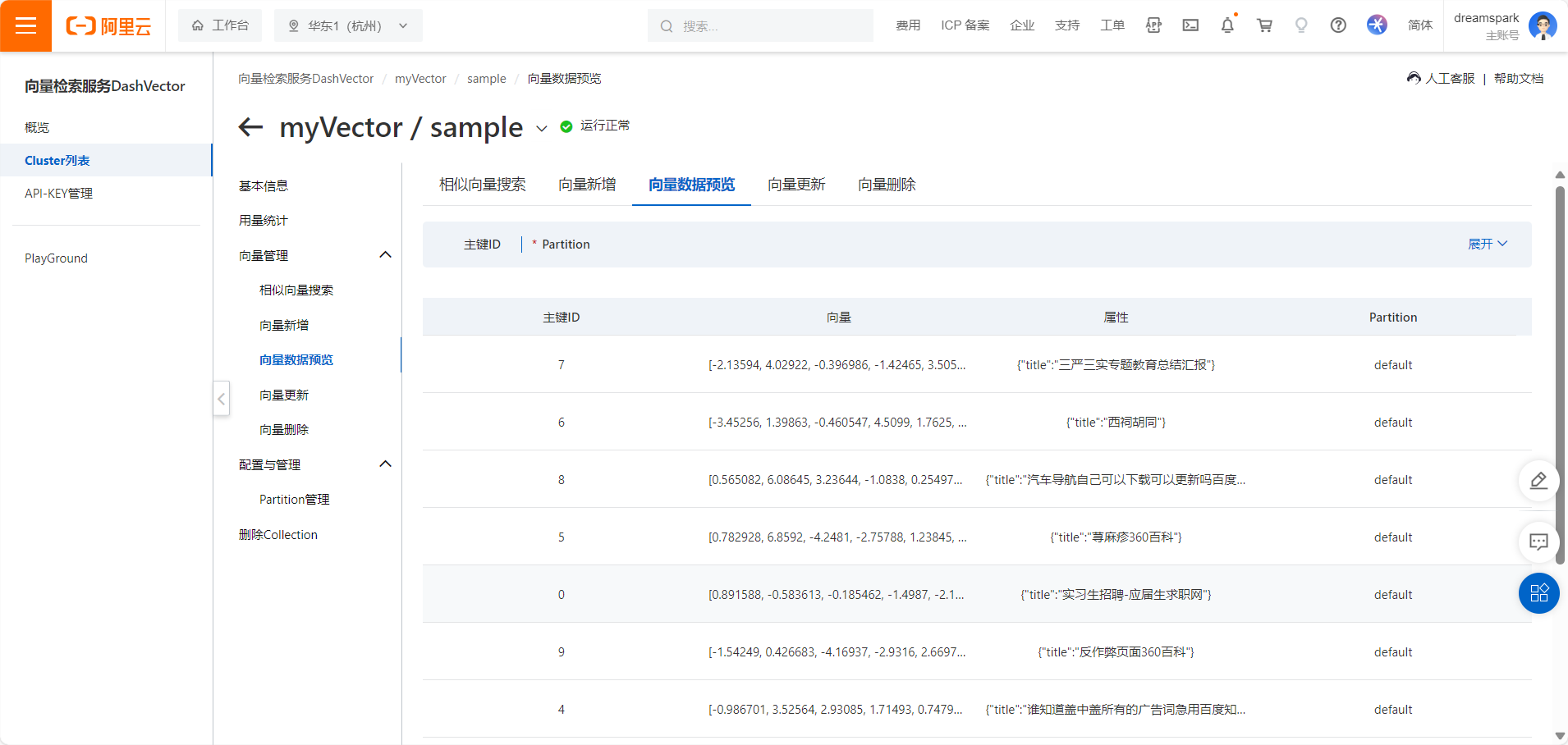
有了上述的集合结果后,可以通过如下命令实现语义检索了。代码及结果如下:
# 基于向量检索的语义搜索
rsp = collection.query(generate_embeddings('应届生 招聘'), output_fields=['title'])
for doc in rsp.output:
print(f"id: {doc.id}, title: {doc.fields['title']}, score: {doc.score}")
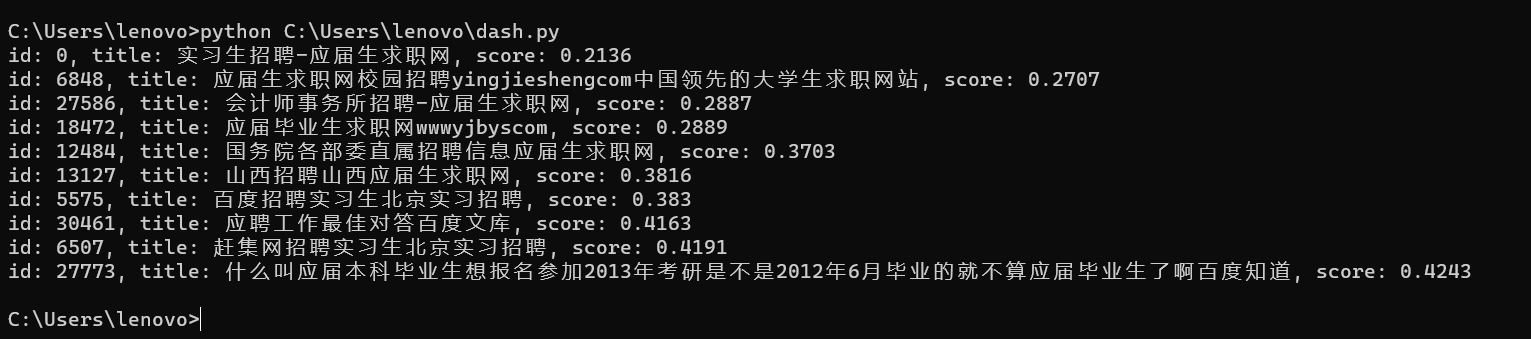
到这里我们就完整体验了使用向量检索服务,基于QQ浏览器搜索标题语料库实现实时的文本语义搜索,查询最相似的相关标题。当然,如果你对于此次的实践意犹未尽,还想继续深入了解并学习,官网很贴心的准备了其他两个小实践,链接如下:
使用DashVector与LLM大模型实现垂直领域专属知识问答服务
使用DashVector和ModelScope实现多模态检索
对比
作为开发者,我之前使用过如Faiss、Milvus和Annoy。感兴趣的同学可以前往如下链接了解学习。
这些工具在向量检索领域都有广泛的应用,并且具有各自的特点和优势。例如,Faiss是Facebook开源的向量检索工具,它支持高效的相似度搜索和聚类,适用于大规模数据集。Milvus则是一个开源的向量数据库,提供了高性能的向量检索和数据分析功能。Annoy则是一个轻量级的向量检索工具,易于使用和部署,适用于小型数据集。
在使用过程中,我发现这些工具都具有不错的性能和稳定性,能够满足大多数向量检索任务的需求。然而,它们也存在一些不足之处,如Faiss在处理超大规模数据集时可能会遇到性能瓶颈,Milvus的部署和配置相对复杂,而Annoy的功能相对简单,可能无法满足一些高级需求。
而阿里向量检索服务DashVector的优势在于
易用性更好:向量检索服务通常提供多种接入方式以适应不同用户的需求并支持多种编程语言,如Python、Java、Go等。例如,为用户提供了API接口、SDK以及阿里云控制台的简单配置等多种接入方式,使得接入变得非常方便。对于有一定技术背景的用户,可以通过API和SDK快速集成向量检索功能;对于不具备技术背景的用户,可以通过阿里云控制台提供的直观界面,完成接入。因此,从接入便捷性来看,向量检索服务通常是满足预期的。
检索性能更佳:向量检索服务通常表现出色。无论是对于大规模数据集还是实时数据流,该服务都能快速准确地返回检索结果。此外,其还提供了多种相似度计算方法,以满足不同场景的需求。这些特点使得向量检索服务在检索性能方面能够满足大多数用户的预期。
扩展性能更强:向量检索服务除了提供基础的向量检索功能外,还提供了诸如数据预处理、索引管理以及自定义相似度计算等高级功能。这些功能大大增强了服务的灵活性和实用性,使得向量检索服务能够更好地满足用户的多样化需求。
因此,对于需要处理大规模数据集的用户,可以考虑使用Faiss、Milvus或DashVector等高性能的工具;对于需要快速部署和使用的用户,可以考虑使用Annoy等轻量级的工具。此外,如果对于近似最近邻搜索的速度和轻量级集成更为关注,可以选择 Annoy;如果需要管理和查询大规模的向量数据库,并希望具备更多的功能和可扩展性,可以选择 Milvus或DashVector。
总结
一、在体验向量检索服务的过程中,通常会得到一定的产品内容引导和文档帮助。这些引导和帮助可能包括产品的介绍、功能说明、使用教程、API文档等,有助于用户了解和使用向量检索服务。但仍可能欠缺一些高级功能和使用场景的详细说明、错误排查和解决问题的指南以及最佳实践和性能优化建议等方面的内容。比如:
- 高级功能和使用场景的详细说明:对于一些高级功能和使用场景,可能只是简单地提及或者没有详细说明,导致用户无法充分理解和使用这些功能。因此,需要提供更详细的高级功能和使用场景文档,包括具体的使用方法、参数说明、示例代码等。
- 错误排查和解决问题的指南:在使用向量检索服务的过程中,用户可能会遇到各种问题或错误。因此,需要提供相应的错误排查和解决问题的指南,帮助用户快速定位和解决问题。这些指南可以包括常见问题的解答、错误码的含义和解决方案等。
- 最佳实践和性能优化建议:对于向量检索服务的使用,可能存在一些最佳实践和性能优化建议。这些建议可以帮助用户更好地使用向量检索服务,提高检索效率和准确性。因此,需要提供相应的最佳实践和性能优化文档,供用户参考和学习。
二、从接入便捷性、检索性能以及其他功能等方面来看,向量检索服务在很大程度上是满足预期的。但仍然需要根据具体业务场景和需求进行持续优化和改进。例如,可以增加更多向量索引算法以满足不同业务场景的需求;提供更丰富的统计和监控功能以便于开发者更好地了解检索效果;优化分布式检索性能以提高在大规模数据场景下的检索速度等。
三、针对业务场景,向量检索产品还有很多可以改进和增加的功能点,比如:
- 定制化的解决方案:对于特定的行业或应用场景,提供定制化的解决方案和功能支持。例如,对于电商、金融、医疗等不同行业,可以根据其数据特点和业务需求,提供专门的向量检索优化方案。
- 多模态向量检索:随着多媒体内容的增加,支持图像、视频、文本等多模态数据的向量检索将变得越来越重要。可以进一步研发和优化这方面的技术,提供更高效、准确的多模态向量检索功能。
- 向量索引和压缩技术:对于海量的向量数据,索引和压缩技术是提高检索效率和降低存储成本的关键。可以研究和引入更先进的向量索引和压缩算法,以优化存储和检索性能。
- 可视化和解释性:提供可视化的检索结果和解释性信息,帮助用户更好地理解检索结果和向量之间的关系。例如,可以显示与查询向量最相似的几个向量的图像或文本描述,以及它们之间的相似度分数。
四、非常期待向量检索服务能与其他产品联动,推出组合产品。比如:
- 将向量检索服务与机器学习平台结合,可以实现更加智能的数据分析和预测。具体来说,机器学习平台可以对向量检索服务检索出的数据进行深入分析和挖掘,发现数据中的潜在规律和趋势,从而为用户提供更加精准和个性化的推荐或决策支持。
- 将向量检索服务与物联网平台结合,可以为物联网设备提供实时监测和智能控制功能。物联网平台可以收集各种传感器的数据,并通过向量检索服务对这些数据进行实时分析和处理。这样,用户就可以随时了解设备的状态和运行情况,并根据需要进行远程控制和调整。
- 将向量检索服务与自然语言处理、图像识别等其他AI产品联动,以满足更复杂的业务场景和需求。例如,在自然语言处理场景中,向量检索服务可以用于文本相似度匹配和语义搜索等任务;在图像识别场景中,向量检索服务可以用于图像检索和相似图像推荐等任务。
