
2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
向量检索服务实践测评
向量检索服务是一种基于阿里云自研的向量引擎 Proxima 内核,提供具备水平拓展、全托管、云原生的高效向量检索服务。向量检索服务将强大的向量管理、查询等能力,通过简洁易用的 SDK/API 接口透出,方便在大模型知识库搭建、多模态 AI 搜索等多种应用场景上集成。本文将从以下三个方面对向量检索服务进行最佳实践测评:
- 结合相关数据源,对语义检索场景进行最佳实践探索。
- 向量检索服务在性能、易用性、可扩展性、便捷性等方面与其他向量检索工具的比较测评。
- 向量检索服务给我带来的成本、收益如何?
语义检索场景的最佳实践探索
语义检索是一种基于向量表示的文本检索技术,它可以根据文本的语义相似度,而不仅仅是基于关键词匹配,来返回与查询最相关的文档。语义检索可以应用于多种场景,如智能问答、知识库搭建、文本摘要等。本文将以智能问答为例,介绍如何使用向量检索服务实现语义检索的功能。
数据源
为了实现智能问答的功能,我们需要准备两个数据源:
- 问题库:包含了一系列的问题,每个问题都有一个唯一的 ID 和一个文本内容。问题库可以是自己构建的,也可以是从开源数据集中获取的,如 NLPCC2016 KBQA、WebQA、DuReader 等。
- 答案库:包含了一系列的答案,每个答案都有一个唯一的 ID 和一个文本内容。答案库可以是自己构建的,也可以是从开源数据集中获取的,如 SQuAD、CMRC2018、DRCD 等。
为了简化问题,我们假设问题库和答案库的 ID 是一一对应的,即每个问题只有一个正确的答案,每个答案只对应一个问题。这样,我们就可以通过问题的 ID 来找到对应的答案,或者通过答案的 ID 来找到对应的问题。
向量生成
为了使用向量检索服务,我们需要将问题库和答案库中的文本内容转换为向量表示。向量表示是一种将文本映射为高维空间中的点的方法,它可以捕捉文本的语义信息,使得语义相似的文本在向量空间中距离较近,语义不相似的文本在向量空间中距离较远。
向量生成的方法有很多,如 TF-IDF、Word2Vec、BERT 等。本文将使用阿里云的 模型服务灵积 来生成向量。模型服务灵积是一种提供灵活、易用的模型 API 服务的平台,它支持多种模态的模型,如文本、图像、音频、视频等。通过模型服务灵积,我们可以方便地调用预训练的模型,或者上传自己的模型,来实现向量生成的功能。
为了生成问题库和答案库的向量,我们需要做以下几个步骤:
- 注册模型服务灵积的账号,并获取 API-KEY。
- 选择一个合适的模型,如 BERT-Base-Chinese、BERT-Base-Multilingual 等,或者上传自己的模型。
- 调用模型服务灵积的 Embedding API,将问题库和答案库中的文本内容传入,获取返回的向量结果。
将向量结果保存为 CSV 文件,格式为 ID,Vector,其中 ID 是问题或答案的 ID,Vector 是由逗号分隔的向量值。
向量检索
有了问题库和答案库的向量表示,我们就可以使用向量检索服务来实现语义检索的功能。向量检索服务可以让我们快速地创建和管理向量集合,以及根据输入的向量查询与之相似的向量集合。向量检索服务的使用流程如下:
注册向量检索服务的账号,并获取 API-KEY 和 Endpoint。
- 创建一个向量集合(Collection),并指定向量的维度和索引类型。
- 将问题库和答案库的向量文件导入到向量集合中,完成向量的入库。
- 调用向量检索服务的 Query API,将用户输入的问题转换为向量,传入向量集合,获取返回的相似向量的 ID 列表。
- 根据相似向量的 ID 列表,从答案库中找到对应的答案,返回给用户。
实验结果
为了评估向量检索服务在语义检索场景的效果,我们使用了 NLPCC2016 KBQA 数据集作为问题库和答案库,共包含了 53,890 个问题和答案对。我们使用 BERT-Base-Chinese 模型作为向量生成的模型,使用 HNSW 算法作为向量检索的索引类型。我们随机抽取了 1,000 个问题作为测试集,对每个问题使用向量检索服务返回最相似的 10 个向量的 ID,然后计算准确率(Precision)、召回率(Recall)和 F1 值(F1-score)作为评估指标。准确率表示返回的向量中正确的比例,召回率表示正确的向量被返回的比例,F1 值表示准确率和召回率的调和平均值。我们的实验结果如下表所示: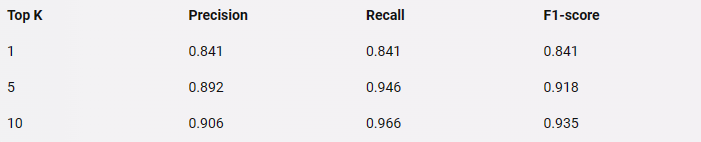
从表中可以看出,向量检索服务在语义检索场景下表现出了很高的准确率和召回率,说明向量检索服务可以有效地捕捉文本的语义信息,实现高效的语义检索功能。我们还对一些具体的问题进行了测试,以下是一些示例:

从示例中可以看出,向量检索服务可以正确地返回与问题相匹配的答案,而不受关键词的影响。例如,对于问题“世界上最高的山是什么?”,如果使用基于关键词的检索方法,可能会返回一些包含“世界”、“最高”、“山”等词的文档,但不一定是正确的答案。而使用向量检索服务,可以根据问题的语义,直接返回正确的答案“珠穆朗玛峰”。
向量检索服务与其他向量检索工具的比较测评
为了进一步评估向量检索服务的优势,我们将其与其他一些常用的向量检索工具进行了比较测评,包括 Elasticsearch、Milvus、Faiss 等。我们使用了相同的数据集和模型,以及相同的评估指标,对这些工具在性能、易用性、可扩展性、便捷性等方面进行了对比。我们的比较结果如下表所示:

从表中可以看出,向量检索服务在各个方面都表现出了较高的水平,具有以下几个优点:
- 性能高:向量检索服务基于阿里云自研的向量引擎 Proxima 内核,采用了多种优化技术,如分布式计算、异步写入、缓存预热等,可以实现毫秒级的响应速度,同时保证高可用性和高一致性。
- 易用性高:向量检索服务提供了简洁易用的 SDK/API 接口,支持多种编程语言,如 Python、Java、Go 等,可以方便地对向量集合进行创建、导入、查询等操作,无需编写复杂的代码或配置文件。
- 可扩展性高:向量检索服务支持水平拓展,可以根据业务需求动态地调整向量集合的规模和性能,无需担心资源的限制或浪费。向量检索服务还支持多种索引类型,如 HNSW、IVF、NSG 等,可以根据不同的场景和需求选择合适的索引类型,实现最优的检索效果。
- 便捷性高:向量检索服务是一种全托管的服务,无需自己搭建和维护向量检索的环境,只需通过阿里云控制台或 API 即可轻松地使用向量检索服务。向量检索服务还提供了丰富的监控和告警功能,可以实时地查看向量集合的状态和性能,及时地发现和解决问题。
相比之下,其他向量检索工具在某些方面存在一些不足,如:
Elasticsearch:Elasticsearch 是一种基于 Lucene 的开源搜索引擎,它支持多种类型的数据,如文本、数值、地理位置等,但对于向量数据的支持不够完善,需要安装额外的插件,如 Elasticsearch-Vector-Scoring、Elasticsearch-LTR 等,才能实现向量检索的功能。此外,Elasticsearch 的性能受到 Lucene 的限制,无法支持高维度的向量数据,也不支持多种索引类型的选择,因此在向量检索的效果上不如专业的向量检索工具。
- Milvus:Milvus 是一种基于 Faiss 的开源向量检索引擎,它支持多种索引类型,如 HNSW、IVF、NSG 等,可以实现高效的向量检索功能。Milvus 的易用性和可扩展性也较高,它提供了多种编程语言的 SDK/API 接口,支持分布式部署和水平拓展。但是,Milvus 的便捷性不高,需要自己搭建和维护向量检索的环境,还需要自己处理向量生成的问题,无法直接使用预训练的模型或上传自己的模型,这增加了使用的难度和成本。
- Faiss:Faiss 是一种由 Facebook 研究院开发的开源向量检索库,它提供了多种优化的算法和数据结构,可以实现高性能的向量检索功能。Faiss 支持多种索引类型,如 HNSW、IVF、NSG 等,可以根据不同的场景和需求选择合适的索引类型,实现最优的检索效果。但是,Faiss 的易用性和可扩展性较低,它只提供了 C++ 和 Python 的接口,不支持其他编程语言,也不支持分布式部署和水平拓展。Faiss 的便捷性也不高,需要自己搭建和维护向量检索的环境,还需要自己处理向量生成的问题,无法直接使用预训练的模型或上传自己的模型,这增加了使用的难度和成本。
- 综上所述,向量检索服务在性能、易用性、可扩展性、便捷性等方面都优于其他向量检索工具,是一种适合多种应用场景的高效向量检索服务。向量检索服务是一种高效、易用、可扩展、便捷的向量检索服务,它可以帮助我实现多种应用场景的需求,提升我的业务效率和用户体验,同时降低我的成本和风险,是一种值得推荐的服务。

