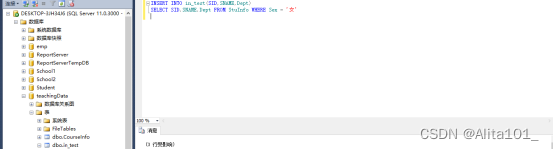
1、向量数据库可以做什么呢?
在互联网行业,通过结合企业领域知识和大模型语义理解能力来构建智能客服,提高了用户在线咨询体验和响应的速度。在游戏行业,通过构建智能游戏攻略和智能NPC,增加了游戏玩家的趣味性。在电商行业,以图搜图系统让用户所见即所搜,拍张照片就能快速定位到具体的商品。这一切智能化应用落地的背后,都离不开大模型和向量数据库的能力加持。向量数据库的具体使用场景繁多又丰富,小编也为你整理出了最热门的使用场景:
- 以图搜图服务,即通过图片检索图片的应用服务。
- 视频检索服务,即通过视频中的某些帧图片进行视频图片检索,来实现视频检索。
- 声纹检索服务,即通过音频匹配音频的应用服务。
- 推荐系统服务,即通过用户特征匹配实现推荐匹配的功能。
- 基于语义的文本检索和推荐,通过文本检索近似文本。
- 问答机器人,通过与大模型结合,提供高效的问答机器人服务。
- 文件去重,通过文件指纹特征来去除重复文件。
2、向量数据库的基础概念
不过,究竟什么是向量呢?使用向量数据库又涉及哪些”难懂“的专有名词呢?下面的表中列举了一些概念名词来为你答疑解惑。
名词 |
名词解释 |
向量 |
具有一定大小和方向的量,就像一行多列的矩阵,例如:[0.7, 0.1, 0.9, 0.9, 0.6, 0.6] |
向量距离 |
用于衡量非结构化数据之间的相似度 |
暴力搜索 |
又称为暴力查询,扫描数据表里所有向量,和给定的向量计算距离再排序 |
ANNS |
Approximate Nearest Neighbors Search,近似最近邻搜索 |
Embedding |
将数据映射到特征空间后的连续且稠密的高维向量 |
Retrieval Plugin |
帮助大模型和向量数据库交互,检索私有知识的插件 |
LangChain |
开发由语言模型驱动的应用程序的框架 |
3、向量分析的原理
向量数据库看着十分“高大上”,实际上,实现向量分析的原理还是很好理解的:通过AI算法提取非结构化数据的特征,然后利用特征向量作为非结构化数据的唯一标识,向量间的距离用于衡量非结构化数据之间的相似度,以此为基础进行向量检索,就像下图展示的这样:

4、向量数据库和大模型交互
进行向量检索的数据流转过程看似复杂,但拆开来看,复杂的流程中流露出结构化严谨的美感!以构建企业专属ChatBot为例,向量数仓和大模型的交互可大致分为四个部分:
1)文档预处理:将原始文档中的文本内容全部提取出来,根据语义切块成多个chunk,还可以额外做一些元数据抽取,敏感信息检测等行为。
2)特征提取和数据入库:将这些chunk都丢给embedding模型,来求取这些chunk的embedding,并将embedding和原始chunk一起存入到向量数据库中。
3)问题推理:结合聊天历史和新问题,推理出用户需要求解答案的独立问题。
4)向量检索:先求取独立问题的embedding,去向量数据库中搜索最相似的向量,获得最相近的内容知识。

5、向量距离计算方法
那么,什么叫做“相似度最高”的向量呢?其实,就是找到和给定向量的距离最短的Top K个向量记录啦!当前有很多计算向量距离的方法,常用的计算公式整理如下表:
向量距离 |
计算方法 |
适用场景 |
欧氏距离(L2) |
|
欧式距离衡量两个向量的大小,表示两个向量的距离 |
余弦相似度 |
|
余弦距离衡量两个向量在方向上的相似性,而不care两个向量的实际长度。 |
点积距离 |
D(x, y) = X *Y |
归一化之后求点积距离就是余弦距离 |
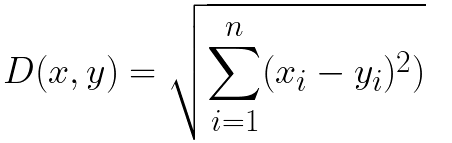
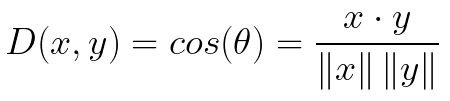
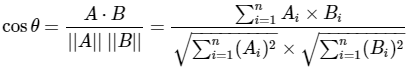
6、向量检索的算法
面对纷繁复杂且高要求的向量检索场景,向量检索算法也是在不断更新,各算法间的区别和使用场景如下表所示:
索引名称 |
索引类别 |
适用场景 |
说明 |
HNSW(推荐) |
基于图的索引 |
|
它按照一定的规则为图像构建多层导航结构。在这种结构中,上层更稀疏,节点之间的距离更远;下层更密集,节点之间的距离更近。搜索从最上层开始,在本层找到距离目标最近的节点,然后进入下一层开始下一次搜索。经过多次迭代,可以快速逼近目标位置。 |
FLAT |
不分类 |
|
FLAT索引不压缩向量,可以保证精确搜索结果。会和数据集中的每个向量进行比较,是最慢的索引。 |
IVF_FLAT |
基于量化的索引 |
|
将向量数据划分为nlist簇单元,目标输入向量会与每个簇中心比较距离。根据系统设置的查询集群数量(nprobe),相似性搜索结果仅基于目标输入与最相似集群中的向量进行比较。没有压缩,索引存的是原始向量。 |
IVF_SQ8 |
基于量化的索引 |
|
在IVF_FLAT基础上,该索引对向量进行了压缩,可以通过执行标量量化将每个 FLOAT(4 个字节)转换为 UINT8(1 个字节)。 |
IVF_PQ |
基于量化的索引 |
|
PQ(Product Quantization)将原始高维向量空间均匀分解为低维向量空间的笛卡尔积,然后对分解后的低维向量空间进行量化。乘积量化代替了计算目标向量到所有单元中心的距离,使得计算目标向量到每个低维空间的聚类中心的距离,大大降低了算法的时间复杂度和空间复杂度. 它的索引文件比 IVF_SQ8 还要小,但也会导致搜索向量时的精度损失。 |
ANNOY |
基于树的索引 |
|
它使用超平面将高维空间划分为多个子空间,然后将它们存储在树结构中。 |
7、AnalyticDB PostgreSQL 版向量数仓的优势
介绍了这么多的向量基础知识,大家是否对如何使用向量数据库仍有疑问呢?也在为寻找合适的向量数据库上手使用而烦恼呢?那这不得来看看阿里云原生数据仓库 AnalyticDB PostgreSQL 版,它在云原生数仓能力上全自研了企业级向量数据库,主旨是构建企业大模型的云上数据大脑,用户通过向量能力把企业文档、图片等非结构化信息补充到企业专属知识库中,结合大模型搭建ChatBot机器人和更丰富的智能化应用。作为一款企业级向量数据库产品,AnalyticDB PostgreSQL 版主要有以下4个优势:
1)一站式融合查询能力:用户只需要通过一条SQL即可实现结构化数据分析、向量分析和全文检索三者融合,实现多路召回,比分别采用三种数据库得到分析结果再进行手动融合,在易用性、成本、准确性上都要更优。

2)社区合作丰富:在AIGC应用的构建过程中,向量数据库和大模型的协作密不可分,因此AnalyticDB PostgreSQL的第二个优势是和主流社区合作紧密,它是国内云厂商中首个被两个主流社区集成的向量数据库引擎;同时,支持对接通义千问、ChatGpt、ChatGLM等主流大模型。


3)向量功能完善,性能极致
- AnalyticDB PostgreSQL给使用者提供了丰富的功能和极致的性能:
- 支持向量数据流式导入和索引压缩
- 较比同类产品有更高的写入吞吐和查询性能
- 支持原子性和事务
- 支持欧式距离、点积距离、汉明距离、余弦距离等相似度算法
- 支持融合查询,从而实现多维度权限管理
- 计划支持一站式的AI服务
4)解决方案可快速落地:
- 提供计算巢一键部署方式,在30分钟内一键构建企业专属大模型和向量数据库,快速搭建企业级ChatBot
/article/1240791?spm=5176.28361150.J_6772997330.1.16d5240aoJr3oV
- 并支持构建以图搜图系统,广泛应用于电商等领域
https://help.aliyun.com/document_detail/2391414.html?spm=5176.28361150.J_6772997330.2.16d5240aoJr3oV
8、快来关注
专题页:
https://www.aliyun.com/activity/database/adbpg_vector
一键启动AIGC应用:
钉钉群: