2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
dataCoord的Compaction分析
milvus版本:2.3.2
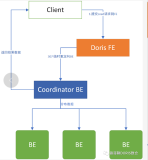
流程图:

compaction用来合并对象存储的小文件,将小的segment合并为大的segment。
Compaction 有一个配置项来控制是否启用自动压缩。此配置是全局的,会影响系统中的所有集合。
dataCoord.enableCompaction = true
dataCoord.compaction.enableAutoCompaction = true
enableAutoCompaction生效的前提是enableCompaction为true。
1.启动dataCoord:
func (s *Server) startDataCoord() {
if Params.DataCoordCfg.EnableCompaction.GetAsBool() {
s.compactionHandler.start()
s.compactionTrigger.start()
}
s.startServerLoop()
s.stateCode.Store(commonpb.StateCode_Healthy)
sessionutil.SaveServerInfo(typeutil.DataCoordRole, s.session.ServerID)
}
2.进入s.compactionHandler.start()
func (c *compactionPlanHandler) start() {
interval := Params.DataCoordCfg.CompactionCheckIntervalInSeconds.GetAsDuration(time.Second)
c.quit = make(chan struct{
})
c.wg.Add(1)
go func() {
defer c.wg.Done()
ticker := time.NewTicker(interval)
defer ticker.Stop()
for {
select {
case <-c.quit:
log.Info("compaction handler quit")
return
case <-ticker.C:
cctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
ts, err := c.allocator.allocTimestamp(cctx)
if err != nil {
log.Warn("unable to alloc timestamp", zap.Error(err))
cancel()
continue
}
cancel()
_ = c.updateCompaction(ts)
}
}
}()
}
CompactionCheckIntervalInSeconds默认10秒。10秒更新一次状态。
3.进入s.compactionTrigger.start()
func (t *compactionTrigger) start() {
t.quit = make(chan struct{
})
t.globalTrigger = time.NewTicker(Params.DataCoordCfg.GlobalCompactionInterval.GetAsDuration(time.Second))
t.wg.Add(2)
go func() {
defer logutil.LogPanic()
defer t.wg.Done()
for {
select {
case <-t.quit:
log.Info("compaction trigger quit")
return
case signal := <-t.signals:
switch {
case signal.isGlobal:
// 处理全局compaction信号
t.handleGlobalSignal(signal)
default:
// 处理collection级别信号
t.handleSignal(signal)
// shouldn't reset, otherwise a frequent flushed collection will affect other collections
// t.globalTrigger.Reset(Params.DataCoordCfg.GlobalCompactionInterval)
}
}
}
}()
// 触发全局compaction信号
go t.startGlobalCompactionLoop()
}
GlobalCompactionInterval默认60秒。
这段代码启动了2个goroutine。
第1个goroutine里面,判断compaction信号(signal)是全局还是collection级别。
4.进入t.handleGlobalSignal(signal)
func (t *compactionTrigger) handleGlobalSignal(signal *compactionSignal) {
t.forceMu.Lock()
defer t.forceMu.Unlock()
log := log.With(zap.Int64("compactionID", signal.id))
// 返回Channel-Partition维度的segment
m := t.meta.GetSegmentsChanPart(func(segment *SegmentInfo) bool {
// segment选择器(选择算法)
return (signal.collectionID == 0 || segment.CollectionID == signal.collectionID) &&
isSegmentHealthy(segment) &&
isFlush(segment) &&
!segment.isCompacting && // not compacting now
!segment.GetIsImporting() // not importing now
}) // m is list of chanPartSegments, which is channel-partition organized segments
if len(m) == 0 {
return
}
ts, err := t.allocTs()
......
for _, group := range m {
if !signal.isForce && t.compactionHandler.isFull() {
break
}
if Params.DataCoordCfg.IndexBasedCompaction.GetAsBool() {
group.segments = FilterInIndexedSegments(t.handler, t.meta, group.segments...)
}
isDiskIndex, err := t.updateSegmentMaxSize(group.segments)
if err != nil {
log.Warn("failed to update segment max size", zap.Error(err))
continue
}
coll, err := t.getCollection(group.collectionID)
......
if !signal.isForce && !t.isCollectionAutoCompactionEnabled(coll) {
log.RatedInfo(20, "collection auto compaction disabled",
zap.Int64("collectionID", group.collectionID),
)
return
}
ct, err := t.getCompactTime(ts, coll)
......
// 寻找需要compaction的segment,产生合并plan
plans := t.generatePlans(group.segments, signal.isForce, isDiskIndex, ct)
for _, plan := range plans {
segIDs := fetchSegIDs(plan.GetSegmentBinlogs())
if !signal.isForce && t.compactionHandler.isFull() {
......
}
start := time.Now()
if err := t.fillOriginPlan(plan); err != nil {
......
}
// 执行compaction
err := t.compactionHandler.execCompactionPlan(signal, plan)
if err != nil {
......
}
segIDMap := make(map[int64][]*datapb.FieldBinlog, len(plan.SegmentBinlogs))
for _, seg := range plan.SegmentBinlogs {
segIDMap[seg.SegmentID] = seg.Deltalogs
}
log.Info("time cost of generating global compaction",
zap.Any("segID2DeltaLogs", segIDMap),
zap.Int64("planID", plan.PlanID),
zap.Int64("time cost", time.Since(start).Milliseconds()),
zap.Int64("collectionID", signal.collectionID),
zap.String("channel", group.channelName),
zap.Int64("partitionID", group.partitionID),
zap.Int64s("segmentIDs", segIDs))
}
}
}
5.进入t.generatePlans()
func (t *compactionTrigger) generatePlans(segments []*SegmentInfo, force bool, isDiskIndex bool, compactTime *compactTime) []*datapb.CompactionPlan {
// find segments need internal compaction
// TODO add low priority candidates, for example if the segment is smaller than full 0.9 * max segment size but larger than small segment boundary, we only execute compaction when there are no compaction running actively
var prioritizedCandidates []*SegmentInfo
var smallCandidates []*SegmentInfo
var nonPlannedSegments []*SegmentInfo
// TODO, currently we lack of the measurement of data distribution, there should be another compaction help on redistributing segment based on scalar/vector field distribution
for _, segment := range segments {
segment := segment.ShadowClone()
// TODO should we trigger compaction periodically even if the segment has no obvious reason to be compacted?
// 判断是否需要SingleCompaction
if force || t.ShouldDoSingleCompaction(segment, isDiskIndex, compactTime) {
prioritizedCandidates = append(prioritizedCandidates, segment)
} else if t.isSmallSegment(segment) {
// 判断是否属于small segment
smallCandidates = append(smallCandidates, segment)
} else {
nonPlannedSegments = append(nonPlannedSegments, segment)
}
}
var plans []*datapb.CompactionPlan
// sort segment from large to small
// 排序,从大到小
sort.Slice(prioritizedCandidates, func(i, j int) bool {
if prioritizedCandidates[i].GetNumOfRows() != prioritizedCandidates[j].GetNumOfRows() {
return prioritizedCandidates[i].GetNumOfRows() > prioritizedCandidates[j].GetNumOfRows()
}
return prioritizedCandidates[i].GetID() < prioritizedCandidates[j].GetID()
})
// 排序,从大到小
sort.Slice(smallCandidates, func(i, j int) bool {
if smallCandidates[i].GetNumOfRows() != smallCandidates[j].GetNumOfRows() {
return smallCandidates[i].GetNumOfRows() > smallCandidates[j].GetNumOfRows()
}
return smallCandidates[i].GetID() < smallCandidates[j].GetID()
})
// Sort non-planned from small to large.
// 排序,从大到小
sort.Slice(nonPlannedSegments, func(i, j int) bool {
if nonPlannedSegments[i].GetNumOfRows() != nonPlannedSegments[j].GetNumOfRows() {
return nonPlannedSegments[i].GetNumOfRows() < nonPlannedSegments[j].GetNumOfRows()
}
return nonPlannedSegments[i].GetID() > nonPlannedSegments[j].GetID()
})
getSegmentIDs := func(segment *SegmentInfo, _ int) int64 {
return segment.GetID()
}
// greedy pick from large segment to small, the goal is to fill each segment to reach 512M
// we must ensure all prioritized candidates is in a plan
// TODO the compaction selection policy should consider if compaction workload is high
for len(prioritizedCandidates) > 0 {
......
}
getSegIDsFromPlan := func(plan *datapb.CompactionPlan) []int64 {
var segmentIDs []int64
for _, binLog := range plan.GetSegmentBinlogs() {
segmentIDs = append(segmentIDs, binLog.GetSegmentID())
}
return segmentIDs
}
var remainingSmallSegs []*SegmentInfo
// check if there are small candidates left can be merged into large segments
for len(smallCandidates) > 0 {
var bucket []*SegmentInfo
// pop out the first element
segment := smallCandidates[0]
bucket = append(bucket, segment)
// 下标为0的是最大的segment
smallCandidates = smallCandidates[1:]
var result []*SegmentInfo
free := segment.GetMaxRowNum() - segment.GetNumOfRows()
// for small segment merge, we pick one largest segment and merge as much as small segment together with it
// Why reverse? try to merge as many segments as expected.
// for instance, if a 255M and 255M is the largest small candidates, they will never be merged because of the MinSegmentToMerge limit.
// result为需要合并的segments
// MaxSegmentToMerge默认为30
smallCandidates, result, _ = reverseGreedySelect(smallCandidates, free, Params.DataCoordCfg.MaxSegmentToMerge.GetAsInt()-1)
bucket = append(bucket, result...)
var size int64
var targetRow int64
for _, s := range bucket {
size += s.getSegmentSize()
targetRow += s.GetNumOfRows()
}
// only merge if candidate number is large than MinSegmentToMerge or if target row is large enough
if len(bucket) >= Params.DataCoordCfg.MinSegmentToMerge.GetAsInt() ||
len(bucket) > 1 && t.isCompactableSegment(targetRow, segment) {
// 产生plan
plan := segmentsToPlan(bucket, compactTime)
log.Info("generate a plan for small candidates",
zap.Int64s("plan segmentIDs", lo.Map(bucket, getSegmentIDs)),
zap.Int64("target segment row", targetRow),
zap.Int64("target segment size", size))
plans = append(plans, plan)
} else {
remainingSmallSegs = append(remainingSmallSegs, bucket...)
}
}
// Try adding remaining segments to existing plans.
for i := len(remainingSmallSegs) - 1; i >= 0; i-- {
s := remainingSmallSegs[i]
if !isExpandableSmallSegment(s) {
continue
}
// Try squeeze this segment into existing plans. This could cause segment size to exceed maxSize.
for _, plan := range plans {
if plan.TotalRows+s.GetNumOfRows() <= int64(Params.DataCoordCfg.SegmentExpansionRate.GetAsFloat()*float64(s.GetMaxRowNum())) {
segmentBinLogs := &datapb.CompactionSegmentBinlogs{
SegmentID: s.GetID(),
FieldBinlogs: s.GetBinlogs(),
Field2StatslogPaths: s.GetStatslogs(),
Deltalogs: s.GetDeltalogs(),
}
plan.TotalRows += s.GetNumOfRows()
plan.SegmentBinlogs = append(plan.SegmentBinlogs, segmentBinLogs)
log.Info("small segment appended on existing plan",
zap.Int64("segmentID", s.GetID()),
zap.Int64("target rows", plan.GetTotalRows()),
zap.Int64s("plan segmentID", getSegIDsFromPlan(plan)),
)
remainingSmallSegs = append(remainingSmallSegs[:i], remainingSmallSegs[i+1:]...)
break
}
}
}
// If there are still remaining small segments, try adding them to non-planned segments.
for _, npSeg := range nonPlannedSegments {
bucket := []*SegmentInfo{
npSeg}
targetRow := npSeg.GetNumOfRows()
for i := len(remainingSmallSegs) - 1; i >= 0; i-- {
// Note: could also simply use MaxRowNum as limit.
if targetRow+remainingSmallSegs[i].GetNumOfRows() <=
int64(Params.DataCoordCfg.SegmentExpansionRate.GetAsFloat()*float64(npSeg.GetMaxRowNum())) {
bucket = append(bucket, remainingSmallSegs[i])
targetRow += remainingSmallSegs[i].GetNumOfRows()
remainingSmallSegs = append(remainingSmallSegs[:i], remainingSmallSegs[i+1:]...)
}
}
if len(bucket) > 1 {
plan := segmentsToPlan(bucket, compactTime)
plans = append(plans, plan)
log.Info("generate a plan for to squeeze small candidates into non-planned segment",
zap.Int64s("plan segmentIDs", lo.Map(bucket, getSegmentIDs)),
zap.Int64("target segment row", targetRow),
)
}
}
return plans
}
t.isSmallSegment(segment) 判断是否属于small segment。
func (t *compactionTrigger) isSmallSegment(segment *SegmentInfo) bool {
return segment.GetNumOfRows() < int64(float64(segment.GetMaxRowNum())*Params.DataCoordCfg.SegmentSmallProportion.GetAsFloat())
}
segment.GetMaxRowNum()为3441480。
Params.DataCoordCfg.SegmentSmallProportion.GetAsFloat()为0.5。
这里只考虑smallCandidates。因此执行流程如下:
func (t *compactionTrigger) generatePlans(segments []*SegmentInfo, force bool, isDiskIndex bool, compactTime *compactTime) []*datapb.CompactionPlan {
// find segments need internal compaction
// TODO add low priority candidates, for example if the segment is smaller than full 0.9 * max segment size but larger than small segment boundary, we only execute compaction when there are no compaction running actively
var prioritizedCandidates []*SegmentInfo
var smallCandidates []*SegmentInfo
var nonPlannedSegments []*SegmentInfo
// TODO, currently we lack of the measurement of data distribution, there should be another compaction help on redistributing segment based on scalar/vector field distribution
for _, segment := range segments {
segment := segment.ShadowClone()
// TODO should we trigger compaction periodically even if the segment has no obvious reason to be compacted?
// 判断是否需要SingleCompaction
if force || t.ShouldDoSingleCompaction(segment, isDiskIndex, compactTime) {
prioritizedCandidates = append(prioritizedCandidates, segment)
} else if t.isSmallSegment(segment) {
// 判断是否属于small segment
smallCandidates = append(smallCandidates, segment)
} else {
nonPlannedSegments = append(nonPlannedSegments, segment)
}
}
var plans []*datapb.CompactionPlan
// sort segment from large to small
// 排序,从大到小
sort.Slice(prioritizedCandidates, func(i, j int) bool {
if prioritizedCandidates[i].GetNumOfRows() != prioritizedCandidates[j].GetNumOfRows() {
return prioritizedCandidates[i].GetNumOfRows() > prioritizedCandidates[j].GetNumOfRows()
}
return prioritizedCandidates[i].GetID() < prioritizedCandidates[j].GetID()
})
// 排序,从大到小
sort.Slice(smallCandidates, func(i, j int) bool {
if smallCandidates[i].GetNumOfRows() != smallCandidates[j].GetNumOfRows() {
return smallCandidates[i].GetNumOfRows() > smallCandidates[j].GetNumOfRows()
}
return smallCandidates[i].GetID() < smallCandidates[j].GetID()
})
// Sort non-planned from small to large.
// 排序,从大到小
sort.Slice(nonPlannedSegments, func(i, j int) bool {
if nonPlannedSegments[i].GetNumOfRows() != nonPlannedSegments[j].GetNumOfRows() {
return nonPlannedSegments[i].GetNumOfRows() < nonPlannedSegments[j].GetNumOfRows()
}
return nonPlannedSegments[i].GetID() > nonPlannedSegments[j].GetID()
})
getSegmentIDs := func(segment *SegmentInfo, _ int) int64 {
return segment.GetID()
}
// greedy pick from large segment to small, the goal is to fill each segment to reach 512M
// we must ensure all prioritized candidates is in a plan
// TODO the compaction selection policy should consider if compaction workload is high
for len(prioritizedCandidates) > 0 {
......
}
getSegIDsFromPlan := func(plan *datapb.CompactionPlan) []int64 {
var segmentIDs []int64
for _, binLog := range plan.GetSegmentBinlogs() {
segmentIDs = append(segmentIDs, binLog.GetSegmentID())
}
return segmentIDs
}
var remainingSmallSegs []*SegmentInfo
// check if there are small candidates left can be merged into large segments
for len(smallCandidates) > 0 {
var bucket []*SegmentInfo
// pop out the first element
segment := smallCandidates[0]
bucket = append(bucket, segment)
// 下标为0的是最大的segment
smallCandidates = smallCandidates[1:]
var result []*SegmentInfo
free := segment.GetMaxRowNum() - segment.GetNumOfRows()
// for small segment merge, we pick one largest segment and merge as much as small segment together with it
// Why reverse? try to merge as many segments as expected.
// for instance, if a 255M and 255M is the largest small candidates, they will never be merged because of the MinSegmentToMerge limit.
// result为需要合并的segments
// MaxSegmentToMerge默认为30
smallCandidates, result, _ = reverseGreedySelect(smallCandidates, free, Params.DataCoordCfg.MaxSegmentToMerge.GetAsInt()-1)
bucket = append(bucket, result...)
var size int64
var targetRow int64
for _, s := range bucket {
size += s.getSegmentSize()
targetRow += s.GetNumOfRows()
}
// only merge if candidate number is large than MinSegmentToMerge or if target row is large enough
// MinSegmentToMerge默认为3
if len(bucket) >= Params.DataCoordCfg.MinSegmentToMerge.GetAsInt() ||
len(bucket) > 1 && t.isCompactableSegment(targetRow, segment) {
plan := segmentsToPlan(bucket, compactTime)
log.Info("generate a plan for small candidates",
zap.Int64s("plan segmentIDs", lo.Map(bucket, getSegmentIDs)),
zap.Int64("target segment row", targetRow),
zap.Int64("target segment size", size))
plans = append(plans, plan)
} else {
remainingSmallSegs = append(remainingSmallSegs, bucket...)
}
}
// Try adding remaining segments to existing plans.
for i := len(remainingSmallSegs) - 1; i >= 0; i-- {
......
}
// If there are still remaining small segments, try adding them to non-planned segments.
for _, npSeg := range nonPlannedSegments {
......
}
return plans
}
MinSegmentToMerge默认设置为3,也就是最少需要3个segment才进行合并。
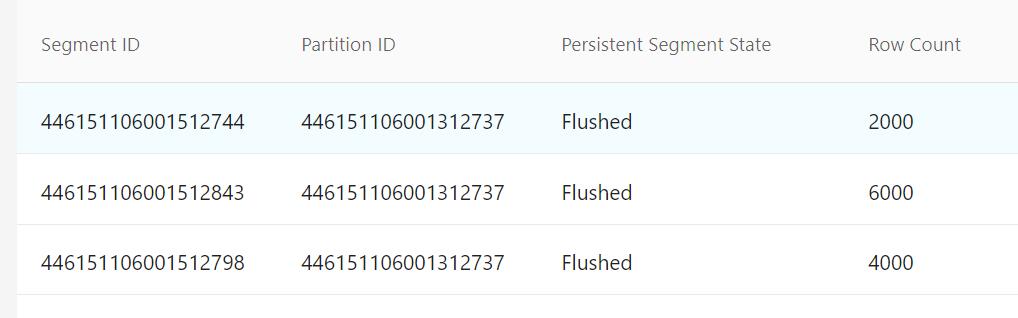
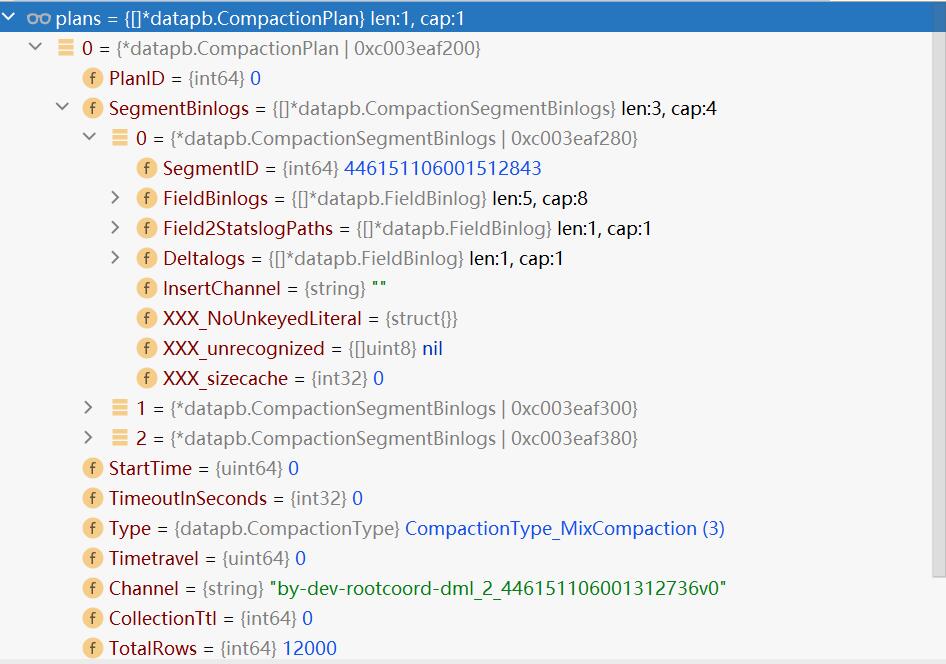
[INFO] [datacoord/compaction_trigger.go:664] ["generate a plan for small candidates"] ["plan segmentIDs"="[446150338661456776,446150338661256646,446150338661456735]"] ["target segment row"=12000] ["target segment size"=953490]
6.查看plans
plans := t.generatePlans(group.segments, signal.isForce, isDiskIndex, ct)
查看plans的值:
下面是待合并的segment:
7.执行compaction
t.compactionHandler.execCompactionPlan(signal, plan)
8.进入execCompactionPlan
// execCompactionPlan start to execute plan and return immediately
func (c *compactionPlanHandler) execCompactionPlan(signal *compactionSignal, plan *datapb.CompactionPlan) error {
c.mu.Lock()
defer c.mu.Unlock()
nodeID, err := c.chManager.FindWatcher(plan.GetChannel())
if err != nil {
log.Error("failed to find watcher", zap.Int64("planID", plan.GetPlanID()), zap.Error(err))
return err
}
log := log.With(zap.Int64("planID", plan.GetPlanID()), zap.Int64("nodeID", nodeID))
c.setSegmentsCompacting(plan, true)
task := &compactionTask{
triggerInfo: signal,
plan: plan,
state: pipelining,
dataNodeID: nodeID,
}
c.plans[plan.PlanID] = task
c.executingTaskNum++
go func() {
log.Info("acquire queue")
c.acquireQueue(nodeID)
ts, err := c.allocator.allocTimestamp(context.TODO())
if err != nil {
log.Warn("Alloc start time for CompactionPlan failed", zap.Error(err))
// update plan ts to TIMEOUT ts
c.updateTask(plan.PlanID, setState(executing), setStartTime(tsTimeout))
return
}
c.updateTask(plan.PlanID, setStartTime(ts))
err = c.sessions.Compaction(nodeID, plan)
c.updateTask(plan.PlanID, setState(executing))
if err != nil {
log.Warn("try to Compaction but DataNode rejected", zap.Error(err))
// do nothing here, prevent double release, see issue#21014
// release queue will be done in `updateCompaction`
return
}
log.Info("start compaction")
}()
return nil
}
调用堆栈:
execCompactionPlan()(internal\datacoord\compaction.go)
|--c.sessions.Compaction(nodeID, plan)(同上)
|--cli.Compaction(ctx, plan)(internal\datacoord\session_manager.go)
|--Compaction()(internal\datanode\services.go)
|--compactionTask.compact()(internal\datanode\compactor.go)
总结:
compaction相关参数:
dataCoord.enableCompaction = true
dataCoord.compaction.enableAutoCompaction = true
dataCoord.compaction.indexBasedCompaction = true
dataCoord.compaction.global.interval = 60 #默认60秒,触发compaction信号
dataCoord.compaction.check.interval = 10 #默认10秒,更新状态
dataCoord.segment.smallProportion = 0.5 #默认0.5
dataCoord.compaction.max.segment = 30 #默认30
dataCoord.compaction.min.segment = 3 #默认3