2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
CreateCollection API执行流程源码解析
milvus版本:v2.3.2
CreateCollection这个API流程较长,也是milvus的核心API之一,涉及的内容比较复杂。这里只介绍和元数据相关的流程。
整体架构:
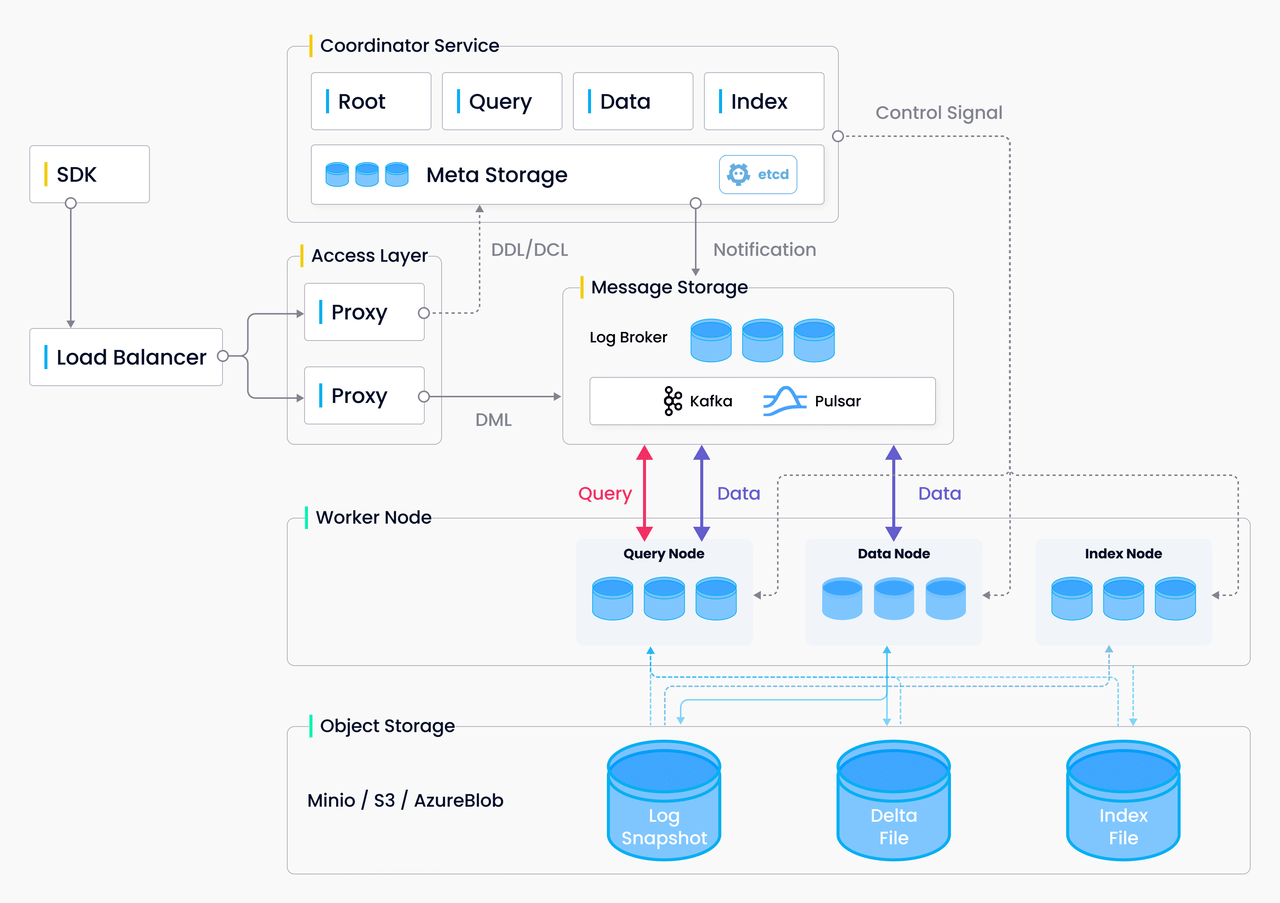
CreateCollection 的数据流向:
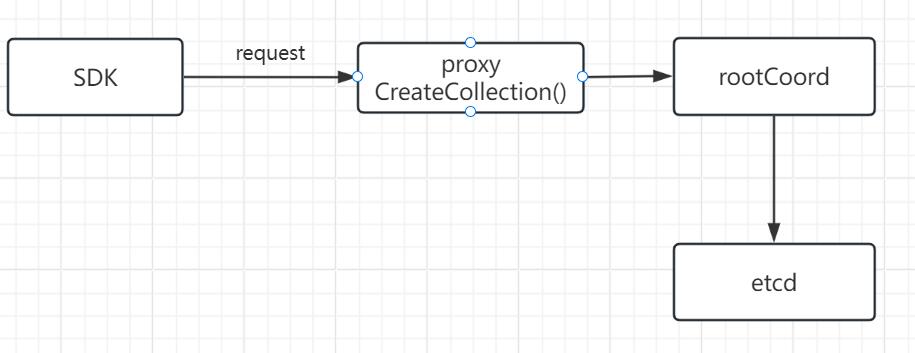
1.客户端sdk发出CreateCollection API请求。
from pymilvus import (
connections,
FieldSchema, CollectionSchema, DataType,
Collection,
)
num_entities, dim = 3000, 1024
print("start connecting to Milvus")
connections.connect("default", host="192.168.230.71", port="19530")
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs")
print("Create collection `hello_milvus`")
hello_milvus = Collection("hello_milvus", schema, consistency_level="Strong",shards_num=2)
客户端SDK向proxy发送一个CreateCollection API请求,创建一个名为hello_milvus的collection。
2.客户端接受API请求,将request封装为createCollectionTask,并压入ddQueue队列。
代码路径:internal\proxy\impl.go
func (node *Proxy) CreateCollection(ctx context.Context, request *milvuspb.CreateCollectionRequest) (*commonpb.Status, error) {
......
// request封装为task
cct := &createCollectionTask{
ctx: ctx,
Condition: NewTaskCondition(ctx),
CreateCollectionRequest: request,
rootCoord: node.rootCoord,
}
......
// 将task压入ddQueue队列
if err := node.sched.ddQueue.Enqueue(cct); err != nil {
......
}
......
// 等待cct执行完
if err := cct.WaitToFinish(); err != nil {
......
}
......
}
3.执行createCollectionTask的3个方法PreExecute、Execute、PostExecute。
PreExecute()一般为参数校验等工作。
Execute()一般为真正执行逻辑。
PostExecute()执行完后的逻辑,什么都不做,返回nil。
代码路径:internal\proxy\task.go
func (t *createCollectionTask) Execute(ctx context.Context) error {
var err error
t.result, err = t.rootCoord.CreateCollection(ctx, t.CreateCollectionRequest)
return err
}
从代码可以看出调用了rootCoord的CreateCollection接口。
4.进入rootCoord的CreateCollection接口。
代码路径:internal\rootcoord\root_coord.go
继续将请求封装为rootcoord里的createCollectionTask
func (c *Core) CreateCollection(ctx context.Context, in *milvuspb.CreateCollectionRequest) (*commonpb.Status, error) {
......
// 封装为createCollectionTask
t := &createCollectionTask{
baseTask: newBaseTask(ctx, c),
Req: in,
}
// 加入调度
if err := c.scheduler.AddTask(t); err != nil {
......
}
// 等待task完成
if err := t.WaitToFinish(); err != nil {
......
}
......
}
5.执行createCollectionTask的Prepare、Execute、NotifyDone方法。
Execute()为核心方法。
代码路径:internal\rootcoord\create_collection_task.go
func (t *createCollectionTask) Execute(ctx context.Context) error {
// collID为collectionID,在Prepare()里分配
// partIDs为partitionID,在Prepare()里分配
collID := t.collID
partIDs := t.partIDs
// 产生时间戳
ts, err := t.getCreateTs()
if err != nil {
return err
}
// vchanNames为虚拟channel,在Prepare()里分配
// chanNames为物理channel,在Prepare()里分配
vchanNames := t.channels.virtualChannels
chanNames := t.channels.physicalChannels
startPositions, err := t.addChannelsAndGetStartPositions(ctx, ts)
if err != nil {
t.core.chanTimeTick.removeDmlChannels(t.channels.physicalChannels...)
return err
}
// 填充partition,创建collection的时候,默认只有一个名为"Default partition"的partition。
partitions := make([]*model.Partition, len(partIDs))
for i, partID := range partIDs {
partitions[i] = &model.Partition{
PartitionID: partID,
PartitionName: t.partitionNames[i],
PartitionCreatedTimestamp: ts,
CollectionID: collID,
State: pb.PartitionState_PartitionCreated,
}
}
// 填充collection
// 可以看出collection由collID、dbid、schemaName、fields、vchanName、chanName、partition、shardNum等组成
collInfo := model.Collection{
CollectionID: collID,
DBID: t.dbID,
Name: t.schema.Name,
Description: t.schema.Description,
AutoID: t.schema.AutoID,
Fields: model.UnmarshalFieldModels(t.schema.Fields),
VirtualChannelNames: vchanNames,
PhysicalChannelNames: chanNames,
ShardsNum: t.Req.ShardsNum,
ConsistencyLevel: t.Req.ConsistencyLevel,
StartPositions: toKeyDataPairs(startPositions),
CreateTime: ts,
State: pb.CollectionState_CollectionCreating,
Partitions: partitions,
Properties: t.Req.Properties,
EnableDynamicField: t.schema.EnableDynamicField,
}
clone := collInfo.Clone()
existedCollInfo, err := t.core.meta.GetCollectionByName(ctx, t.Req.GetDbName(), t.Req.GetCollectionName(), typeutil.MaxTimestamp)
if err == nil {
equal := existedCollInfo.Equal(*clone)
if !equal {
return fmt.Errorf("create duplicate collection with different parameters, collection: %s", t.Req.GetCollectionName())
}
log.Warn("add duplicate collection", zap.String("collection", t.Req.GetCollectionName()), zap.Uint64("ts", ts))
return nil
}
// 分为多个step执行,每一个undoTask由todoStep和undoStep构成
// 执行todoStep,报错则执行undoStep
undoTask := newBaseUndoTask(t.core.stepExecutor)
undoTask.AddStep(&expireCacheStep{
baseStep: baseStep{
core: t.core},
dbName: t.Req.GetDbName(),
collectionNames: []string{
t.Req.GetCollectionName()},
collectionID: InvalidCollectionID,
ts: ts,
}, &nullStep{
})
undoTask.AddStep(&nullStep{
}, &removeDmlChannelsStep{
baseStep: baseStep{
core: t.core},
pChannels: chanNames,
})
undoTask.AddStep(&addCollectionMetaStep{
baseStep: baseStep{
core: t.core},
coll: &collInfo,
}, &deleteCollectionMetaStep{
baseStep: baseStep{
core: t.core},
collectionID: collID,
ts: ts,
})
undoTask.AddStep(&nullStep{
}, &unwatchChannelsStep{
baseStep: baseStep{
core: t.core},
collectionID: collID,
channels: t.channels,
isSkip: !Params.CommonCfg.TTMsgEnabled.GetAsBool(),
})
undoTask.AddStep(&watchChannelsStep{
baseStep: baseStep{
core: t.core},
info: &watchInfo{
ts: ts,
collectionID: collID,
vChannels: t.channels.virtualChannels,
startPositions: toKeyDataPairs(startPositions),
schema: &schemapb.CollectionSchema{
Name: collInfo.Name,
Description: collInfo.Description,
AutoID: collInfo.AutoID,
Fields: model.MarshalFieldModels(collInfo.Fields),
},
},
}, &nullStep{
})
undoTask.AddStep(&changeCollectionStateStep{
baseStep: baseStep{
core: t.core},
collectionID: collID,
state: pb.CollectionState_CollectionCreated,
ts: ts,
}, &nullStep{
})
return undoTask.Execute(ctx)
}
创建collection涉及多个步骤,可以看出这里依次分为expireCacheStep、addCollectionMetaStep、watchChannelsStep、changeCollectionStateStep这几个步骤,关于etcd元数据的操作,这里重点关注addCollectionMetaStep。其余step另用篇幅进行讲解。
6.进入addCollectionMetaStep,执行其Execute()方法。
代码路径:internal\rootcoord\step.go
func (s *addCollectionMetaStep) Execute(ctx context.Context) ([]nestedStep, error) {
err := s.core.meta.AddCollection(ctx, s.coll)
return nil, err
}
在这里重点研究s.core.meta.AddCollection()这个方法做了什么事情。
调用栈如下:
CreateCollection()(internal\proxy\impl.go)
|--Execute()(internal\proxy\task.go)
|--t.rootCoord.CreateCollection()(同上)
|--CreateCollection()(rpc调用,internal\rootcoord\root_coord.go)
|--Execute()(internal\rootcoord\create_collection_task.go)
|--Execute()(internal\rootcoord\step.go)
|--s.core.meta.AddCollection()
|--AddCollection()(internal\rootcoord\meta_table.go)
|--mt.catalog.CreateCollection()
|--CreateCollection()(internal\metastore\kv\rootcoord\kv_catalog.go)
|--kc.Snapshot.Save()
|--etcd.SaveByBatchWithLimit()
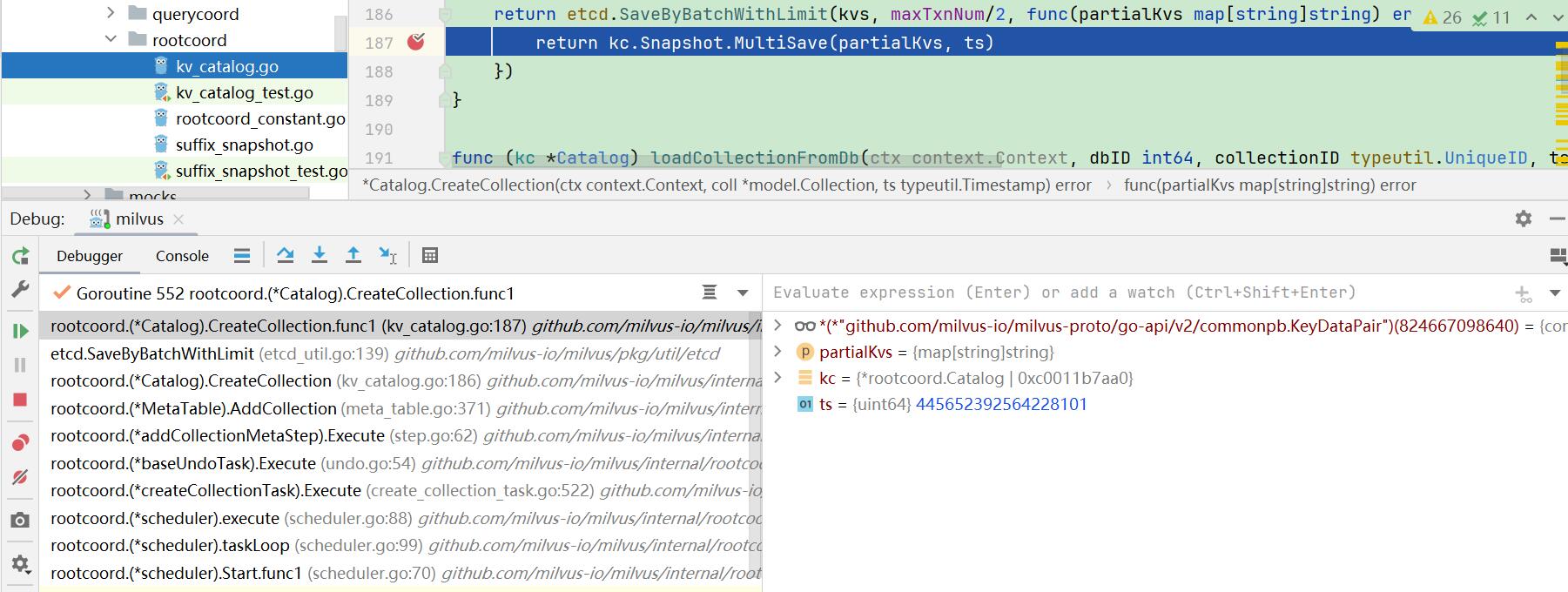
在etcd产生collection相关的key:
==root-coord/database/collection-info/1/445652621026918798==
value的值的结构为etcdpb.CollectionInfo,然后进行protobuf序列化后存入etcd。
因此etcd存储的是二进制数据。
collSchema := &schemapb.CollectionSchema{
Name: coll.Name,
Description: coll.Description,
AutoID: coll.AutoID,
EnableDynamicField: coll.EnableDynamicField,
}
collectionPb := &pb.CollectionInfo{
ID: coll.CollectionID,
DbId: coll.DBID,
Schema: collSchema,
CreateTime: coll.CreateTime,
VirtualChannelNames: coll.VirtualChannelNames,
PhysicalChannelNames: coll.PhysicalChannelNames,
ShardsNum: coll.ShardsNum,
ConsistencyLevel: coll.ConsistencyLevel,
StartPositions: coll.StartPositions,
State: coll.State,
Properties: coll.Properties,
}

可以看出collection由ID、DbId、schema等组成,其中schema不记录Fields,也不记录partitionID、partitionName、FieldIndex。其它信息由另外的key-value记录。
func (kc *Catalog) CreateCollection(ctx context.Context, coll *model.Collection, ts typeutil.Timestamp) error {
if coll.State != pb.CollectionState_CollectionCreating {
return fmt.Errorf("cannot create collection with state: %s, collection: %s", coll.State.String(), coll.Name)
}
// 构建key的规则
k1 := BuildCollectionKey(coll.DBID, coll.CollectionID)
collInfo := model.MarshalCollectionModel(coll)
// 序列化
v1, err := proto.Marshal(collInfo)
if err != nil {
return fmt.Errorf("failed to marshal collection info: %s", err.Error())
}
// 写入etcd
if err := kc.Snapshot.Save(k1, string(v1), ts); err != nil {
return err
}
......
}
跟踪BuildCollectionKey()函数,不难得出key的规则。整理如下:
key规则:
- 前缀/root-coord/database/collection-info/{dbID}/{collectionID}
- 前缀/snapshots/root-coord/database/collection-info/{dbID}/{collectionID}_ts{时间戳}
根据路径能够反映出collection属于哪个DB。默认数据库名为default,dbID为1。
在etcd还会产生partition相关的key:
==root-coord/partitions/445653146967736660/445653146967736661==
value的值的结构为etcdpb.PartitionInfo,然后进行protobuf序列化后存入etcd。
因此etcd存储的是二进制数据。
&pb.PartitionInfo{
PartitionID: partition.PartitionID,
PartitionName: partition.PartitionName,
PartitionCreatedTimestamp: partition.PartitionCreatedTimestamp,
CollectionId: partition.CollectionID,
State: partition.State,
}
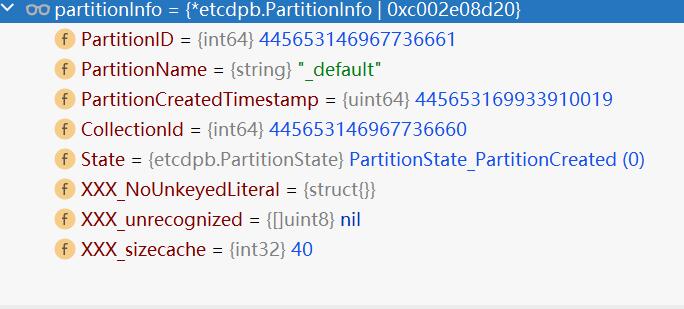
可以看出来partition包括partitionID、partitionName、collectionId等。
for _, partition := range coll.Partitions {
k := BuildPartitionKey(coll.CollectionID, partition.PartitionID)
partitionInfo := model.MarshalPartitionModel(partition)
v, err := proto.Marshal(partitionInfo)
if err != nil {
return err
}
kvs[k] = string(v)
}
跟踪BuildPartitionKey()函数,不难得出key的规则。整理如下:
key规则:
前缀/root-coord/partitions/{collectionID}/{partitionID}
前缀/snapshots/root-coord/partitions/{collectionID}/{partitionID}_ts{时间戳}
由路径可以反映出partition属于哪个collection。
一个collection可以包含多个partition。默认partition名为:_default。
分区名称可配置(milvus.yml):
common.defaultPartitionName
在etcd还会产生field相关的key:
==root-coord/fields/445653146967736660/100==
value的值的结构为schemapb.FieldSchema ,然后进行protobuf序列化后存入etcd。
因此etcd存储的是二进制数据。
&schemapb.FieldSchema{
FieldID: field.FieldID,
Name: field.Name,
IsPrimaryKey: field.IsPrimaryKey,
Description: field.Description,
DataType: field.DataType,
TypeParams: field.TypeParams,
IndexParams: field.IndexParams,
AutoID: field.AutoID,
IsDynamic: field.IsDynamic,
IsPartitionKey: field.IsPartitionKey,
DefaultValue: field.DefaultValue,
ElementType: field.ElementType,
}
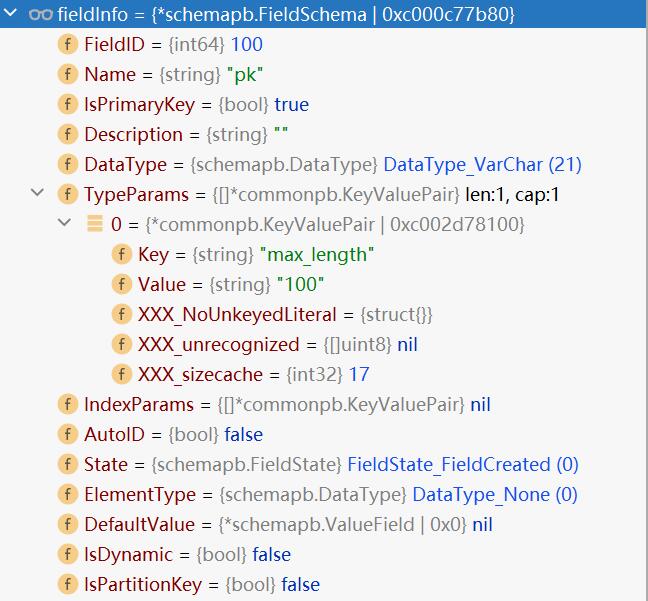
fieldInfo记录了字段的filedID、name、description、datatype等信息。
for _, field := range coll.Fields {
k := BuildFieldKey(coll.CollectionID, field.FieldID)
fieldInfo := model.MarshalFieldModel(field)
v, err := proto.Marshal(fieldInfo)
if err != nil {
return err
}
kvs[k] = string(v)
}
跟踪BuildFieldKey()函数,不难得出key的规则。整理如下:
key规则:
- 前缀/root-coord/fields/{collectionID}/{fieldID}
- 前缀/snapshots/root-coord/fields/{collectionID}/{fieldID}_ts{时间戳}
从路径可以反映field属于哪个collection。一个field就是一个字段。

将kvs批量写入etcd。kvs既有partition,又有field。
完整代码:
func (kc *Catalog) CreateCollection(ctx context.Context, coll *model.Collection, ts typeutil.Timestamp) error {
if coll.State != pb.CollectionState_CollectionCreating {
return fmt.Errorf("cannot create collection with state: %s, collection: %s", coll.State.String(), coll.Name)
}
// 构建collection的key规则
k1 := BuildCollectionKey(coll.DBID, coll.CollectionID)
// 填充collection
collInfo := model.MarshalCollectionModel(coll)
// 序列化
v1, err := proto.Marshal(collInfo)
if err != nil {
return fmt.Errorf("failed to marshal collection info: %s", err.Error())
}
// 写入etcd,最终会写入2个key,一个原始的,一个加snapshots
if err := kc.Snapshot.Save(k1, string(v1), ts); err != nil {
return err
}
kvs := map[string]string{
}
// 构建partition
for _, partition := range coll.Partitions {
// 构建partition的key规则
k := BuildPartitionKey(coll.CollectionID, partition.PartitionID)
// 填充partition
partitionInfo := model.MarshalPartitionModel(partition)
// 序列化
v, err := proto.Marshal(partitionInfo)
if err != nil {
return err
}
kvs[k] = string(v)
}
// 构建field
for _, field := range coll.Fields {
// 构建field的key规则
k := BuildFieldKey(coll.CollectionID, field.FieldID)
// 填充field
fieldInfo := model.MarshalFieldModel(field)
// 序列化
v, err := proto.Marshal(fieldInfo)
if err != nil {
return err
}
kvs[k] = string(v)
}
// 批量写入etcd,传入一个key,最终会写入2个key,一个原始的,一个加snapshots
return etcd.SaveByBatchWithLimit(kvs, maxTxnNum/2, func(partialKvs map[string]string) error {
return kc.Snapshot.MultiSave(partialKvs, ts)
})
}
使用etcd-manager查看etcd。

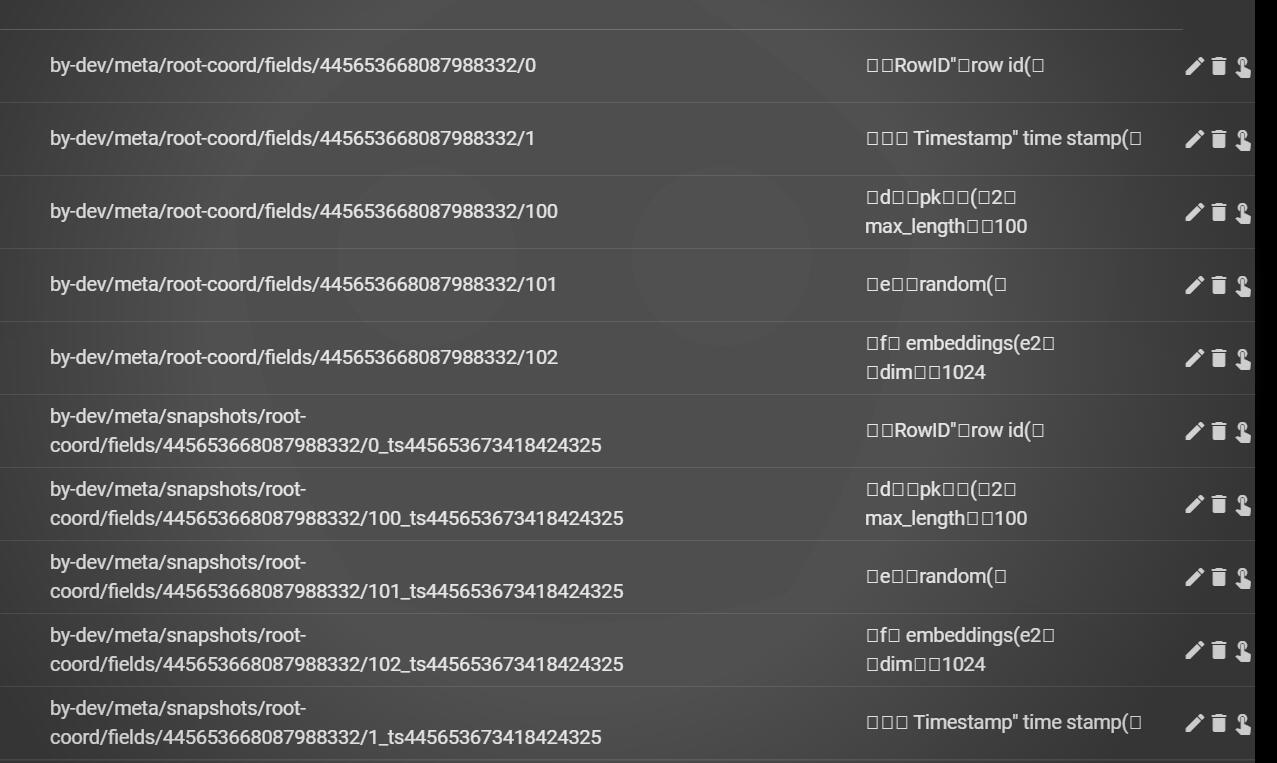
客户端SDK使用了3个field,分别是pk、random、embeddings。
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
每一个field都分配有一个fieldID,例如本例中pk分配100、random分配101、embedding分配102。
但是注意还会产生2个fieldID,一个为0、一个为1。
总结:
1.CreateCollection由proxy传递给协调器rootCoord操作etcd。
2.CreateCollection最终会在etcd上写入3种类型的key
collection
前缀/root-coord/database/collection-info/{dbID}/{collectionID}
partition
前缀/root-coord/partitions/{collectionID}/{partitionID}
field
前缀/root-coord/fields/{collectionID}/{fieldID}
