





LLM 大模型学习必知必会系列(二):提示词工程-Prompt Engineering 以及实战闯关
LLM 大模型学习必知必会系列(二):提示词工程-Prompt Engineering 以及实战闯关
幻方开源第二代MoE模型 DeepSeek-V2,魔搭社区推理、微调最佳实践教程
5月6日,幻方继1月份推出首个国产MoE模型,历时4个月,带来第二代MoE模型DeepSeek-V2,并开源了技术报告和模型权重,魔搭社区可下载体验。
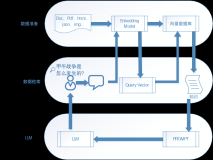
RAG:AI大模型联合向量数据库和 Llama-index,助力检索增强生成技术
RAG:AI大模型联合向量数据库和 Llama-index,助力检索增强生成技术
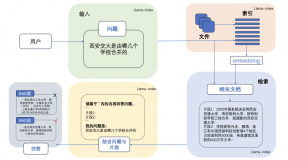
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
LISA微调技术解析:比LoRA更低的显存更快的速度
LISA是Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning的简写,由UIUC联合LMFlow团队于近期提出的一项LLM微调技术,可实现把全参训练的显存使用降低到之前的三分之一左右,而使用的技术方法却是非常简单。

基于LangChain-Chatchat实现的本地知识库的问答应用-快速上手(检索增强生成(RAG)大模型)
基于LangChain-Chatchat实现的本地知识库的问答应用-快速上手(检索增强生成(RAG)大模型)
社区供稿 |【中文Llama-3】Chinese-LLaMA-Alpaca-3开源大模型项目正式发布
Chinese-LLaMA-Alpaca-3开源大模型项目正式发布,开源Llama-3-Chinese-8B(基座模型)和Llama-3-Chinese-8B-Instruct(指令/chat模型)
学习资料大全? | 一起来魔搭社区学AI吧!
魔搭社区特别推出研习社栏目,包含AI前沿技术解读、模型应用最佳实践、动手做AI应用(AIGC/Agent/RAG)等主题,持续更新,代码实战点击即运行
社区供稿 | 元象首个多模态大模型XVERSE-V开源,刷新权威大模型榜单,支持任意宽高比输入
元象公司发布了开源多模态大模型XVERSE-V,该模型在图像输入的宽高比方面具有灵活性,并在多项评测中展现出优越性能,超越了包括谷歌在内的多个知名模型。XVERSE-V采用创新方法结合全局和局部图像信息,适用于高清全景图识别、文字检测等任务,且已在Hugging Face、ModelScope和GitHub上开放下载。此外,模型在视障场景、内容创作、教育解题、百科问答和代码生成等领域有广泛应用,并在VizWiz等测试集中表现出色。元象致力于推动AI技术的普惠,支持中小企业、研究者和开发者进行研发和应用创新。
sysbench 对MySQL压测100分钟的命令
使用 `sysbench` 对 MySQL 数据库进行性能测试(压测)时,首先确保 `sysbench` 和 MySQL 数据库已经安装,并且你有一个测试数据库可以使用。下面是一个针对 MySQL 数据库进行压测的示例命令,测试时长为 100 分钟(6000 秒)。 在运行此命令之前,请确保以下内容: - 使用适当的数据库连接参数(主机、端口、用户名、密码、数据库名)。 - 根据你的需求调整测试参数(如并发数、线程数、事务数等)。 以下是一个示例命令,使用 `sysbench` 对 MySQL 数据库进行压测 100 分钟: ```shell sysbench --db-driver=m
对云效流水线 Flow 的一些体验
Flow是阿里云的CI/CD工具,以其可视化界面和拖拽式构建流程简化了新手上手难度,同时提供代码检查、构建、测试及部署等功能。尽管对CI/CD概念新手仍有学习曲线,Flow的入门教程有助于理解和使用。Flow在性能和开放性上表现出色,支持多种语言和框架,能与阿里云服务集成。成本相对较低,适合与阿里云生态匹配的团队。与其他CI/CD工具比较,Flow在功能和性能上有竞争力,但最佳选择取决于团队具体需求。总体而言,Flow是值得考虑的CI/CD解决方案。
社区供稿 | 中文llama3模型哪家强?llama3汉化版微调模型大比拼
随着llama3的发布,业界越来越多的针对其中文能力的微调版本也不断涌现出来,我们在ModelScope魔搭社区上,搜集到几款比较受欢迎的llama3中文版本模型,来从多个维度评测一下,其对齐后的中文能力到底如何? 微调后是否产生了灾难性遗忘问题。
千亿大模型来了!通义千问110B模型开源,魔搭社区推理、微调最佳实践
近期开源社区陆续出现了千亿参数规模以上的大模型,这些模型都在各项评测中取得杰出的成绩。今天,通义千问团队开源1100亿参数的Qwen1.5系列首个千亿参数模型Qwen1.5-110B,该模型在基础能力评估中与Meta-Llama3-70B相媲美,在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。
Phi-3:小模型,大未来!(附魔搭社区推理、微调实战教程)
近期, Microsoft 推出 Phi-3,这是 Microsoft 开发的一系列开放式 AI 模型。Phi-3 模型是一个功能强大、成本效益高的小语言模型?(SLM),在各种语言、推理、编码和数学基准测试中,在同级别参数模型中性能表现优秀。为开发者构建生成式人工智能应用程序时提供了更多实用的选择。
Llama3 中文通用Agent微调模型来啦!(附手把手微调实战教程)
Llama3模型在4月18日公布后,国内开发者对Llama3模型进行了很多训练和适配,除了中文纯文本模型外,多模态版本也陆续在发布中。
社区供稿 | XTuner发布LLaVA-Llama-3-8B,支持单卡推理,评测和微调
日前,XTuner 团队基于 meta 最新发布的 Llama-3-8B-Instruct 模型训练并发布了最新版多模态大模型 LLaVA-Llama-3-8B, 在多个评测数据集上取得显著提升。
在魔搭使用SD-WebUI,玩转AIGC!
stable-diffusion-webui是一个便捷的工具,大大降低了复杂AI技术的使用门槛,让更多人能享受到AI驱动的图像生成技术带来的便利与创新可能。
阿里云助力开发者创新:探索云原生技术的新境界
阿里云开发者社区推动云原生技术发展,提供丰富产品(如容器服务、Serverless、微服务架构、服务网格)与学习平台,助力企业数字化转型。开发者在此探索实践,共享资源,参与技术活动,共同创新,共创云原生技术新篇章。一起加入,开启精彩旅程!
社区供稿 | Llama3-8B中文版!OpenBuddy发布新一代开源中文跨语言模型
此次发布的是在3天时间内,我们对Llama3-8B模型进行首次中文跨语言训练尝试的结果:OpenBuddy-Llama3-8B-v21.1-8k。

Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama 3 研究论文。
社区供稿 | 开放开源!蚂蚁集团浙江大学联合发布开源大模型知识抽取框架OneKE
OneKE 是由蚂蚁集团和浙江大学联合研发的大模型知识抽取框架,具备中英文双语、多领域多任务的泛化知识抽取能力,并提供了完善的工具链支持。OneKE 以开源形式贡献给 OpenKG 开放知识图谱社区。
手把手教你捏一个自己的Agent
Modelscope AgentFabric是一个基于ModelScope-Agent的交互式智能体应用,用于方便地创建针对各种现实应用量身定制智能体,目前已经在生产级别落地。
社区供稿 | vLLM部署Yuan2.0:高吞吐、更便捷
vLLM是UC Berkeley开源的大语言模型高速推理框架,其内存管理核心——PagedAttention、内置的加速算法如Continues Batching等,一方面可以提升Yuan2.0模型推理部署时的内存使用效率,另一方面可以大幅提升在实时应用场景下Yuan2.0的吞吐量。
生活小事件(SpringMVC主要的组件及作用和执行流程)
Spring MVC 的主要组件包括 DispatcherServlet(核心,请求调度)、HandlerMapping(URL 映射到处理器)、HandlerAdapter(统一执行处理器)、Handler(处理业务逻辑,通常为 @Controller 类)、ViewResolver(视图解析)和 View(渲染输出)。通过这些组件的协作,Spring MVC 实现了从接收请求到返回响应的流程,类似于警察处理交通违规的协调过程。
快来与 CodeQwen1.5 结对编程!
今天,来自 Qwen1.5 开源家族的新成员,代码专家模型 CodeQwen1.5开源!CodeQwen1.5 基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了优秀的代码生成、长序列建模、代码修改、SQL 能力等,该模型可以大大提高开发人员的工作效率,并在不同的技术环境中简化软件开发工作流程。
社区供稿 | 140B参数、可商用!OpenBuddy 发布首个开源千亿中文 MoE 模型的早期预览版
我们很自豪地于今天发布OpenBuddy最新一代千亿MoE大模型的早期预览版本:OpenBuddy-Mixtral-22Bx8-preview0-65k。此次发布的早期预览版对应约50%的训练进度。
新一代端侧模型,面壁 MiniCPM 2.0开源,魔搭社区最佳实践
MiniCPM-V 2.0 不仅带来优秀端侧多模态通用能力,更带来惊艳的 OCR 表现。通过自研的高清图像解码技术,可以突破传统困境,让更为精准地识别充满纷繁细节的街景、长图在端侧成为可能。
性能提升30%!中国电信进一步开源12B星辰大模型TeleChat-12B!魔搭社区最佳实践来啦!
中国电信人工智能研究院开源12B参数规模星辰语义大模型TeleChat-12B,相较1月开源7B版本,内容、性能和应用等方面整体效果提升30%,其中,多轮推理、安全问题等领域提升超40%。在C-eval、MMLU、AGIEVAL等国际权威榜单上,排名处于国内同级别参数开源模型的前列,进一步促进大模型开源生态繁荣,助力AI产业加速高质量发展。另据悉,中国电信人工智能研究院将于年内开源千亿级参数大模型。
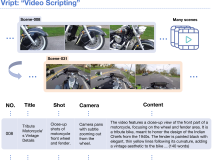
Vript:最为详细的视频文本数据集,每个视频片段平均超过140词标注 | 多模态大模型,文生视频
[Vript](https://github.com/mutonix/Vript) 是一个大规模的细粒度视频文本数据集,包含12K个高分辨率视频和400k+片段,以视频脚本形式进行密集注释,每个场景平均有145个单词的标题。除了视觉信息,还转录了画外音,提供额外背景。新发布的Vript-Bench基准包括三个挑战性任务:Vript-CAP(详细视频描述)、Vript-RR(视频推理)和Vript-ERO(事件时序推理),旨在推动视频理解的发展。
8卡环境微调Grok-1实战
SWIFT(Scalable lightWeight Infrastructure for Fine-Tuning)是魔搭ModelScope开源社区推出的一套完整的轻量级训练推理工具,基于PyTorch的轻量级、开箱即用的模型微调、推理框架,让AI爱好者用自己的消费级显卡就能玩转大模型和AIGC。
ModelScope模型使用与EAS部署调用
本文以魔搭数据的模型为例,演示在DSW实例中如何快速调用模型,然后通过Python SDK将模型部署到阿里云PAI EAS服务,并演示使用EAS SDK实现对服务的快速调用,重点针对官方关于EAS模型上线后示例代码无法正常调通部分进行了补充。
【RAG实践】Rerank,让RAG更近一步
本文主要关注在Rerank,本文中,Rerank可以在不牺牲准确性的情况下加速LLM的查询(实际上可能提高准确率),Rerank通过从上下文中删除不相关的节点,重新排序相关节点来实现这一点。
MySQL之show profile相关总结
综上所述,`SHOW PROFILE`是MySQL提供的一个用于查询性能分析的工具,可以帮助开发人员定位查询性能问题,并进行优化。通过分析每个阶段的执行时间和资源消耗情况,可以更好地理解查询的执行过程,从而提升数据库性能。
元象开源首个MoE大模型:4.2B激活参数,效果堪比13B模型,魔搭社区最佳实践来了
近日,元象发布其首个Moe大模型 XVERSE-MoE-A4.2B, 采用混合专家模型架构 (Mixture of Experts),激活参数4.2B,效果即可媲美13B模型。该模型全开源,无条件免费商用,支持中小企业、研究者和开发者可在元象高性能“全家桶”中按需选用,推动低成本部署。
TripoSR开源!从单个图像快速生成 3D 对象!(附魔搭社区推理实战教程)
近期,VAST团队和Stability AI团队合作发布了TripoSR,可在一秒内从单个图像生成高质量3D对象。

适合假期自学一战成名的必看秘籍-五板斧打造AgentScope应用
本文写给有一定编程基础的学习者,得以入门 源码级 开发Agentscope应用,并上线创空间,参加AgentScope的应用开发挑战赛。
Multi-Agent实践第6期:面向智能体编程:狼人杀在AgentScope
本期文章,我们会介绍一下AgentScope的一个设计哲学(Agent-oriented programming)



