zhangqianglxiaoe-46270_个人页



文章
39
问答
32
视频
0
个人介绍
暂无个人介绍
擅长的技术
- 人工智能
- 大数据
- 数据湖
- 大模型
- 云原生
获得更多能力

通用技术能力:
暂时未有相关通用技术能力~
云产品技术能力:
-
Clouder
-
云原生Clouder认证:函数计算的功能与使用入门
获得于2024-05-11 18:57:05
-
云原生数据库Clouder认证:PolarDB 快速入门
获得于2024-05-11 18:02:59
-
云原生Clouder认证:函数计算的功能与使用入门
阿里云技能认证
详细说明
暂无更多信息
2024年05月
-
05.19 13:16:01
 发表了文章
2024-05-19 13:16:01
发表了文章
2024-05-19 13:16:01
【LangChain系列】第三篇:Agent代理简介及实践
【5月更文挑战第17天】LangChain代理利用大型语言模型(LLM)作为推理引擎,结合各种工具和数据库,处理复杂任务和决策。这些代理能理解和生成人类语言,访问外部信息,并结合LLM进行推理。文章介绍了如何通过LangChain构建代理,包括集成DuckDuckGo搜索和维基百科,以及创建Python REPL工具执行编程任务。此外,还展示了如何构建自定义工具,如获取当前日期的示例,强调了LangChain的灵活性和可扩展性,为LLM的应用开辟了新途径。 -
05.17 17:55:05发表了文章
2024-05-17 17:55:05
【AI】从零构建深度学习框架实践
【5月更文挑战第16天】 本文介绍了从零构建一个轻量级的深度学习框架tinynn,旨在帮助读者理解深度学习的基本组件和框架设计。构建过程包括设计框架架构、实现基本功能、模型定义、反向传播算法、训练和推理过程以及性能优化。文章详细阐述了网络层、张量、损失函数、优化器等组件的抽象和实现,并给出了一个基于MNIST数据集的分类示例,与TensorFlow进行了简单对比。tinynn的源代码可在GitHub上找到,目前支持多种层、损失函数和优化器,适用于学习和实验新算法。 -
05.17 16:08:04
 回答了问题
2024-05-17 16:08:04
回答了问题
2024-05-17 16:08:04
如何评价 OpenAI 最新发布支持实时语音对话的模型GPT-4o?
赞42 踩0 评论0 -
05.17 15:49:10回答了问题
2024-05-17 15:49:10
为什么程序员害怕改需求?
赞33 踩0 评论0 -
05.17 15:36:36回答了问题
2024-05-17 15:36:36
“AI黏土人”一夜爆火,图像生成类应用应该如何长期留住用户?
赞23 踩0 评论0 -
05.17 14:55:22回答了问题
2024-05-17 14:55:22
AI面试成为线下面试的“隐形门槛”,对此你怎么看?
赞4 踩0 评论0 -
05.17 14:46:01回答了问题
2024-05-17 14:46:01
如何从零构建一个现代深度学习框架?
赞8 踩0 评论0 -
05.16 19:19:17发表了文章
2024-05-16 19:19:17
【LangChain系列】第二篇:文档拆分简介及实践
【5月更文挑战第15天】 本文介绍了LangChain中文档拆分的重要性及工作原理。文档拆分有助于保持语义内容的完整性,对于依赖上下文的任务尤其关键。LangChain提供了多种拆分器,如CharacterTextSplitter、RecursiveCharacterTextSplitter和TokenTextSplitter,分别适用于不同场景。MarkdownHeaderTextSplitter则能根据Markdown标题结构进行拆分,保留文档结构。通过实例展示了如何使用这些拆分器,强调了选择合适拆分器对提升下游任务性能和准确性的影响。 -
05.15 18:29:41发表了文章
2024-05-15 18:29:41
【LangChain系列】第一篇:文档加载简介及实践
【5月更文挑战第14天】 LangChain提供80多种文档加载器,简化了从PDF、网站、YouTube视频和Notion等多来源加载与标准化数据的过程。这些加载器将不同格式的数据转化为标准文档对象,便于机器学习工作流程中的数据处理。文中介绍了非结构化、专有和结构化数据的加载示例,包括PDF、YouTube视频、网站和Notion数据库的加载方法。通过LangChain,用户能轻松集成和交互各类数据源,加速智能应用的开发。 -
05.14 18:53:58发表了文章
2024-05-14 18:53:58
【LLM】智能学生顾问构建技术学习(Lyrz SDK + OpenAI API )
【5月更文挑战第13天】智能学生顾问构建技术学习(Lyrz SDK + OpenAI API ) -
05.13 10:56:26发表了文章
2024-05-13 10:56:26
【AIGC】LangChain Agent(代理)技术分析与实践
【5月更文挑战第12天】 LangChain代理是利用大语言模型和推理引擎执行一系列操作以完成任务的工具,适用于从简单响应到复杂交互的各种场景。它能整合多种服务,如Google搜索、Wikipedia和LLM。代理通过选择合适的工具按顺序执行任务,不同于链的固定路径。代理的优势在于可以根据上下文动态选择工具和执行策略。适用场景包括网络搜索、嵌入式搜索和API集成。代理由工具组成,每个工具负责单一任务,如Web搜索或数据库查询。工具包则包含预定义的工具集合。创建代理需要定义工具、初始化执行器和设置提示词。LangChain提供了一个从简单到复杂的AI解决方案框架。 -
05.12 20:30:51发表了文章
2024-05-12 20:30:51
【AIGC】英语小助手Lingo:基于大语言模型的学习英语小帮手
【5月更文挑战第11天】英语小助手Lingo:基于大语言模型的学习英语小帮手 -
05.11 10:21:14发表了文章
2024-05-11 10:21:14
【AIGC】深入浅出理解检索增强技术(RAG)
【5月更文挑战第10天】本文介绍了检索增强生成(RAG)技术,这是一种将AI模型与内部数据结合,提升处理和理解能力的方法。通过实时从大型文档库检索信息,扩展预训练语言模型的知识。文章通过示例说明了当模型需要回答未公开来源的内容时,RAG如何通过添加上下文信息来增强模型的回答能力。讨论了实际应用中令牌限制和文本分块的问题,以及使用文本嵌入技术解决相关性匹配的挑战。最后,概述了实现RAG的步骤,并预告后续将分享构建检索增强服务的详情。 -
05.10 10:39:15发表了文章
2024-05-10 10:39:15
【AIGC】通过人工智能总结PDF文档摘要服务的构建
【5月更文挑战第9天】 使用Python和预训练的AI模型,结合Gradio前端框架,创建了一个文本及PDF摘要聊天机器人。通过加载"FalconsAI/text_summarization"模型,实现文本和PDF的预处理,包括PDF合并与文本提取。聊天机器人接收用户输入,判断是文本还是PDF,然后进行相应的摘要生成。用户可以通过运行`app.py`启动机器人,访问`localhost:7860`与之交互,快速获取内容摘要。这个工具旨在帮助忙碌的人们高效获取信息。 -
05.09 18:47:22回答了问题
2024-05-09 18:47:22
粘贴卡住
赞2 踩0 评论0 -
05.09 18:46:07回答了问题
2024-05-09 18:46:07
PolarDB 刷脚本特别慢可能是什么问题,一个4M大小的脚本要刷半个多小时
赞0 踩0 评论0 -
05.09 18:44:47回答了问题
2024-05-09 18:44:47
ModelScope能编写股票量化交易代码吗?
赞1 踩0 评论0 -
05.09 18:42:54回答了问题
2024-05-09 18:42:54
请问有人用ChatUI IMSDK部署过智能对话机器人吗?
赞3 踩0 评论0 -
05.09 18:40:17回答了问题
2024-05-09 18:40:17
通义灵码在vscode无法登录
赞2 踩0 评论1 -
05.09 18:37:52回答了问题
2024-05-09 18:37:52
-
05.09 18:34:46回答了问题
2024-05-09 18:34:46
算法工程师是学什么专业出身的?
赞13 踩0 评论0 -
05.09 18:23:23回答了问题
2024-05-09 18:23:23
你遇到过哪些触发NPE的代码场景?
赞14 踩0 评论0 -
05.09 18:01:58回答了问题
2024-05-09 18:01:58
你见过哪些独特的代码注释?
赞15 踩0 评论0 -
05.09 14:46:07发表了文章
2024-05-09 14:46:07
【AIGC】基于大语言模型构建多语种聊天机器人(基于Bloom大语言模型)
【5月更文挑战第8天】基于大语言模型Bloom构建多语种聊天机器人 -
05.08 18:50:51发表了文章
2024-05-08 18:50:51
【AIGC】基于检索增强技术(RAG)构建大语言模型(LLM)应用程序
【5月更文挑战第7天】基于检索增强技术(RAG)构建大语言模型(LLM)应用程序实践 -
05.06 17:16:41发表了文章
2024-05-06 17:16:41
【AI】生成式AI,对话式AI,LLM,SLM 差异分析
【5月更文挑战第6天】生成式AI,对话式AI,LLM,SLM 学习 -
05.05 21:40:06发表了文章
2024-05-05 21:40:06
【AIGC】LangChain Agent 最新教程详解及示例学习
【5月更文挑战第5天】LangChain Agent全网最全最新教程学习及示例学习 -
05.04 22:04:23发表了文章
2024-05-04 22:04:23
【LLM】基于pvVevtor和LangChain构建RAG(检索增强)服务
【5月更文挑战第4天】基于pgVector和LangChain构建RAG检索增强服务 -
05.03 10:14:59发表了文章
2024-05-03 10:14:59
【AIGC】人脸验证服务简介及实践案例分析
【5月更文挑战第3天】手把手教你如何基于pgVector和LangChain构建检索增强服务 -
05.02 20:44:18发表了文章
2024-05-02 20:44:18
【LLM】深入浅出学习模型中Embedding(嵌入)
【5月更文挑战第2天】人工智能嵌入深入浅出介绍 -
05.01 19:20:50发表了文章
2024-05-01 19:20:50
【RAG】人工智能:检索增强(RAG)六步学习法
【5月更文挑战第1天】人工智能检索增强学习六步基本介绍 -
04.30 16:45:30发表了文章
2024-04-30 16:45:30
【AGI】智能体简介及场景分析
【4月更文挑战第14天】AI时代,智能体的意义,使用场景及对未来的意义 -
04.30 16:38:39发表了文章
2024-04-30 16:38:39
【AIGC】文档智能助手技术解决方案报告
【4月更文挑战第14天】智能文档处理助手技术解决方案报告整理输出 -
04.29 15:57:19发表了文章
2024-04-29 15:57:19
【LLM】基于Stable-Diffusion模型构建可以生成图像的聊天机器人
【4月更文挑战第13天】基于Stable-Diffusion模型构建可以生成图像的聊天机器人 -
04.28 15:25:00发表了文章
2024-04-28 15:25:00
【LLM】能够运行在移动端的轻量级大语言模型Gemma实践
【4月更文挑战第12天】可以运行在移动端的开源大语言模型Gemma模型介绍 -
04.28 10:06:14发表了文章
2024-04-28 10:06:14
【LLM】基于LLama构建智能助理实现与PDF文件智能对话
【4月更文挑战第12天】构建智能助理服务,实现与PDF的自由对话 -
04.27 19:33:08发表了文章
2024-04-27 19:33:08
【LLMOps】Paka:大模型管理应用平台部署实践
【4月更文挑战第11天】Paka大模型管理及应用平台介绍 -
04.26 17:23:29发表了文章
2024-04-26 17:23:29
【LLMOps】AIGC使用场景解决方案
【4月更文挑战第10天】AIGC五大使用场景解决方案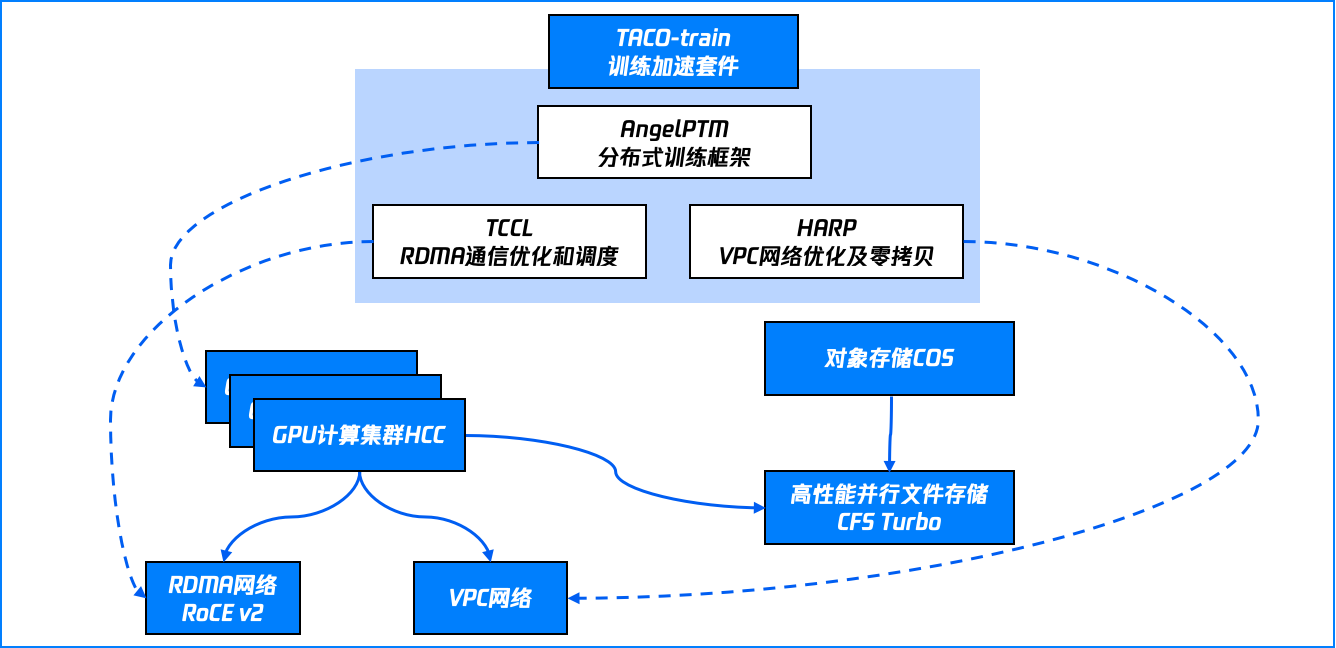
-
04.26 17:06:35发表了文章
2024-04-26 17:06:35
【AIGC】人工智能在教育领域的场景应用
【4月更文挑战第10天】人工智能对教育领域的发展有哪些应用及影像 -
04.25 15:04:11发表了文章
2024-04-25 15:04:11
【AI智能体】SuperAGI-开源AI Agent 管理平台
【4月更文挑战第9天】智能体管理平台SuperAGI简介及实践 -
04.25 11:11:52发表了文章
2024-04-25 11:11:52
【SpringBoot系列】微服务远程调用Open Feign深度学习
【4月更文挑战第9天】微服务远程调度open Feign 框架学习 -
04.24 15:33:56发表了文章
2024-04-24 15:33:56
【SpringBoot系列】微服务数据持久化方案
【4月更文挑战第8天】微服务数据持久化方案Spring Boot JPA + Hiberate -
04.23 16:37:59发表了文章
2024-04-23 16:37:59
【SpringBoot系列】微服务集成Flyway
【4月更文挑战第7天】SpringBoot微服务集成Flyway
-
04.22 16:46:25发表了文章
2024-04-22 16:46:25
【SpringBoot系列】微服务监测(常用指标及自定义指标)
【4月更文挑战第6天】SpringBoot微服务的监测指标及自定义指标讲解 -
04.19 15:08:47发表了文章
2024-04-19 15:08:47
【Spring Boot系列】通过OpenAPI规范构建微服务服务接口
【4月更文挑战第5天】通过OpenAPI接口构建Spring Boot服务RestAPI接口
2024年04月
-
04.24 11:13:29回答了问题
2024-04-24 11:13:29
如何让系统具备良好的扩展性?
赞50 踩0 评论0 -
04.24 10:44:36回答了问题
2024-04-24 10:44:36
在JS编程中有哪些常见的编程“套路”或习惯?
赞4 踩0 评论0 -
04.24 10:12:24回答了问题
2024-04-24 10:12:24
在做程序员的道路上,你掌握了什么关键的概念或技术让你感到自身技能有了显著飞跃?
赞3 踩0 评论0 -
04.23 17:59:40回答了问题
2024-04-23 17:59:40
作为一个经典架构模式,事件驱动在云时代为什么会再次流行呢?
赞4 踩0 评论0
-
发表了文章
2024-05-19
【LangChain系列】第三篇:Agent代理简介及实践
-
发表了文章
2024-05-17
【AI】从零构建深度学习框架实践
-
发表了文章
2024-05-16
【LangChain系列】第二篇:文档拆分简介及实践
-
发表了文章
2024-05-15
【LangChain系列】第一篇:文档加载简介及实践
-
发表了文章
2024-05-15
【AIGC】通过人工智能总结PDF文档摘要服务的构建
-
发表了文章
2024-05-15
【AIGC】LangChain Agent(代理)技术分析与实践
-
发表了文章
2024-05-15
【AIGC】英语小助手Lingo:基于大语言模型的学习英语小帮手
-
发表了文章
2024-05-15
【LLM】智能学生顾问构建技术学习(Lyrz SDK + OpenAI API )
-
发表了文章
2024-05-15
【AIGC】人脸验证服务简介及实践案例分析
-
发表了文章
2024-05-15
【AIGC】基于检索增强技术(RAG)构建大语言模型(LLM)应用程序
-
发表了文章
2024-05-15
【AIGC】LangChain Agent 最新教程详解及示例学习
-
发表了文章
2024-05-15
【LLM】基于pvVevtor和LangChain构建RAG(检索增强)服务
-
发表了文章
2024-05-15
【RAG】人工智能:检索增强(RAG)六步学习法
-
发表了文章
2024-05-15
【AIGC】基于大语言模型构建多语种聊天机器人(基于Bloom大语言模型)
-
发表了文章
2024-05-15
【LLMOps】Paka:大模型管理应用平台部署实践
-
发表了文章
2024-05-15
【AGI】智能体简介及场景分析
-
发表了文章
2024-05-15
【LLM】能够运行在移动端的轻量级大语言模型Gemma实践
-
发表了文章
2024-05-15
【AI】生成式AI,对话式AI,LLM,SLM 差异分析
-
发表了文章
2024-05-15
【AI智能体】SuperAGI-开源AI Agent 管理平台
-
发表了文章
2024-05-15
【LLM】基于Stable-Diffusion模型构建可以生成图像的聊天机器人
滑动查看更多
-
回答了问题
2024-05-17
如何评价 OpenAI 最新发布支持实时语音对话的模型GPT-4o?
GPT-4o相比前代的技术提升:
GPT-4o是GPT-4的升级版。“o”是Omni的缩写,意为“全能”,可接受文本、音频和图像的任意组合作为输入,生成文本、音频和图像。GPT-4o支持API调用,比上一代速度快了2倍,价格降低了50%,还能实现无延迟实时对话。GPT-4o拥有ChatGPT Plus会员版所有的能力,包括视觉、联网、记忆、执行代码、GPT Store……更为关键的是,它将对所有用户免费开放!而实时语音对话的过程,更是丝滑流畅毫无延迟——它可以在短至232毫秒、平均320毫秒的时间内响应音频输入,与人类在对话中的反应速度一致。在理解能力上,GPT-4o能够快速理解代码,并给出了准确完整的描述。
国内大模型行业的机会:
国内大模型未来的机会在于应用,模型的能力当然会不断地迭代,但最终能够把大模型用好的还是应用。从技术方面来看,OpenAI成功为国内大模型行业提供了一条可能的发展路径:三模态端到端实时输入输出是可行的,并且能极大地提高模型的情感理解能力。在AI应用领域,由于GPT-4o的实时响应能力显著提升,意味着AI的交互体验将会更加流畅,这在一定程度上扩展了AI的应用范围。GPT-4o能更好地支持多模态,并且有着强大的用户交互能力,这也使得AI的应用领域更加丰富,并且能大幅提高如手机语音助手等应用的业务能力。
赞42 踩0 评论0 -
回答了问题
2024-05-17
为什么程序员害怕改需求?
其实程序员本质上怕的不是改需求,而是最终的成果是否被能接受或者肯定,如果因为中间的需求变动而导致最终不被接受或者肯定,这个结果是谁也不愿意接受的,毕竟累死累活了,还不被老板接受。
程序员怕的是提出需求的人,对于更改需求所需要的成本没有足够的认知,在他们眼中类似的两个功能,可能从底层设计就完全不同。他们眼中,烟囱倒过来就是水井,但是他们根本不考虑,之类地下可能就打不出水。他们在忽略金钱成本的同时,也会忽略时间成本。在他们眼中,找个吊车把烟囱调个方向就行,3天妥妥的。
其实任何行业都怕改动需求,什么行业不怕改需求?要你修个塔,你快封顶了说不要了改挖口井;预约去银行取一个亿,你们现金准备好了改需求说存一万块;拍个古装电视剧,杀青了说改需求换成时装的;
程序员不怕改需求,怕的是改需求还不给钱,钱到位了,你要盖楼就盖楼,你要挖井就挖井,程序员不怕改需求?怕不是你自己揣着明白装糊涂,白嫖完了不想结账而已。
赞33 踩0 评论0 -
回答了问题
2024-05-17
“AI黏土人”一夜爆火,图像生成类应用应该如何长期留住用户?
爆火生成式AI产品的走红有共性,他们都踩准了技术创新、市场需求和资本聚焦的结合点,从而获得了出圈的效果,这就是所谓的从0到1的创新。从1到n的发展,则需要持续不断的突破,一时的成功不算成功,持续的成功才是真的厉害,这就离不开持续的创新生成式AI技术、准确的市场定位、社交属性产品设计、热点营销策略、低门槛入门的定价策略等,这一系列的小成功应用才有可能造就持续的最后的成功,这可能是打造爆款生成式AI产品成功的共性因素吧。
赞22 踩0 评论0 -
回答了问题
2024-05-17
AI面试成为线下面试的“隐形门槛”,对此你怎么看?
站在企业的角度:AI面试可以更全面地评估候选人的技术能力和解决问题的能力,有助于筛选出更适合岗位的人才。AI面试还可以提高面试效率,节省人力资源和时间成本。但是,不好的方面是:AI面试可能存在算法歧视和不公平性,有些算法可能会偏向某些特定类型的候选人,导致招聘过程不公平。此外,AI面试可能无法全面评估候选人的软技能和沟通能力,这些能力在实际工作中同样重要。
同样,从员工的角度来看,AI面试可以提供更公平和客观的评价标准,避免主观偏见和人为因素对面试结果的影响。AI面试还可以帮助候选人更好地准备面试,了解面试流程和问题类型,提高面试通过率。同时,不好的一方面确实:AI面试可能无法充分展示候选人的个性和特长,有些候选人可能在面试中表现不佳,但实际工作能力很强。此外,有些候选人可能对AI面试的技术要求不熟悉,导致面试不顺利。
不管从企业的角度,还是员工的角度,AI面试都是一把双刃剑,我们需要根据自己企业的实际情况进行判断,水能载舟,亦能覆舟,古往今来,这个规律一直有有效的。
赞4 踩0 评论0 -
回答了问题
2024-05-17
如何从零构建一个现代深度学习框架?
[toc]
【AI】从零构建深度学习框架
当前深度学习框架越来越成熟,对于使用者而言封装程度越来越高,好处就是现在可以非常快速地将这些框架作为工具使用,用非常少的代码就可以构建模型进行实验,坏处就是可能背后地实现都被隐藏起来了。在这篇文章里笔者将设计和实现一个、轻量级的(约 200 行)、易于扩展的深度学习框架 tinynn(基于 Python 和 Numpy 实现),希望对大家了解深度学习的基本组件、框架的设计和实现有一定的帮助。
构建深度学习框架需要考虑以下几个关键步骤:
- 设计框架架构:首先需要确定框架的整体架构,包括模型定义、层次结构、优化算法等。可以参考现有的深度学习框架,如TensorFlow、PyTorch等,来设计自己的框架。
- 实现基本功能:实现基本的张量操作、各种激活函数、损失函数、优化器等功能,这些是深度学习框架的基础。
- 实现模型定义:实现各种常用的深度学习模型,如卷积神经网络、循环神经网络、深度神经网络等,可以参考已有的模型定义来实现。
- 实现反向传播算法:深度学习的核心是反向传播算法,需要实现梯度计算和参数更新的过程。
- 实现训练和推理过程:实现训练过程和推理过程,包括数据加载、模型训练、模型评估等步骤。
- 优化性能:优化框架的性能,可以考虑使用GPU加速、多线程并行等技术来提高训练速度。
- 测试和调试:对框架进行测试和调试,确保框架的正确性和稳定性。
本文首先会从深度学习的流程开始分析,对神经网络中的关键组件抽象,确定基本框架;然后再对框架里各个组件进行代码实现;最后基于这个框架实现了一个 MNIST 分类的示例,并与 Tensorflow 做了简单的对比验证。
一、组件抽象
首先考虑神经网络运算的流程,神经网络运算主要包含训练 training 和预测 predict (或 inference) 两个阶段,训练的基本流程是:输入数据 -> 网络层前向传播 -> 计算损失 -> 网络层反向传播梯度 -> 更新参数,预测的基本流程是 输入数据 -> 网络层前向传播 -> 输出结果。从运算的角度看,主要可以分为三种类型的计算:
- 数据在网络层之间的流动:前向传播和反向传播可以看做是张量 Tensor(多维数组)在网络层之间的流动(前向传播流动的是输入输出,反向传播流动的是梯度),每个网络层会进行一定的运算,然后将结果输入给下一层
- 计算损失:衔接前向和反向传播的中间过程,定义了模型的输出与真实值之间的差异,用来后续提供反向传播所需的信息
- 参数更新:使用计算得到的梯度对网络参数进行更新的一类计算
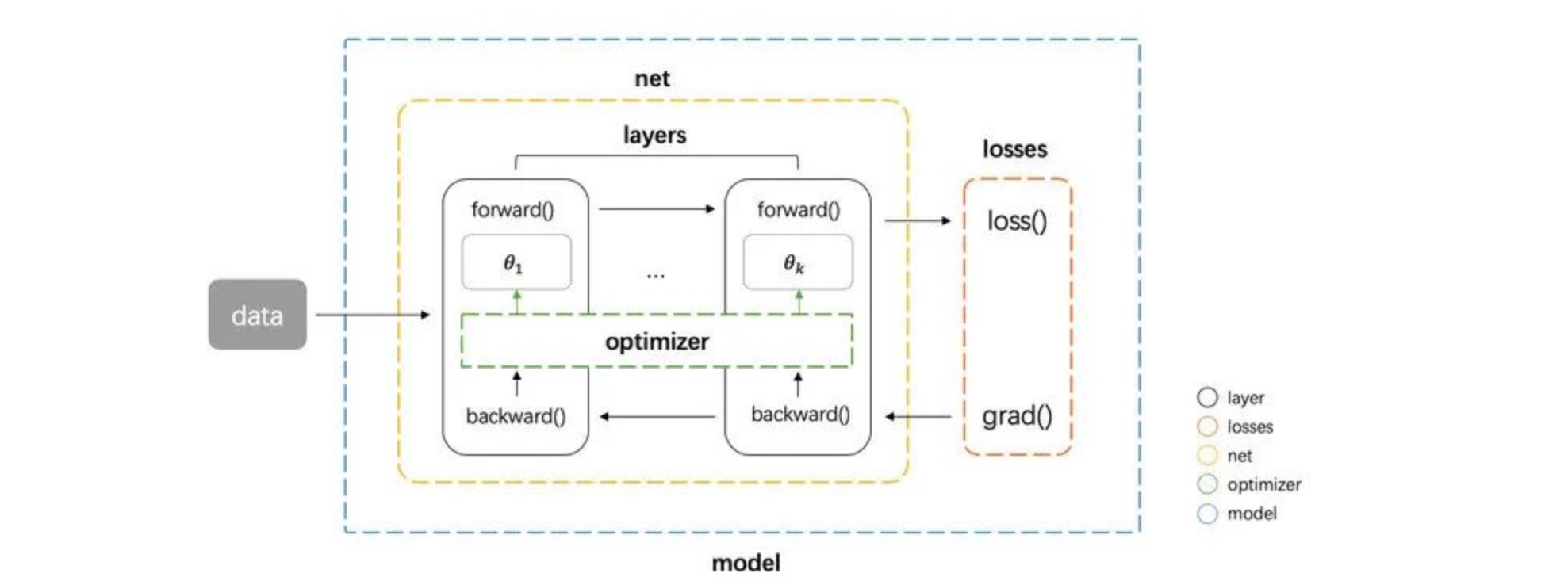
基于这个三种类型,我们可以对网络的基本组件做一个抽象
tensor张量,这个是神经网络中数据的基本单位layer网络层,负责接收上一层的输入,进行该层的运算,将结果输出给下一层,由于 tensor 的流动有前向和反向两个方向,因此对于每种类型网络层我们都需要同时实现 forward 和 backward 两种运算loss损失,在给定模型预测值与真实值之后,该组件输出损失值以及关于最后一层的梯度(用于梯度回传)optimizer优化器,负责使用梯度更新模型的参数
然后我们还需要一些组件把上面这个 4 种基本组件整合到一起,形成一个 pipeline
- net 组件负责管理 tensor 在 layers 之间的前向和反向传播,同时能提供获取参数、设置参数、获取梯度的接口
- model 组件负责整合所有组件,形成整个 pipeline。即 net 组件进行前向传播 -> losses 组件计算损失和梯度 -> net 组件将梯度反向传播 -> optimizer 组件将梯度更新到参数。
基本的框架图如下图
二、组件实现
按照上面的抽象,我们可以写出整个流程代码如下。
# define model net = Net([layer1, layer2, ...]) model = Model(net, loss_fn, optimizer) # training pred = model.forward(train_X) loss, grads = model.backward(pred, train_Y) model.apply_grad(grads) # inference test_pred = model.forward(test_X)首先定义 net,net 的输入是多个网络层,然后将 net、loss、optimizer 一起传给 model。model 实现了 forward、backward 和 apply_grad 三个接口分别对应前向传播、反向传播和参数更新三个功能。接下来我们看这里边各个部分分别如何实现。
1.tensor
tensor 张量是神经网络中基本的数据单位,我们这里直接使用 numpy.ndarray 类作为 tensor 类的实现
numpy.ndarray :https://numpy.org/doc/stable/reference/generated/numpy.ndarray.html
2.layer
上面流程代码中 model 进行 forward 和 backward,其实底层都是网络层在进行实际运算,因此网络层需要有提供 forward 和 backward 接口进行对应的运算。同时还应该将该层的参数和梯度记录下来。先实现一个基类如下
# layer.py class Layer(object): def __init__(self, name): self.name = name self.params, self.grads = None, None def forward(self, inputs): raise NotImplementedError def backward(self, grad): raise NotImplementedError最基础的一种网络层是全连接网络层,实现如下。forward 方法接收上层的输入 inputs,实现 的运算;backward 的方法接收来自上层的梯度,计算关于参数 和输入的梯度,然后返回关于输入的梯度。这三个梯度的推导可以见附录,这里直接给出实现。w_init 和 b_init 分别是参数 和 的初始化器,这个我们在另外的一个实现初始化器中文件 initializer.py 去实现,这部分不是核心部件,所以在这里不展开介绍。
# layer.py class Dense(Layer): def __init__(self, num_in, num_out, w_init=XavierUniformInit(), b_init=ZerosInit()): super().__init__("Linear") self.params = { "w": w_init([num_in, num_out]), "b": b_init([1, num_out])} self.inputs = None def forward(self, inputs): self.inputs = inputs return inputs @ self.params["w"] + self.params["b"] def backward(self, grad): self.grads["w"] = self.inputs.T @ grad self.grads["b"] = np.sum(grad, axis=0) return grad @ self.params["w"].T同时神经网络中的另一个重要的部分是激活函数。激活函数可以看做是一种网络层,同样需要实现 forward 和 backward 方法。我们通过继承 Layer 类实现激活函数类,这里实现了最常用的 ReLU 激活函数。func 和 derivation_func 方法分别实现对应激活函数的正向计算和梯度计算。
# layer.py class Activation(Layer): """Base activation layer""" def __init__(self, name): super().__init__(name) self.inputs = None def forward(self, inputs): self.inputs = inputs return self.func(inputs) def backward(self, grad): return self.derivative_func(self.inputs) * grad def func(self, x): raise NotImplementedError def derivative_func(self, x): raise NotImplementedError class ReLU(Activation): """ReLU activation function""" def __init__(self): super().__init__("ReLU") def func(self, x): return np.maximum(x, 0.0) def derivative_func(self, x): return x > 0.03.net
上文提到 net 类负责管理 tensor 在 layers 之间的前向和反向传播。forward 方法很简单,按顺序遍历所有层,每层计算的输出作为下一层的输入;backward 则逆序遍历所有层,将每层的梯度作为下一层的输入。这里我们还将每个网络层参数的梯度保存下来返回,后面参数更新需要用到。另外 net 类还实现了获取参数、设置参数、获取梯度的接口,也是后面参数更新时需要用到
# net.py class Net(object): def __init__(self, layers): self.layers = layers def forward(self, inputs): for layer in self.layers: inputs = layer.forward(inputs) return inputs def backward(self, grad): all_grads = [] for layer in reversed(self.layers): grad = layer.backward(grad) all_grads.append(layer.grads) return all_grads[::-1] def get_params_and_grads(self): for layer in self.layers: yield layer.params, layer.grads def get_parameters(self): return [layer.params for layer in self.layers] def set_parameters(self, params): for i, layer in enumerate(self.layers): for key in layer.params.keys(): layer.params[key] = params[i][key]4.losses
上文我们提到 losses 组件需要做两件事情,给定了预测值和真实值,需要计算损失值和关于预测值的梯度。我们分别实现为 loss 和 grad 两个方法,这里我们实现多分类回归常用的 SoftmaxCrossEntropyLoss 损失。这个的损失 loss 和梯度 grad 的计算公式推导进文末附录,这里直接给出结果:多分类 softmax 交叉熵的损失为
梯度稍微复杂一点,目标类别和非目标类别的计算公式不同。对于目标类别维度,其梯度为对应维度模型输出概率减一,对于非目标类别维度,其梯度为对应维度输出概率本身。
代码实现如下
# loss.py class BaseLoss(object): def loss(self, predicted, actual): raise NotImplementedError def grad(self, predicted, actual): raise NotImplementedError class CrossEntropyLoss(BaseLoss): def loss(self, predicted, actual): m = predicted.shape[0] exps = np.exp(predicted - np.max(predicted, axis=1, keepdims=True)) p = exps / np.sum(exps, axis=1, keepdims=True) nll = -np.log(np.sum(p * actual, axis=1)) return np.sum(nll) / m def grad(self, predicted, actual): m = predicted.shape[0] grad = np.copy(predicted) grad -= actual return grad / m5.optimizer
optimizer 主要实现一个接口 compute_step,这个方法根据当前的梯度,计算返回实际优化时每个参数改变的步长。我们在这里实现常用的 Adam 优化器。
# optimizer.py class BaseOptimizer(object): def __init__(self, lr, weight_decay): self.lr = lr self.weight_decay = weight_decay def compute_step(self, grads, params): step = list() # flatten all gradients flatten_grads = np.concatenate( [np.ravel(v) for grad in grads for v in grad.values()]) # compute step flatten_step = self._compute_step(flatten_grads) # reshape gradients p = 0 for param in params: layer = dict() for k, v in param.items(): block = np.prod(v.shape) _step = flatten_step[p:p+block].reshape(v.shape) _step -= self.weight_decay * v layer[k] = _step p += block step.append(layer) return step def _compute_step(self, grad): raise NotImplementedError class Adam(BaseOptimizer): def __init__(self, lr=0.001, beta1=0.9, beta2=0.999, eps=1e-8, weight_decay=0.0): super().__init__(lr, weight_decay) self._b1, self._b2 = beta1, beta2 self._eps = eps self._t = 0 self._m, self._v = 0, 0 def _compute_step(self, grad): self._t += 1 self._m = self._b1 * self._m + (1 - self._b1) * grad self._v = self._b2 * self._v + (1 - self._b2) * (grad ** 2) # bias correction _m = self._m / (1 - self._b1 ** self._t) _v = self._v / (1 - self._b2 ** self._t) return -self.lr * _m / (_v ** 0.5 + self._eps)6.model
最后 model 类实现了我们一开始设计的三个接口 forward、backward 和 apply_grad ,forward 直接调用 net 的 forward ,backward 中把 net 、loss、optimizer 串起来,先计算损失 loss,然后反向传播得到梯度,然后 optimizer 计算步长,最后由 apply_grad 对参数进行更新
# model.py class Model(object): def __init__(self, net, loss, optimizer): self.net = net self.loss = loss self.optimizer = optimizer def forward(self, inputs): return self.net.forward(inputs) def backward(self, preds, targets) loss = self.loss.loss(preds, targets) grad = self.loss.grad(preds, targets) grads = self.net.backward(grad) params = self.net.get_parameters() step = self.optimizer.compute_step(grads, params) return loss, step def apply_grad(self, grads): for grad, (param, _) in zip(grads, self.net.get_params_and_grads()): for k, v in param.items(): param[k] += grad[k]三、整体结构
最后我们实现出来核心代码部分文件结构如下
tinynn ├── core │ ├── initializer.py │ ├── layer.py │ ├── loss.py │ ├── model.py │ ├── net.py │ └── optimizer.py其中 initializer.py 这个模块上面没有展开讲,主要实现了常见的参数初始化方法(零初始化、Xavier 初始化、He 初始化等),用于给网络层初始化参数。
四、MNIST 例子
框架基本搭起来后,我们找一个例子来用 tinynn 这个框架 run 起来。这个例子的基本一些配置如下
- 数据集:MNIST(http://yann.lecun.com/exdb/mnist/)
- 任务类型:多分类
- 网络结构:三层全连接 INPUT(784) -> FC(400) -> FC(100) -> OUTPUT(10),这个网络接收 的输入,其中 是每次输入的样本数,784 是每张 的图像展平后的向量,输出维度为 ,其中 是样本数,10 是对应图片在 10 个类别上的概率
- 激活函数:ReLU
- 损失函数:SoftmaxCrossEntropy
- optimizer:Adam(lr=1e-3)
- batch_size:128
- Num_epochs:20
这里我们忽略数据载入、预处理等一些准备代码,只把核心的网络结构定义和训练的代码贴出来如下
# example/mnist/run.py net = Net([ Dense(784, 400), ReLU(), Dense(400, 100), ReLU(), Dense(100, 10) ]) model = Model(net=net, loss=SoftmaxCrossEntropyLoss(), optimizer=Adam(lr=args.lr)) iterator = BatchIterator(batch_size=args.batch_size) evaluator = AccEvaluator() for epoch in range(num_ep): for batch in iterator(train_x, train_y): # training pred = model.forward(batch.inputs) loss, grads = model.backward(pred, batch.targets) model.apply_grad(grads) # evaluate every epoch test_pred = model.forward(test_x) test_pred_idx = np.argmax(test_pred, axis=1) test_y_idx = np.asarray(test_y) res = evaluator.evaluate(test_pred_idx, test_y_idx) print(res)运行结果如下
# tinynn Epoch 0 {'total_num': 10000, 'hit_num': 9658, 'accuracy': 0.9658} Epoch 1 {'total_num': 10000, 'hit_num': 9740, 'accuracy': 0.974} Epoch 2 {'total_num': 10000, 'hit_num': 9783, 'accuracy': 0.9783} ......可以看到测试集 accuracy 随着训练进行在慢慢提升,这说明数据在框架中确实按照正确的方式进行流动和计算,参数得到正确的更新。为了对比下效果,我用 Tensorflow 1.13 实现了相同的网络结构、采用相同的采数初始化方法、优化器配置等等,得到的结果如下
# Tensorflow 1.13.1 Epoch 0 {'total_num': 10000, 'hit_num': 9591, 'accuracy': 0.9591} Epoch 1 {'total_num': 10000, 'hit_num': 9734, 'accuracy': 0.9734} Epoch 2 {'total_num': 10000, 'hit_num': 9706, 'accuracy': 0.9706} ......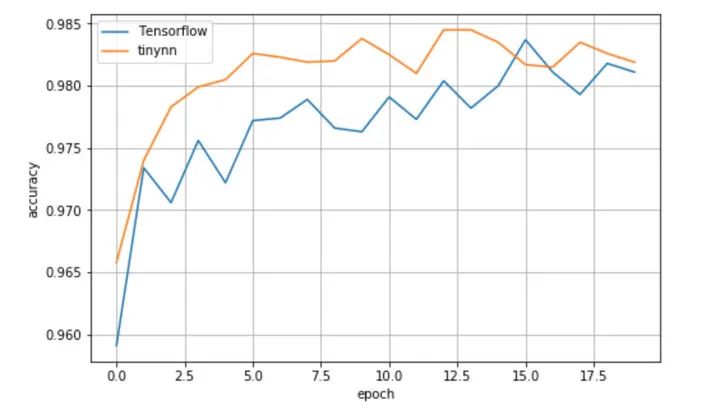
可以看到两者效果上大差不差,测试集准确率都收敛到 0.982 左右,就单次的实验看比 Tensorflow 稍微好一点点。
小结
tinynn 相关的源代码在这个 repo(https://github.com/borgwang/tinynn) 里。目前支持:
- layer :全连接层、2D 卷积层、 2D反卷积层、MaxPooling 层、Dropout 层、BatchNormalization 层、RNN 层以及 ReLU、Sigmoid、Tanh、LeakyReLU、SoftPlus 等激活函数
- loss:SigmoidCrossEntropy、SoftmaxCrossEntroy、MSE、MAE、Huber
- optimizer:RAam、Adam、SGD、RMSProp、Momentum 等优化器,并且增加了动态调节学习率 LRScheduler
- 实现了 mnist(分类)、nn_paint(回归)、DQN(强化学习)、AutoEncoder 和 DCGAN (无监督)等常见模型。见 tinynn/examples:https://github.com/borgwang/tinynn/tree/master/examples
当然 tinynn 只是一个「玩具」版本的深度学习框架,一个成熟的深度学习框架至少还需要:支持自动求导、高运算效率(静态语言加速、支持 GPU 加速)、提供丰富的算法实现、提供易用的接口和详细的文档等等。这个小项目的出发点更多地是学习,在设计和实现 tinynn 的过程中笔者个人学习确实到了很多东西,包括如何抽象、如何设计组件接口、如何更效率的实现、算法的具体细节等等。对笔者而言写这个小框架除了了解深度学习框架的设计与实现之外还有一个好处:后续可以在这个框架上快速地实现一些新的算法,新的参数初始化方法,新的优化算法,新的网络结构设计,都可以快速地在这个小框架上进行实验。如果你对自己设计实现一个深度学习框架也感兴趣,希望看完这篇文章会对你有所帮助,也欢迎大家提 PR 一起贡献代码~
赞8 踩0 评论0 -
回答了问题
2024-05-09
粘贴卡住
没遇到类似场景,可以试一下重新安装idea,或者换个版本安装,还有就是看看是否有快件键冲突
赞2 踩0 评论0 -
回答了问题
2024-05-09
PolarDB 刷脚本特别慢可能是什么问题,一个4M大小的脚本要刷半个多小时
1.确认网络原因,
2.确认数据库使用情况
3.确认数据是否正常,条数是多少
4.调用重试是否解决问题赞0 踩0 评论0 -
回答了问题
2024-05-09
ModelScope能编写股票量化交易代码吗?
请详细描述下你的使用场景,没懂你的意思,ModelSocpe是人工智能相关的,是可以生成代码的,你可以使用阿里的通义千问试一下,说出你的要求
赞1 踩0 评论0 -
回答了问题
2024-05-09
请问有人用ChatUI IMSDK部署过智能对话机器人吗?
截图太模糊了,检查镜像源是否配置正确,去aliyun镜像源生成自己的地址,配制好再试一次
赞3 踩0 评论0 -
回答了问题
2024-05-09
通义灵码在vscode无法登录
应该不需要配置代理,我这边不配置代理,是成功的,你检查一下你的安装过程是否正确
赞2 踩0 评论1 -
回答了问题
2024-05-09
flink cdc 实时同步oracel 12 物理备份库的报错是什么原因?是不支持备份库吗
通过分析结果,请确认当前用户对数据库的读写权限,截图中提示是只读权限。
 赞1 踩0 评论0
赞1 踩0 评论0 -
回答了问题
2024-05-09
算法工程师是学什么专业出身的?
数学专业,软件开发专业都可以
赞12 踩0 评论0 -
回答了问题
2024-05-09
你遇到过哪些触发NPE的代码场景?
NPE代码场景:
1.对象未进行初始化:对象未进行初始化就进行对象调用,尤其在单实例对象调用过程中场景,本人就犯过类似的错误。
2.对象未进行正确调用:对对象的调用需要首先调用初始化函数,然后才能调用,这个也是在单实例过程中比较常见,一般来说是不需要判断的,但是不排除别人的代码本身是有Bug的,所以还是要判断的
3.复杂逻辑处理过程导致对象未初始化或者已经释放:如果处理过程或者流程比较复杂,那么可能在代码后面的调用过程中,对象已经失效或者还未生效,此时需要进行空置判断。
4.对其他接口调用,返回指缺失空置判断:在调用其他人写的接口的时候,需要对他人的返回值需要非空判断,每个人的变成习惯都不一样,业务逻辑也不一样,水平更是不一样,这就非常容易导致类似问题的发生。NPE异常处理:
1.对象未初始化:对此类场景可以进行函数封装,对外只提供单一调用入口,然后开发者编写测试用例进行代码测试,规避风险。、
2.对象未正确初始化:对于此类场景,一种方式是开发者可以对对象进行进一步的代码封装,对外只提供单一入口,方便调用者使用。另一种方式是输出完整的接口使用手册,调用者严格按照手册来调用
3.复杂的处理逻辑:针对此类情况,可以拆分复杂处理过程为多个模块,一方面代码逻辑变简单了了,方便问题定位,另外一方面,方便后期代码维护,有的代码回过头来看,自己都不一定能读得懂。
4.接口调用:一方面定义统一的代码规范,大家都遵守这套规范来编程,另一方面是对别人的调用逻辑进行适当的空置处理,异常捕获,毕竟谁也不能保证自己写的代码就一定是OK的。赞14 踩0 评论0 -
回答了问题
2024-05-09
你见过哪些独特的代码注释?
回想一下这些年的工作经历,确实遇到过有趣的注释或者让人苦笑不得的注释,原话记不太清楚了,只能列个大概意思,供大家一笑:
不是原话,大概意思大差不差:
- 如果你在这里发现了一个 bug,请立即逃离,我已经离职了,别找我
- 这里是一个魔法的地方,不要触碰,我到目前为止,也没有完全搞明白
- 请不要问我为什么这样写,我也不知道
- 如果你能读懂这段代码,恭喜你,你是一个勇敢的人
- 这段代码是我写的最糟糕的代码之一,但它却奇迹般地生效了,我也懒得改了,虽然效率低下,但是能用,
赞15 踩0 评论0 -
回答了问题
2024-04-24
如何让系统具备良好的扩展性?
从事软件行业15年左右,有一些好的工作经验分享大家,需要让系统具备良好的扩展性,我一般的做法如下:
第一步:分析当前用户的业务场景,我需要搞清楚我们系统当面的业务场景是什么?当前场景具有哪些问题?这类问题或者场景的解决策略是什么?当前场景的用户体量是多少?分析用户的并发量等等第二步:对于已有系统,我们需要分析当前系统的技术架构,至少需要了解清楚我们系统当前的技术架构是否能够满足用户的需求?我们系统现在有哪些瓶颈需要处理?我们系统能够承载的最大负荷是多少等等
第三步:我们当前的系统是否能够满足当前的业务场景,不满足的话,我们需要从哪方面进行入手?那种方案投入产出比最好?那种方案时间最快等等,
第四步:如果是新建系统,我们需要考虑新建的系统需要支撑多大的用户体量?多的并发请求?采取什么样的技术方案等等。
经过以上四步,我才会去考虑我们扩展的方向或者重点,我会从几个方面进行优先考虑:
1.注重模块化的设计: 我会将系统拆分成多个独立的模块,每个模块负责一个特定的功能或业务逻辑,模块化的设计可以降低模块之间的耦合度,方便新增、修改或删除功能,同时也提高了代码的复用性。
2.重视接口设计: 我会为每个模块定义清晰的接口,规定输入参数和输出结果的格式,确保模块之间的通信和交互是统一和可靠的,接口设计可以使得模块之间的依赖关系更加清晰,方便扩展和替换模块。
3.可扩展的插件架构: 如果系统需要支持插件或扩展功能,我会设计一个灵活的插件架构,允许第三方开发者编写自定义插件并集成到系统中,大大增强系统的灵活性和可扩展性,满足不同用户的需求。
4.事件驱动设计: 最后,我会采用事件驱动的方式设计系统,通过事件和消息的发布订阅机制来实现模块之间的解耦和异步通信。这样可以使得系统更具弹性,能够更好地适应未来的扩展需求。
优秀的系统设计是一个循序渐进的过程,设计也是一样,我们需要考虑业务场景才能确定最佳扩展方式,没有最好的扩展方式,只有最合适的扩展。
赞50 踩0 评论0 -
回答了问题
2024-04-24
在JS编程中有哪些常见的编程“套路”或习惯?
前端代码开发过程中,有些好的编程习惯是直观重要的,与其说是套路,我更喜欢习惯这个词,我做前段超过5年,下面说一下我的个人编写习惯中最重要的5点:
1.我一般将功能拆分成独立的模块,提高代码的复用性和可维护性。
2.我会给变量、函数和类起一个有意义的名字,我采用的是驼峰命名法,这样可以让代码更易读易懂。
3.我会在代码中添加清晰明了的注释来解释代码的作用、实现逻辑和特殊情况,我还会编写文档说明函数的参数、返回值和用法,方便后期其他开发者理解和使用你的代码。
4.我会尽量避免在全局作用域中定义变量,而是通过使用模块化的方式组织代码,这样可以有效减少全局污染和命名冲突的可能性。
5.我会对可能发生错误的地方进行适当的错误处理,避免程序崩溃或产生未知的行为。
赞4 踩0 评论0 -
回答了问题
2024-04-24
在做程序员的道路上,你掌握了什么关键的概念或技术让你感到自身技能有了显著飞跃?
结合个人10多年的工作经历,在个人成长过程中,有几点秘籍或者心得可以分享如下:
1.全局视角:不管是工作,还是生活,我们遇到问题的时候总是习惯以一个当事人的角度去看,从内部去看,从小处去看,这么看往往会以偏概全,进而得出错误的结论,我们不管是讨论需求还是技术,都要时刻不忘跳出来看一看,我们的初心是什么?
2.整体架构:在落实一项具体的工作的时候,心中最好有一个整体的架构图,架构图的设计可能让我们能够更好的去了解模块之间或者产品之间的关系,进而分析出我们应该选择什么样的技术或者工具去解决事情,我们才能构建出更好的产品。
3.大处著眼,小处着手:前面俩点分开说总是感觉说的不够透彻,大处著眼,小处着手也正是基于此,我们在思考的时候能够全盘去思考,在实践的时候,我们可以选择一个小模块去慢慢设计,进而一步一步扩展到全局。如果一开始就全局入手的话,可能会因为概念太多或者太空而导致无从下手。
4.耐得住寂寞:有的时候学习代码或者写代码是一个漫长的过程,尤其是你已经达到了一定的高度,别人已经不能帮助你进行技术指点的时候,你有可能已经是某个领域的专家或者资深的时候,这个时候对你来说是非常难的,为了攻克某些技术,我们可能需要更能沉的下心来才能有更长足的进步。
5.不怕错误:这个不是是对于新手还是老鸟来说,都是比较重要的,我们天生的会对错误进行排斥,我们不喜欢错误,但是人家只有在面对错误解决错误的时候才能有一个更加深入的理解和成长,一直不面对错误最后就会导致我们面对错误一无所知。
6.分享和求助:这个也是非常重要的,不懂就问和乐于奉献是同样重要的,是一个事情的来面,我们不问别人是不知道我们有问题的,解决对你的问题无从解答,你的疑惑可能在别人看来早就解惑了。同样,别人的问题,我们也要做到乐于解答,在交流过程中进行知识的传播和碰撞。上面这几点,是我认为在成长过程中比较重要的,全局视角,整体架构,大处着眼,小处着手,耐得住寂寞,不怕错误,分享与求助。
赞3 踩0 评论0 -
回答了问题
2024-04-23
作为一个经典架构模式,事件驱动在云时代为什么会再次流行呢?
工作这么多年了,多多少少会对技术有一种特殊的敏感,谈到事件驱动,我的第一反应就是低耦合,松散,微服务,业务场景复杂,灵活,实时等这么写关键词,总结下来三个方面:
微服务架构的出现:微服务架构可谓是当前最热门的技术了,微服务的低耦合离不开事件驱动这一设计思路,微服务通过事件驱动可以更好地实现解耦和独立部署,提高系统的灵活性和可维护性。
云大厂的出现:云大厂的出现让我们每个人都能够使用的起服务器了,我们可以通过云服务器灵活地部署和扩展应用程序,事件驱动非常善于处理我们过程中的复杂业务,我们通过事件驱动设计,各个组件可以独立地响应事件,实现解耦和异步处理;
Web 3.0时代: 当前时代,数据正在呈爆炸式增长,人们对数据的实时性有了愈来愈多的要求,面对海量的实时数据,事件驱动架构可以帮助我们更好地处理实时事件流,实现更快的响应速度和更高的处理效率。
纯手工搭载,希望对读者有所帮助。
赞4 踩0 评论0 -
回答了问题
2024-04-09
你认为一个优秀的技术PM应该具备什么样的能力?
我个人是一步一步从开发做到了项目经理,再到产品经理的,谈不上资深,有几点是我认为一个优秀的技术产品经理应该具备以下能力:
- 技术背景:产品经理应该具备扎实的技术背景,能够理解和沟通技术需求、架构设计和开发流程,与工程团队有效合作。
- 产品视野:产品经理需要具备敏锐的产品洞察力和战略思维,能够深入了解用户需求、市场趋势,制定产品愿景和发展策略。
- 项目管理:产品经理需要具备良好的项目管理能力,能够制定项目计划、管理进度和资源,确保产品按时交付并符合质量标准。
- 沟通协调:产品经理应该具备优秀的沟通和协调能力,能够与跨部门团队有效沟通,协调资源和利益冲突,推动项目顺利进行。
- 用户导向:产品经理需要以用户为中心,关注用户体验,不断优化产品功能和设计,提升用户满意度和忠诚度。
- 创新思维:优秀的技术产品经理应该具备创新思维,能够不断探索新的产品功能和商业模式,保持竞争优势。
我是从技术一步一步干上来的,我深知经理在具备技术素养,产品素养,项目管理素养的同时,还需要有良好的沟通能力,同时具备以用户为导向的思维和创新思维,以上仅代表我个人观点。
赞4 踩0 评论0 -
回答了问题
2024-04-09
如何看待首个 AI 程序员入职科技公司?
一、今天你跟通义灵码互动的第一句话是什么,TA 是怎么回复的?
我的问题是:帮我实现汉诺塔算法

二、分享一下你使用通义灵码的感受:以下是我使用通义灵码的2点个人感受:
1.简单易用:通义灵码提供了简洁直观的用户界面,操作流程清晰明了,我可以非常方便简易的使用。
2.高效准确:通义灵码准确的理解了我的意图,并且高效快速地生成了文本数据和代码数据,并且具有较高的准确性。赞1 踩0 评论0
滑动查看更多
暂无更多信息