2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
? Vript: Refine Video Captioning into Video Scripting
将传统视频标注细化为视频脚本标注
Github地址: mutonix/Vript (github.com)
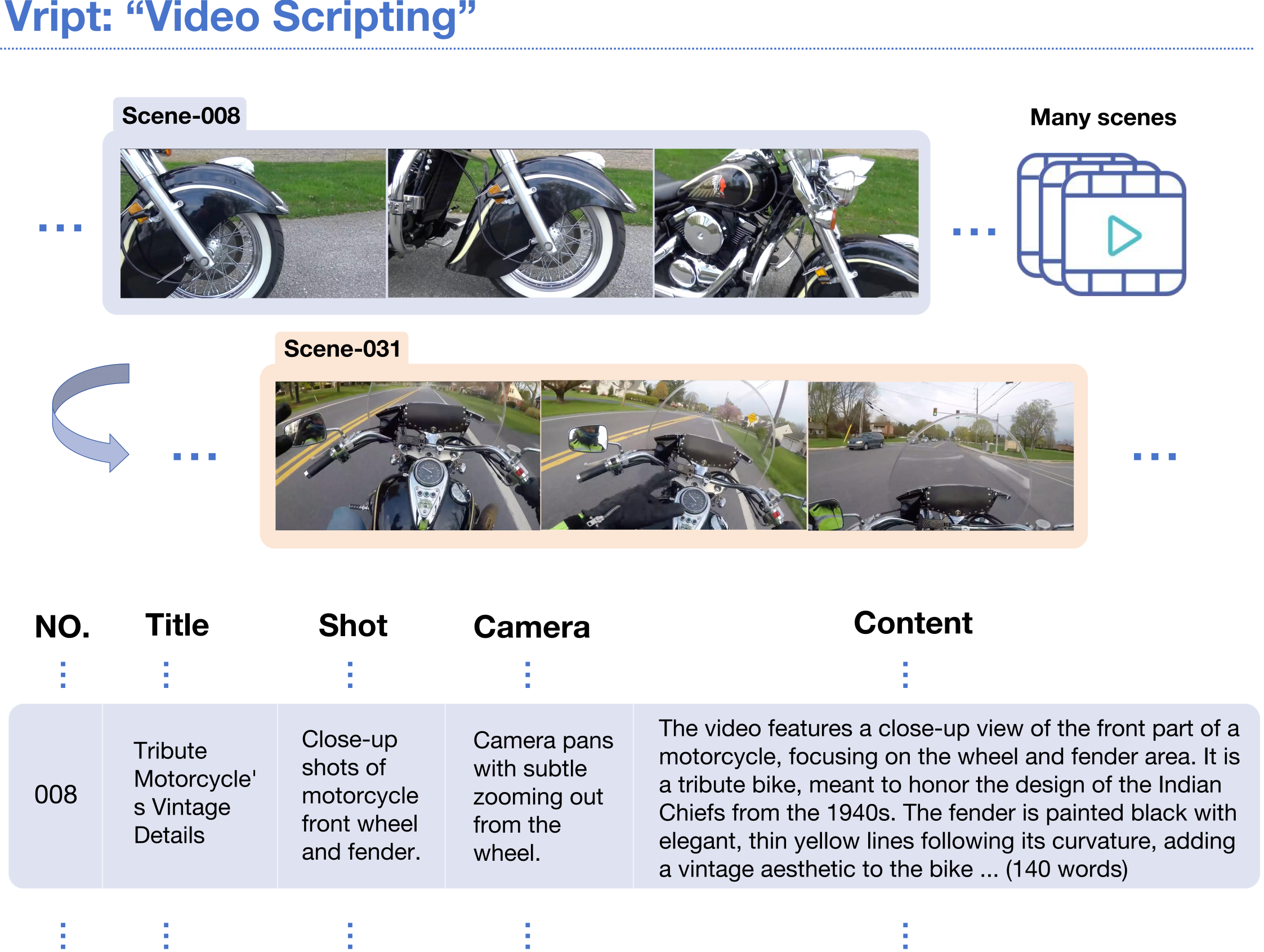
Vript是一个带有12K个注释的高分辨率视频(超过400k片段)的细粒度视频文本数据集。该数据集的注释受到视频脚本的启发。如果我们想做一个视频,我们必须首先写一个脚本来组织如何拍摄视频中的场景。为了拍摄一个场景,我们需要决定内容,拍摄类型(中景,特写等),以及相机如何移动(平移,倾斜等)。因此,受到视频脚本格式的启发,我们以视频脚本的方式对视频进行注释。与之前的视频文本数据集不同,我们在不丢弃任何场景的情况下对整个视频来进行密集注释,每个场景都有一个约145个单词的标题。除了视觉模态,我们还将画外音转录成文字,并与视频标题放在一起,为视频注释提供更多的背景信息。
此外,我们提出了Vript-Bench,这个新的benchmark包括三个具有挑战性的视频理解任务:
- Vript-CAP (Caption): 一个测试模型描述视频能力的benchmark。相比之前的benchmark,如MSR-VTT 以及Panda-70M ,它们的标注都比较短,一般只有一到两句话,对于目前的视频多模态模型来说,已经过于简单。Vript-CAP数据集测试模型输出详细描述的能力。
- Vript-RR(Retrieve then Reason): 一个新的视频推理benchmark。相比直接短视频片段的QA,Vript-RR基于长视频,首先给出视频中的场景的详细描述作为提示,然后就场景中的细节提出问题。
- Vript-ERO(Event Re-ordering): 一个新的视频时序推理benchmark。Vript-ERO通过提供位于同一视频的两个/四个不同视频时间点的场景描述,并要求模型给出正确的场景时间顺序。


