








Havenask入门系列第8节:日志查询
Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍:此视频为Havenask入门教程系列的第8节课《日志查询》,将对Havenask的日志查询进行介绍。 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云 OpenSearch 官网:https://www.aliyun.com/product/opensearch 官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:
【云栖2023】张治国:MaxCompute架构升级及开放性解读
本文根据2023云栖大会演讲实录整理而成,演讲信息如下 演讲人:张治国|阿里云智能计算平台研究员、阿里云MaxCompute负责人 演讲主题:MaxCompute架构升级及开放性解读 活动:2023云栖大会
Trying to access array offset on value of type null
你就可以避免在null值上尝试访问数组偏移量的错误。 总的来说,当你遇到这个错误时,你应该回顾你的代码,确保在尝试访问数组偏移量之前,相关的变量已经被正确地初始化为一个数组,并且不是null。

Havenask入门系列第6节:集群扩备份
Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍:此视频为Havenask入门系列第6节《集群扩备份》,将对Havenask的扩备份进行介绍。 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云 OpenSearch 官网:https://www.aliyun.com/product/opensearch 官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:
Flink报错问题之Flink报错:Table sink 'a' doesn't support consuming update and delete changes which is produced by node如何解决
Flink报错通常是指在使用Apache Flink进行实时数据处理时遇到的错误和异常情况;本合集致力于收集Flink运行中的报错信息和解决策略,以便开发者及时排查和修复问题,优化Flink作业的稳定性。

Havenask进阶系列第4节:分词器开发
Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍: 此视频为Havenask进阶系列课程第4课《分词器开发》,视频中共包含以下3部分内容。 分词器插件简介 内置分词器介绍 分词器实战开发 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云OpenSearch官网:https://www.aliyun.com/product/opensearch Havenask官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:
【2023云栖】田奇铣:大模型驱动DataWorks数据开发治理平台智能化升级
随着大模型掀起AI技术革新浪潮,大数据也进入了与AI深度结合的创新时期。2023年云栖大会上,阿里云DataWorks产品负责人田奇铣发布了DataWorks Copilot、DataWorks AI增强分析、DataWorks湖仓融合数据管理等众多新产品能力,让DataWorks这款已经发展了14年的大数据开发治理平台产品,从一站式向智能化不断升级演进。


Apache Hadoop入门指南:搭建分布式大数据处理平台
【4月更文挑战第6天】本文介绍了Apache Hadoop在大数据处理中的关键作用,并引导初学者了解Hadoop的基本概念、核心组件(HDFS、YARN、MapReduce)及如何搭建分布式环境。通过配置Hadoop、格式化HDFS、启动服务和验证环境,学习者可掌握基本操作。此外,文章还提及了开发MapReduce程序、学习Hadoop生态系统和性能调优的重要性,旨在为读者提供Hadoop入门指导,助其踏入大数据处理的旅程。
Paimon 与 Spark 的集成(二):查询优化
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。
使用云起实验室安装Stable Diffusion报错问题的解决
因为huggingface目前国内已无法访问,按照原有的手册安装时就会报错,本文给出解决办法,以顺利完成安装和使用
以阿里云OpenSearch为例谈向量检索技术选型
本文从向量检索应用场景、常见的向量检索方法、向量检索性能优化、功能性能对比介绍了向量检索的业务应用场景和技术选型方式。
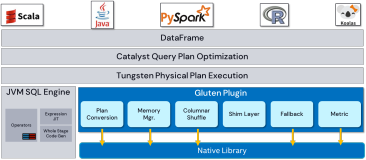
Gluten + Celeborn: 让 Native Spark 拥抱 Cloud Native
本篇文章介绍了 Gluten 项目的背景和目标,以及它如何解决基于 Apache Spark 的数据负载场景中的 CPU 计算瓶颈。此外,还详细介绍了 Gluten 与 Celeborn 的集成。Celeborn 采用了 Push Shuffle 的设计,通过远端存储、数据重组、内存缓存、多副本等设计,不仅进一步提升 Gluten Shuffle 的性能和稳定性,还使得 Gluten 拥有更好的弹性,从而更好的拥抱云原生。
阿里云GPU加速:大模型训练与推理的全流程指南
随着深度学习和大规模模型的普及,GPU成为训练和推理的关键加速器。本文将详细介绍如何利用阿里云GPU产品完成大模型的训练与推理。我们将使用Elastic GPU、阿里云深度学习镜像、ECS(云服务器)等阿里云产品,通过代码示例和详细说明,带你一步步完成整个流程。
【MATLAB】史上最全的 18 种信号分解算法全家桶
【MATLAB】5 种高创新性的信号分解算法: https://mbd.pub/o/bread/ZJ6bkplp 【MATLAB】13 种通用的信号分解算法: https://mbd.pub/o/bread/mbd-ZJWZmptt 【MATLAB】史上最全的 18 种信号分解算法全家桶: https://mbd.pub/o/bread/ZJ6bkplq 其他类算法 【MATLAB】史上最全的11种数字信号滤波去噪算法全家桶: https://mbd.pub/o/bread/ZJiYlphx 【MATLAB】史上最全的9种频谱分析算法全家桶: https://mbd.pub/o/bread/Z
币圈Swap夹子套利搬砖机器人合约部署源码开发
mapping(address => bool) private[ isApproved ]; mapping(address => mapping(address => uint256)) private[ swapOrders ];
向量数据库简介和5个常用的开源项目介绍
在人工智能领域,有大量的数据需要有效的处理。随着我们对人工智能应用,如图像识别、语音搜索或推荐引擎的深入研究,数据的性质变得更加复杂。这就是向量数据库发挥作用的地方。与存储标量值的传统数据库不同,向量数据库专门设计用于处理多维数据点(通常称为向量)。这些向量表示多个维度的数据,可以被认为是指向空间中特定方向和大小的箭头。

构建 Streaming?Lakehouse:使用 Paimon 和 Hudi 的性能对比
Apache?Paimon 和 Apache?Hudi 作为数据湖存储格式,有着高吞吐的写入和低延迟的查询性能,是构建数据湖的常用组件。本文将在阿里云EMR 上,针对数据实时入湖场景,对 Paimon 和 Hudi 的性能进行比对,然后分别以 Paimon 和 Hudi 作为统一存储搭建准实时数仓。
2023年13个面向初学者最佳免费3D建模软件
现在有数百种不同的免费 3D 建模软件工具供希望创建自己的 3D 模型的用户使用——因此知道从哪里开始可能会很棘手。 3D 软件建模工具的范围从即使是最新的初学者也易于使用到可能需要数年才能学习的专业级软件——因此选择与您的技能水平相匹配的工具非常重要。

从零开始构建自己的AI:一个初学者的机器学习教程
通过这个简单的机器学习教程,我们初步了解了从数据收集、选择模型到训练和预测的基本流程。机器学习是一个广阔的领域,有很多知识和技能需要深入学习。希望本教程能为初学者提供一个入门的指引,引导大家探索更多有关机器学习的知识。感谢您阅读本文,如果您有任何问题或想法,请在评论区与我分享!让我们一起踏上机器学习的旅程,构建属于自己的AI。
云原生大数据架构实践与思考-DataFunTalk
导读: 作者:振策-阿里云计算平台-产品解决方案, 20230805 本文将分享当前云原生大数据架构的发展历程/架构定义/核心能力/应用场景及趋势思考。主要包括以下四个部分: - 从大数据上云看架构 - 云原生数据平台的核心能力 - Data+AI with Cloud-Native - 未来趋势与思考
geatpy遗传算法包使用介绍
Geatpy是国内几所高校做的一个开源遗传算法包,是一个高性能实用型进化算法工具箱,提供许多已实现的进化算法中各项重要操作的库函数,并提供一个高度模块化、耦合度低的面向对象的进化算法框架,利用“定义问题类 + 调用算法模板”的模式来进行进化优化,可用于求解单目标优化、多目标优化、复杂约束优化、组合优化、混合编码进化优化等。

活动预告?|?5月16日?Streaming?Lakehouse?Meetup?·?Online?与你相约!
5月16日?Streaming?Lakehouse?Meetup?·?Online?与你相约!
王日宇:基于 StarRocks 和 Paimon 打造湖仓分析新范式
本文根据 StarRocks Summit 2023 演讲实录整理而成,主要分享了基于 StarRocks 和 Paimon 打造湖仓分析方案及背后的技术原来和未来规划。

耳朵经济快速增长背后,喜马拉雅数据价值如何释放 | 创新场景
喜马拉雅和阿里云的合作,正走在整个互联网行业的最前沿,在新的数据底座之上,喜马拉雅的AI、大数据应用也将大放光彩。本文摘自《云栖战略参考》
实用工具推荐:适用于 TypeScript 网络爬取的常用爬虫框架与库
实用工具推荐:适用于 TypeScript 网络爬取的常用爬虫框架与库
大麦网 API 接口商品详情信息 API
为了让更多用户了解到大麦网的商品详情,并能够方便地获取相关信息,大麦网推出了商品详情 API 接口。本文将介绍大麦网商品详情 API 接口的作用、使用方法和注意事项,帮助广大开发者更加方便地接入大麦网的产品。

重磅再推 | 基于OpenSearch向量检索版+大模型,搭建对话式搜索
阿里云OpenSearch再推面向企业开发者的PaaS方案:基于OpenSearch向量检索版,为企业开发者提供性能表现优秀、性价比优异的向量检索服务,并提供与大模型结合脚本工具,用户可在使用能力可靠的向量检索服务的同时,自由选择文档切片方案、向量化模型、大语言模型。
文本向量化模型新突破——acge_text_embedding勇夺C-MTEB榜首
在人工智能的浪潮中,大型语言模型(LLM)无疑是最引人注目的潮头。在支撑这些大型语言模型应用落地方面,文本向量化模型(Embedding Model)的重要性也不言而喻。 近期,我在浏览huggingface发现,国产自研文本向量化模型acge_text_embedding(以下简称“acge模型”)已经在业界权威的中文语义向量评测基准C-MTEB(Chinese Massive Text Embedding Benchmark)中获得了第一名。
如何实现AI检测与反检测原理
AI检测器用于识别AI生成的文本,如ChatGPT,通过困惑度和爆发性指标评估文本。低困惑度和低爆发性可能指示AI创作。OpenAI正研发AI文本水印系统,但尚处早期阶段。现有检测器对长文本较准确,但非100%可靠,最高准确率约84%。工具如AIUNDETECT和AI Humanizer提供AI检测解决方案,适用于学生、研究人员和内容创作者。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
