文章目录
一、状态一致性
1.1 一致性级别
1.2 三个级别的区别
二、一致性检查点(Checkpoints)
三、端到端(end-to-end)状态一致性
四、端到端的精确一次(ecactly-once)保证
4.1 幂等写入(Idempotent Writes)
4.2 事务写入 (Transactional Writes)
4.2.1 预写日志(Write-Ahead-Log,WAL)
4.2.2 两阶段提交(Two-Phase-Commit,2PC)
4.2.3 2PC 对外部 sink 系统的要求
4.2.4 不同 Source 和 Sink 的一致性
五、Flink+Kafka 端到端状态一致性的保证
5.1 Exactly-once 两阶段提交
5.2 两阶段提交步骤总结
一、状态一致性
当在分布式系统中引入状态时,自然也引入了一致性问题。一致性实际上是"正确性级别"的另一种说法,也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少?如果有偏差,是有漏掉的计数还是重复计数?
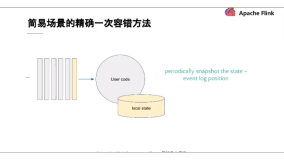
有状态的流处理,内部每个算子任务都可以有自己的状态
对于流处理内部来说,所谓的状态一致性,其实就是我们所说的计算结果保证准确。
一条数据不应该丢失,也不应该重复计算
在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
1.1 一致性级别
在流处理中,一致性可以分为 3 个级别:
at-most-once(最多一次): 这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。同样的还有 udp。
at-least-once (至少一次): 这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
exactly-once (精确一次): 这指的是系统保证在发生故障后得到的计数结果与正确值一致。恰好处理一次是最严格的保证,也是最难实现的。
1.2 三个级别的区别
曾经,at-least-once 非常流行。第一代流处理器(如 Storm 和 Samza)刚问世时只保证 at-least-once,原因有二。
保证 exactly-once 的系统实现起来更复杂。这在基础架构层(决定什么代表正确,以及 exactly-once 的范围是什么)和实现层都很有挑战性。
流处理系统的早期用户愿意接受框架的局限性,并在应用层想办法弥补(例如使应用程序具有幂等性,或者用批量计算层再做一遍计算)。
最先保证 exactly-once 的系统(Storm Trident 和 Spark Streaming)在性能和表现力这两个方面付出了很大的代价。为了保证 exactly-once,这些系统无法单独地对每条记录运用应用逻辑,而是同时处理多条(一批)记录,保证对每一批的处理要么全部成功,要么全部失败。这就导致在得到结果前,必须等待一批记录处理结束。因此,用户经常不得不使用两个流处理框架(一个用来保证 exactly-once,另一个用来对每个元素做低延迟处理),结果使基础设施更加复杂。曾经,用户不得不在保证exactly-once 与获得低延迟和效率之间权衡利弊。Flink 避免了这种权衡。
Flink 的一个重大价值在于,它既保证了 exactly-once,也具有低延迟和高吞吐的处理能力。
从根本上说,Flink 通过使自身满足所有需求来避免权衡,它是业界的一次意义重大的技术飞跃。尽管这在外行看来很神奇,但是一旦了解,就会恍然大悟。
二、一致性检查点(Checkpoints)
Flink 使用了一种轻量级快照机制 ---- 检查点(checkpoint)来保证 exactly-once 语义
有状态应用的一致检查点,其实就是:所有任务的状态,在某个时间点的一份拷贝(一份快照)。而这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
应用状态的一致检查点,是 Flink 故障恢复机制的核心

三、端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性
整个端到端的一致性级别取决于所有组件中一致性最弱的组件。
四、端到端的精确一次(ecactly-once)保证
我们知道,端到端(end-to-end)状态一致性取决于它所有组件中最薄弱的一环,也就是典型的木桶理论了。
具体可以划分如下:
内部保证 —— 依赖 checkpoint
source 端 —— 需要外部源可重设数据的读取位置
sink 端 —— 需要保证从故障恢复时,数据不会重复写入外部系统
而对于 sink 端,又有两种具体的实现方式:幂等(Idempotent)写入和事务性(Transactional)写入。
4.1 幂等写入(Idempotent Writes)
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
Hashmap 的写入插入操作是幂等的操作,重复写入,写入的结果还一样。