问题一:Flink CDC里.mongodb schema变更有什么好的方案处理吗?
Flink CDC里.mongodb schema变更有什么好的方案处理吗?
参考答案:
你可以看看阿里云的文章,
/article/1425190?spm=a2c6h.27925324.detail.38.25d35eefwklXT4#slide-2
关于本问题的更多回答可点击进行查看:
/ask/598585?spm=a2c6h.12873639.article-detail.77.50e24378TRW91E
问题二:我想把flink cdc同步的数据写入到目标服务器,该怎么做?有官方案例吗?
我想把flink cdc同步的数据写入到目标服务器,该怎么做?有官方案例吗?
参考答案:
要将Flink CDC同步的数据写入到目标服务器,你可以使用Flink的DataStream API来实现。以下是一个简单的示例代码,演示了如何将数据流写入到Kafka中:
import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; public class FlinkCDCToKafka { public static void main(String[] args) throws Exception { // 创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 从Flink CDC获取数据流 DataStream<String> cdcStream = getCDCStream(env); // 将数据流写入到Kafka cdcStream.addSink(new FlinkKafkaProducer<>( "localhost:9092", // Kafka broker地址 "your-topic", // Kafka主题 new SimpleStringSchema())); // 序列化方式 // 启动任务 env.execute("Flink CDC to Kafka"); } private static DataStream<String> getCDCStream(StreamExecutionEnvironment env) { // 在这里实现从Flink CDC获取数据流的逻辑 // 返回一个DataStream对象 return null; } }
在上述代码中,你需要根据实际情况实现getCDCStream方法,以从Flink CDC获取数据流。然后,通过addSink方法将数据流写入到Kafka中。你还需要根据你的需求修改Kafka的broker地址、主题和序列化方式等参数。
请注意,这只是一个简单的示例,你需要根据自己的实际情况进行适当的调整和扩展。另外,确保你已经添加了Flink和Kafka的相关依赖项,并正确配置了Flink和Kafka的环境。
关于本问题的更多回答可点击进行查看:
/ask/598584?spm=a2c6h.12873639.article-detail.78.50e24378TRW91E
问题三:flink cdc同步mysql分表,当作业启动之后,新增的分表同步不到,是mysql设置的问题吗?
flink cdc同步mysql分表,当作业启动之后,新增的分表同步不到,是mysql设置的问题,还是flink cdc的啊?这个是有打开的 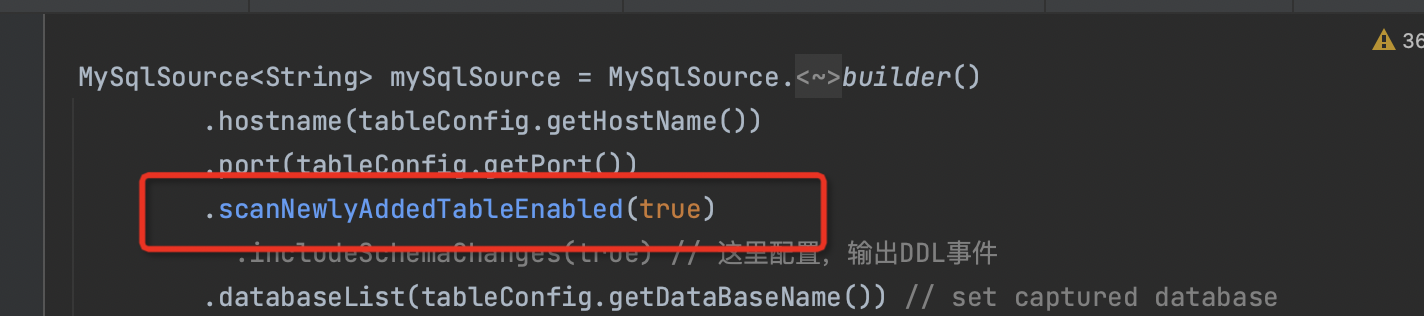
参考答案:
需要开启动态加表和检查点重启。一般是savepoint比较好,checkpoint如果配置了持久化,指定下路径也可以。动态加表,不对已经存在的表历史数据同步。
关于本问题的更多回答可点击进行查看:
/ask/598583?spm=a2c6h.12873639.article-detail.79.50e24378TRW91E
问题四:Flink CDC里我对某个字段做分组count的时候,source内容有变化,结果这样是为什么?
Flink CDC里我对某个字段做分组count的时候,source内容有变化,结果表只是做了insert,没有upsert,请问是什么原因,我ddl里有设置name为primary key(mysql里没有设置) 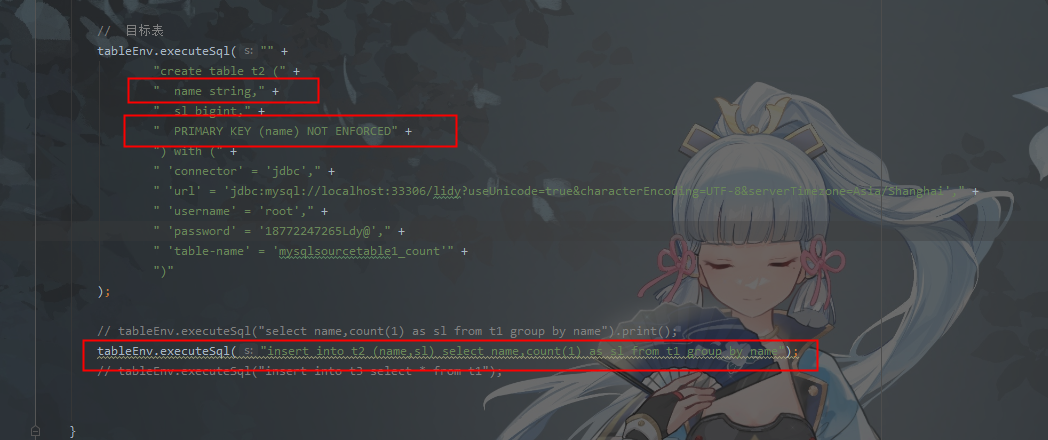
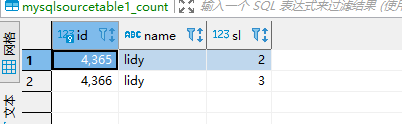
参考答案:
下游表需要设置业务主键 union key 也是name。就是说要在mysql里也给这个name字段添加唯一索引。
关于本问题的更多回答可点击进行查看:
/ask/598582?spm=a2c6h.12873639.article-detail.80.50e24378TRW91E
问题五:Flink CDC里1.18 planner使用哪个版本?
Flink CDC里1.18 planner使用哪个版本?我看有个planner-loader和一个指定scala版本的。
参考答案:
我记得是如果不用hive的话,默认的这个就行了。 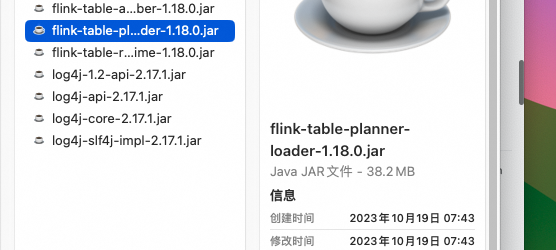 1.18要使用planner loader这个,然后也要额外添加runtime依赖,指定scala的那个planner内部依赖的某个类方法不太对。
1.18要使用planner loader这个,然后也要额外添加runtime依赖,指定scala的那个planner内部依赖的某个类方法不太对。 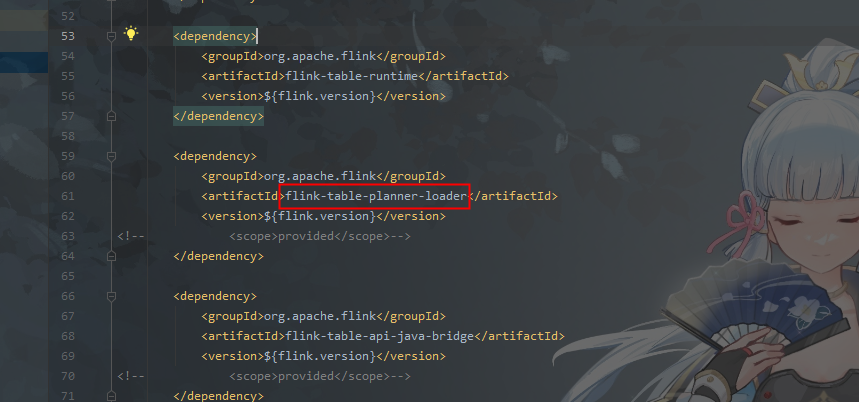
关于本问题的更多回答可点击进行查看:
/ask/598581?spm=a2c6h.12873639.article-detail.81.50e24378TRW91E


