问题一:Flink CDC里我们公司目前要集成oracle 的数据,它的cdc有没有在企业用过啊?
Flink CDC里我们公司目前要集成oracle 的数据,oracle的cdc有没有在企业中使用过啊?有没有什么疑难杂症呢?
参考回答:
问题一:Flink CDC 支持 Oracle 数据库的实时数据同步。在企业中,确实有使用 Flink CDC 集成 Oracle 数据的案例。关于疑难杂症,可能会遇到以下问题:
1. 网络不稳定:由于 Oracle 数据库通常部署在内网环境,因此需要确保网络连接稳定,以避免数据同步中断。
1. 数据库版本兼容性:确保 Oracle 数据库版本与 Flink CDC 兼容,否则可能无法正常同步数据。
1. 性能优化:根据业务需求和系统资源,可能需要对 Flink CDC 任务进行性能优化,例如调整并行度、缓冲区大小等。
问题二:对于使用 Oracle 数据库的公司,可以通过 Flink CDC 实现实时数据同步。解决方案如下:
1. 使用 Flink CDC 提供的 Oracle 连接器,配置数据源和目标端的相关信息,如用户名、密码、表名等。
1. 根据业务需求,设置数据同步的过滤条件,例如只同步某些表或者某些字段。
1. 部署 Flink CDC 任务,监控数据同步过程中的异常情况,并进行相应的处理。
总之,通过 Flink CDC,可以实现 Oracle 数据库的实时数据同步,帮助企业更好地利用数据,提高业务效率。
关于本问题的更多回答可点击原文查看:
/ask/594764?spm=a2c6h.13066369.question.96.283f3f3314D7zY
问题二:Flink CDC里我用cdc同步mysql数据到mysql,想增加一个表结构变更的通知,该怎么做?
Flink CDC里我用cdc同步mysql数据到mysql,想增加一个表结构变更的通知,这个该怎么实现呢?有相似的实现吗?
参考回答:
在 Flink CDC 中,你可以使用 Change Data Capture (CDC) 来捕获源数据库的表结构变更通知。具体实现方式如下:
配置 CDC: 首先,你需要在 Flink CDC 的配置中启用表结构变更通知。这可以通过设置 scan.startup.mode 参数为 latest-offset 来实现。这将告诉 Flink CDC 从最新的偏移量开始读取数据,并包括表结构变更的通知。
处理表结构变更通知: 当 Flink CDC 检测到表结构变更时,它会生成一个特殊的事件,称为 "DDL"(Data Definition Language)事件。你可以在 Flink 作业中添加逻辑来处理这些 DDL 事件。例如,你可以根据 DDL 事件的类型(如创建表、修改表、删除表等)执行相应的操作,如更新目标数据库的表结构或触发其他处理流程。
自定义处理逻辑: 根据你的需求,你可以编写自定义的逻辑来处理 DDL 事件。例如,你可以使用 Flink 提供的 API 来动态地创建或修改目标数据库中的表结构,或者将 DDL 事件写入日志文件以供后续处理。
需要注意的是,具体的实现方式可能因你使用的 Flink CDC 连接器和目标数据库而有所不同。因此,建议查阅相关文档或示例代码,以了解如何在你的特定环境中实现表结构变更通知。
另外,如果你使用的是 MySQL 数据库,可以考虑使用第三方工具或库来监听 MySQL 的 binlog,并在表结构变更时触发相应的操作。一些常见的工具包括 Canal、Maxwell 和Debezium。这些工具可以与 Flink CDC 结合使用,以便在表结构变更时进行实时的数据同步和处理。
关于本问题的更多回答可点击原文查看:
/ask/594760?spm=a2c6h.13066369.question.97.283f3f33EHhLZ0
问题三:Flink CDC里这个错误怎么解决?
Flink CDC里这个错误怎么解决? 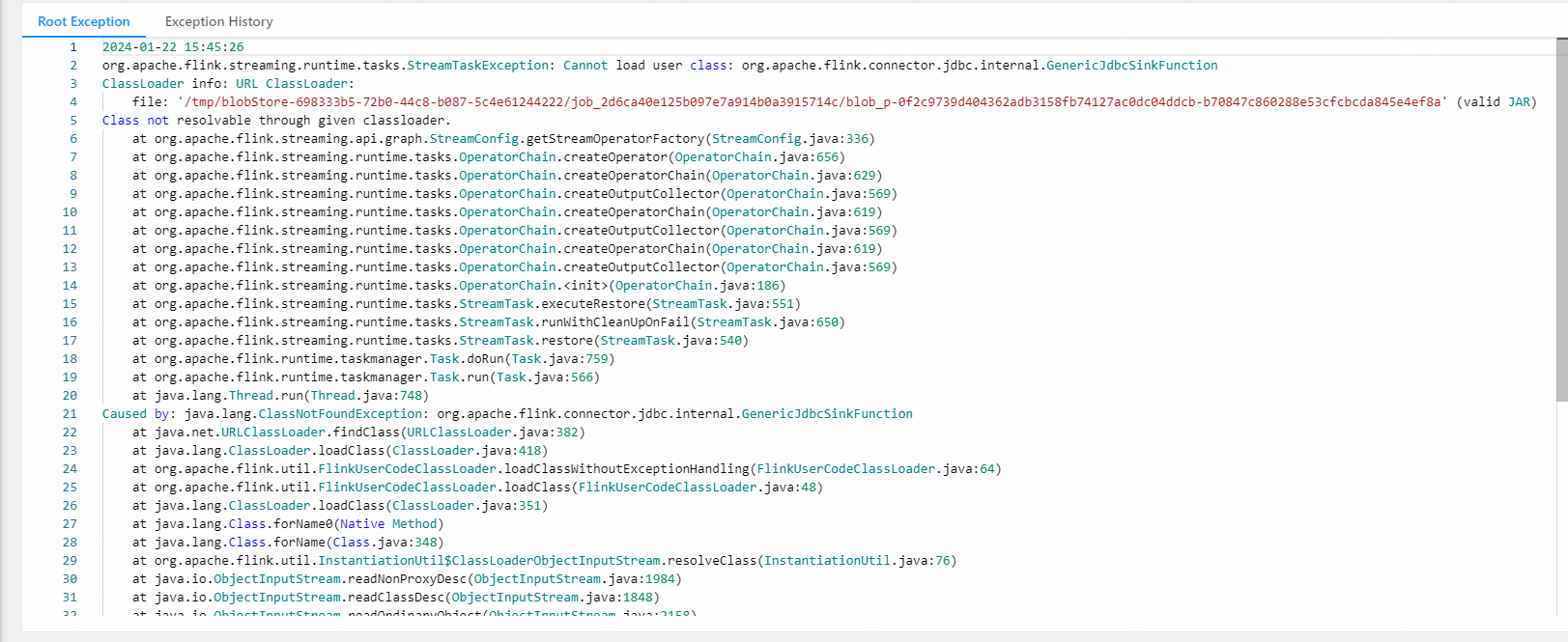
参考回答:
这个错误是由于Flink CDC无法加载用户类org.apache.flink.connector.jdbc.internal.GenericJdbcsinkFunction。要解决这个问题,你可以尝试以下方法:
1. 确保你的Flink CDC依赖中包含了org.apache.flink.connector.jdbc.internal.GenericJdbcsinkFunction类。检查你的项目依赖,确保已经添加了正确的Flink CDC和JDBC连接器依赖。
1. 检查你的Flink集群的类路径,确保org.apache.flink.connector.jdbc.internal.GenericJdbcsinkFunction类可以被找到。如果你在本地运行Flink任务,确保将相关依赖添加到项目的类路径中。
1. 如果你使用的是Flink on Yarn或者其他分布式环境,请确保将相关依赖分发到所有工作节点上。你可以将这些依赖打包到一个fat jar或者使用分布式缓存将依赖分发到所有节点。
1. 如果问题仍然存在,可能是由于类加载器的问题。尝试使用不同的类加载器策略,例如将Flink的类加载器设置为父优先(parent-first)模式。你可以在Flink的配置文件中设置jobmanager.classpaths.packaged: false来实现这一点。
1. 如果以上方法都无法解决问题,建议查阅Flink CDC和JDBC连接器的官方文档,查找是否有关于类似问题的解决方法。同时,你也可以在Flink社区论坛或者GitHub仓库中寻求帮助。
关于本问题的更多回答可点击原文查看:
/ask/594756?spm=a2c6h.13066369.question.98.283f3f33nPIYZl
问题四:Flink CDC里如果源端 MySQL 主键是bigint unsigned 类型, 怎么转换?
Flink CDC里如果源端 MySQL 主键是bigint unsigned 类型, 转换成 cdc 类型为 decimal , 然后写到 starrocks 对应的类型为 decimal128 , StarRocks 不支持 decimal 作为主键的类型, 我也尝试过改 cdc 源码将 bigint unsigned 转换为 bigint , 但在存入 starrocks 时候,主键在 mysql 是 1 , 在 starrocks 是一长串,这该怎么做?
参考回答:
你可以尝试将MySQL中的bigint unsigned类型转换为字符串类型,然后在StarRocks中将字符串类型作为主键。具体操作如下:
1. 在Flink CDC中,将源端MySQL的bigint unsigned类型转换为字符串类型。你可以在CDC的数据流中添加一个转换操作,将bigint unsigned类型的字段转换为字符串类型。例如,如果你使用的是Java,可以使用以下代码进行转换:
DataStream<Row> dataStream = ...; // 从MySQL读取的数据流 DataStream<Row> convertedStream = dataStream.map(row -> { Object bigIntValue = row.getField(0); // 假设bigint unsigned类型的字段是第一个字段 long longValue = ((BigInteger) bigIntValue).longValue(); String stringValue = String.valueOf(longValue); return Row.of(stringValue, ...); // 将其他字段保持不变 });
1. 将转换后的数据流写入StarRocks。在StarRocks中,将字符串类型的字段作为主键。你可以使用Flink的JDBC连接器将数据写入StarRocks。确保在StarRocks中创建表时,将主键字段的类型设置为字符串类型(例如,VARCHAR)。
这样,你就可以避免使用不支持的decimal类型作为主键,同时保持数据的完整性。
关于本问题的更多回答可点击原文查看:
/ask/594749?spm=a2c6h.13066369.question.99.283f3f33pbcXgI
问题五:Flink CDC里我一执行滚动开窗,就报下面的错误怎么解决?
Flink CDC里就是消费kafka中的debezium-json格式数据,使用滚动窗口统计1分钟新增的数据量,这个简单的需求,被卡住了。之前一直写的datastream,现在想用flink sql来实现我本来就是消费的kafka数据,为什么还要推到kafka里面?我现在数据源是kafka,kafka中的数据是flink cdc同步到kafka中的,数据有更新,有插入。
// 源表
tableEnv.executeSql("CREATE TABLE KafkaTable (\n" +
" UNSEND_ID STRING,\n" +
" SEND_TIME BIGINT,\n" +
" SENDER_CODE STRING,\n" +
" STATUS STRING,\n" +
" CREATE_TIME BIGINT,\n" +
" ts AS TO_TIMESTAMP_LTZ(CREATE_TIME, 3),\n" +
" WATERMARK FOR ts AS ts - INTERVAL '2' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'T_E10_MESSAGE_UNSEND_INFO',\n" +
" 'properties.bootstrap.servers' = 'hadoop01:9092',\n" +
" 'properties.group.id' = 'test',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'debezium-json'\n" +
")\n");// 开窗聚合
tableEnv.executeSql("select\n" +
" TUMBLE_START(ts, interval '1' MINUTE),\n" +
" TUMBLE_END(ts, interval '1' MINUTE),\n" +
" count(1) as cnt\n" +
"from KafkaTable\n" +
"group by TUMBLE(ts, interval '1' MINUTE)").print();
就是上面的数据,我一执行滚动开窗,就报下面的错误怎么解决?Exception in thread "main" org.apache.flink.table.api.TableException: StreamPhysicalGroupWindowAggregate doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[default_catalog, default_database, KafkaTable, watermark=[-(TO_TIMESTAMP_LTZ($4, 3), 2000:INTERVAL SECOND)]]], fields=[UNSEND_ID, SEND_TIME, SENDER_CODE, STATUS, CREATE_TIME])有点理解了,但是为什么我指定'format' = 'debezium-json'就不行呢?
参考回答:
根据你提供的信息,问题出在使用了debezium-json格式的数据源。滚动窗口聚合操作不支持消费由TableSourceScan节点产生的更新和删除更改。这是因为debezium-json格式的数据源会将数据变更(如插入、更新和删除)作为单独的记录发送到Kafka,而不是将它们作为数据流的一部分。
要解决这个问题,你可以尝试以下方法:
1. 使用Flink SQL的ROW_NUMBER()函数为每个数据变更分配一个唯一的行号。然后,你可以根据这个行号进行分组和聚合操作。这样,你可以避免使用滚动窗口聚合操作,而是使用分组和聚合操作来处理数据变更。
1. 如果你仍然希望使用滚动窗口聚合操作,你可以考虑将数据变更转换为数据流。这可以通过使用Flink的CEP(Complex Event Processing)库来实现。CEP库允许你处理事件流中的模式匹配和状态管理。你可以使用CEP库来检测数据变更,并将它们转换为数据流,然后再应用滚动窗口聚合操作。
关于为什么指定'format' = 'debezium-json'就不行的问题,这是因为debezium-json格式的数据源与Flink SQL的滚动窗口聚合操作不兼容。如上所述,debezium-json格式的数据源会将数据变更作为单独的记录发送到Kafka,而不是将它们作为数据流的一部分。因此,你需要使用其他方法来处理这些数据变更,例如使用Flink SQL的ROW_NUMBER()函数或使用Flink的CEP库。
关于本问题的更多回答可点击原文查看:
