问题一:Flink CDC里用maven shade在做relocation时,如何处理这个多语言的反应?
link CDC里用maven shade在做relocation时,只编译进来了Java,而Scala没有被编译进rename后的jar,你们是如何处理这个多语言的relocation呢 ?例如:本来a.jar=10k, rename 后只有8k了,少了2k的scala的代码。
参考回答:
在Apache Flink CDC项目中,如果你使用Maven Shade Plugin进行relocation并遇到只包含了Java代码而未包含Scala代码的问题,可能是shade plugin在处理混合Java和Scala项目的依赖时发生了问题。这是因为Scala编译后的字节码分布在多个地方,不仅仅是类路径下的.class文件,还可能涉及到元数据和其他scala专用的目录结构。
要确保在relocation过程中正确包含Scala部分,你需要确保Maven Shade Plugin的配置正确涵盖了Scala相关的资源。以下是一种可能的解决方案:
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <!-- 使用适合你的版本 --> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/> <!-- 处理META-INF/services的合并 --> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <!-- 修改MANIFEST.MF文件 --> </transformer> <!-- 如果需要重定位,添加Relocator配置 --> <transformer implementation="org.apache.maven.plugins.shade.resource.ApacheNoticeResourceTransformer"/> <!-- 保持Apache许可证信息 --> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.handlers</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.schemas</resource> </transformer> <!-- 举例:处理Spring框架相关的资源 --> </transformers> <relocations> <!-- 示例:重定位包 --> <relocation> <pattern>原包名</pattern> <shadedPattern>新包名</shadedPattern> </relocation> </relocations> <!-- 确保包含所有资源,特别是Scala相关的 --> <filters> <filter> <artifact>*:*</artifact> <excludes> <!-- 排除不希望shade的内容 --> <exclude>**/*.html</exclude> <exclude>**/*.txt</exclude> </excludes> </filter> <filter> <!-- 包含所有Scala相关资源 --> <artifact>**/*scala*</artifact> <includes> <include>**/*.class</include> <!-- 如果还有其他Scala相关的资源,比如*.sbt、*.scala等 --> </includes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build>
特别要注意的是, 部分需要确保不会意外排除掉Scala编译后的任何.class文件或者其他重要的Scala资源。此外,如果你使用了特殊的Scala插件进行构建,可能还需要额外配置确保它们在shade阶段也被正确处理。
在实践中,有时仅仅依靠Shade Plugin的标准配置可能不够,因为Scala编译后的某些资源可能隐藏在复杂的目录结构中,此时可能需要更精细的过滤和迁移策略。
关于本问题的更多回答可点击原文查看:/ask/592292
问题二:Flink CDC里整库同步的时候,因为源表有写字段是大文本,怎么解决同步问题?
Flink CDC里整库同步的时候,因为源表有写字段是大文本:longblob、text等等,这时候CDC就无法同步数据了,如何解决这个问题吗? 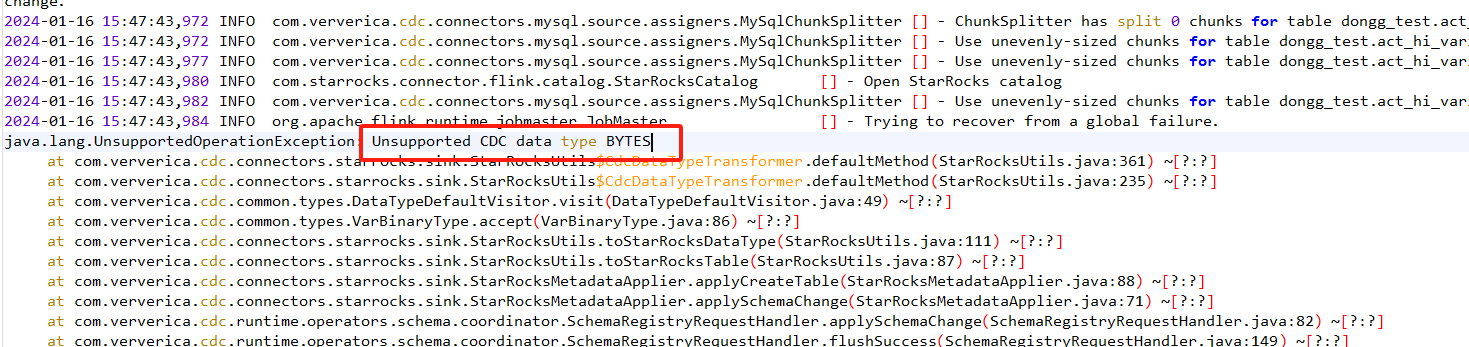
参考回答:
改下StarRocksUtils这个类的createFieldGetter方法,使其支持下bytes格式。 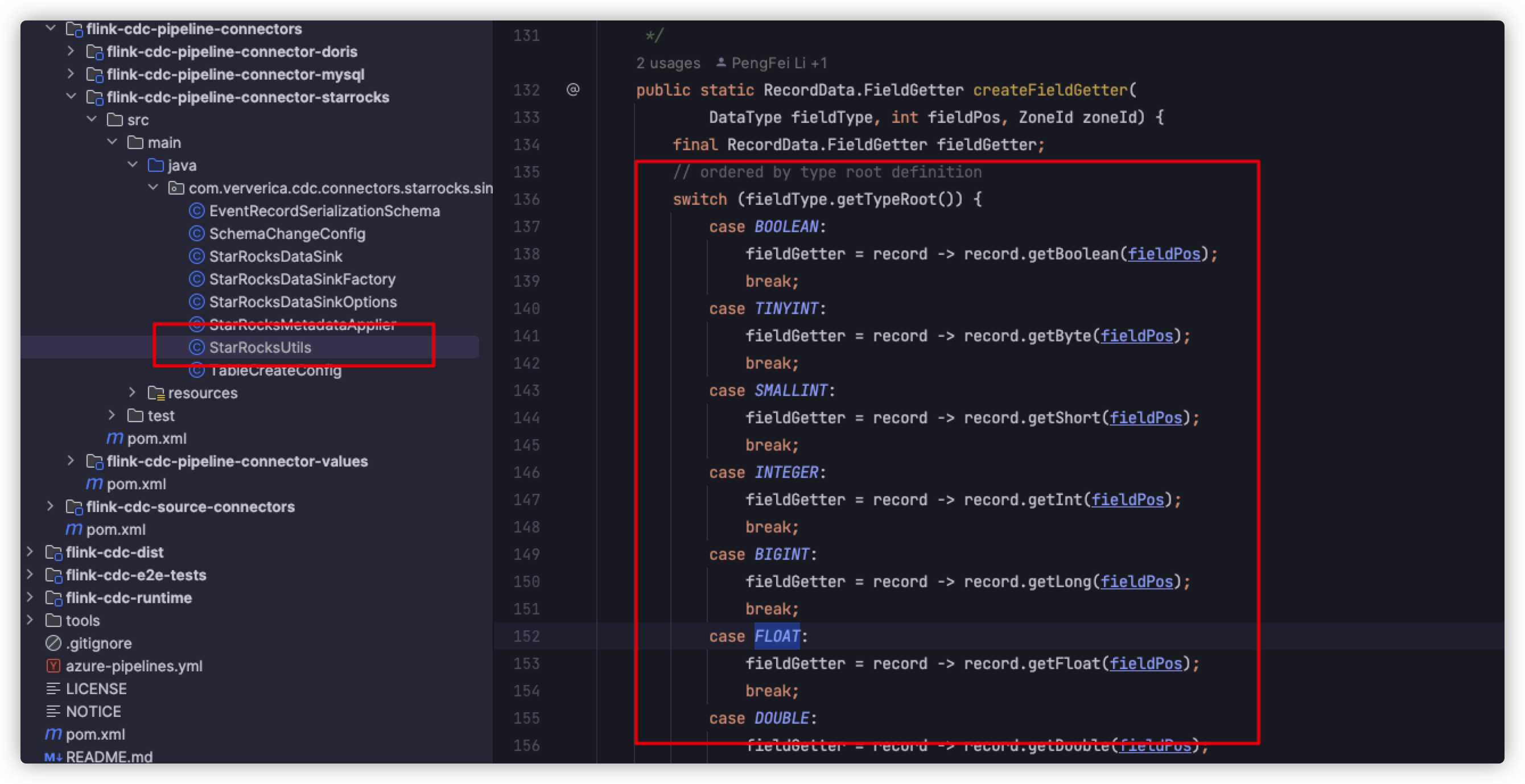
关于本问题的更多回答可点击原文查看:/ask/592296
问题三:Flink CDC里mysql5.7和mysql8是不是binlog生成机制不一样?
Flink CDC里mysql5.7和mysql8是不是binlog生成机制不一样? 还是说是binlog的配置不一样, 都开启了binlog 但是 mysql8读不到啊?
参考回答:
参考  show variables like 'log_bin';
show variables like 'log_bin';
关于本问题的更多回答可点击原文查看:/ask/592297
问题四:Flink CDC里增量快照是单个作业内多并行度,但是多个作业、每个作业同步的不同库可以同时运行吗?
Flink CDC里增量快照是单个作业内多并行度,但是多个作业、每个作业同步的不同库,但不同库在一个实例下,这时能多个库的作业同时运行吗?怎么控制数据库中创建复制槽不阻塞呢?
参考回答:
可以的啊,但是不建议这样操作,一个是一个库一个job。
关于本问题的更多回答可点击原文查看:/ask/592300
问题五:Flink CDC里 是重新下载3.0的版本还是 等3.1发版?
Flink CDC里
这个pr, 解决了 不在同步列表的 其他表schema变动,导致任务失败的问题吧, 是重新下载3.0的版本还是 等3.1发版? 目前 这个问题 在生产环境的 同步流程完全没法用,时不时就任务失败了 。 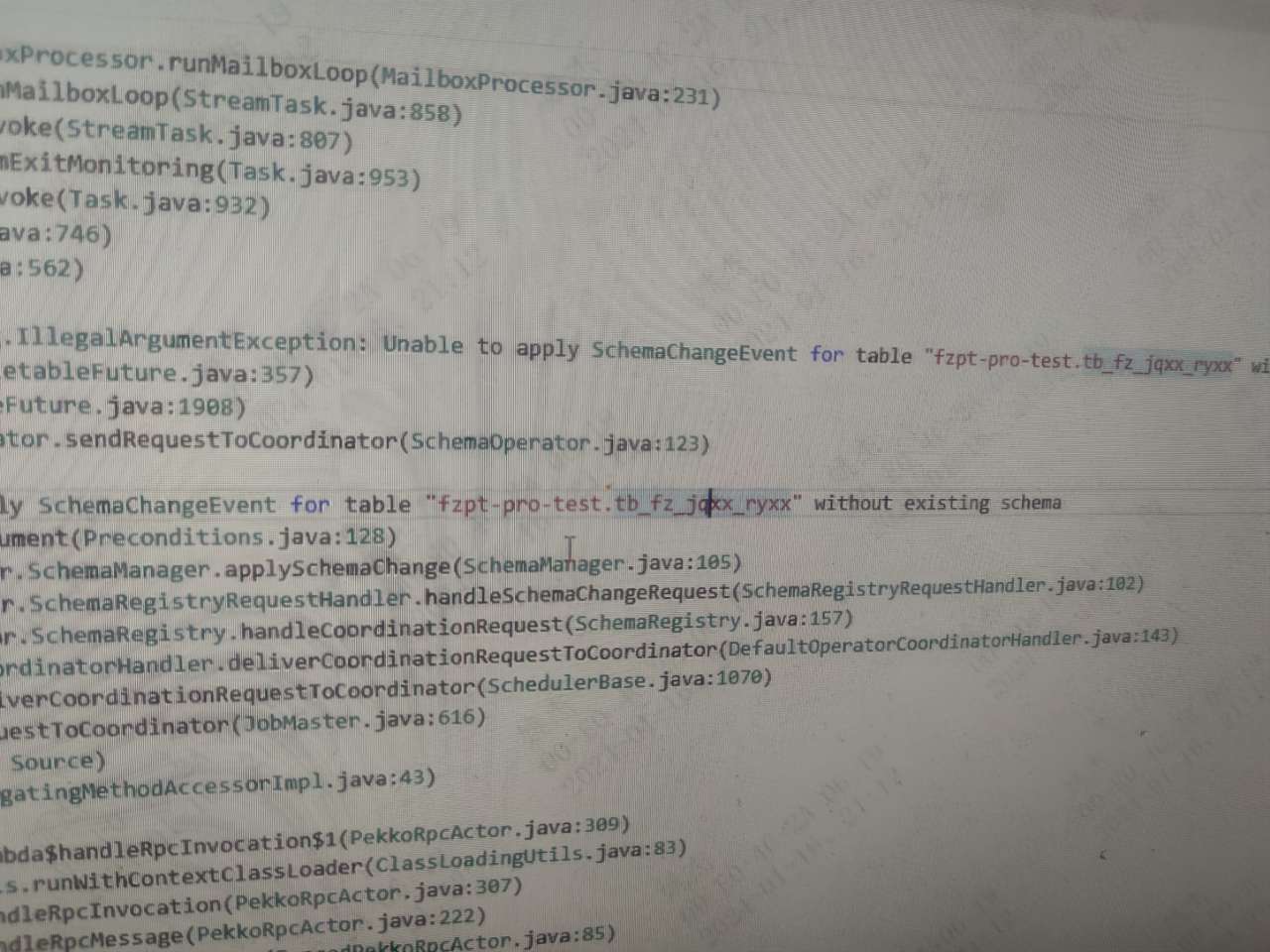
参考回答:
这周发布一个小版本的包解决。着急的话自己先在 master 的分支上打包替换 mysql 的 jar。
关于本问题的更多回答可点击原文查看:/ask/592301
