近日Apache Hudi社区合并了Flink引擎的基础实现(HUDI-1327),这意味着 Hudi 开始支持 Flink 引擎。有很多小伙伴在交流群里咨询 Hudi on Flink 的使用姿势,三言两语不好描述,不如实操演示一把,于是有了这篇文章。
当前 Flink 版本的Hudi还只支持读取 Kafka 数据,Sink到 COW(COPY_ON_WRITE) 类型的 Hudi 表中,其他功能还在继续完善中。
这里我们简要介绍下如何从 Kafka 读取数据写出到Hudi表。
1. 打包
由于还没有正式发布, 我们需要到Github下载源码自行打包。
git clone https://github.com/apache/hudi.git && cd hudimvn clean package -DskipTests
Windows 系统用户打包时会报如下错误:
[ERROR] Failed to execute goal org.codehaus.mojo:exec-maven-plugin:1.6.0:exec (Setup HUDI_WS) on project hudi-integ-test: Command execution failed. Cannot run program "\bin\bash" (in directory "D:\github\hudi\hudi-integ-test"): CreateProcess error=2, 系统找不到指定的文件。 -> [Help 1][ERROR][ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.[ERROR] Re-run Maven using the -X switch to enable full debug logging.[ERROR][ERROR] For more information about the errors and possible solutions, please read the following articles:[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException[ERROR][ERROR] After correcting the problems, you can resume the build with the command[ERROR] mvn <goals> -rf :hudi-integ-test
这是 hudi-integ-test 模块的一个bash脚本无法执行导致的错误,我们可以把它注释掉。
修改D:\github\hudi\pom.xml根pom文件
<modules> <module>hudi-common</module> <module>hudi-cli</module> <module>hudi-client</module> <module>hudi-hadoop-mr</module> <module>hudi-spark</module> <module>hudi-timeline-service</module> <module>hudi-utilities</module> <module>hudi-sync</module> <module>packaging/hudi-hadoop-mr-bundle</module> <module>packaging/hudi-hive-sync-bundle</module> <module>packaging/hudi-spark-bundle</module> <module>packaging/hudi-presto-bundle</module> <module>packaging/hudi-utilities-bundle</module> <module>packaging/hudi-timeline-server-bundle</module> <module>docker/hoodie/hadoop</module><!-- <module>hudi-integ-test</module>--><!-- <module>packaging/hudi-integ-test-bundle</module>--> <module>hudi-examples</module> <module>hudi-flink</module> <module>packaging/hudi-flink-bundle</module> </modules>
再次执行 mvn clean package -DskipTests, 执行成功后,找到这个jar : D:\github\hudi\packaging\hudi-flink-bundle\target\hudi-flink-bundle_2.11-0.6.1-SNAPSHOT.jar (笔者Hudi源码在D:\github\ 路径下,大家根据自己实际路径找一下)
这个 hudi-flink-bundle_2.11-0.6.1-SNAPSHOT.jar 就是我们需要使用的flink客户端,类似于原版的 hudi-utilities-bundle_2.11-x.x.x.jar 。
2. 入参介绍
有几个必传的参数介绍下:
?--kafka-topic :Kafka 主题?--kafka-group-id :消费组?--kafka-bootstrap-servers : Kafka brokers?--target-base-path : Hudi 表基本路径?--target-table :Hudi 表名?--table-type :Hudi 表类型?--props : 任务配置
其他参数可以参考 org.apache.hudi.HoodieFlinkStreamer.Config,里面每个参数都有介绍 。
3. 启动准备清单
1.Kafka 主题,消费组2.jar上传到服务器3.schema 文件4.Hudi任务配置文件
注意根据自己的配置把配置文件放到合适的地方,笔者的 hudi-conf.properties和schem.avsc文件均上传在HDFS。
-rw-r--r-- 1 user user 592 Nov 19 09:32 hudi-conf.properties-rw-r--r-- 1 user user 39086937 Nov 30 15:51 hudi-flink-bundle_2.11-0.6.1-SNAPSHOT.jar-rw-r--r-- 1 user user 1410 Nov 17 17:52 schema.avsc
hudi-conf.properties内容如下
hoodie.datasource.write.recordkey.field=uuidhoodie.datasource.write.partitionpath.field=tsbootstrap.servers=xxx:9092hoodie.deltastreamer.keygen.timebased.timestamp.type=EPOCHMILLISECONDShoodie.deltastreamer.keygen.timebased.output.dateformat=yyyy/MM/ddhoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.TimestampBasedAvroKeyGeneratorhoodie.embed.timeline.server=falsehoodie.deltastreamer.schemaprovider.source.schema.file=hdfs://olap/hudi/test/config/flink/schema.avschoodie.deltastreamer.schemaprovider.target.schema.file=hdfs://olap/hudi/test/config/flink/schema.avsc
schema.avsc内容如下
{ "type":"record", "name":"stock_ticks", "fields":[{ "name": "uuid", "type": "string" }, { "name": "ts", "type": "long" }, { "name": "symbol", "type": "string" },{ "name": "year", "type": "int" },{ "name": "month", "type": "int" },{ "name": "high", "type": "double" },{ "name": "low", "type": "double" },{ "name": "key", "type": "string" },{ "name": "close", "type": "double" }, { "name": "open", "type": "double" }, { "name": "day", "type":"string" }]}
4. 启动任务
/opt/flink-1.11.2/bin/flink run -c org.apache.hudi.HoodieFlinkStreamer -m yarn-cluster -d -yjm 1024 -ytm 1024 -p 4 -ys 3 -ynm hudi_on_flink_test hudi-flink-bundle_2.11-0.6.1-SNAPSHOT.jar --kafka-topic hudi_test_flink --kafka-group-id hudi_on_flink --kafka-bootstrap-servers xxx:9092 --table-type COPY_ON_WRITE --target-base-path hdfs://olap/hudi/test/data/hudi_on_flink --target-table hudi_on_flink --props hdfs://olap/hudi/test/config/flink/hudi-conf.properties --checkpoint-interval 3000 --flink-checkpoint-path hdfs://olap/hudi/hudi_on_flink_cp
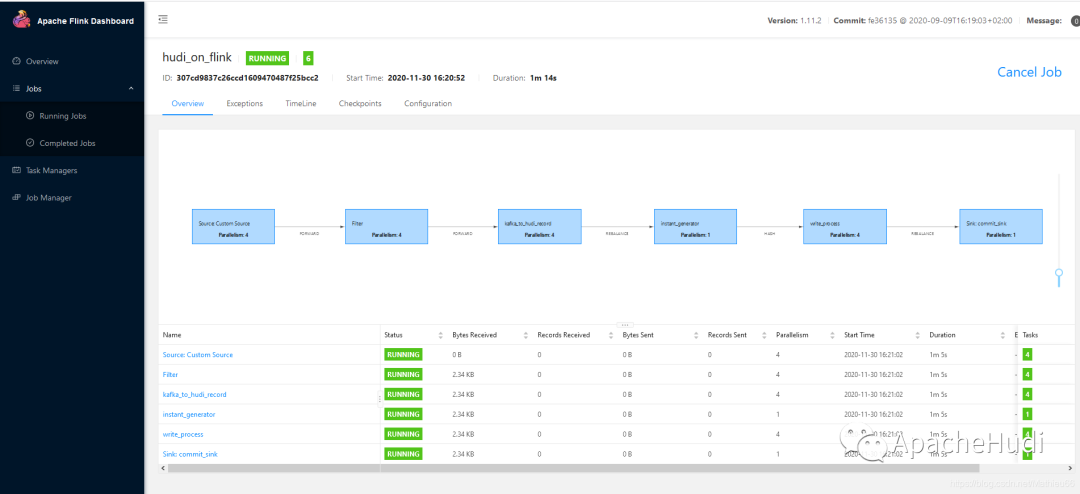
查看监控页面,任务已经跑起来了
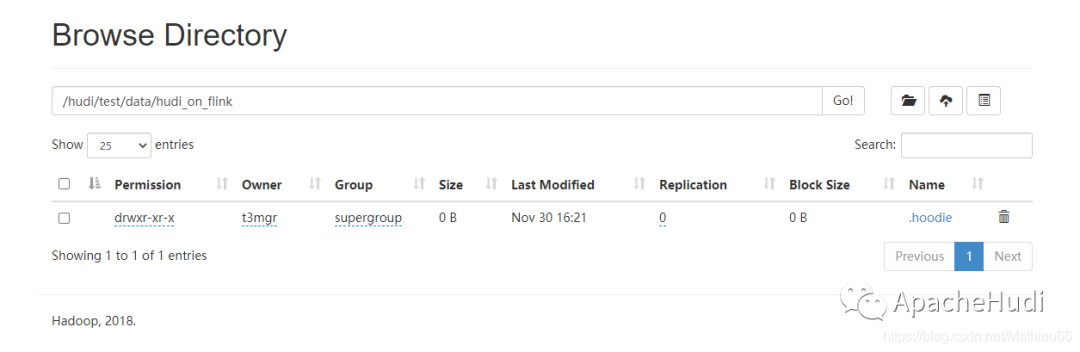
现在在Hdfs路径下已经创建了一个空表(Hudi自动创建)
我们向 topic 中发数据(发了 900 条,本地写的 Producer 就不贴代码了)

我们查一下结果:
@Test public void query() { spark.read().format("hudi") .load(basePath + "/*/*/*/*") .createOrReplaceTempView("tmp_view"); spark.sql("select * from tmp_view limit 2").show(); spark.sql("select count(1) from tmp_view").show(); }
+-------------------+--------------------+--------------------+----------------------+--------------------+--------------------+-------------+--------------------+----+-----+-------------------+------------------+------+------------------+-------------------+---+|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| uuid| ts| symbol|year|month| high| low| key| close| open|day|+-------------------+--------------------+--------------------+----------------------+--------------------+--------------------+-------------+--------------------+----+-----+-------------------+------------------+------+------------------+-------------------+---+| 20201130162542| 20201130162542_0_20|01e11b9c-012a-461...| 2020/10/29|c8f3a30a-0523-4c8...|01e11b9c-012a-461...|1603947341061|12a-4614-89c3-f62...| 120| 10|0.45757580489415417|0.0816472025173598|01e11b|0.5795817262998396|0.15864898816336837| 1|| 20201130162542| 20201130162542_0_21|22e96b41-344a-4be...| 2020/10/29|c8f3a30a-0523-4c8...|22e96b41-344a-4be...|1603921161580|44a-4be2-8454-832...| 120| 10| 0.6200960168557579| 0.946080636091312|22e96b|0.6138608980526853| 0.5445994550724997| 1|+-------------------+--------------------+--------------------+----------------------+--------------------+--------------------+-------------+--------------------+----+-----+-------------------+------------------+------+------------------+-------------------+---+
+--------+|count(1)|+--------+| 900|+--------+
5. 总结
本文简要介绍了使用 Flink 引擎将数据写出到Hudi表的过程。主要包括自主打可执行jar、启动参数介绍、Schema配置、Hudi任务参数配置等步骤
