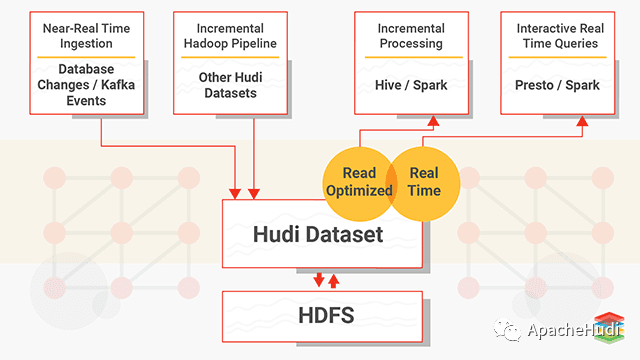
1. 什么是Hudi?
Apache Hudi代表Hadoop Upserts anD Incrementals,管理大型分析数据集在HDFS上的存储。Hudi的主要目的是高效减少摄取过程中的数据延迟。由Uber开发并开源,HDFS上的分析数据集通过两种类型的表提供服务:读优化表(Read Optimized Table)和近实时表(Near-Real-Time Table)。
读优化表的主要目的是通过列式存储提供查询性能,而近实时表则提供实时(基于行的存储和列式存储的组合)查询。
Hudi是一个开源Spark库,用于在Hadoop上执行诸如更新,插入和删除之类的操作。它还允许用户仅摄取更改的数据,从而提高查询效率。它可以像任何作业一样进一步水平扩展,并将数据集直接存储在HDFS上。
2. Hudi如何工作?
Hudi针对HDFS上的数据集提供以下原语
- 插入更新(upsert)
- 增量消费
Hudi维护在数据集上执行的所有操作的时间轴(timeline),以提供数据集的即时视图。Hudi将数据集组织到与Hive表非常相似的基本路径下的目录结构中。数据集分为多个分区,文件夹包含该分区的文件。每个分区均由相对于基本路径的分区路径唯一标识。
分区记录会被分配到多个文件。每个文件都有一个唯一的文件ID和生成该文件的提交(commit)。如果有更新,则多个文件共享相同的文件ID,但写入时的提交(commit)不同。
存储类型–处理数据的存储方式
- 写时复制
- 纯列式
- 创建新版本的文件
- 读时合并
- 近实时
视图–处理数据的读取方式
读取优化视图-输入格式仅选择压缩的列式文件
- parquet文件查询性能
- 500 GB的延迟时间约为30分钟
- 导入现有的Hive表
近实时视图
- 混合、格式化数据
- 约1-5分钟的延迟
- 提供近实时表
增量视图
- 数据集的变更
- 启用增量拉取
Hudi存储层由三个不同的部分组成
元数据–它以时间轴的形式维护了在数据集上执行的所有操作的元数据,该时间轴允许将数据集的即时视图存储在基本路径的元数据目录下。时间轴上的操作类型包括
- 提交(commit),一次提交表示将一批记录原子写入数据集中的过程。单调递增的时间戳,提交表示写操作的开始。
- 清理(clean),清理数据集中不再被查询中使用的文件的较旧版本。
- 压缩(compaction),将行式文件转化为列式文件的动作。
- 索引,将传入的记录键快速映射到文件(如果已存在记录键)。索引实现是可插拔的,Bloom过滤器-由于不依赖任何外部系统,因此它是默认配置,索引和数据始终保持一致。Apache HBase-对少量key更高效。在索引标记过程中可能会节省几秒钟。
- 数据,Hudi以两种不同的存储格式存储数据。实际使用的格式是可插入的,但要求具有以下特征–读优化的列存储格式(ROFormat),默认值为Apache Parquet;写优化的基于行的存储格式(WOFormat),默认值为Apache Avro。
3. 为什么Hudi对于大规模和近实时应用很重要?
Hudi解决了以下限制
- HDFS的可伸缩性限制
- 需要在Hadoop中更快地呈现数据
- 没有直接支持对现有数据的更新和删除
- 快速的ETL和建模
- 要检索所有更新的记录,无论这些更新是添加到最近日期分区的新记录还是对旧数据的更新,Hudi都允许用户使用最后一个检查点时间戳。此过程不用执行扫描整个源表的查询
4. 如何使用Apache Spark将Hudi用于数据管道?
4.1 下载Hudi
$ mvn clean install -DskipTests -DskipITs$ mvn clean install -DskipTests -DskipITs -Dhive11
4.2 版本兼容性
Hudi需要安装Java 8,适用于Spark-2.x版本。
| Hadoop | Hive | Spark | 构建命令 |
| Apache Hadoop-2.8.4 | Apache Hive-2.3.3 | spark-2.[1-3].x | mvn clean install -DskipTests |
| Apache Hadoop-2.7.3 | Apache Hive-1.2.1 | spark-2.[1-3].x | mvn clean install -DskipTests |
4.3 生成Hudi数据集
设置环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre/ export HIVE_HOME=/var/hadoop/setup/apache-hive-1.1.0-cdh5.7.2-bin export HADOOP_HOME=/var/hadoop/setup/hadoop-2.6.0-cdh5.7.2 export HADOOP_INSTALL=/var/hadoop/setup/hadoop-2.6.0-cdh5.7.2 export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop export SPARK_HOME=/var/hadoop/setup/spark-2.3.1-bin-hadoop2.7 export SPARK_INSTALL=$SPARK_HOME export SPARK_CONF_DIR=$SPARK_HOME/conf export PATH=$JAVA_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$SPARK_INSTALL/bin:$PATH
4.4 Api支持
使用DataSource API,只需几行代码即可快速开始读取或写入Hudi数据集及使用RDD API操作Hudi数据集。
5. Hudi最佳实践
使用一种新的HoodieRecordPayload类型,并保留以前的持久类型作为CombineAndGetUpdateValue(...)的输出。否则前一次提交的提交时间一直更新到最新,会使得下游增量ETL将此记录计数两次。
左连接(left join)包含所有通过键保留的数据的数据框(data frame),并插入persisted_data.key为空的记录。但不确定是否充分利用了BloomIndex/metadata。
添加一个新的标志字段至从HoodieRecordPayload元数据读取的HoodieRecord中,以表明在写入过程中是否需要复制旧记录。
在数据框(data frame)选项中传递一个标志位以强制整个作业会复制旧记录。
6. Hudi的优势
- HDFS中的可伸缩性限制。
- Hadoop中数据的快速呈现
- 支持对于现有数据的更新和删除
- 快速的ETL和建模
7. Apache Hudi与Apache Kudu的比较
Apache Kudu与Hudi非常相似;Apache Kudu用于对PB级数据进行实时分析,也支持插入更新。
Apache Kudu和Hudi之间的主要区别在于Kudu试图充当OLTP(在线事务处理)工作负载的数据存储,而Hudi却不支持,它仅支持OLAP(在线分析处理)。
Apache Kudu不支持增量拉取,但Hudi支持增量拉取。
还有其他主要的主要区别,Hudi完全基于Hadoop兼容的文件系统,例如HDFS,S3或Ceph,而Hudi也没有自己的存储服务器,Apache Kudu的存储服务器通过RAFT进行相互通信。
对于繁重的工作流,Hudi依赖于Apache Spark,因此可以像其他Spark作业一样轻松地扩展Hudi。
8. Hudi总结
Hudi填补了在HDFS上处理数据的巨大空白,因此可以与一些大数据技术很好地共存。Hudi最好用于在HDFS之上对parquet格式数据执行插入/更新操作。
