二 、多端部署-以ChatGLM3+个人Mac电脑为例
魔搭社区和Xinference合作, 提供了模型GGML的部署方式, 以ChatGLM3为例。
Xinference支持大语言模型, 语音识别模型, 多模态模型的部署, 简化了部署流程, 通过一行命令完 成模型的部署工作 。并支持众多前沿的大语言模型, 结合GGML技术, 支持多端部署 。Xinference的 合作文章具体可以参考这篇文章《之前那篇微信公众号》
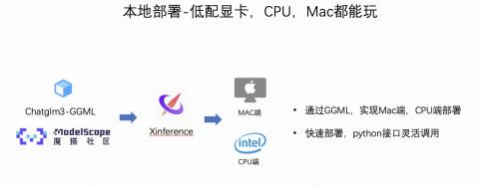
ChatGLM3使用的模型为GGML格式, 模型链接:
https://modelscope.cn/models/Xorbits/chatglm3-ggml/summary
使用方式:
首先在mac上预装Xinference:

pip install x inference[ggml]>=0.4.3
然后本地开启Xinference的实例:
x inference -p 9997
运行如下Python代码, 验证模型推理效果
from xinference.client import Client client = Client(“http://localhost:9997”) model_u id = client.launch_model( model_name=“chatglm3”, model_format=“ggmlv3”, model_size_in_billions=6, quantization=“q4_0”, ) model = client.get_model(model_u id) chat_history = [] prompt = "最大的动物是什么? " model.chat( prompt, chat_history, generate_config={“max_tokens”: 1024} )
以ChatGLM3为例, 在个人Mac电脑上load模型到完成推理验证, 仅需要10s:
Mac电脑配置:

推理示例:

三 、定制化模型部署 - 微调后命令行部署
结合魔搭微调框架swift, 可以实现定制化模型部署。
目前swift支持VLLM框架, chatglm.cpp ,Xinference等推理框架, 具体可以参考文档:
https://github.com/modelscope/swift/blob/main/docs/source/GetStarted/Deployment.md
本文以ChatGLM3模型+chatglm.cpp为例:
该推理优化框架支持:
ChatGLM系列模型
BaiChuan系列模型
CodeGeeX系列模型
chatglm.cpp的github地址是:https://github.com/li-plus/chatglm.cpp
首先初始化对应repo:
git clone --recursive https://g it hub.com/li-plus/chatglm.cpp.g it && cd chatglm.cpp python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece cmake -B build cmake --build build -j --config Release
如果SWIFT训练的是LoRA模型, 需要将LoRA weights合并到原始模型中去:
# 先将文件夹cd到swift根目录中 python tools/merge_lora_weights_to_model.py --model_id_or_path /dir/to/your/base/model --model_revision master --ck pt_dir /dir/to/your/lora/model 合并后的模型会输出到 {ckpt_dir}-merged 文件夹中。 之后将上述合并后的 {ckpt_dir}-merged 的模型weights转为cpp支持的bin文件: # 先将文件夹cd到chatglm.cpp根目录中 python3 chatglm_cpp/convert.py -i {ck pt_dir}-merged -t q4_0 -o chatglm-ggml.bin chatglm.cpp支持以各种精度转换模型 ,详情请参考: https://github.com/li- plus/chatglm.cpp#getting-started
之后就可以拉起模型推理:
./build/bin/main -m chatglm-ggml.bin -i # 以下对话为使用agent数据集训练后的效果 # Prompt > how are you? # ChatGLM3 > < |startofthink|>```JSON # {“api_name”: “greeting”, “apimongo_instance”: "ddb1e34-0406-42a3- a547a220a2", “parameters”: {“text”: “how are # you?”}}} # ```< |endofthink|> # # I 'm an AI assistant and I can only respond to text input. I don 't have the ability to respond to audio or # video input.
之后启动xinference:
x inference -p 9997
在浏览器界面上选择Register Model选项卡, 添加chatglm.cpp章节中转换成功的ggml模 型:
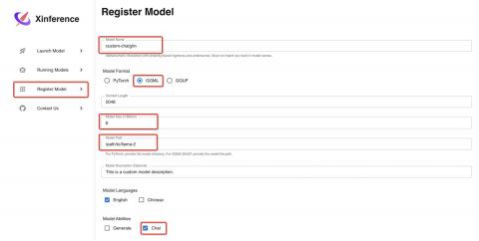
注意:
● 模型能力选择Chat
之后再Launch Model中搜索刚刚创建的模型名称, 点击火箭标识运行即可使用。
调用可以使用如下代码:
from xinference.client import Client client = Client(“http://localhost:9997”) model_u id = client.launch_model(model_name=“custom-chatglm”) model = client.get_model(model_u id) chat_history = [] prompt = “What is the largest animal?” model.chat( prompt, chat_history, generate_config={“max_tokens”: 1024} ) # { 'id ': 'chatcmpl-df3c2c28-f8bc-4e79-9c99-2ae3950fd459 ', 'object ': 'chat.completion ', 'created ': 1699367362, 'model ': '021c2b74-7d7a-11ee-b1aa- ead073d837c1 ', 'choices ': [{ 'index ': 0, 'message ': { 'role ': 'assistant ', 'content ': "According to records kept by the Guinness World Records, the largest animal in the world is the Blue Whale, specifically, the Right and Left Whales, which were both caught off the coast of Newfoundland. The two whales measured a length of 105.63 meters, or approximately 346 feet long, and had a corresponding body weight of 203,980 pounds, or approximately 101 tons. It 's important to note that this was an extremely rare event and the whales that size don 't commonly occur."}, 'finish_reason ': None}], 'usage ': { 'prompt_tokens ': -1, 'completion_tokens ': -1, 'total_tokens ': -1}}


![NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]](https://ucc.alicdn.com/fnj5anauszhew_20240410_230ba39d3fa54e0cac91da7f7a3e06b5.jpeg?x-oss-process=image/resize,h_160,m_lfit)