导读
9月25日,阿里云开源通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,免费可商用。Qwen-14B在多个权威评测中超越同等规模模型,部分指标甚至接近Llama2-70B。阿里云此前开源的70亿参数模型Qwen-7B等,一个多月下载量破100万,成为开源社区的口碑之作。
Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推理、认知、规划和记忆能力。
Qwen-14B-Chat 是在基座模型上经过精细SFT得到的对话模型。借助基座模型强大性能,Qwen-14B-Chat生成内容的准确度大幅提升,也更符合人类偏好,内容创作上的想象力和丰富度也有显著扩展。
用户可从魔搭社区直接下载模型,也可通过阿里云灵积平台访问和调用Qwen-14B和Qwen-14B-Chat。阿里云为用户提供包括模型训练、推理、部署、精调等在内的全方位服务,以下是魔搭的最佳实践。
环境配置与安装
- python 3.8及以上版本
- pytorch 1.12及以上版本,推荐2.0及以上版本
- 建议使用CUDA 11.4及以上(GPU用户需考虑此选项)
使用步骤
本文在PAI-DSW的环境配置下运行 (可单卡运行, 显存最低要求11G)
创空间体验
模型零代码创空间体验地址:
https://modelscope.cn/studios/qwen/Qwen-14B-Chat-Demo
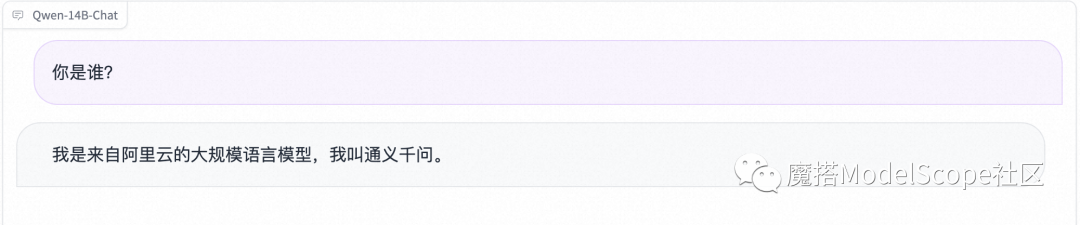
效果展示:
- 国际惯例自我认知
- 写作创作

- 知识常识

- 数学

- 代码

- 安全

模型链接和下载Qwen-14B系列模型现已在ModelScope社区开源,包括:
Qwen-14B-Chat
模型链接:https://modelscope.cn/models/qwen/Qwen-14B-Chat
Qwen-14B
模型链接:https://modelscope.cn/models/qwen/Qwen-14B
Qwen-14B-Chat-Int4
模型链接:https://www.modelscope.cn/models/qwen/Qwen-14B-Chat-Int4
社区支持直接下载模型的repo:
from modelscope.hub.snapshot_download import snapshot_download model_dir = snapshot_download('qwen/Qwen-14B-Chat', 'v1.0.0')
模型推理
依赖项:
Qwen-14B-Chat-Int4依赖项:
pip install "modelscope>=1.9.1" auto-gptq optimum
Qwen-14B-Chat和Qwen-14B依赖项:
pip install "modelscope>=1.9.1"
推理代码:
Qwen-14B-Chat-Int4可在魔搭社区免费GPU算力(单卡A10)运行:
from modelscope import AutoTokenizer, AutoModelForCausalLM, snapshot_download model_dir = snapshot_download("qwen/Qwen-14B-Chat-Int4",revision = 'v1.0.0') # Note: The default behavior now has injection attack prevention off. tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( model_dir, device_map="auto", trust_remote_code=True ).eval() response, history = model.chat(tokenizer, "你好", history=None) print(response) # 你好!很高兴为你提供帮助。
资源消耗:

Qwen-14B-Chat模型推理代码
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download from modelscope import GenerationConfig model_dir = snapshot_download('qwen/Qwen-14B-Chat', revision='v1.0.0') # Note: The default behavior now has injection attack prevention off. tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True) # use bf16 # model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval() # use cpu only # model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval() # use auto mode, automatically select precision based on the device. model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval() # Specify hyperparameters for generation model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参 # 第一轮对话 1st dialogue turn response, history = model.chat(tokenizer, "你好", history=None) print(response) # 你好!很高兴为你提供帮助。 # 第二轮对话 2nd dialogue turn response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history) print(response) # 这是一个关于一个年轻人奋斗创业最终取得成功的故事。 # 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。 # 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。 # 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。 # 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。 # 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。 # 第三轮对话 3rd dialogue turn response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history) print(response) # 《奋斗创业:一个年轻人的成功之路》
资源消耗

模型微调和微调后推理
微调代码开源地址:
clone swift仓库并安装swift
git clone https://github.com/modelscope/swift.git cd swift pip install . cd examples/pytorch/llm
单卡A10 QLoRA微调案例
模型微调脚本 (qlora)
# Experimental environment: A10 # 17GB GPU memory CUDA_VISIBLE_DEVICES=0 \ python src/llm_sft.py \ --model_type qwen-14b \ --sft_type lora \ --template_type default-generation \ --dtype bf16 \ --output_dir output \ --dataset dureader-robust-zh \ --train_dataset_sample -1 \ --num_train_epochs 1 \ --max_length 2048 \ --quantization_bit 4 \ --bnb_4bit_comp_dtype bf16 \ --lora_rank 8 \ --lora_alpha 32 \ --lora_dropout_p 0. \ --lora_target_modules ALL \ --gradient_checkpointing true \ --batch_size 1 \ --weight_decay 0. \ --learning_rate 1e-4 \ --gradient_accumulation_steps 16 \ --max_grad_norm 0.5 \ --warmup_ratio 0.03 \ --eval_steps 100 \ --save_steps 100 \ --save_total_limit 2 \ --logging_steps 10 \ --use_flash_attn false \ --push_to_hub false \ --hub_model_id qwen-14b-qlora \ --hub_private_repo true \ --hub_token 'your-sdk-token' \
模型微调后的推理脚本
# If you want to merge LoRA weight and save it, you need to set `--merge_lora_and_save true`. CUDA_VISIBLE_DEVICES=0 \ python src/llm_infer.py \ --model_type qwen-14b \ --sft_type lora \ --template_type default-generation \ --dtype bf16 \ --ckpt_dir "output/qwen-14b/vx_xxx/checkpoint-xxx" \ --eval_human false \ --dataset dureader-robust-zh \ --max_length 2048 \ --quantization_bit 4 \ --bnb_4bit_comp_dtype bf16 \ --use_flash_attn false \ --max_new_tokens 1024 \ --temperature 0.9 \ --top_k 20 \ --top_p 0.9 \ --do_sample true \ --merge_lora_and_save false \
微调的可视化结果
训练损失:

资源消耗:
Qwen-14B使用 qlora 的方式训练的显存占用如下,大约在17G. (quantization_bit=4, batch_size=1, max_length=1024)
双卡A100 LoRA微调案例:
模型微调脚本 (lora+ddp)
# Experimental environment: 2 * A100 # 2 * 55GB GPU memory nproc_per_node=2 CUDA_VISIBLE_DEVICES=0,1 \ torchrun \ --nproc_per_node=$nproc_per_node \ --master_port 29500 \ src/llm_sft.py \ --model_type qwen-14b-chat \ --sft_type lora \ --template_type chatml \ --dtype bf16 \ --output_dir output \ --dataset damo-agent-mini-zh \ --train_dataset_sample 20000 \ --num_train_epochs 1 \ --max_length 4096 \ --lora_rank 8 \ --lora_alpha 32 \ --lora_dropout_p 0. \ --lora_target_modules ALL \ --gradient_checkpointing true \ --batch_size 1 \ --weight_decay 0. \ --learning_rate 1e-4 \ --gradient_accumulation_steps $(expr 32 / $nproc_per_node) \ --max_grad_norm 0.5 \ --warmup_ratio 0.03 \ --eval_steps 100 \ --save_steps 100 \ --save_total_limit 2 \ --logging_steps 10 \ --use_flash_attn true \ --push_to_hub false \ --hub_model_id qwen-14b-chat-qlora \ --hub_private_repo true \ --hub_token 'your-sdk-token' \
模型微调后的推理脚本
# If you want to merge LoRA weight and save it, you need to set `--merge_lora_and_save true`. CUDA_VISIBLE_DEVICES=0 \ python src/llm_infer.py \ --model_type qwen-14b-chat \ --sft_type lora \ --template_type chatml \ --dtype bf16 \ --ckpt_dir "output/qwen-14b-chat/vx_xxx/checkpoint-xxx" \ --eval_human false \ --dataset damo-agent-mini-zh \ --max_length 4096 \ --use_flash_attn true \ --max_new_tokens 2048 \ --temperature 0.9 \ --top_k 20 \ --top_p 0.9 \ --do_sample true \ --merge_lora_and_save false \
微调的可视化结果:
训练损失

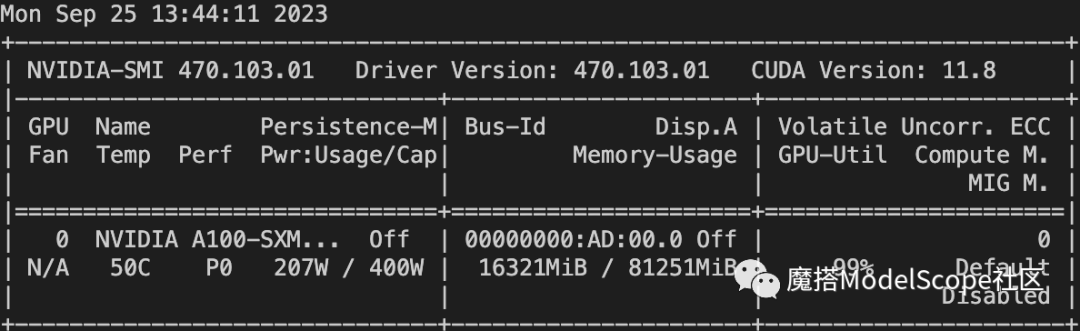
资源消耗:
Qwen-14B-Chat使用 lora+ddp 的方式训练的显存占用如下,大约在55G. (quantization_bit=4, batch_size=1, max_length=4096)

最后,欢迎关注通义千问开源的开发者小伙伴们入群沟通交流~

点击阅读原文,直达创空间体验
https://modelscope.cn/studios/qwen/Qwen-14B-Chat-Demo/summary