2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
我们今天来总结一下2024年3月上半月份发表的最重要的论文,无论您是研究人员、从业者还是爱好者,本文都将提供有关计算机视觉中最先进的技术和工具重要信息。
Diffusion Models
1. OOTDiffusion: Outfitting Fusion-based Latent Diffusion for Controllable Virtual Try-on
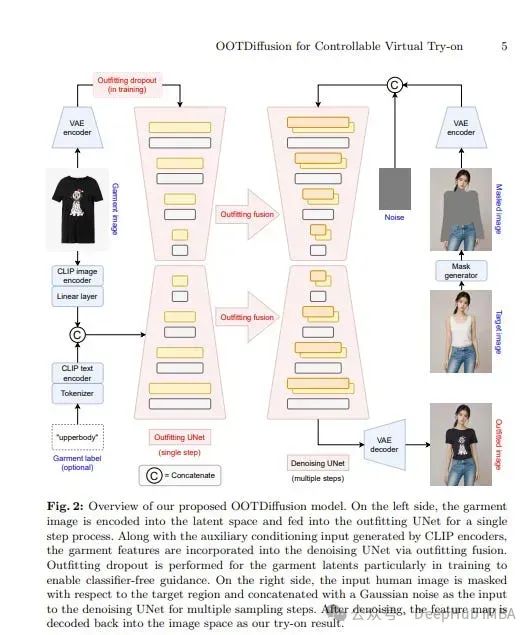
Outfitting over Try-on Diffusion (OOTDiffusion),利用预训练的潜在扩散模型的力量,设计了一种新颖的网络架构,可以现实和可控的虚拟试穿。论文提出了一个outfitting UNet来学习服装细节特征,并通过扩散模型去噪过程中的outfitting融合将其与目标人体融合。
在训练过程中引入了服装dropout,能够通过无分类器的指导来调整服装特征的强度。在VITON-HD和Dress Code数据集上的综合实验表明,OOTDiffusion可以有效地为任意人体和服装图像生成高质量的服装图像,
https://arxiv.org/abs/2403.01779
2、ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models
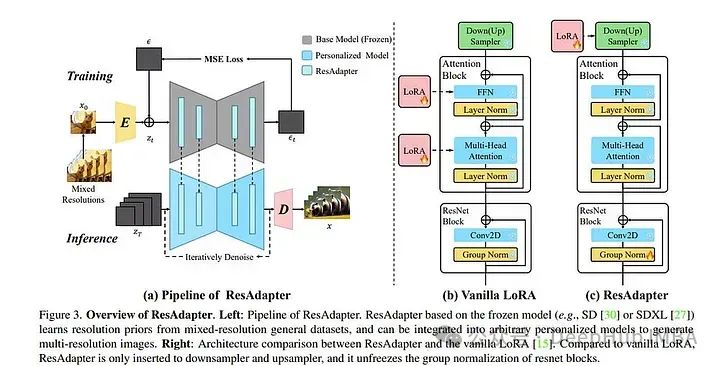
文本到图像模型(如Stable Diffusion)和相应的个性化技术(如DreamBooth和LoRA)的最新进展使个人能够生成高质量和富有想象力的图像。但是当生成分辨率超出其训练域的图像时,它们经常受到限制。
论文提出了分辨率适配器(ResAdapter),用于生成具有不受限制的分辨率和宽高比的图像。与其他多分辨率生成方法不同的是,ResAdapter直接生成动态分辨率的图像,而其他静态分辨率的图像需要进行复杂的后处理操作。
在学习了对纯分辨率先验的深入理解之后,ResAdapter在通用数据集上进行训练,生成具有个性化扩散模型的无分辨率图像,同时保留其原始风格域。
实验表明,仅0.5M的ResAdapter就可以处理任意扩散模型下灵活分辨率的图像。更多的扩展实验表明,ResAdapter与其他模块(例如,ControlNet, IP-Adapter和LCM-LoRA)兼容,可以在广泛的分辨率范围内生成图像,并且可以集成到另一个多分辨率模型(例如,ElasticDiffusion)中,以有效地生成更高分辨率的图像。
https://arxiv.org/abs/2403.02084
3. PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation

论文介绍了PixArt- \Sigma,一个能够直接生成4K分辨率图像的扩散变压器模型(DiT)。
PixArt- \Sigma的一个关键特点是它的训练效率。利用PixArt- \alpha的基础预训练,它通过合并更高质量的数据,从“较弱”的基线发展到“更强”的模型,我们称之为“弱到强的训练”的过程。
https://arxiv.org/abs/2403.04692
4、Pix2Gif: Motion-Guided Diffusion for GIF Generation

Pix2Gif是一个用于图像到gif(视频)生成的运动引导扩散模型。论文中将任务表述为由文本和运动幅度提示引导的图像翻译问题。
为了保证模型遵循运动引导,提出了一种新的运动引导扭曲模块,以两种类型的提示为条件对源图像的特征进行空间变换。此外论文还增加了感知损失,确保转换后的特征映射与目标图像保持在相同的空间内,确保内容的一致性和连贯性。
对于训练资源使用16x100个gpu的单个节点来训练所有模型,这应该算是比较少的资源消耗了。
https://arxiv.org/abs/2403.04634
视觉语言模型
1、Enhancing Vision-Language Pre-training with Rich Supervisions
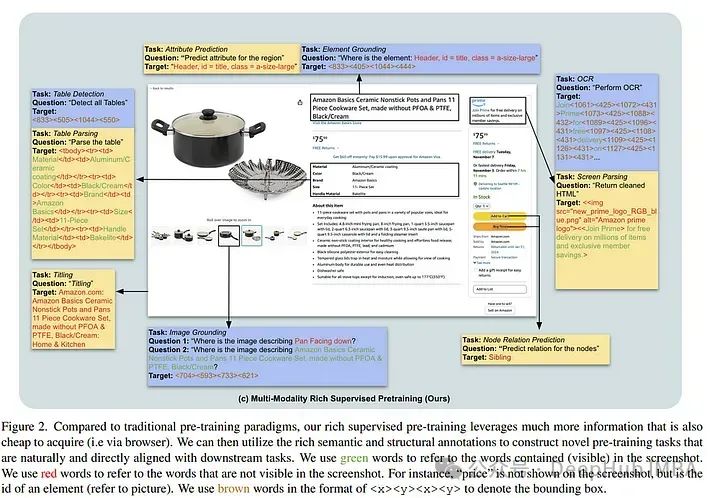
lunwen 提出使用屏幕截图进行强监督预训练(S4)范例。使用网络截图利用HTML元素固有的树状结构层次结构和空间定位来精心设计10个带有大规模注释数据的预训练任务。
这些任务类似于跨不同领域的下游任务,并且获得注释的成本很低。与当前的截图预训练目标相比,论文创新的预训练方法显着提高了图像到文本模型在九个不同和流行的下游任务中的性能——在表格检测方面提高了76.1%,在Widget字体方面提高了至少1%。
https://arxiv.org/abs/2403.03346
图像生成和编辑
1、RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization
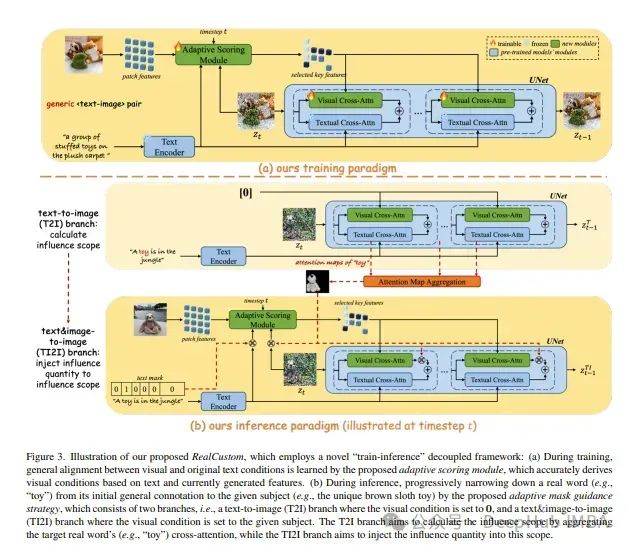
文本到图像自定义旨在为给定主题合成文本驱动的图像,论文提出的RealCustom首次通过精确地将主题影响限制在相关部分,从而将相似性与可控性分开,通过逐渐将真实文本单词从其一般内容缩小到特定主题,并使用交叉注意力来区分相关性来实现。
RealCustom引入了一种新颖的“训练-推理”解耦框架:(1)在训练过程中,RealCustom通过一种新颖的自适应评分模块来学习视觉条件与原始文本条件之间的一般一致性,可以自适应调节影响量;(2)在推理过程中,提出了一种新的自适应掩码引导策略,迭代更新给定主题的影响范围和影响量,逐步缩小真实文本词的生成范围。
综合实验证明了RealCustom在开放领域具有优越的实时定制能力,首次实现了给定主题前所未有的相似性和给定文本的可控性。
https://arxiv.org/abs/2403.00483
2、 StableDrag: Stable Dragging for Point-based Image Editing

自DragGAN出现以来,基于点的图像编辑引起了人们的极大关注。DragDiffusion将这种拖拽技术应用于扩散模型,进一步提高了生成质量。
DragDiffusion允许精确定位更新的点,从而提高稳定性。论文实例化了两种类型的图像编辑模型,包括StableDrag-GAN和StableDrag-Diff,它们通过在DragBench上进行广泛的定性实验和定量评估,获得了更稳定的拖动性能。
https://arxiv.org/abs/2403.04437
视频生成和编辑
1、AtomoVideo: High-Fidelity Image-to-Video Generation

基于先进的文本到图像生成技术,视频生成取得了长足的发展。论文提出了一个用于图像到视频生成的高保真框架,名为AtomoVideo。
基于多粒度图像注入,实现了生成的视频对给定图像的高保真度。由于高质量的数据集和训练策略,实现了更大的运动强度,同时保持了优越的时间一致性和稳定性。
https://arxiv.org/abs/2403.01800
2、MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
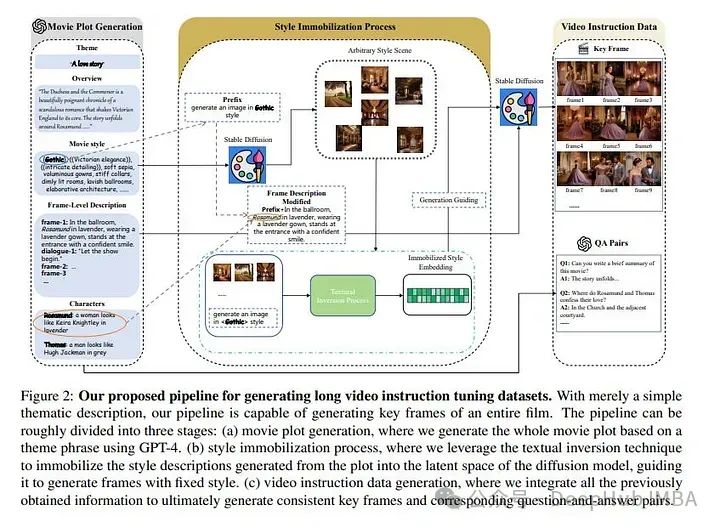
多模态模型的发展标志着机器在理解视频方面迈出了重要的一步。这些模型在分析短视频片段方面显示出了前景。但是当涉及到像电影这样的较长格式时,它们往往会有所不足。
主要的障碍是缺乏高质量、多样化的视频数据,以及需要大量的工作来收集或注释这些数据。面对这些挑战,论文提出了MovieLLM可以为长视频创建合成的高质量数据。
该框架利用GPT-4和文本到图像模型的功能来生成详细的脚本和相应的视觉效果。方法因其灵活性和可扩展性而脱颖而出,使其成为传统数据收集方法的卓越替代方案。
大量实验验证了MovieLLM产生的数据显著提高了多模态模型在理解复杂视频叙事方面的性能,克服了现有数据集在稀缺性和偏见方面的局限性。
https://arxiv.org/abs/2403.02827
图像识别
1、 VisionLLaMA: A Unified LLaMA Interface for Vision Tasks

大型语言模型构建在基于transformer的体系结构之上,LLaMA在许多开源实现中脱颖而出。同样的transformer可以用来处理2D图像吗?
论文展示了一种类似于llama的视觉transformer来回答这个问题,该transformer具有平面和金字塔形式,称为VisionLLaMA。VisionLLaMA是一个统一的通用建模框架,用于解决大多数视觉任务。使用典型的预训练范式在图像感知的大部分下游任务中广泛评估其有效性,特别是图像生成。
在许多情况下,VisionLLaMA比以前的最先进的VIT表现出了实质性的进步。我们相信VisionLLaMA可以作为视觉生成和理解的一个强大的新基线模型。
https://arxiv.org/abs/2403.00522
2、How Far Are We from Intelligent Visual Deductive Reasoning?
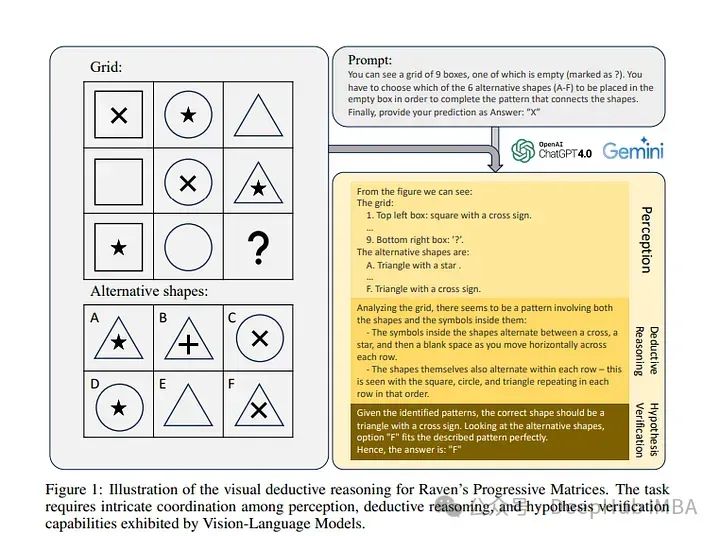
像GPT-4V这样的视觉语言模型(vlm)最近在各种视觉语言任务上取得了令人难以置信的进步。论文深入研究了基于视觉的演绎推理,这是一个更复杂但较少探索的领域,并在当前的SOTA VLMs中发现了以前未暴露的盲点。
利用Raven ' s Progressive Matrices (rpm)来评估vlm仅依靠视觉线索执行多跳关系推理和演绎推理的能力。在三个不同的数据集(包括Mensa IQ测试、IntelligenceTest和RAVEN)上使用标准策略,如上下文学习、自我一致性和思维链(CoT),对几种流行的vlm进行了全面的评估。
结果表明,尽管LLM在基于文本的推理方面的能力令人印象深刻,但在视觉演绎推理方面仍远未达到相当的熟练程度。某些适用于LLM的有效标准策略并不能无缝地转化为视觉推理任务所带来的挑战。
https://arxiv.org/abs/2403.04732
https://avoid.overfit.cn/post/3c01305dabf4473ca29bfea2e74f3473
作者:Eslam Mohamed Fouad Salah Jabr
