 算精通
算精通
算精通_个人页
算精通




文章
1192
问答
16375
视频
0
个人介绍
北京阿里云ACE会长
擅长的技术
- Java
- C++
- C语言
- Python
- Shell
- Go
- Kotlin
- iOS开发
- Android开发
- 设计模式

暂无更多信息
2024年05月
-
05.09 07:42:52
 回答了问题
2024-05-09 07:42:52
回答了问题
2024-05-09 07:42:52
-
05.09 07:42:50回答了问题
2024-05-09 07:42:50
rocketmq默认情况下消费者不会从slave节点拉取消息消费吗?
赞1 踩0 评论0 -
05.09 07:41:43回答了问题
2024-05-09 07:41:43
-
05.09 07:40:53回答了问题
2024-05-09 07:40:53
RocketMQ遇到过好几次Message-Id 长度不同,是啥原因呢?
赞0 踩0 评论0 -
05.09 07:40:24回答了问题
2024-05-09 07:40:24
-
05.09 07:37:23
 发表了文章
2024-05-09 07:37:23
发表了文章
2024-05-09 07:37:23
mysqldump
mysqldumpmysqldump -
05.09 07:35:42发表了文章
2024-05-09 07:35:42
synchronized
synchronized -
05.09 07:34:58发表了文章
2024-05-09 07:34:58
ReentrantLock
ReentrantLock -
05.08 11:12:30回答了问题
2024-05-08 11:12:30
-
05.08 11:11:46回答了问题
2024-05-08 11:11:46
宜搭提交流程之后流程上的数据被删除
赞2 踩0 评论0 -
05.08 11:10:49回答了问题
2024-05-08 11:10:49
-
05.08 11:07:28发表了文章
2024-05-08 11:07:28
FIFO
FIFO -
05.08 11:05:27发表了文章
2024-05-08 11:05:27
ChangeMessageVisibility
ChangeMessageVisibility -
05.08 11:03:49发表了文章
2024-05-08 11:03:49
Message Service
Message Service -
05.07 08:18:29回答了问题
2024-05-07 08:18:29
AI面试成为线下面试的“隐形门槛”,对此你怎么看?
赞3 踩0 评论0 -
05.07 08:15:05回答了问题
2024-05-07 08:15:05
如何从零构建一个现代深度学习框架?
赞1 踩0 评论0 -
05.07 08:12:32回答了问题
2024-05-07 08:12:32
OceanBase数据库两者高并发时响应时长是否都一致 。ap和lp时哪个更好?
赞0 踩0 评论0 -
05.07 08:12:29回答了问题
2024-05-07 08:12:29
OceanBase数据库这个性能瓶颈在当前最新版本 4.2.2 还存在吗 ?
赞0 踩0 评论0 -
05.07 08:11:06回答了问题
2024-05-07 08:11:06
OceanBase数据库意思是不路由到 备副本 ,都默认路由到 主 副本 吗?
赞0 踩0 评论0 -
05.07 08:10:38回答了问题
2024-05-07 08:10:38
-
05.07 08:09:51回答了问题
2024-05-07 08:09:51
OceanBase数据库mysql_version能调整吗?
赞0 踩0 评论0 -
05.07 07:51:25发表了文章
2024-05-07 07:51:25
in
in -
05.07 07:50:55发表了文章
2024-05-07 07:50:55
Flow
Flow -
05.07 07:49:30发表了文章
2024-05-07 07:49:30
索引
索引 -
05.06 07:38:18回答了问题
2024-05-06 07:38:18
EMAS移动推送Android集成时报错compile not found
赞0 踩0 评论0 -
05.06 07:37:16回答了问题
2024-05-06 07:37:16
-
05.06 07:36:35回答了问题
2024-05-06 07:36:35
DataWorks已经切换,但是提交任务会出现这个提示,不让提交怎么办?
赞0 踩0 评论0 -
05.06 07:36:02回答了问题
2024-05-06 07:36:02
DataWorks离线同步的组件是dataX怎么办?
赞2 踩0 评论0 -
05.06 07:33:52发表了文章
2024-05-06 07:33:52
RXTX
RXTX -
05.06 07:33:14发表了文章
2024-05-06 07:33:14
Performance Optimization
Performance Optimization -
05.06 07:31:51发表了文章
2024-05-06 07:31:51
:掌握移动端开发:HTML5 与 CSS3 的高效实践
:掌握移动端开发:HTML5 与 CSS3 的高效实践 -
05.05 08:34:10回答了问题
2024-05-05 08:34:10
代码优化建议的功能无法替入代码
赞0 踩0 评论0 -
05.05 08:34:08回答了问题
2024-05-05 08:34:08
我付了两次费用你为什么只产生一次
赞2 踩0 评论0 -
05.05 08:32:58回答了问题
2024-05-05 08:32:58
AI Earth出现这种情况是什么原因?
赞1 踩0 评论0 -
05.05 08:32:15回答了问题
2024-05-05 08:32:15
AUI有没有比如阿里向我们服务器发送事件通知回调。告知主播关闭了直播等?
赞0 踩0 评论0 -
05.05 08:31:38回答了问题
2024-05-05 08:31:38
我有时候在家里登陆不了AI Earth,是为什么啊?
赞2 踩0 评论0 -
05.05 08:28:11发表了文章
2024-05-05 08:28:11
数据对账
统标识(System Identifiers)**:用于区分数据来源,确保知道数据来自哪个系统。 -
05.05 08:27:50发表了文章
2024-05-05 08:27:50
chaosblade
chaosblade -
05.05 08:27:30发表了文章
2024-05-05 08:27:30
Canny
Canny -
05.04 07:56:52回答了问题
2024-05-04 07:56:52
云效买资源包,周期长的话有优惠么?
赞0 踩0 评论0 -
05.04 07:54:25回答了问题
2024-05-04 07:54:25
在云效流水线中走的时候输出的报告都是0,这是为什么?
赞2 踩0 评论0 -
05.04 07:53:58回答了问题
2024-05-04 07:53:58
云效流水线新增加单元测试报错,如何解决?
赞1 踩0 评论0 -
05.04 07:53:23回答了问题
2024-05-04 07:53:23
云效appstack应用搜索这一块可以加个筛选吗? 筛选出未加入应用模板的应用
赞0 踩0 评论0 -
05.04 07:51:01回答了问题
2024-05-04 07:51:01
-
05.04 07:50:17回答了问题
2024-05-04 07:50:17
在云效为什么部署成功了,缺一直显示部署中呢?
赞0 踩0 评论0 -
05.04 07:49:44回答了问题
2024-05-04 07:49:44
在DBS数据库备份要关闭这个备份计划,在备份计划中有没有这个计划?
赞3 踩0 评论0 -
05.04 07:44:21发表了文章
2024-05-04 07:44:21
List
List -
05.04 07:43:57发表了文章
2024-05-04 07:43:57
YOLO
YOLO -
05.04 07:43:33发表了文章
2024-05-04 07:43:33
DataV
DataV -
05.03 08:16:04回答了问题
2024-05-03 08:16:04
大数据计算MaxCompute 这个有人遇到过吗?
赞0 踩0 评论0
-
发表了文章
2024-05-09
ReentrantLock
-
发表了文章
2024-05-09
mysqldump
-
发表了文章
2024-05-09
synchronized
-
发表了文章
2024-05-08
FIFO
-
发表了文章
2024-05-08
ChangeMessageVisibility
-
发表了文章
2024-05-08
Message Service
-
发表了文章
2024-05-07
索引
-
发表了文章
2024-05-07
Flow
-
发表了文章
2024-05-07
in
-
发表了文章
2024-05-06
:掌握移动端开发:HTML5 与 CSS3 的高效实践
-
发表了文章
2024-05-06
RXTX
-
发表了文章
2024-05-06
Performance Optimization
-
发表了文章
2024-05-05
数据对账
-
发表了文章
2024-05-05
chaosblade
-
发表了文章
2024-05-05
Canny
-
发表了文章
2024-05-04
YOLO
-
发表了文章
2024-05-04
DataV
-
发表了文章
2024-05-04
List
-
发表了文章
2024-05-03
添加监控
-
发表了文章
2024-05-03
ModelScope
滑动查看更多
-
回答了问题
2024-05-09
RocketMQ主从复制对于新加入的 Slave 为什么不是默认就从最旧的文件同步?
如果新加入的 Slave 节点从最旧的文件开始同步,那么它需要追赶大量的历史数据。这不仅会消耗更多的时间和资源,还可能对 Master 节点的性能产生较大影响,因为 Master 需要不断地提供历史数据的访问。
赞0 踩0 评论0 -
回答了问题
2024-05-09
rocketmq默认情况下消费者不会从slave节点拉取消息消费吗?
由于 Master 节点是消息写入的唯一来源,消费者从 Master 节点读取消息可以确保消息的一致性和顺序性。
赞1 踩0 评论0 -
回答了问题
2024-05-09
rocketmq的demo,在demo的基础上再加一个消息接收者就收不到消息,这是怎么回事呀?
RocketMQ 的 Broker 配置也可能影响消息的接收,比如队列数量、权限设置等。
网络问题:检查网络连接,确保消费者能够成功连接到 RocketMQ 服务器。
赞0 踩0 评论0 -
回答了问题
2024-05-09
RocketMQ遇到过好几次Message-Id 长度不同,是啥原因呢?
如果消息发送到了同一个 Topic 下不同的队列(Queue),它们的 QueueId 可能会不同,从而影响 MessageId 的长度。
赞0 踩0 评论0 -
回答了问题
2024-05-09
RocketMQ升级到5后,还是master-slave模式么?还是改成了DLedger模式了?
ocketMQ 5.x 引入 DLedger 后,提供了更灵活的存储选择,允许用户根据需要选择使用传统的 master-slave 模式或者 DLedger 模式。DLedger 模式通过 Raft 协议提供了更强的数据一致性保证,适用于对数据一致性要求极高的场景。
赞0 踩0 评论0 -
回答了问题
2024-05-08
在阿里云环境下,想让没有公网IP的Linux ECS实例通过有公网IP的Windows ECS
检查安全组规则:确保安全组规则允许相关的入站和出站流量。
检查网络ACLs:网络ACLs也应允许所需的流量。赞0 踩0 评论1 -
回答了问题
2024-05-08
宜搭提交流程之后流程上的数据被删除
刷新页面或重新加载应用,以确保前端显示的是最新的数据。
检查流程状态:在宜搭的流程管理界面检查流程的当前状态。赞2 踩0 评论0 -
回答了问题
2024-05-08
ModelScope中damo yolo训练,数据归一化好像没生效,配置文件给的均值0怎么办?
重新检查您的配置文件,确保归一化参数(均值和标准差)与您的数据集相匹配。如果均值是0,标准差是1,这意味着您的数据应该分布在标准正态分布周围。
赞1 踩0 评论0 -
回答了问题
2024-05-07
AI面试成为线下面试的“隐形门槛”,对此你怎么看?
这个问题有两面性的,在整体中看部分的意义和价值。不可孤立的分析问题本身。
我对AI面试成为线下面试“隐形门槛”的几点看法:效率提升:AI面试可以快速筛选大量候选人,特别是在初步筛选阶段,这有助于企业节省时间和资源。

标准化流程:AI面试通过预设的问题和评估标准,可以减少人为偏见,使面试过程更加标准化和客观。

心理压力:面对AI面试官,一些求职者可能会感到不自在或压力增大,因为缺乏人际互动和即时反馈。

人际互动的缺失:AI可能无法完全捕捉到人类面试官通过微妙的非语言交流所能观察到的候选人特质。
技术局限性:AI面试系统依赖算法,可能存在一定的局限性,比如难以评估求职者的创造力、团队合作能力等软技能。
隐私和数据安全:AI面试涉及大量个人数据的收集和分析,这引发了对隐私保护和数据安全的担忧。
准备策略的变化:求职者可能需要调整面试准备策略,比如练习在镜头前的表现,熟悉可能的AI面试问题等。
辅助而非替代:AI面试目前更多地被用作辅助工具,帮助企业在初筛阶段减少工作量,而非完全替代传统的面试方法。
持续改进:随着技术的不断进步,AI面试系统也在不断优化,以更好地模拟和理解人类交流的复杂性。
对求职者的新要求:AI面试要求求职者不仅要有扎实的专业技能,还需要具备良好的镜头表现力和对新技术的适应能力。
赞3 踩0 评论0 -
回答了问题
2024-05-07
如何从零构建一个现代深度学习框架?
从零构建一个现代深度学习框架是一个复杂且耗时的过程:
可以参考这样的过程,试试看
研究现有框架:首先,了解现有的深度学习框架(如TensorFlow、PyTorch、PaddlePaddle等)的设计原理和实现细节。这有助于你了解深度学习框架的基本组成和功能需求。
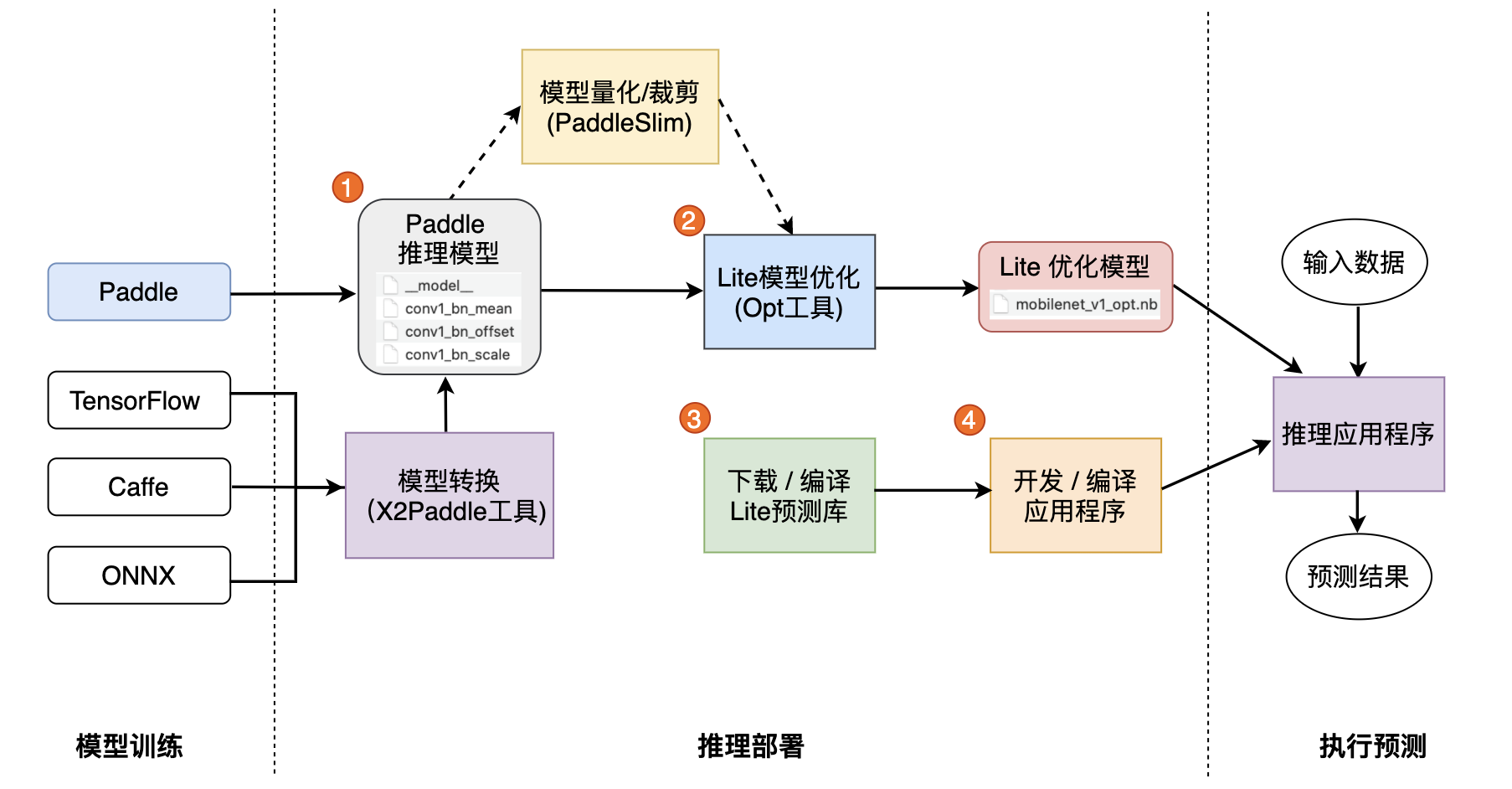
确定目标:明确你想要构建的深度学习框架的目标,例如是否支持动态图、是否需要高性能、是否需要跨平台支持等。
设计架构:设计深度学习框架的架构,包括计算图、自动微分、优化器、损失函数、层结构等。这需要对深度学习算法有深入的理解。
选择编程语言:选择一种或多种编程语言进行开发,常见的选择有Python、C++和CUDA。Python通常用于快速原型开发,而C++和CUDA用于性能关键部分的实现。

实现核心组件:
- 计算图:实现一个计算图,用于表示神经网络的前向和后向计算。
- 自动微分:实现自动微分机制,以便计算梯度并进行优化。
- 优化器:实现常用的优化器,如SGD、Adam等。
- 损失函数:实现常用的损失函数,如交叉熵、均方误差等。
- 层和激活函数:实现各种层(如全连接层、卷积层等)和激活函数(如ReLU、Sigmoid等)。
性能优化:对关键部分进行性能优化,例如使用GPU加速计算、并行计算等。
接口和API设计:设计易于使用的API和接口,以便用户能够方便地构建和训练模型。
单元测试和集成测试:编写测试代码,确保框架的各个组件能够正常工作。
文档和示例:编写详细的文档和示例代码,帮助用户理解和使用你的深度学习框架。
社区和生态系统建设:鼓励社区参与,收集反馈并持续改进框架。同时,开发相关的工具和库,构建一个完整的生态系统。
部署和跨平台支持:确保框架能够在不同的平台(如Windows、Linux、macOS等)上运行,并支持模型的部署到各种设备(如服务器、移动设备、嵌入式设备等)。
持续迭代:根据用户反馈和技术发展,不断迭代和优化框架。
赞1 踩0 评论0 -
回答了问题
2024-05-07
OceanBase数据库两者高并发时响应时长是否都一致 。ap和lp时哪个更好?
在高并发环境下,如果主要是读取操作,LP模式可能会提供更好的响应时长,因为它允许多个副本处理读取请求。
对于写入操作,AP模式下主副本是唯一的写入点,因此在写入密集型操作中,主副本的性能将直接影响整体响应时长。赞0 踩0 评论0 -
回答了问题
2024-05-07
OceanBase数据库这个性能瓶颈在当前最新版本 4.2.2 还存在吗 ?
避免单个表的AUTO_INCREMENT索引过大,可以采用分区表,每个分区有自己的AUTO_INCREMENT。
赞0 踩0 评论0 -
回答了问题
2024-05-07
OceanBase数据库意思是不路由到 备副本 ,都默认路由到 主 副本 吗?
OceanBase的默认路由策略可能会根据负载均衡和高可用性的需求将读取操作路由到备副本上,而将写入操作路由到主副本。这样可以在保证数据一致性的同时,提高系统的读取吞吐量。
赞0 踩0 评论0 -
回答了问题
2024-05-07
OceanBase数据库现在oc数据库mysql租户版本是5.7.25现在想使用5.7.28怎么办?
按照OceanBase提供的升级工具和步骤执行升级,通常这涉及到使用OceanBase的管理工具或命令行界面。
赞1 踩0 评论0 -
回答了问题
2024-05-07
OceanBase数据库mysql_version能调整吗?
OceanBase数据库的版本号主要用于显示和兼容性声明,一般不推荐用户手动修改版本号,因为这可能会影响客户端与数据库服务器的兼容性。
赞0 踩0 评论0 -
回答了问题
2024-05-06
EMAS移动推送Android集成时报错compile not found
检查app模块的build.gradle文件,确保您已经按照EMAS的集成文档正确添加了依赖项。
赞0 踩0 评论0 -
回答了问题
2024-05-06
DataWorks读取polarDB FOR mysql的binlog,是否会对数据库产生压力?
为了保证数据的一致性和完整性,可能需要保留一定时间窗口内的 binlog 文件,这会占用磁盘空间。
赞0 踩0 评论0 -
回答了问题
2024-05-06
DataWorks已经切换,但是提交任务会出现这个提示,不让提交怎么办?
在 DataWorks 的任务配置界面,找到资源组设置的部分,并将其从公共资源组切换到独享资源组。
赞0 踩0 评论0 -
回答了问题
2024-05-06
DataWorks离线同步的组件是dataX怎么办?
在 DataWorks 或 StreamX 的控制台中配置实时流任务。
使用 streamx-pump 组件订阅 MySQL 的 binlog。
配置数据的转换和目标系统,比如将增量数据同步到 Kafka 或其他支持的系统。赞2 踩0 评论0 -
回答了问题
2024-05-05
代码优化建议的功能无法替入代码
如果插件生成的类包含多个优化后的函数,你可以选择性地逐个集成这些函数,而不是一次性集成整个类。
赞0 踩0 评论0
滑动查看更多
暂无更多信息