

勋章







我关注的人
粉丝










技术能力
- 网络安全
- 网络攻防
- 渗透技术
- 算法
暂时未有相关云产品技术能力~
暂无个人介绍
2024年05月
-
05.13 17:54:55
 发表了文章
2024-05-13 17:54:55
发表了文章
2024-05-13 17:54:55
【Java开发指南 | 第三十一篇】Java 包(package)
【Java开发指南 | 第三十一篇】Java 包(package) -
05.13 17:40:43发表了文章
2024-05-13 17:40:43
Java开发指南 | 第三十篇】Java 枚举(enum)
Java开发指南 | 第三十篇】Java 枚举(enum) -
05.13 17:38:36发表了文章
2024-05-13 17:38:36
【Java开发指南 | 第二十九篇】Java接口
【Java开发指南 | 第二十九篇】Java接口 -
05.13 17:36:48发表了文章
2024-05-13 17:36:48
【Java开发指南 | 第二十八篇】Java封装
【Java开发指南 | 第二十八篇】Java封装 -
05.13 17:35:31发表了文章
2024-05-13 17:35:31
【Java开发指南 | 第二十七篇】Java抽象类
【Java开发指南 | 第二十七篇】Java抽象类 -
05.13 17:33:55发表了文章
2024-05-13 17:33:55
【Java开发指南 | 第二十六篇】Java多态
【Java开发指南 | 第二十六篇】Java多态 -
05.13 17:33:01发表了文章
2024-05-13 17:33:01
【Java开发指南 | 第二十五篇】Java 重写(Override)与重载(Overload)
【Java开发指南 | 第二十五篇】Java 重写(Override)与重载(Overload) -
05.13 17:31:08发表了文章
2024-05-13 17:31:08
【Java开发指南 | 第二十四篇】Java继承
【Java开发指南 | 第二十四篇】Java继承 -
05.13 17:28:11发表了文章
2024-05-13 17:28:11
【Java开发指南 | 第二十三篇】Java异常处理
【Java开发指南 | 第二十三篇】Java异常处理 -
05.13 17:25:33发表了文章
2024-05-13 17:25:33
【Java开发指南 | 第二十一篇】Java流之文件
【Java开发指南 | 第二十一篇】Java流之文件 -
05.13 17:23:54发表了文章
2024-05-13 17:23:54
【Java开发指南 | 第二十篇】Java流之控制台
【Java开发指南 | 第二十篇】Java流之控制台 -
05.13 17:21:46发表了文章
2024-05-13 17:21:46
【Java开发指南 | 第十九篇】Java方法
【Java开发指南 | 第十九篇】Java方法 -
05.13 17:18:45发表了文章
2024-05-13 17:18:45
【Java开发指南 | 第十八篇】Eclipse安装教程
【Java开发指南 | 第十八篇】Eclipse安装教程 -
05.13 17:15:58发表了文章
2024-05-13 17:15:58
本地CentOS安装轻量级容器PaaS平台KubeSphere并实现无公网IP远程访问
本地CentOS安装轻量级容器PaaS平台KubeSphere并实现无公网IP远程访问 -
05.13 17:13:33发表了文章
2024-05-13 17:13:33
【C语言】求最小新整数(贪心算法)
【C语言】求最小新整数(贪心算法) -
05.13 17:12:23发表了文章
2024-05-13 17:12:23
【Java开发指南 | 第十七篇】Java 方法
【Java开发指南 | 第十七篇】Java 方法 -
05.13 17:10:47发表了文章
2024-05-13 17:10:47
【Java开发指南 | 第十六篇】Java数组及Arrays类
【Java开发指南 | 第十六篇】Java数组及Arrays类 -
05.13 17:07:14发表了文章
2024-05-13 17:07:14
【Java开发指南 | 第十五篇】Java Character 类、String 类
【Java开发指南 | 第十五篇】Java Character 类、String 类 -
05.13 17:03:54发表了文章
2024-05-13 17:03:54
【Java开发指南 | 第十四篇】Java Number类及Math类
【Java开发指南 | 第十四篇】Java Number类及Math类 -
05.13 17:00:40发表了文章
2024-05-13 17:00:40
【Java开发指南 | 第十三篇】Java条件语句
【Java开发指南 | 第十三篇】Java条件语句
-
05.13 16:52:36发表了文章
2024-05-13 16:52:36
【Java开发指南 | 第十二篇】Java循环结构
【Java开发指南 | 第十二篇】Java循环结构 -
05.13 16:50:14发表了文章
2024-05-13 16:50:14
VPN淘汰,零信任接入崛起
VPN淘汰,零信任接入崛起 -
05.13 16:43:29发表了文章
2024-05-13 16:43:29
【Java开发指南 | 第十一篇】Java运算符
【Java开发指南 | 第十一篇】Java运算符 -
05.13 16:31:31发表了文章
2024-05-13 16:31:31
【网络安全 | 信息收集】JS文件信息收集工具LinkFinder安装使用教程
【网络安全 | 信息收集】JS文件信息收集工具LinkFinder安装使用教程 -
05.13 16:28:13发表了文章
2024-05-13 16:28:13
【Java开发指南 | 第十篇】Java修饰符
【Java开发指南 | 第十篇】Java修饰符 -
05.13 16:24:27发表了文章
2024-05-13 16:24:27
【Java开发指南 | 第九篇】访问实例变量和方法、继承、接口
【Java开发指南 | 第九篇】访问实例变量和方法、继承、接口 -
05.13 16:22:29发表了文章
2024-05-13 16:22:29
【Java开发指南 | 第八篇】Java变量、构造方法、创建对象
【Java开发指南 | 第八篇】Java变量、构造方法、创建对象 -
05.13 16:21:06发表了文章
2024-05-13 16:21:06
【Java开发指南 | 第七篇】静态变量生命周期、初始化时机及静态变量相关性质
【Java开发指南 | 第七篇】静态变量生命周期、初始化时机及静态变量相关性质 -
05.13 16:19:58发表了文章
2024-05-13 16:19:58
【Java开发指南 | 第六篇】Java成员变量(实例变量)、 类变量(静态变量)
【Java开发指南 | 第六篇】Java成员变量(实例变量)、 类变量(静态变量) -
05.13 16:18:23发表了文章
2024-05-13 16:18:23
【Java开发指南 | 第五篇】Java变量类型、参数变量及局部变量
【Java开发指南 | 第五篇】Java变量类型、参数变量及局部变量 -
05.13 16:14:16发表了文章
2024-05-13 16:14:16
【Java开发指南 | 第四篇】Java常量、自动类型转换、修饰符
【Java开发指南 | 第四篇】Java常量、自动类型转换、修饰符 -
05.13 16:10:26发表了文章
2024-05-13 16:10:26
【Java开发指南 | 第三篇】Java 空行、强制类型转换及基本数据类型
【Java开发指南 | 第三篇】Java 空行、强制类型转换及基本数据类型 -
05.13 16:09:14发表了文章
2024-05-13 16:09:14
【Java开发指南 | 第二篇】标识符、Java关键字及注释
【Java开发指南 | 第二篇】标识符、Java关键字及注释 -
05.13 16:07:32发表了文章
2024-05-13 16:07:32
【Java开发指南 | 第一篇】类、对象基础概念及Java特征
【Java开发指南 | 第一篇】类、对象基础概念及Java特征 -
05.13 16:01:19发表了文章
2024-05-13 16:01:19
【JavaScript | RegExp】正则表达式
【JavaScript | RegExp】正则表达式 -
05.13 15:49:36发表了文章
2024-05-13 15:49:36
【汇编语言实战】解素数环问题
【汇编语言实战】解素数环问题 -
05.13 15:48:10发表了文章
2024-05-13 15:48:10
【汇编语言实战】解迷宫问题
【汇编语言实战】解迷宫问题 -
05.13 15:45:19发表了文章
2024-05-13 15:45:19
【汇编语言实战】整数拆分问题
【汇编语言实战】整数拆分问题 -
05.13 15:43:10发表了文章
2024-05-13 15:43:10
【汇编语言实战】实现九九乘法表
【汇编语言实战】实现九九乘法表 -
05.13 15:41:25发表了文章
2024-05-13 15:41:25
【汇编语言实战】基础知识+函数的引用(求1+2+..+N)+OllyDBG的使用
【汇编语言实战】基础知识+函数的引用(求1+2+..+N)+OllyDBG的使用 -
05.13 15:37:58发表了文章
2024-05-13 15:37:58
【汇编语言实战】冒泡排序
【汇编语言实战】冒泡排序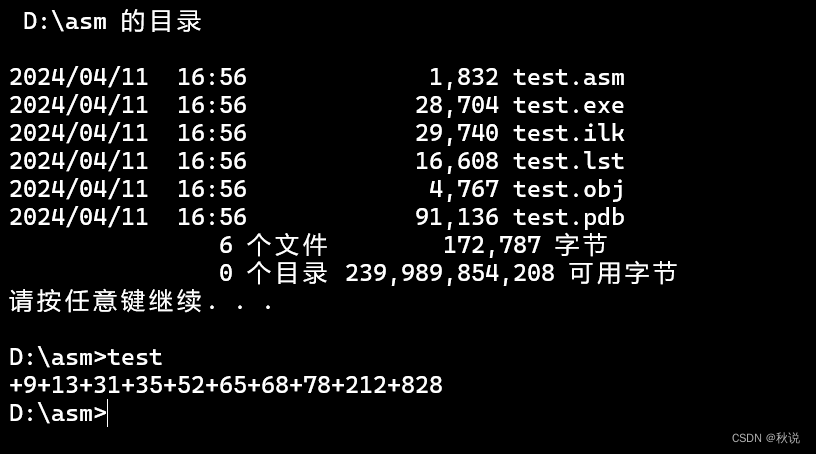
-
05.13 15:36:01发表了文章
2024-05-13 15:36:01
【汇编语言实战】实现输出集合{1,2,...,n}全排列
【汇编语言实战】实现输出集合{1,2,...,n}全排列 -
05.13 15:34:11发表了文章
2024-05-13 15:34:11
【汇编语言实战】给定一个句子,将大写字母变为小写
【汇编语言实战】给定一个句子,将大写字母变为小写 -
05.13 15:32:51发表了文章
2024-05-13 15:32:51
【汇编语言实战】最小公倍数和最大公约数
【汇编语言实战】最小公倍数和最大公约数 -
05.13 15:30:40发表了文章
2024-05-13 15:30:40
【汇编语言实战】二分查找
【汇编语言实战】二分查找 -
05.13 15:29:13发表了文章
2024-05-13 15:29:13
【汇编语言实战】对给定的数组实现堆排序
【汇编语言实战】对给定的数组实现堆排序
-
发表了文章
2024-05-15
【Java开发指南 | 第二十五篇】Java 重写(Override)与重载(Overload)
-
发表了文章
2024-05-15
【Java开发指南 | 第二十六篇】Java多态
-
发表了文章
2024-05-15
【Java开发指南 | 第二十七篇】Java抽象类
-
发表了文章
2024-05-15
【Java开发指南 | 第十五篇】Java Character 类、String 类
-
发表了文章
2024-05-15
【Java开发指南 | 第十四篇】Java Number类及Math类
-
发表了文章
2024-05-15
【网络安全 | 信息收集】JS文件信息收集工具LinkFinder安装使用教程
-
发表了文章
2024-05-15
【Java开发指南 | 第一篇】类、对象基础概念及Java特征
-
发表了文章
2024-05-15
【Java开发指南 | 第八篇】Java变量、构造方法、创建对象
-
发表了文章
2024-05-15
【Java开发指南 | 第七篇】静态变量生命周期、初始化时机及静态变量相关性质
-
发表了文章
2024-05-15
【Java开发指南 | 第九篇】访问实例变量和方法、继承、接口
-
发表了文章
2024-05-15
【汇编语言实战】实现九九乘法表
-
发表了文章
2024-05-15
【汇编语言实战】两个32位数的相加运算
-
发表了文章
2024-05-15
【汇编语言实战】输出二维数组中特定元素
-
发表了文章
2024-05-15
【汇编语言实战】输出数组中特定元素
-
发表了文章
2024-05-15
【网络安全 | 网络协议】一文讲清HTTP协议
-
发表了文章
2024-05-15
【Java开发指南 | 第三十一篇】Java 包(package)
-
发表了文章
2024-05-15
【Java开发指南 | 第十七篇】Java 方法
-
发表了文章
2024-05-15
【Java开发指南 | 第十六篇】Java数组及Arrays类
-
发表了文章
2024-05-15
【Java开发指南 | 第十篇】Java修饰符
-
发表了文章
2024-05-15
【Java开发指南 | 第六篇】Java成员变量(实例变量)、 类变量(静态变量)

-
 回答了问题
2023-05-24
回答了问题
2023-05-24
你印象最深的一道SQL题目是什么?
写题时遇见的一道SQL
有一个数据表?student,包含以下列:id、name和score。每个学生都有一个唯一的ID,name?是学生的姓名,score?是该学生的分数。编写一个?SQL?查询,使用以下条件筛选前三个最高分数的学生:
CREATE?TABLE?student( ??id?INT, ??name?VARCHAR(100), ??score?INT );
INSERT?INTO?student?VALUES?(1,?'AAA',?80); INSERT?INTO?student?VALUES?(2,?'BBB',?67); INSERT?INTO?student?VALUES?(3,?'CCC',?92); INSERT?INTO?student?VALUES?(4,?'DDD',?91); INSERT?INTO?student?VALUES?(5,?'EEE',?88); INSERT?INTO?student?VALUES?(6,?'FFF',?95); INSERT?INTO?student?VALUES?(7,?'GGG',?87); INSERT?INTO?student?VALUES?(8,?'HHH',?90); INSERT?INTO?student?VALUES?(9,?'III',?79);
想了好久,发现这个问题可以使用?RANK()?函数和子查询来解决。以下是解决方案: SELECT?*?FROM?( ??SELECT?*,?RANK()?OVER?(ORDER?BY?score?DESC)?AS?rank ??FROM?student )?as?s WHERE?s.rank?<=?3;
这个方案首先对学生表进行了一个子查询,并且使用?RANK()?函数来为每个学生成绩进行排名。然后,它在查询结果中找到排名前三的学生。 如果有多个学生分数一样,排名可能会出现重复。如果不希望重复排名,可以使用?DENSE_RANK()?函数来代替?RANK()。
赞2 踩0 评论0