




通义千问7B-基于本地知识库问答
上期,我们介绍了通义千问7B模型的微调+部署方式,但在实际使用时,很多开发者还是希望能够结合特定的行业知识来增强模型效果,这时就需要通过外接知识库,让大模型能够返回更精确的结果。
DeepSeek VL系列开源,魔搭社区模型微调最佳实践教程来啦!
3月11日,DeepSeek-AI开源了全新多模态大模型DeepSeek-VL系列,包含1.3b、7b两种不同规模的4个版本的模型。
社区供稿 |【中文Llama-3】Chinese-LLaMA-Alpaca-3开源大模型项目正式发布
Chinese-LLaMA-Alpaca-3开源大模型项目正式发布,开源Llama-3-Chinese-8B(基座模型)和Llama-3-Chinese-8B-Instruct(指令/chat模型)
通义千问7B模型开源,魔搭最佳实践来了
通义千问开源!阿里云开源通义千问70亿参数模型,包括通用模型Qwen-7B-Base和对话模型Qwen-7B-Chat,两款模型均已上线ModelScope魔搭社区,开源、免费、可商用,欢迎大家来体验。
零一万物Yi-34B-Chat 微调模型及量化版开源!魔搭社区最佳实践教程!
11月24日,零一万物基正式发布并开源微调模型 Yi-34B-Chat,可申请免费商用。同时,零一万物还为开发者提供了 4bit/8bit 量化版模型,Yi-34B-Chat 4bit 量化版模型可以直接在消费级显卡(如RTX3090)上使用。魔搭社区已支持下载、推理训练体验,并推出相关教程,欢迎大家来玩!

用LangChain构建大语言模型应用
LangChain 是一个开源 Python 库,任何可以编写代码的人都可以使用它来构建 LLM 支持的应用程序。 该包为许多基础模型提供了通用接口,支持提示管理,并在撰写本文时充当其他组件(如提示模板、其他 LLM、外部数据和其他工具)的中央接口。
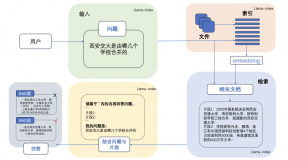
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
深度强化学习在大模型中的应用:现状、问题和发展
强化学习在大模型中的应用具有广泛的潜力和机会。通过使用强化学习算法,如DQN、PPO和TRPO,可以训练具有复杂决策能力的智能体,在自动驾驶、机器人控制和游戏玩家等领域取得显著成果。然而,仍然存在一些挑战,如样本效率、探索与利用平衡以及可解释性问题。未来的研究方向包括提高样本效率、改进探索策略和探索可解释的强化学习算法,以进一步推动强化学习在大模型中的应用。
社区供稿 | Llama3-8B中文版!OpenBuddy发布新一代开源中文跨语言模型
此次发布的是在3天时间内,我们对Llama3-8B模型进行首次中文跨语言训练尝试的结果:OpenBuddy-Llama3-8B-v21.1-8k。
手把手教你捏一个自己的Agent
Modelscope AgentFabric是一个基于ModelScope-Agent的交互式智能体应用,用于方便地创建针对各种现实应用量身定制智能体,目前已经在生产级别落地。


一文读懂“大语言模型”
本文基于谷歌云的官方视频:[《Introduction to Large Language Models》](https://www.youtube.com/watch?v=zizonToFXDs&t=525s&ab_channel=GoogleCloudTech) ,整理而成,希望对大家入门大语言模型有帮助。
社区供稿 | XTuner发布LLaVA-Llama-3-8B,支持单卡推理,评测和微调
日前,XTuner 团队基于 meta 最新发布的 Llama-3-8B-Instruct 模型训练并发布了最新版多模态大模型 LLaVA-Llama-3-8B, 在多个评测数据集上取得显著提升。
FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量的计算资源,而能效比高的 Arm 架构服务器可以提供更好的性能和效率。



