2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
>>发布会传送门:https://yqh.aliyun.com/live/detail/21691
点击查看详情:https://yqh.aliyun.com/live/polardb2021
作者:阿里云数据库 胡庆达,张海平,季育轩
在过去的几年里,我们观察到,当数据达到一定规模后,PolarDB for MySQL(后文简称PolarDB)的部分用户(包括集团内部用户和公有云上的外部客户)更愿意使用gh-ost/pt-osc这样的外部工具来进行DDL操作。PolarDB内核团队为用户case by case地解决了很多DDL使用带来的问题,在处理这些问题的同时,我们也在不断地思考和讨论,云上客户越来越多,中小客户群体不断扩大,我们究竟要如何在内核层面解决DDL日益凸显的繁重弊端,让客户少为DDL担忧。
DDL面临的问题
DDL在生产环境下面临的问题主要来自两个方面:一个是MDL导致的阻塞问题,一个是全量数据复制带来的资源使用问题。
为了保证DD的一致性,MDL被引入来同步DDL,DML和DQL,这使得同一个表上的各种操纵必须在MDL这一粗粒度锁上汇聚,由此引发了各种超时问题,严重影响了上层业务。此外,在PolarDB共享存储结构下,多节点间的DD一致性要求使得这一问题拓展到了读写节点之间,也为用户带来了诸多困扰。
在PolarDB内部,数据物理存储和数据定义是分离的,因此DDL操作常常需要进行全量数据的重建,由此导致了单次DDL操作耗时甚至可以达到天级。这种操作的潜藏风险让用户不得不焦躁地在客户群里反复和研发同学沟通确认。同时,全量数据的重建会占用大量的系统资源。PolarDB的云原生优势已经在相当程度上为客户规避了这一问题,资源的快速弹性伸缩防止了OOM,磁盘空间不足等问题,但是系统资源的大量占用将提高其他操作的耗时,降低数据库的整体吞吐,最终将影响上层业务的稳定性。
此外,在全面上云的大背景下,云上中小客户群体不断扩大,他们中很多还缺乏处理数据库复杂生产环境下的各种细节问题的经验。在我们的观察里,这些客户的DDL操作频率显著高于集团内部用户和其他大客户,DDL使用过程中的很多问题让这些用户焦头烂额。
优化和演进方向
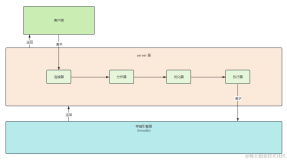
解决DDL带来的问题,本质上我们需要做到的只有一点:降低DDL执行耗时。如果DDL可以在瞬间完成,那么DDL带来的诸多问题都将迎刃而解。于是在这样一种思路的指导下,我们提出了Instant DDL + Parallel DDL + 物理复制链路优化的整体解决方案。
对于可通过变更数据定义完成的DDL类型,如加列,减列等,我们将其Instant化,使其无需修改存量数据,因而可在瞬间完成;对于必须全量扫描并构建数据的DDL类型,如重建主键索引,新建二级索引等,我们允许其在引擎内部被并行地处理,从而充分利用系统资源,降低执行耗时。
此外,我们还使用了并行MDL同步方案,解决DDL过程MDL在读写节点上的阻塞问题,同时优化了物理复制使用的Redo Log,降低了DDL操作时读节点同步Redo Log的负载。这些物理复制链路上的优化和DDL执行链路上的整体演进共同作用,构成了攻克DDL难关的主力军和护卫队。
Instant DDL
像add column这类DDL,原有的执行逻辑包含两个部份的操作,分别涉及数据字典和存量数据。其中数据字典的修改是非常快速的,但是表全量数据的重建则耗时漫长。
Instant DDL则仅改变数据字典中的表定义信息,而不修改任何存量数据,从而使得DDL操作可以在瞬间完成。

目前add column at last instantly已经在PolarDB 5.7和8.0上得到支持, add column at any position instantly和drop column instantly等也将在随后的版本中上线,未来所有逻辑上可Instant 化的DDL操作都将支持Instant算法。用户只需热升级到相应的版本,即可让原本耗时达到小时级甚至天级的DDL操作在瞬间完成。
Parallel DDL
新建二级索引这类DDL操作,执行时必须扫描全量数据,并构建新的索引树,整体耗时非常长。
Parallel DDL则将Data Scan和B+ Tree Build操作划分成多个子任务,通过内部的并行服务子系统进行调度并适时地执行,最后将各个子任务的执行结果进行合并得到最终结果。
Parallel DDL 通过存储引擎内部的并行执行,充分利用系统资源,使得部分DDL的执行效率最高可提高十倍以上,从而将整个DDL的时间窗口缩小到原来的十分之一。目前parallelly create secondary index 已经在PolarDB 8.0上得到支持,后续将陆续上线到其他版本,同时其他类型的Parallel DDL支持也将在随后的版本中发布。
物理复制链路上的DDL优化
Instant DDL 和Parallel DDL 是DDL执行链路上的演进方案。但是在PolarDB共享存储架构下,复制链路上的问题同样制约着DDL的能力。例如为了保证各节点的一致性,必须在读写节点间通过Redo Log同步MDL信息,然而MDL锁的阻塞将影响Redo Log的同步,为此我们采用了并行MDL同步方案,将MDL信息的同步和Redo Log的同步解偶,提高了整个集群在DDL时的吞吐能力。此外我们改进了DDL过程中的Redo Log同步路径,不仅优化了写节点在产生DDL Redo Log时的IO开销,同时让只读节点有选择的同步Redo Log,降低DDL 操作时只读节点的负载,从而降低DDL过程中的读写节点间的同步代价。这些物理复制链路上的优化为DDL执行链路上的优化效果保驾护航,两者协同使得整个集群处理DDL的能力显著增强。
小结
DDL是PolarDB所有操作中最繁重的一种,曾经为用户带去了很多不好的使用体验。而Instant DDL + Parallel DDL + 物理复制链路优化是切实解决DDL 繁重弊端的重要组合拳。相信经过未来若干版本的迭代和演进,PolarDB DDL将为客户带来体验上翻天覆地的变化。期待未来用户执行DDL操作像执行简单查询一样淡定坦然,PolarDB内核团队将始终如一地为用户打造最佳的云原生关系性数据库管理系统。