问题一:DataWorks怎样查看binlog日志?
DataWorks怎样查看binlog日志?
参考回答:
在DataWorks中,您可以按照以下步骤查看MySQL的binlog日志:
- 连接到您的MySQL服务器,然后运行以下查询以检查binlog是否已启用:
sql
SHOW VARIABLES LIKE 'log_bin';
如果输出包含 log_bin 和 log_bin_index 变量,并且它们的值不为空,则说明binlog已启用。
- 如果binlog已启用,请继续执行以下查询以获取最新的binlog文件名和位置:
sql
SHOW MASTER STATUS;
此查询的结果将包括两个字段:File 和 Position,分别表示最新的binlog文件名和当前位置。
- 使用上述查询得到的 File 和 Position 值,您可以从MySQL的数据目录中找到相应的binlog文件并将其下载到本地进行查看。默认情况下,数据目录的位置将在 my.cnf 文件中定义,可以通过以下查询获得:
csharp
SELECT @@datadir;
您可以使用 cat、less 或其他文本编辑器来打开和查看binlog文件的内容。
关于本问题的更多回答可点击原文查看:/ask/566948
问题二:DataWorks如何【新建表】?
DataWorks如何【新建表】?
参考回答:
数据开发(datastudio)界面支持多种可视化建表方式:
方式一:业务流程下使用表容器建表
方式二:表管理下新建表
方式三:数据集成一键生成MaxCompute表
方式四:创建手动任务新建表
【删除表】
方式一:在数据开发表管理中删除开发表。
方式二:在“数据地图”-“我的数据”删除表。
方式三:新建手动任务/临时查询删除表
关于本问题的更多回答可点击原文查看:/ask/566946
问题三:DataWorks中 ots 新建表,插入数据方式?
DataWorks中 ots 新建表,插入数据方式?
参考回答:
在DataWorks中,您可以按照以下步骤使用OTS(开放表格存储)新建一个表并插入数据:
- 首先,登录 DataWorks 控制台。
- 然后,选择要操作的项目并点击进入。
- 接着,点击左侧导航栏上的“开发”,然后选择“数据开发”。
- 在数据开发页面,点击左侧菜单栏上的“表”,然后点击右上角的“新建”按钮。
- 在弹出的新建表对话框中,填写表的相关信息,例如表名、表描述、所属业务流程等。
- 接下来,选择表引擎为OTS。
- 在表结构设置中,为每个列设置对应的列名、列类型和列描述等信息。
- 完成表结构设置后,点击“保存”按钮即可完成表的创建。
- 创建完表后,您可以使用DataWorks提供的API来插入数据。例如,您可以使用POST请求,将JSON格式的数据发送到OTS服务端的API接口,即可完成数据的插入。
关于本问题的更多回答可点击原文查看:/ask/566945
问题四:DataWorks是ploarDB for mysql,binlog怎么查看呢?
DataWorks是ploarDB for mysql,binlog怎么查看呢?
参考回答:
类似于 show binlog events之类的,1. 如果是在数据开发界面执行的,可以在运行历史或冒烟测试记录中查看历史的运行日志。
运行历史保留近3天的记录。
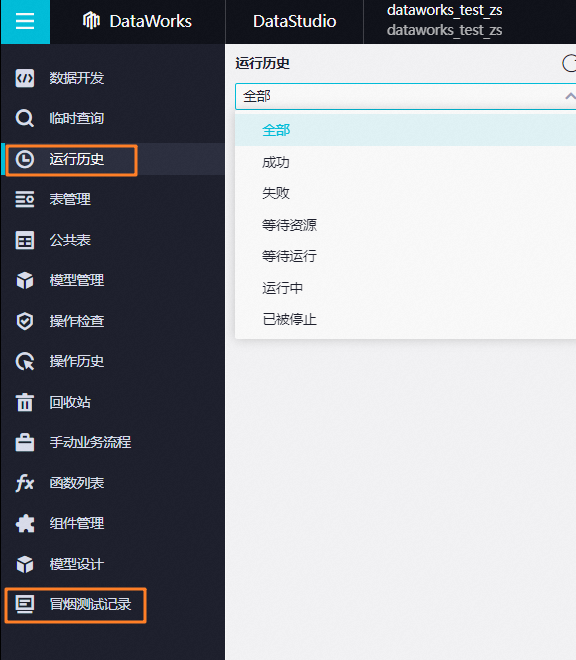
如果是在运维中心中执行的,可以对实例右键查看运行日志或使用运行诊断。
实例保存30天;
独享调度资源组的实例日志runlog保存30天;
公共调度资源组的实例日志runlog保存7天,运行完成的实例大于3m的每天定时清理。
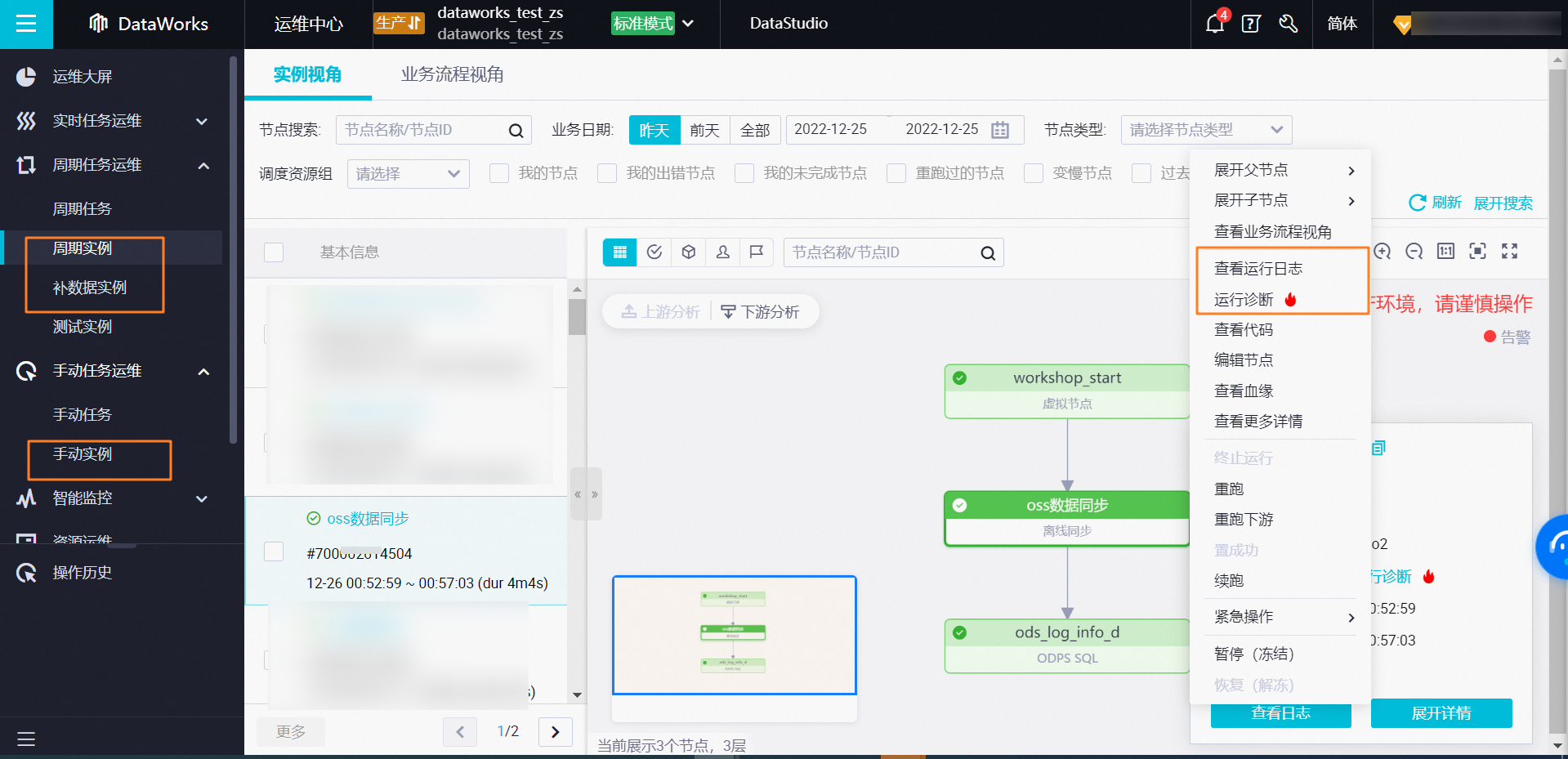
看截图的表字段 应该是实时同步读取的表数据 实时同步实际读取的是binlog的数据 如果发现写入的数据不符合预期 最好是先查一下binlog是否符合预期
关于本问题的更多回答可点击原文查看:/ask/566944
问题五:DataWorks在整库全增量(准实时)的数据集成中,对现有的同步任务,如何在添加部分表的同步呢?
DataWorks在整库全增量(准实时)的数据集成中,对现有的同步任务,如何在添加部分表的同步呢?是需要将现有的任务暂停再添加么? 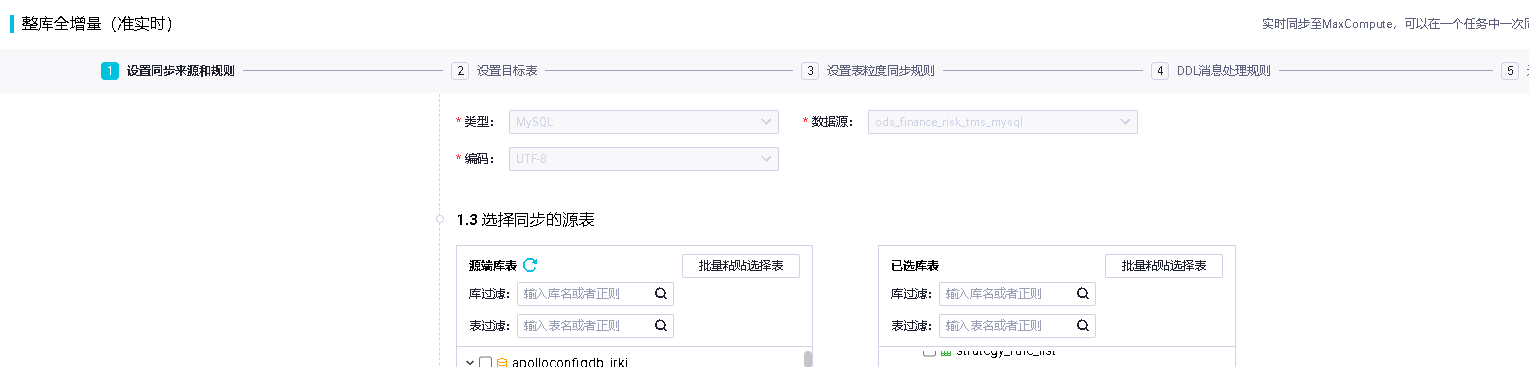
参考回答:
在这边可以直接修改配置 增加需要的表以后再提交执行 新表会执行一次全增量 
关于本问题的更多回答可点击原文查看:/ask/566943




