2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
前言
文本向量化是将文本数据转换为数值向量的过程。由于计算机只能处理数值数据,文本数据需要被转换成数值形式才能被算法和模型处理。这种向量化的过程使得文本数据能够被机器学习、深度学习等算法有效地处理。文本向量化的方法有多种,其中常见的有以下几种:
词袋模型 (Bag of Words, BoW): 这是最简单的文本向量化方法,它忽略了文本中单词的顺序和语法,只考虑单词的出现次数。每个文档或句子可以表示为一个向量,其中每个维度代表一个单词,值为该单词在文本中的出现次数或频率。
TF-IDF (Term Frequency-Inverse Document Frequency): TF-IDF是一个更复杂的向量化方法,它考虑了单词在文档中的频率以及它在整个语料库中的频率。TF-IDF值会衡量一个单词在文档中的重要性,越大表示该单词在文档中越重要。
Word Embeddings: 词嵌入是通过神经网络学习得到的单词向量,它能够捕捉单词之间的语义关系。例如,Word2Vec、GloVe和FastText都是常用的词嵌入模型。
预训练模型: 例如BERT、GPT等,这些模型能够直接将文本转换成固定长度的向量,保留了文本的上下文信息和语义信息。
Embedding模型原理
Embedding模型通过学习数据的内在特性和上下文关系,将原始数据表示为密集的向量形式。这些向量在低维空间中的距离和方向能够反映原始数据项之间的相似度和语义关联。例如,在自然语言处理(NLP)中,词向量表示能够揭示词汇之间的多种关系,如同义、反义或上下位关系。使用Embedding模型,搜索引擎可以超越传统的关键词匹配,实现更深层次的语义理解。例如,在搜索“家庭咖啡制作方法”时,传统搜索引擎可能只会返回包含这些关键词的文本。而采用Embedding模型的搜索引擎能够理解查询背后的意图,提供涵盖选择咖啡豆、磨豆技巧和不同冲泡方法等更详细、更专业的内容。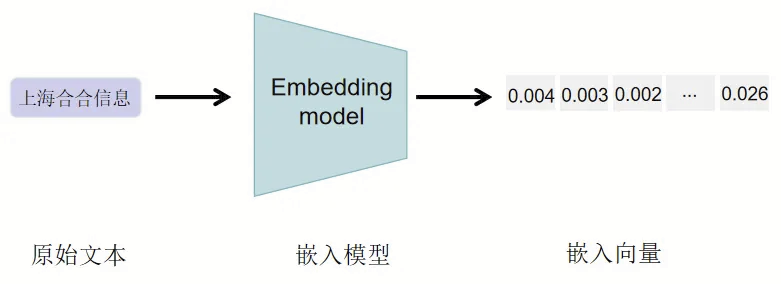
C-MTEB
MTEB(Multilingual Text Embedding Benchmark)是一个专门用于评测NLP(自然语言处理)模型的平台。该平台包括8个不同的语义向量任务,覆盖了58个不同的数据集和112种语言。这些任务涵盖了NLP中的多个关键应用领域,如文本检索、语义文本相似度(STS)、对句子对的分类(PairClassification)、文本分类(Classification)、重新排序(Reranking)和文本聚类(Clustering)。
C-MTEB是MTEB的中文版本,专门针对中文文本的海量嵌入(embedding)进行评估。C-MTEB通过以下六个任务对中文文本嵌入进行评估:
Retrieval:这个任务评估模型在文本检索方面的性能,即模型如何在给定的查询下找到相关的文档或句子。
STS(Semantic Textual Similarity):这个任务评估模型在衡量两个文本片段之间语义相似度方面的性能。
PairClassification:这个任务评估模型在对句子对进行分类方面的性能,即判断两个句子是否属于同一类别或具有某种关系。
Classification:这个任务评估模型在文本分类方面的性能,即将文本分到预定义的类别或标签中。
Reranking:这个任务评估模型在重新排序方面的性能,即如何根据给定的查询和候选文档对候选文档进行重新排序。
Clustering:这个任务评估模型在文本聚类方面的性能,即如何将相似的文本分到同一个簇中。
通过这六个任务,C-MTEB能够全面地评估中文文本嵌入模型在不同的NLP应用场景下的性能,从而提供对模型性能的全面和深入的了解。这对于研究者和开发者来说是非常有价值的,因为它们可以更准确地了解模型的优势和局限性,从而进行更有效的模型选择和优化。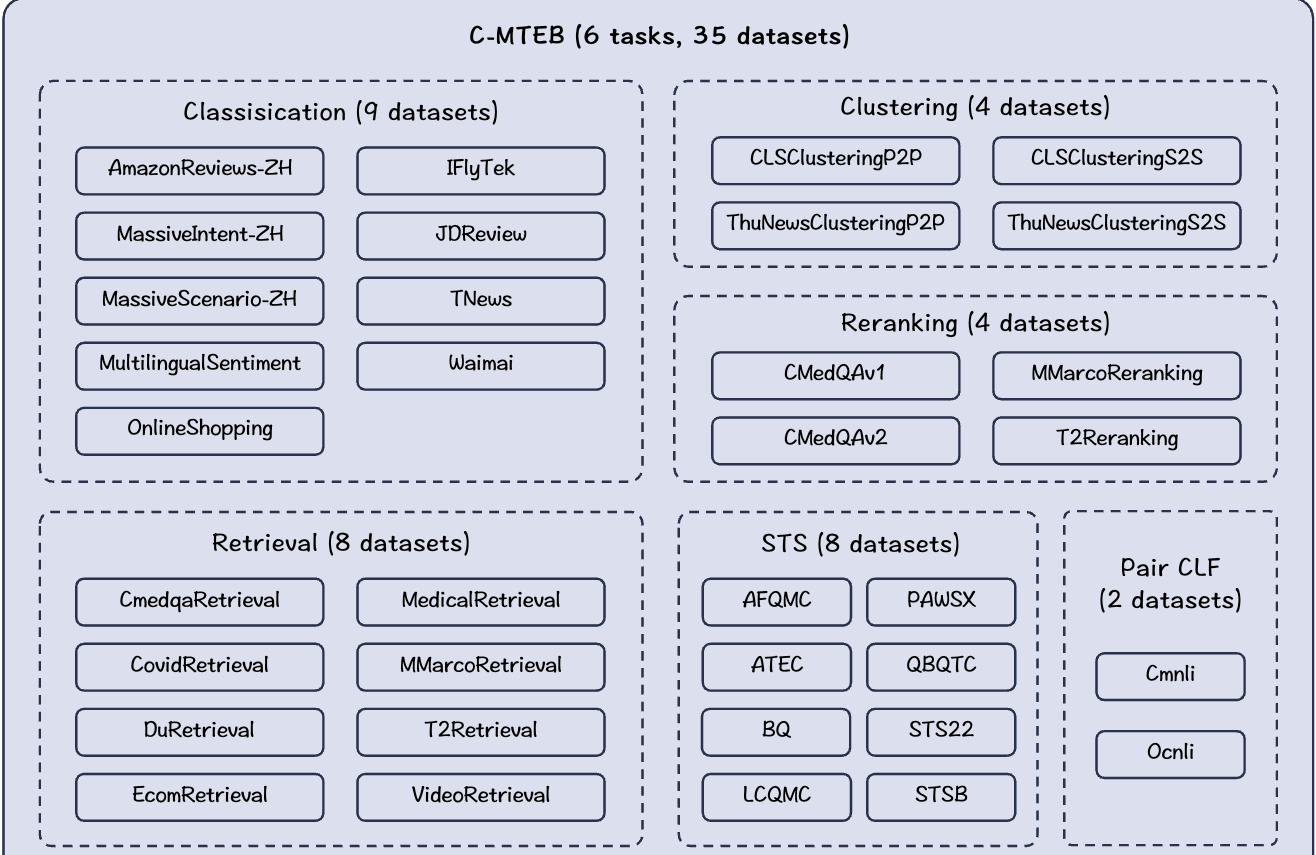
合合信息acge模型
acge模型来自于合合信息技术团队智能文字识别服务平台TextIn。这次最新发布的acge_text_embedding 模型属于Word Embeddings模型,适用于情感分析、文本生成等复杂的NLP任务。这一模型获得MTEB中文榜单(C-MTEB)第一的成绩,相关成果将有助于大模型更快速地在千行百业中产生应用价值。可以看到acge模型在分类、聚类任务准确率很高;应用场景广泛,在相似性检索、信息检索和推荐系统中都有很好的效果;模型在设计时考虑到不同行业,不算规模应用的需要,支持定制服务,满足多样化需求。不仅如此,与榜单前五名其他几个模型相比,acge模型占用资源少;模型输入长度较长,可以满足上下文关联的需求;支持可变输出维度,可以根据具体场景合理分配资源。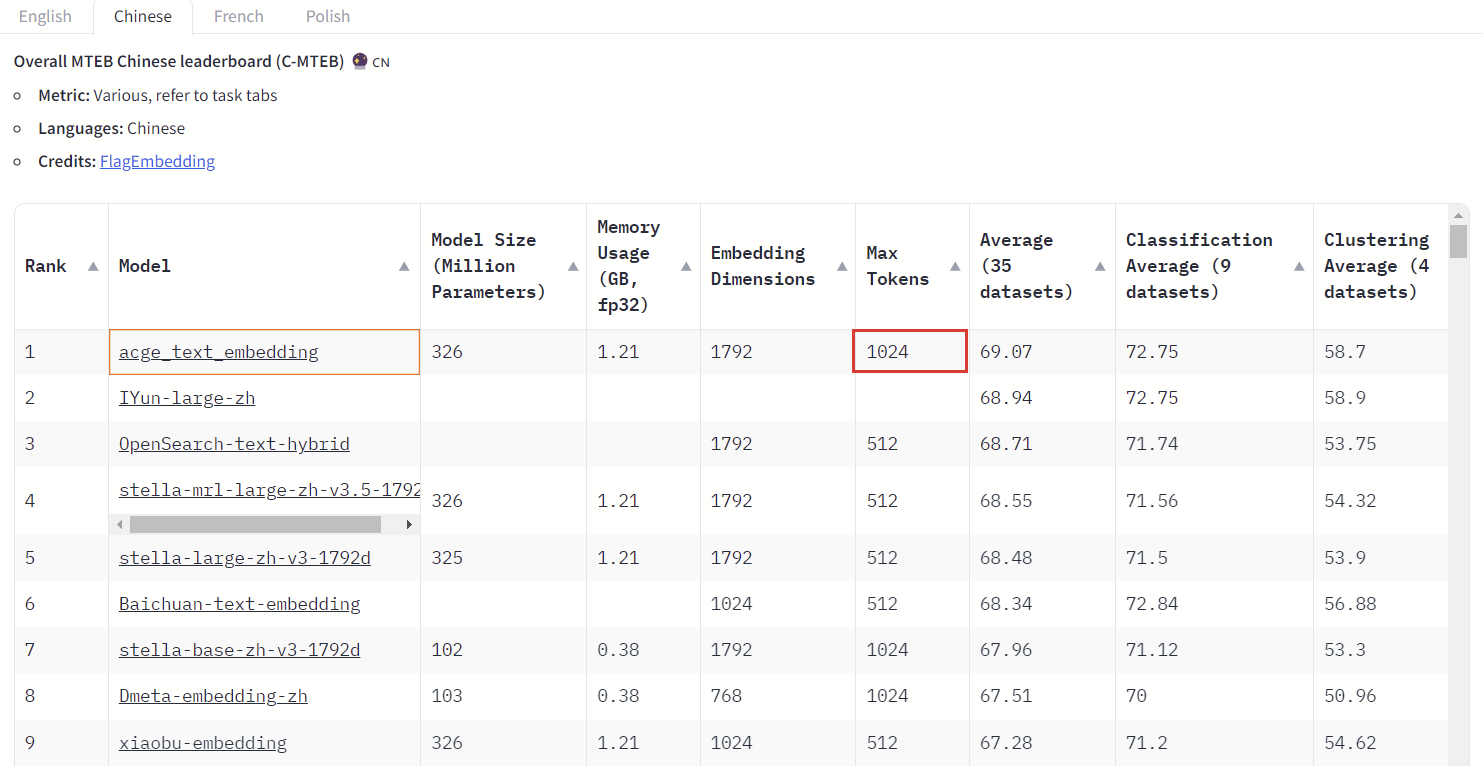
技术突破
合合信息算法团队在模型升级迭代过程中采取了多项措施,以克服行业中存在的技术难点,并不断优化Embedding模型的性能和效果。
数据集构建与优化:
技术人员积极收集和构建大量数据集,确保训练数据的质量和多样性。这些数据集覆盖了多种场景和应用,有助于模型在不同领域中的泛化能力和适应性;数据集的构建还注重覆盖不同的场景和语境,以确保模型能够处理多样化的输入,并准确地捕捉数据的语义特征和关系。
模型训练策略优化:
引入多种有效的模型调优技术,如Matryoshka训练方式。这种训练方式能够在一次训练中获取不同维度的表征提取,从而有效地提高模型的训练效率和参数收敛速度;采用策略学习训练方式,针对不同任务进行有针对性的学习,特别是在检索、聚类、排序等任务上,显著提升了模型的性能和效果;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题。这种训练方式使得模型在迭代训练过程中能够保持对先前学习任务的记忆,并在不断学习新知识的同时保持模型的整体性能。
Demo 体验
接下来我们使用acge模型使的sentence_transformers 库对给定的句子列表进行向量化,并计算句子之间的相似度。下面是代码的详细步骤描述:
- 首先我们定义一个包含两个句子的列表 sentences。:
sentences = ["数据1", "数据2"]
- 之后使用 'acge_text_embedding' 预训练模型初始化 SentenceTransformer 对象,并将其赋值给 model 变量。
model = SentenceTransformer('acge_text_embedding')
- 接下来使用 model.encode() 方法对 sentences 列表中的句子进行向量化,得到两组嵌入向量 embeddings_1 和 embeddings_2。normalize_embeddings=True 参数表示归一化这些向量,使其长度为1。
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
- 最后计算两组向量 embeddings_1 和 embeddings_2 之间的相似度。@ 符号表示矩阵乘法,embeddings_2.T 表示 embeddings_2 的转置矩阵。这将得到一个相似度矩阵 similarity,其中 similarity[i][j] 表示 sentences[i] 和 sentences[j] 之间的余弦相似度。
similarity = embeddings_1 @ embeddings_2.T
详细代码如下:
from sentence_transformers import SentenceTransformer
sentences = ["我喜欢这本书", "我很爱读这本书"]
model = SentenceTransformer('acge_text_embedding')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
总结
随着技术的不断进步和创新,acge_text_embedding 致力于维持其在业界的领先地位,同时推动文本处理技术的进一步发展。对于关心或依赖文本智能处理技术的个人和企业来说,了解和使用 acge_text_embedding 将是提升效率和智能化水平的有效方案。通过深入探索 acge_text_embedding 的多维优势,希望本文能帮助各位在日益复杂的数据世界中找到简单、高效的解决方案。