2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
一、背景

如果要人们评选当今最受关注话题的top10榜单,雾霾一定能够入选。如今走在北京街头,随处可见带着厚厚口罩的人在埋头前行,雾霾天气不光影响了人们的出行和娱乐,对于人们的健康也有很大危害。本文通过爬取并分析北京一年来的真实天气数据,挖掘出二氧化氮是跟雾霾天气(这里指的是PM2.5)相关性最强的污染物,从而为您揭秘形成雾霾的罪魁祸首。
这里我们是用阿里云机器学习平台来完成实验:
https://data.aliyun.com/product/learn
登陆阿里云机器学习平台,即可在demo页选择实验并且亲手实现整个机器学习的预测分析,完全零门槛。 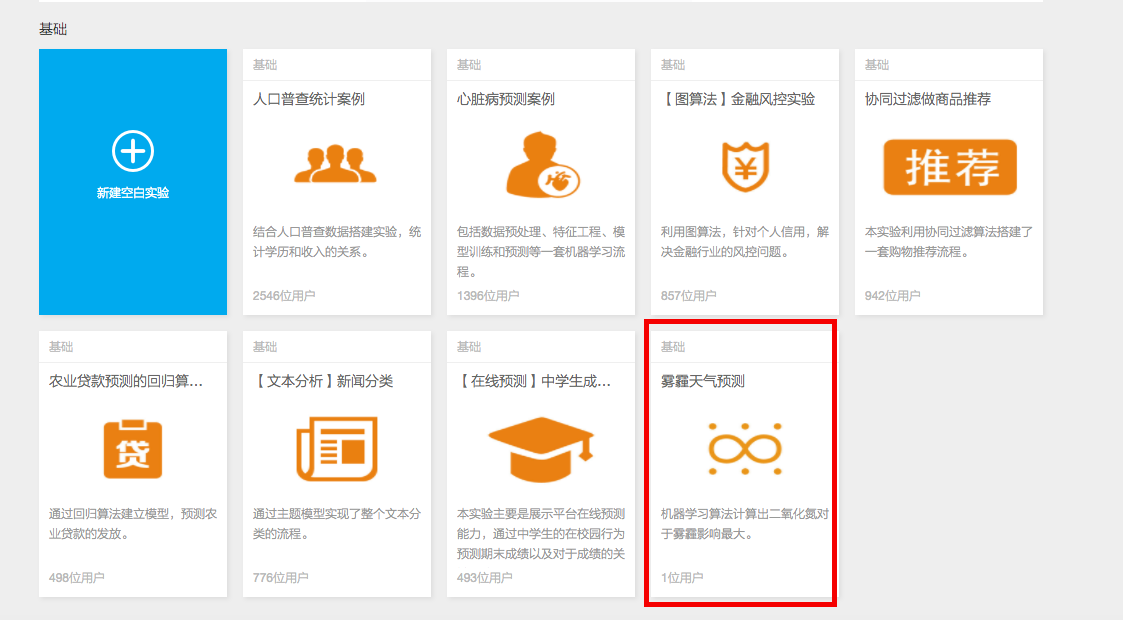
底层计算引擎-阿里云数加MaxCompute:https://www.aliyun.com/product/odps
二、数据集介绍
数据源:采集了2016全年的北京天气指标。
采集的是从2016年1月1号以来每个小时的空气指标,。具体字段如下表:
| 字段名 | 含义 | 类型 |
|---|---|---|
| time | 日期,精确到天 | string |
| hour | 表示的是时间,第几小时的数据 | string |
| pm2 | pm2.5的指标 | string |
| pm10 | pm10的指标 | string |
| so2 | 二氧化硫的指标 | string |
| co | 一氧化碳的指标 | string |
| no2 | 二氧化氮的指标 | string |
三、数据探索流程
阿里云机器学习平台采用拖拉算法组件拼接实验的操作方式,先来看下整个实验流程: 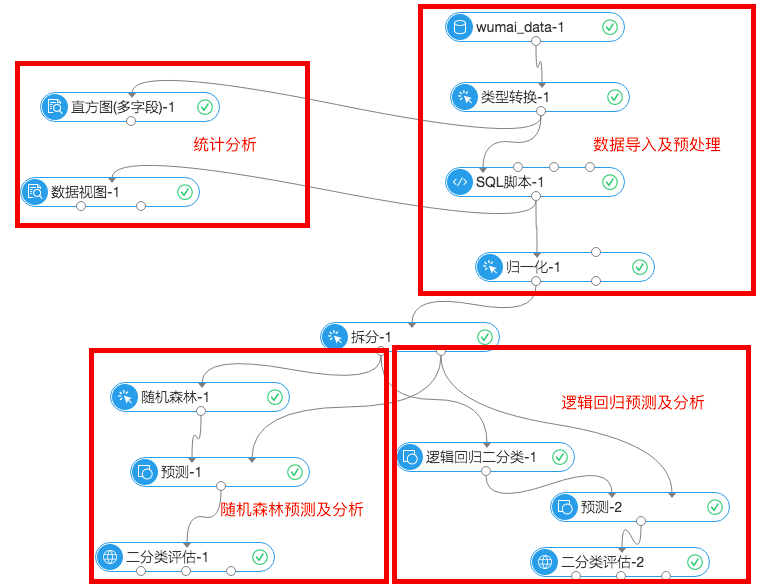
我们把整个实验拆解成四个部分,分别是数据导入及预处理、统计分析、随机森林预测及分析、逻辑回归预测及分析。下面我们分别介绍一下这四个模块的逻辑。
1.数据导入及预处理
(1)数据导入
在“数据源”中选择“新建表”,可以把本地txt文件上传。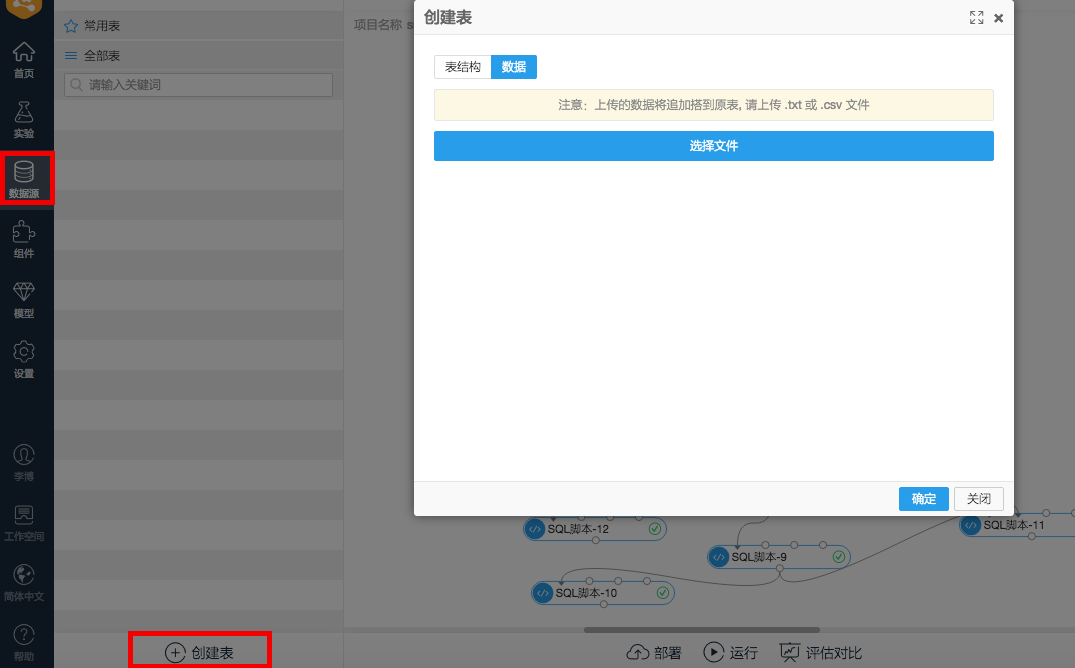
数据导入后查看: 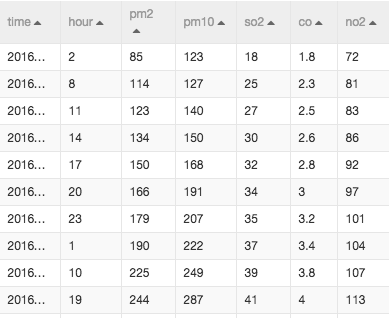
(2)数据预处理
通过类型转换把string型的数据转double。把pm2这一列作为目标列,数值超过200的情况作为重度雾霾天气打标为1,低于200标为0,实现的SQL语句如下。
select time,hour,(case when pm2>200 then 1 else 0 end),pm10,so2,co,no2 from ${t1}; (3)归一化
归一化主要是去除量纲的作用,把不同指标的污染物单位统一。 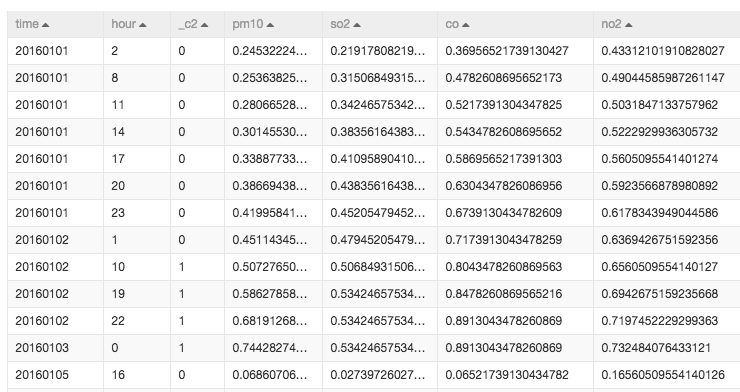
2.统计分析
我们在统计分析的模块用了两个组件:
(1)直方图
通过直方图可以可视化的查看不同数据在不同区间下的分布。通过这组数据的可视化展现,我们可以了解到每一个字段数据的分布情况,以PM2.5为例,数值区间出现最多的是11.74~15.61,一共出现了430次。 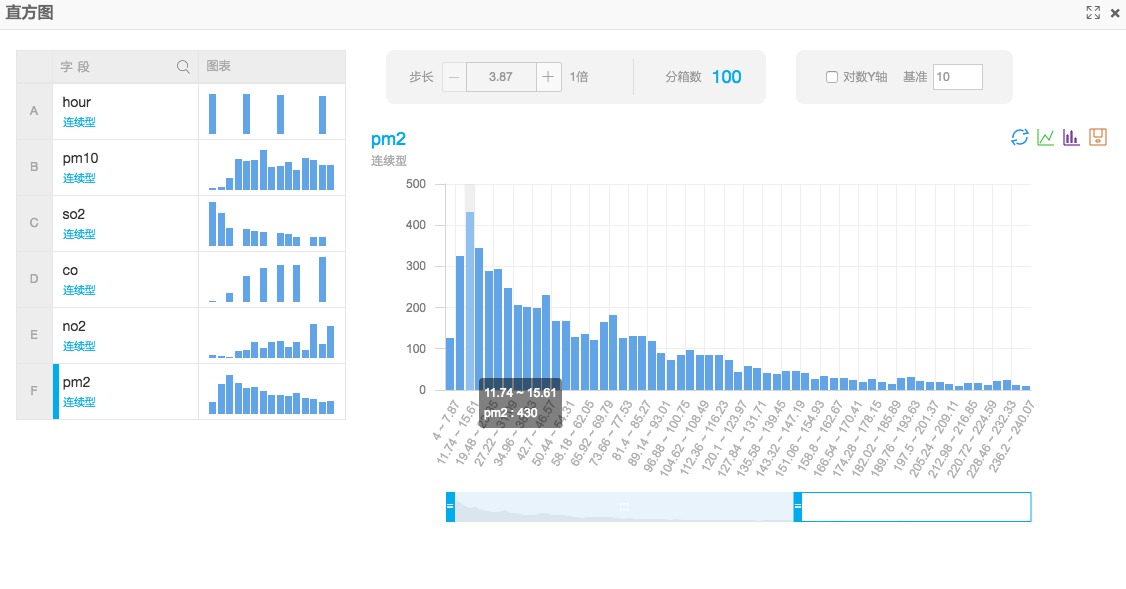
(2)数据视图
通过数据视图可以查看不同指标的不同区间对于结果的影响。 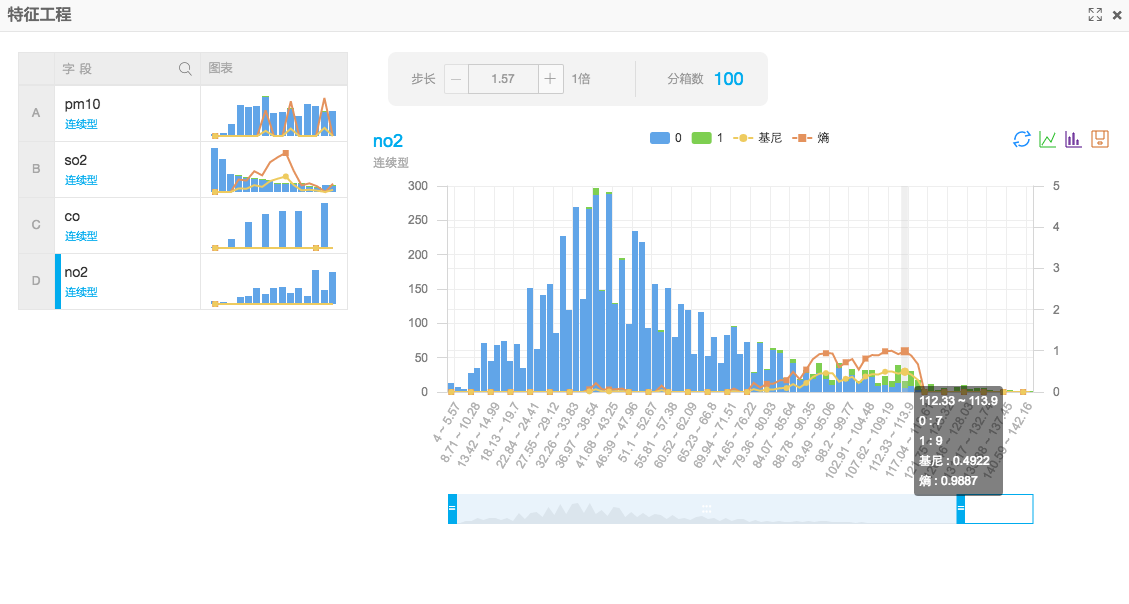
以no2为例,在112.33~113.9这个区间产生了7个目标列为0的目标,产生了9个目标列为1的目标。也就是说当no2为112.33~113.9区间的情况下,出现重度雾霾的天气的概率是非常大的。熵和基尼系数是表示这个特征区间对于目标值的影响,数值越大影响越大,这个是从信息量层面的影响。
3.随机森林预测及分析
本案其实是采用了两种不同的算法对于结果进行预测,我们先来看看随机森林这一分支。我们通过将数据集拆分,百分之八十的数据训练模型,百分之二十的数据预测。最终模型的呈现可以可视化的显示出来,在左边模型菜单下查看,随机森林是树状模型。 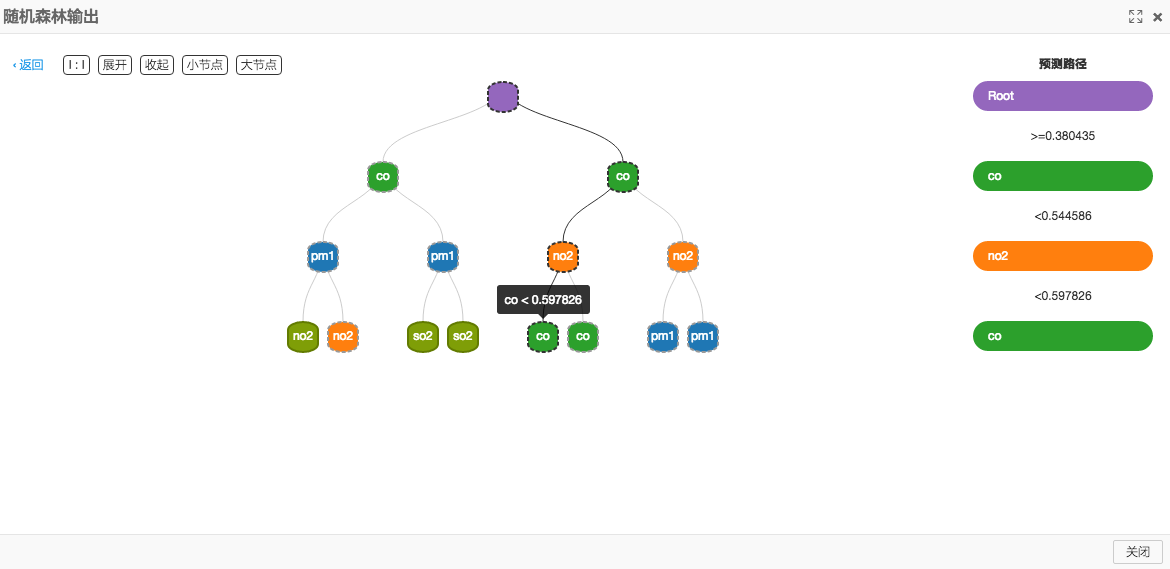
通过这个模型预测结果的准确率: 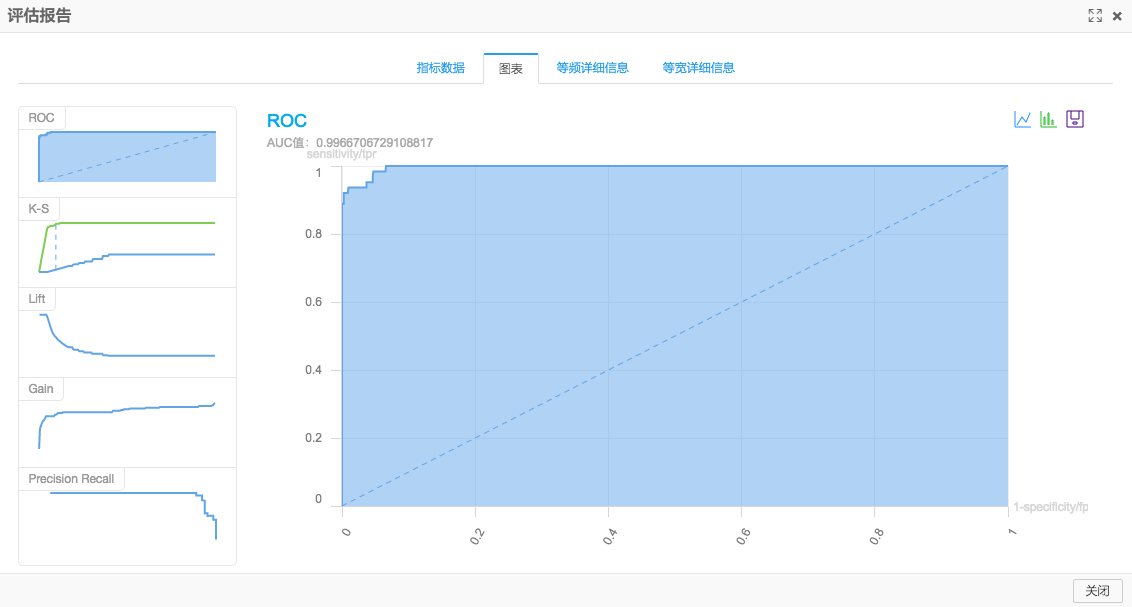
我们看到AUC是0.99,也就是说如果我们有了本文用到的天气指标数据,就可以预测天气是否雾霾,而且准确率可以达到百分之九十以上。
4.逻辑回归预测及分析
再来看下逻辑回归这一分支的预测模型,逻辑回归是线性模型: 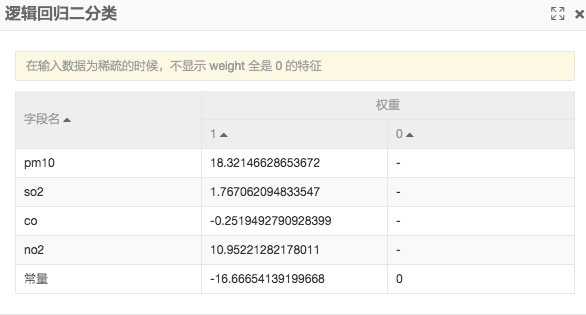
模型预测准确率: 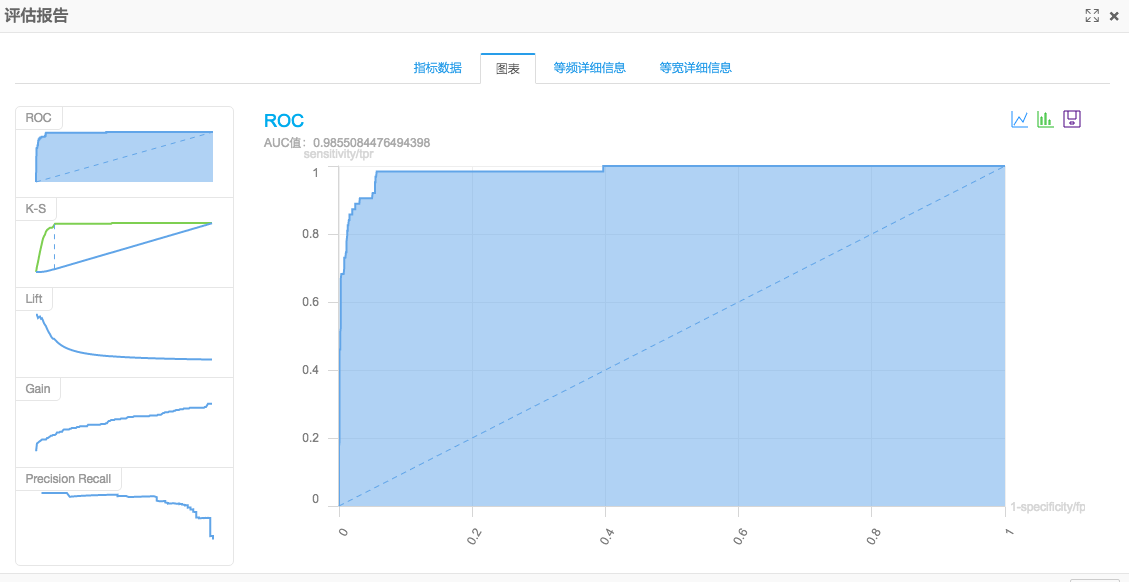
逻辑回归的AUC为0.98,比用随机森林计算得到的结果略低一点。如果排除调参对于结果的影响因素,可以说明针对这个数据集,随机森林的训练效果会更好一点。
四、结果评估
上面介绍了如何通过搭建实验来搭建针对PM2.5的预测流程,准确率达到百分之九十以上。下面我们来分析一下哪种空气指标对于PM2.5影响最大,首先来看下逻辑回归的生成模型:
因为经过归一化计算的逻辑回归算法有这样的特点,模型系数越大表示对于结果的影响越大,系数符号为正号表示正相关,负号表示负相关。我们看一下正号系数里pm10和no2最大。pm10和pm2只是颗粒尺寸大小不同,是一个包含关系,这里不考虑。剩下的no2(二氧化氮)对于pm2.5的影响最大。我们只要查阅一下相关文档,了解下哪些因素会造成no2的大量排放即可找出影响pm2.5的主要因素。
下面网上是找到的关于no2排放的论述,文中说明了no2主要来自电厂和汽车尾气。no2来源文章
五、其它
作者微信公众号(与作者讨论): 
参与讨论:云栖社区公众号
免费体验:阿里云数加机器学习平台
MaxCompute:https://www.aliyun.com/product/odps
阿里云大数据公众号:https://yq.aliyun.com/teams/6?spm=5176.100244.teamlist.17.SRj3O7
