- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 ?,持续学习,持续干货输出。
- 一起交流?,一起进步?。
- 微信公众号也可搜【同学小张】 ?
本站文章一览:

前面我们学习了RAG的基本框架并进行了实践,我们也知道使用它的目的是为了改善大模型在一些方面的不足:如训练数据不全、无垂直领域数据、容易出现幻觉等。那么如何评估RAG的效果呢?本文我们来了解一下。
推荐前置阅读
0. RAG效果评估的必要性
- 评估出RAG对大模型能力改善的程度
- RAG优化过程,通过评估可以知道改善的方向和参数调整的程度
1. RAG评估方法
1.1 人工评估
最Low的方式是进行人工评估:邀请专家或人工评估员对RAG生成的结果进行评估。他们可以根据预先定义的标准对生成的答案进行质量评估,如准确性、连贯性、相关性等。这种评估方法可以提供高质量的反馈,但可能会消耗大量的时间和人力资源。
1.2 自动化评估
自动化评估肯定是RAG评估的主流和发展方向。
1.2.1.1 LangSmith
在我的这篇文章中 【AI大模型应用开发】【LangSmith: 生产级AI应用维护平台】1. 快速上手数据集与测试评估过程 介绍了如何使用LangSmith平台进行效果评估。
- 需要准备测试数据集
- 不仅可以评估RAG效果,对于LangChain中的Prompt模板等步骤都可进行测试评估。

1.2.1.2 Langfuse
Langfuse作为LangSmith的平替,也具有自动化评估的功能。在我的这篇文章中 【AI大模型应用开发】【LangFuse: LangSmith平替,生产级AI应用维护平台】0. 快速上手 - 基本功能全面介绍与实践(附代码) 介绍了如何使用Langfuse平台进行效果评估。
- 需要准备测试数据集
- 不仅可以评估RAG效果,对于LangChain中的Prompt模板等步骤都可进行测试评估。
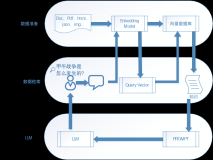
以上两个平台对RAG的评估,都可以自定义自己的评估函数。当然其也支持一些内置的评估函数。
1.2.1.3 Trulens
TruLens是一款旨在评估和改进 LLM 应用的软件工具,它相对独立,可以集成 LangChain 或 LlamaIndex 等 LLM 开发框架。它使用反馈功能来客观地衡量 LLM 应用的质量和效果。这包括分析相关性、适用性和有害性等方面。TruLens 提供程序化反馈,支持 LLM 应用的快速迭代,这比人工反馈更快速、更可扩展。
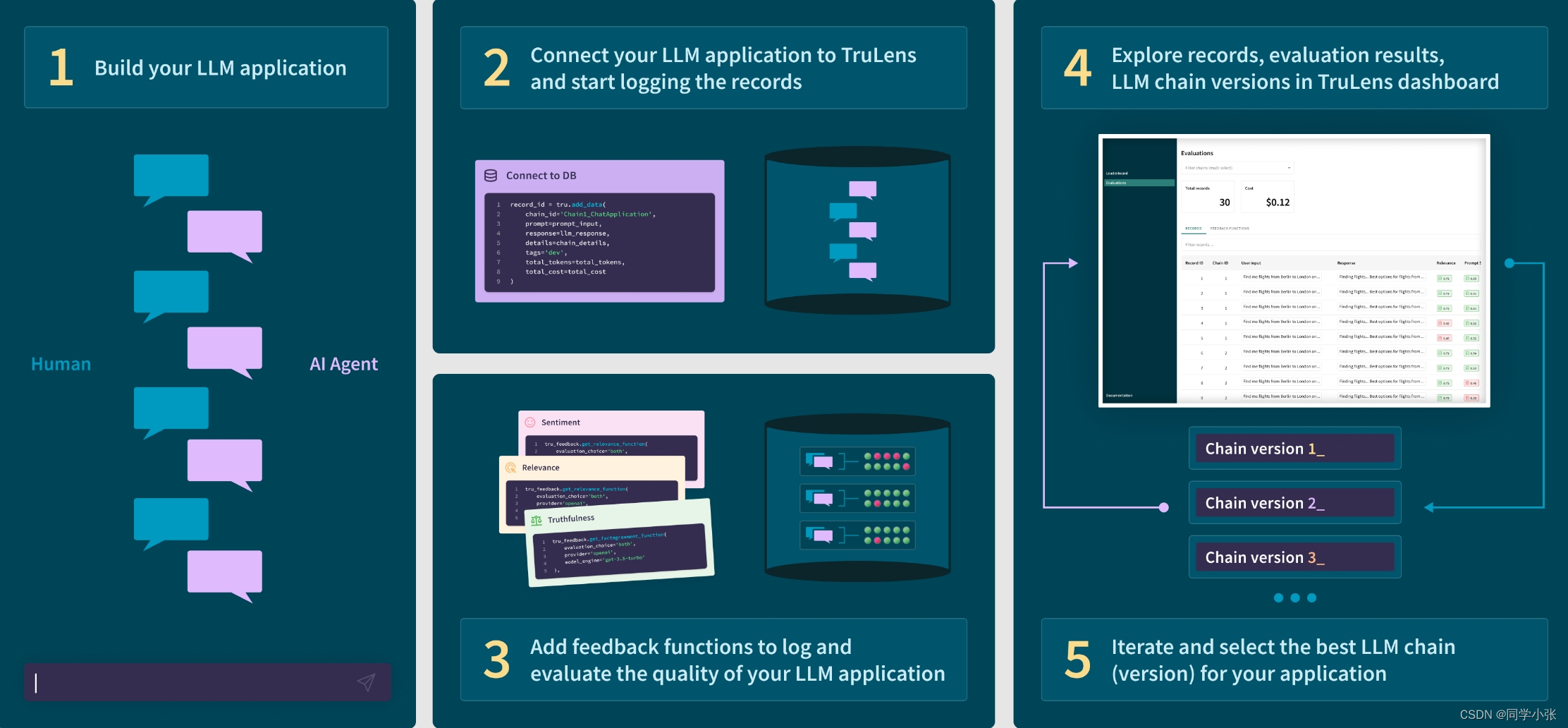
使用的步骤:
(1)创建LLM应用
(2)将LLM应用与TruLens连接,记录日志并上传
(3)添加 feedback functions到日志中,并评估LLM应用的质量
(4)在TruLens的看板中可视化查看日志、评估结果等
(5)迭代和优化LLM应用,选择最优的版本
其对于RAG的评估主要有三个指标:
- 上下文相关性(context relevance):衡量用户提问与查询到的参考上下文之间的相关性
- 忠实性(groundedness ):衡量大模型生成的回复有多少是来自于参考上下文中的内容
- 答案相关性(answer relevance):衡量用户提问与大模型回复之间的相关性

其对RAG的评估不需要有提前收集的测试数据集和相应的答案。
1.2.4 RAGAS
考虑标准的RAG设置,即给定一个问题q,系统首先检索一些上下文c(q),然后使用检索到的上下文生成答案as(q)。在构建RAG系统时,通常无法访问人工标注的数据集或参考答案,因此该工作将重点放在完全独立且无参考的度量指标上。
四个指标,与Trulens的评估指标有些类似:
- 评估检索质量:
- context_relevancy(上下文相关性,也叫 context_precision)
- context_recall(召回性,越高表示检索出来的内容与正确答案越相关)
- 评估生成质量:
- faithfulness(忠实性,越高表示答案的生成使用了越多的参考文档(检索出来的内容))
- answer_relevancy(答案的相关性)

2. 常用评估指标
在上文评估方法中已经介绍了几种常用的评估指标:
2.1 Trulens 的RAG三元组指标
- 上下文相关性(context relevance):衡量用户提问与查询到的参考上下文之间的相关性
- 忠实性(groundedness ):衡量大模型生成的回复有多少是来自于参考上下文中的内容
- 答案相关性(answer relevance):衡量用户提问与大模型回复之间的相关性
2.2 RAGAS的四个指标
四个指标,与Trulens的评估指标有些类似:
- 评估检索质量:
- context_relevancy(上下文相关性,也叫 context_precision)
- context_recall(召回性,越高表示检索出来的内容与正确答案越相关)
- 评估生成质量:
- faithfulness(忠实性,越高表示答案的生成使用了越多的参考文档(检索出来的内容))
- answer_relevancy(答案的相关性)
2.3 其它指标
(1)噪声鲁棒性(Noise Robustness)
衡量从噪声文档中提取有用的信息能力。在现实世界中,存在大量的噪声信息,例如假新闻,这给语言模型带来了挑战。
(2)否定拒绝(Negative Rejection)
当检索到的文档不足以支撑回答用户的问题时,模型应拒绝回答问题,发出"信息不足"或其他拒绝信号。
(3)信息整合(information integration)
评估模型能否回答需要整合多个文档信息的复杂问题,即,当一个问题需要查找多个文档,综合信息之后才能回答时,模型的表现。
(4)反事实鲁棒性(CounterfactualRobustness)
模型能否识别检索文档中已知事实错误的能力,即当索引的文档信息原本就是与事实相背时,大模型能否识别出不对。

3. 总结
本文主要总结了当前比较流行的评估方法和指标。当前AI技术的快速发展,RAG和RAG评估是当前比较有前景的发展方向,不断有新的评估工具和理论被提出,让我们持续跟进,了解这些工具和理论,从而在使用时知道如何选择。
参考
- https://mp.weixin.qq.com/s/Si8rb0L1uqMiwoQ1BWS0Sw
- https://mp.weixin.qq.com/s/z18J2l_b-VsKDhOd6-nIsg
- https://mp.weixin.qq.com/s/YFji1s2yT8MTrO3z9_aI_w
- https://mp.weixin.qq.com/s/TrXWXkQIYTVsS1o4IZjs9w
- https://maimai.cn/article/detail?fid=1816656853&efid=TVdhzg972NYV9Q1MyFBqqg
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 ?,持续学习,持续干货输出。
- 一起交流?,一起进步?。
- 微信公众号也可搜【同学小张】 ?
本站文章一览:


![[译][AI OpenAI] 引入 GPT-4o 及更多工具至免费版 ChatGPT 用户](https://ucc.alicdn.com/pic/developer-ecology/tbo73ymmu5nmu_f91a4c16f5a84cd1bd63cd453fee0efd.png?x-oss-process=image/resize,h_160,m_lfit)