2024年4月18-19日,2024中国生成式AI大会在北京JW万豪酒店举行,阿里云高级技术专家、阿里云异构计算AI推理团队负责人李鹏受邀在【AI Infra】专场发表题为《AI基础设施的演进与挑战》的主题演讲。李鹏从AIGC对云基础设施的挑战、如何进一步释放云上性能、AIGC场景下训练和推理最佳实践三个方向逐一展开分享。
大模型的发展给计算体系结构带来了功耗墙、内存墙和通讯墙等多重挑战。其中,大模型训练层面,用户在模型装载、模型并行、通信等环节面临各种现实问题;在大模型推理层面,用户在显存、带宽、量化上面临性能瓶颈。
对于如何更好地释放云上性能助力AIGC应用创新?“阿里云弹性计算为云上客户提供了ECS GPU DeepGPU增强工具包,帮助用户在云上高效地构建AI训练和AI推理基础设施,从而提高算力利用效率。”李鹏介绍到。目前,阿里云ECS DeepGPU已经帮助众多客户实现性能的大幅提升。其中,LLM微调训练场景下性能最高可提升80%,Stable Difussion推理场景下性能最高可提升60%。
以下是全文内容,供阅览。

李鹏 阿里云高级技术专家 & 阿里云异构计算AI推理团队负责人
从2023年开始,生成式AI爆发,文生视频、文生图、文生文等场景有很多大模型/通用大模型产生,我也和我们的产品团队、架构师团队一起与阿里云客户做过多次技术分享交流,看到了企业客户开始逐渐将生成式AI技术应用到实际的业务当中。

从我的感受来讲,如今越来越多的云上客户拥抱生成式AI的场景,大模型的接受度也越来越高,比如电子商务、影视、内容资讯和办公软件、游戏等典型的行业。

上图左侧是2024GTC大会上展示的一张关于模型发展对算力需求的曲线图。从2018年开始这条绿色曲线,从Transformer模型、到如今的GPT、再到最新的1.8万亿参数大模型,对算力需求呈现了10倍规模递增的爆炸性增长,训练场景对算力的需求非常大。
另外根据估算,如果要训练一个GPT-3、1750亿参数的模型,训练的计算量大概在3640 PFLOP * 天,对芯片的需求大概需要1024张A100跑一个月的时间,这是一个相当大的千卡规模,换算到成本上则是一笔非常巨大的计算开销。总体来说,当前阶段的GPU算力价格相对较贵,再到推理/微调本身的算力需求和成本,也可以看到部署的成本也比较高,开销同样较大。
AIGC对云基础设施的挑战

谈到大模型发展对体系结构的挑战,首先看到的是功耗墙的问题。以NVIDIA GPU举例,2017年开始,V100的功耗只有250瓦,递增到A100功耗接近400瓦,H100功耗700瓦,到最新B200功耗大概到了1000瓦,算力成倍增长,计算功耗也会增加的越来越多。最近业界也有许多讨论说到AI的尽头是能源,随着计算需求的增大,会带来能源上更大的需求。
第二个体系结构挑战就是内存墙。所谓内存墙,计算过程数据在CPU和GPU之间会做搬移/交换,如今PCIE的体系结构逐渐成为数据交换和传输的瓶颈。可以看到,像NVIDIA也在Grace Hopper架构上推出了NVlink C2C方案,能够大幅提升整个数据传输的速率。
第三个是通讯墙。尤其对于训练来说,分布式训练规模还是非常大的,从去年的千卡规模到了如今万卡甚至十万卡规模,分布式训练场景下如何增加机器之间的互联带宽也是一个巨大的挑战。从国内外各个厂商的一些进展来看,在A100上会采用800G互联的带宽,在H100上会有3.2T带宽,也就是更大的互联带宽。所以现在看到的趋势就是硬件堆砌的趋势,总结下来就是会有更大的显存、更高的显存带宽,还有更高的CPU和GPU之间的互联带宽,最后还有PCIE本身的向下迭代。
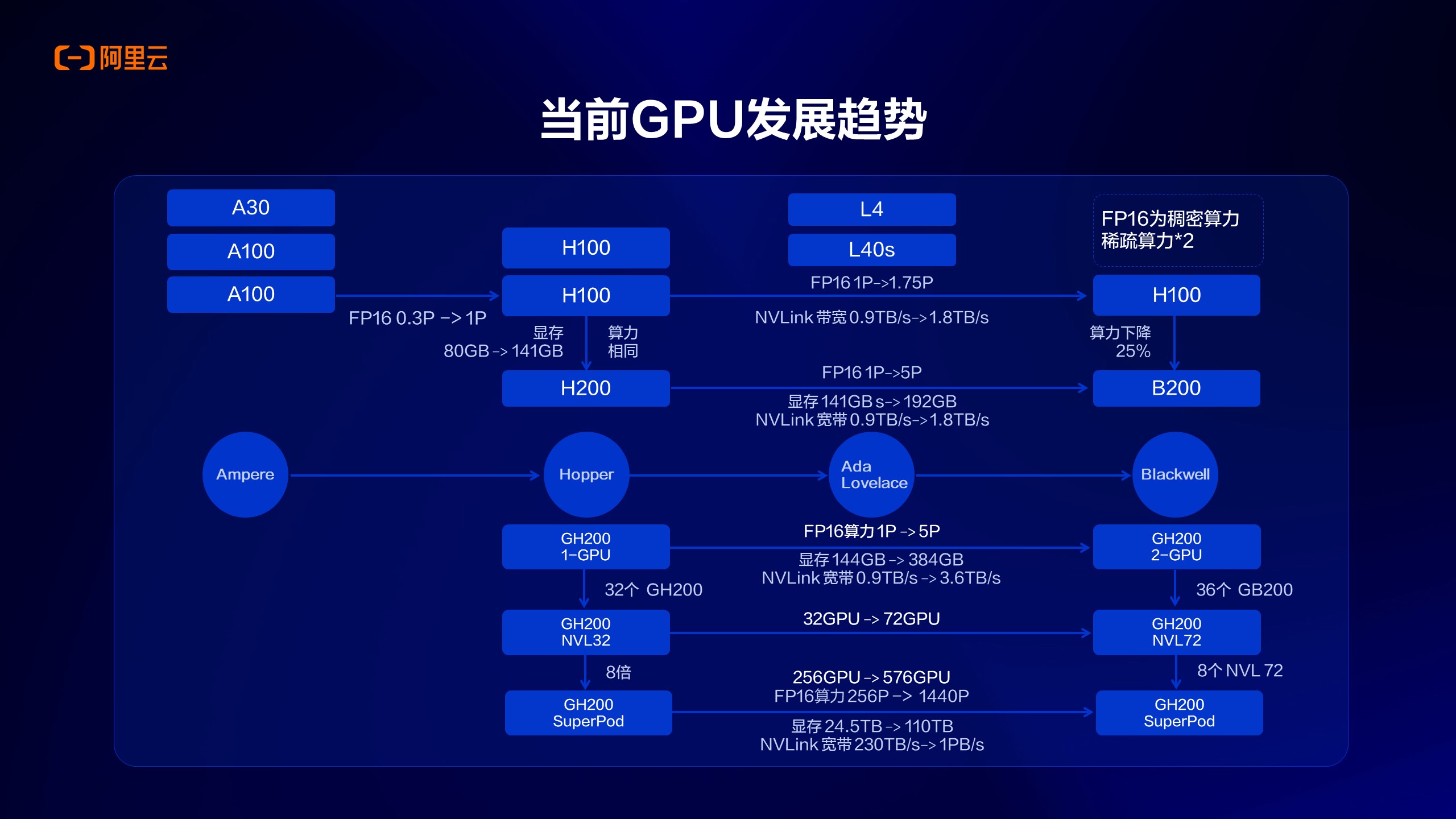
上图是以NVIDIA GPU举例,展示了Ampere从这一代架构开始到后面的Blackwell芯片的一些特点变化,体现在算力维度就是计算规模会越来越高,过往的不到1PFlops、如今要到1P以上,且显存大小也会越来越大,从前的80G到如今的100G+的规模;显存带宽也是非常重要的指标,也在不断增加,这也反映了未来硬件、尤其是AI计算上硬件规格的变化。
如何释放云上性能?

对于大模型训练的技术栈,由AI训练算法与软件、Ai训练硬件资源两个部分构成。
- 当前,主要是模型结构(主要是Transformer结构)、海量级数据以及梯度寻优算法,这三块构成AI训练的软件和算法。
- AI硬件就是GPU的计算卡,从单卡扩展到服务器(如8卡),再扩展到更大的服务器集群,做成千卡/万卡的规模,构成整个大模型训练硬件的计算资源。

大模型训练过程中有一个典型的现实问题:模型的加载和并行。以GPT 175B的模型举例来说,它需要的显存规模就训练来说大概需要2800G,上图是以A100 80G为例,要解决的问题是我们需要多少张卡装载这个模型,装载模型后还需要如何去把训练效率提升,这就需要用模型并行技术来解决。
另外,还有互联的问题,互联有单机内部互联(NVlink),还有机器与机器之间的互联网络,这对于分布式训练来说非常重要,因为会在通信上产生一些开销。

- 大模型训练当中的模型装载
以175B模型为例,以FP16精度计算,模型参数大概350G显存,模型梯度也需要350G,优化器需要的显存规模大概在2100GB,合并起来大概是2800GB的规模,如今分布式训练的框架也有比较成熟的方案,像NVIDIA做的Megatron-LM和微软开发的DeepSpeed Zero算法,能够解决模型装载和并行的问题。

- 大模型训练的并行方式
在大模型训练方式上,业界也有比较多的并行技术可以帮助提升训练效率,比如张量并行、流水线并行、数据并行等等。
- TP是张量并行(Tensor Parallel) ,是对模型的每个层做了一个层内的拆分。使用TP能达到很好的 GPU 利用率。TP通信粒度是非常细的。TP 每计算完成一次层的拆分,就需要有一次通信来做AllReduce合并,虽然 TP 单次通信量较小,但是它通信频率频次都很高,对带宽的要求也很高。
- PP是流水线并行(Pipeline Parallel),也就是模型的层与层之间拆分,把不同的层放到不同的 GPU 上。在计算过程中,必须顺序执行,后面的计算过程依赖于前面的计算结果。一个完整的 Pipeline运行起来需要将一个workload 切分成很小的多个 Workload,也就是需要将一个比较大 Batch size 切分成很多个小 Batch 才能保持流水线并行的高吞吐。
- DP是数据并行(Data Parallel),数据并行是指将相同的参数复制到多个GPU上,通常称为“工作节点(workers)”,并为每个GPU分配不同的数据子集同时进行处理。数据并行需要把模型参数加载到单GPU显存里,而让多个GPU计算的代价就是需要存储参数的多个副本。更新数据并行的节点对应的参数副本时,需要协调节点以确保每个节点具有相同的参数。

在模型训练过程中, 尤其是分布式训练场景下, 我们还看到一些比较关键的问题,就是集合通信性能问题。比如,在Tensor 并行的切分当中,实际上会产生一些allreduce的操作,这些allreduce操作是夹杂在计算流当中的,会产生一个计算中断的问题,因此会带来计算效率的影响。现在有相应的集合通信算法,或者是一些优化实现被开发出来去解决集合通信性能的影响,上图截图中展示的是我们在做一些并行训练时发现的部分瓶颈。

在大模型推理时,我们需要关注三个方面:显存、带宽和量化。
- 显存,模型参数量大小决定了需要多少显存。
- 带宽,因为在大模型推理时实际上是访存密集型的计算方式,在计算当中需要频繁的访问显存,这种情况下带宽的规格是影响推理速度的首要因素。
- 量化,如今很多模型在发布时都会提供FP16精度的模型,还会给一些量化后的模型,低精度量化带来的效果是可以省下更多显存,也可以提高访存效率,因此现在很多大模型推理都会采用量化的方式。
总结来说:首先,大模型推理会有显存瓶颈;其次,在推理方面可以选择多卡推理,做TP方式切分,训练卡可以用在推理业务,且会有一些不错的效果。

上图展示的是我们在做一些模型微观性能分析时看到的一些状况,上面是典型的Tranformer结构,包含了像attention结构和MLP结构。在这些算子里面,我们通过微观的分析可以看到,大部分的计算都是矩阵乘运算,就是GEMM的操作,实际有85%的耗时都是访存,主要是去做显存的读取。
大模型推理本身是自回归的方式,上一个生成出来的token会用在下一个token的计算,基本都是访存密集型计算。总结来说基于这些行为,在优化时我们会把attention结构的许多算子以及MLP的算子分别融合成大的算子,这样会显著提高计算效率。

在大模型推理带宽需求方面,以LLaMA 7B在A10或者A100上的对比为例:如上图,红色曲线代表的是A100 VS A10 QPS的比例关系,在不同batchsize下,红色曲线基本上是一条水平的线,这从侧面印证了大模型推理基本是一个访存密集型的操作,它的上限是由GPU的HBM显存带宽决定的。

除此之外,在大模型推理时的一些通信性能也需要特别关注。这里强调一下通信性能是指单机内部多卡通信。举例来说跑一个LLaMA 70B的模型,是没办法在A10一张卡上装载,需要至少8张卡的规格才能把这个模型装载下来,因为计算时做了TP切分,每张卡算一部分,计算完成后需要AllReduce通信的操作,我们针对通信开销做了一些性能分析,最明显的是推理卡上,A10通信开销占比是比较高的,能够达到整个端到端性能开销的31%,这个开销占比还是很高的,因此需要在这方面重点关注。
那如何优化通信的开销?通常来说比较直观的方法是如果有卡和卡之间的Nvlink互联,性能自然会有提升,因为Nvlink互联带宽还是比较高的。另外,如果GPU卡没有像A100这样的Nvlink,则需要走PCIE P2P通信,这种通信方式也会从一方面帮助提高通信性能,在阿里云上我们团队通过亲和性分配调优,摸索出一套优化方法,能够在4卡、8卡场景下把通信开销占比进一步优化,实现开销下降。

从今年年初OpenAI发布Sora之后,国外已经有机构给出了关于Sora这样视频模型算力需求的分析,因为它的模型结构和原来文生图的模型结构有区别,其中较为显著的区别是原来的Unet结构变成了diffusion Transformer的结构,通过结构上的变化和一些算力的估算,可以看到Sora视频模型不管是在训练和推理上都会有比较大的算力需求。
上图展示的就是国外某研究机构给出的算力需求,他们估算如果要训练Sora这样一个模型大概需要4000-10000张H100训练一个月,基本能训练出Sora这样的模型。在推理上这个需求也会比传统的大语言模型来得更高,估算结果是如果我们要生成像Sora这样的5分钟长视频,大概需要一张H100推理一个小时的时间,所以算力的需求还是非常高的。

下面为大家介绍一下阿里云弹性计算为云上客户在AI场景下提供的基础产品增强工具包DeepGPU,这是针对生成式AI场景为用户提供的软件工具和解决方案,旨在帮助用户在云上构建训练/推理的AI基础设施时,提高其在使用GPU上训练和推理的效率。因为,目前普遍AI算力还较为昂贵,我们需要用工具包的方式帮助用户优化他们使用GPU的效率,同时我们也会提供像文生图和文生文等场景下的解决方案。目前,阿里云ECS DeepGPU已经帮助众多客户实现性能的大幅提升。其中,LLM微调训练场景下性能最高可提升80%,Stable Difussion推理场景下性能最高可提升60%。
AIGC场景下训练和推理最佳实践

上图展示的是关于SD文生图场景下的微调训练案例,我们可以通过DeepGPU和阿里云GPU云服务器结合在一起,在客户的SD微调场景下,帮助客户提升15%-40%的端到端性能。

第二个是关于大语言模型场景的微调案例,可以看到有些客户想做一个垂直领域/垂直场景下的大模型,会有模型微调的需求。针对这一类模型微调需求,我们会做一些针对性的解决方案/优化方案,客户通过软硬结合的优化方法,性能最高可提升80%。

最后是关于大语言模型推理的客户案例。这个客户主要是做智能业务问答/咨询类业务,我们为客户在端到端的场景里面提供了方案,包括云服务器、容器环境、AI套件、DeepGPU等产品,帮助客户优化整个端到端的推理性能,最终帮助客户提升近5倍的端到端的请求处理/推理的效率。
以上就是本次分享的全部内容,也欢迎大家持续关注阿里云的产品,谢谢。