fast.ai 深度学习笔记(一)(2)/article/1482674
深度学习 2:第 1 部分第 2 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-2-eeae2edd2be4译者:飞龙
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
第 2 课
上一课的回顾[01:02]
- 我们用 3 行代码构建了一个图像分类器。
- 为了训练模型,数据需要以一定方式组织在
PATH(在本例中为data/dogscats/)下:

- 应该有一个
train文件夹和一个valid文件夹,每个文件夹下面都有带有分类标签的文件夹(例如本例中的cats和dogs),其中包含相应的图像。 - 训练输出:[
*epoch #*,**training loss*,*validation loss*,*accuracy*]
''' [ 0\. 0.04955 0.02605 0.98975] '''
学习率[4:54]
- 学习率的基本思想是它将决定我们快速地聚焦在解决方案上。

- 如果学习率太小,将需要很长时间才能到达底部
- 如果学习率太大,它可能会从底部摆动。
- 学习率查找器(
learn.lr_find)会在每个小批次后增加学习率。最终,学习率会变得太高,损失会变得更糟。然后,我们查看学习率与损失的图表,并确定最低点,然后后退一个数量级,并选择该学习率(在下面的示例中为1e-2)。 - 小批量是我们每次查看的几个图像,以便有效地利用 GPU 的并行处理能力(通常每次 64 或 128 个图像)。
- 在 Python 中:

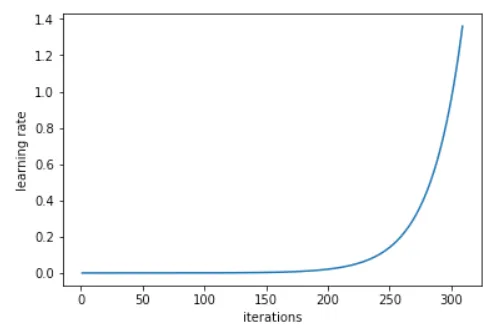

- 通过调整这个数字,您应该能够获得相当不错的结果。fast.ai 库会为您选择其余的超参数。但随着课程的进行,我们将学习到一些更多的可以调整以获得稍微更好结果的东西。但学习率对我们来说是关键数字。
- 学习率查找器位于其他优化器(例如动量、Adam 等)之上,并帮助您选择最佳学习率,考虑您正在使用的其他调整(例如高级优化器但不限于优化器)。
- 问题:在 epoch 期间改变学习率的优化器会发生什么?这个查找器是否选择了初始学习率?[14:05] 我们稍后会详细了解优化器,但基本答案是否定的。即使是 Adam 也有一个学习率,该学习率会被平均先前梯度和最近平方梯度的总和除以。即使那些所谓的“动态学习率”方法也有学习率。
- 使模型更好的最重要的事情是提供更多数据。由于这些模型有数百万个参数,如果您训练它们一段时间,它们开始做所谓的“过拟合”。
- 过拟合 - 模型开始看到训练集中图像的具体细节,而不是学习一些可以转移到验证集的通用内容。
- 我们可以收集更多数据,但另一种简单的方法是数据增强。
数据增强[15:50]

- 每个 epoch,我们会随机微调图像。换句话说,模型每个 epoch 都会看到图像的略微不同版本。
- 您希望为不同类型的图像使用不同类型的数据增强(水平翻转、垂直翻转、放大、缩小、变化对比度和亮度等)。
学习率查找问题:
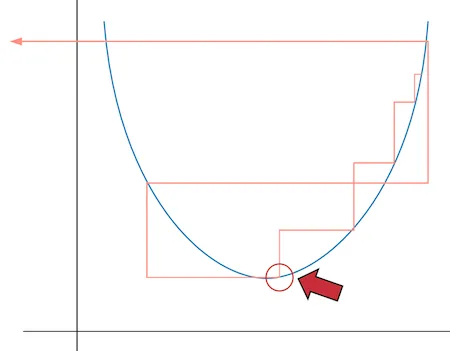
- 为什么不选择最低点?损失最低的点是红色圆圈所在的位置。但是在那一点学习率实际上太大了,不太可能收敛。因此,前一个点可能是更好的选择(总是选择比太大的学习率更小的学习率更好)
- 何时学习
lr_find?在开始时运行一次,也许在解冻层之后再运行(我们稍后会学习)。还有当我改变我正在训练的东西或改变我训练的方式时。运行它永远不会有害。
回到数据增强:
tfms = tfms_from_model(resnet34, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
transform_side_on- 用于侧面照片的预定义转换集(还有transform_top_down)。稍后我们将学习如何创建自定义转换列表。- 这并不是在创建新数据,而是让卷积神经网络学习如何从略有不同的角度识别猫或狗。
data = ImageClassifierData.from_paths(PATH, tfms=tfms) learn = ConvLearner.pretrained(arch, data, precompute=True)learn.fit(1e-2, 1)
- 现在我们创建了一个包含增强的新
data对象。最初,由于precompute=True,增强实际上什么也没做。 - 卷积神经网络有这些称为“激活”的东西。激活是一个数字,表示“这个特征在这个位置以这个置信度(概率)”。我们正在使用一个已经学会识别特征的预训练网络(即我们不想改变它学到的超参数),所以我们可以预先计算隐藏层的激活,然后只训练最终的线性部分。

- 这就是为什么当你第一次训练模型时,需要更长时间 - 它正在预计算这些激活。
- 尽管我们每次都试图展示猫的不同版本,但我们已经为特定版本的猫预先计算了激活(即我们没有使用改变后的版本重新计算激活)。
- 要使用数据增强,我们必须执行
learn.precompute=False:
learn.precompute=Falselearn.fit(1e-2, 3, cycle_len=1) ''' [ 0\. 0.03597 0.01879 0.99365] [ 1\. 0.02605 0.01836 0.99365] [ 2\. 0.02189 0.0196 0.99316] '''
- 坏消息是准确性没有提高。训练损失在减少,但验证损失没有,但我们没有过拟合。过拟合是指训练损失远低于验证损失。换句话说,当你的模型在训练集上表现比在验证集上好得多时,这意味着你的模型没有泛化。
cycle_len=1:这使得**随机梯度下降重启(SGDR)**成为可能。基本思想是,当你越来越接近具有最小损失的位置时,你可能希望开始减小学习率(采取更小的步骤)以确切地到达正确的位置。- 在训练过程中降低学习率的想法被称为学习率退火,这是非常常见的。最常见和“hacky”方法是使用某个学习率训练模型一段时间,当它停止改进时,手动降低学习率(分阶段退火)。
- 更好的方法是简单地选择某种功能形式 - 结果表明,真正好的功能形式是余弦曲线的一半,它在开始时保持高学习率,然后在接近时迅速下降。

- 然而,我们可能发现自己处于一个不太有弹性的权重空间中 - 也就是说,对权重进行微小的更改可能导致损失的巨大变化。我们希望鼓励我们的模型找到既准确又稳定的权重空间的部分。因此,我们不时增加学习率(这是“SGDR”中的“重启”),这将迫使模型跳到权重空间的不同部分,如果当前区域“尖锐”。如果我们三次重置学习率,它可能看起来像这样(在这篇论文中,他们称之为“循环 LR 计划”):

- 重置学习率之间的周期数由
cycle_len设置,这种情况下发生的次数被称为周期数,实际上是我们作为fit()的第二个参数传递的内容。这是我们实际学习率的样子:

- 问题:我们可以通过使用随机起始点获得相同的效果吗?在创建 SGDR 之前,人们通常会创建“集成”,他们会重新学习一个全新的模型十次,希望其中一个会变得更好。在 SGDR 中,一旦我们接近最佳和稳定区域,重置实际上不会“重置”,而是权重保持更好。因此,SGDR 将比随机尝试几个不同的起始点给出更好的结果。
- 选择一个学习率(这是 SGDR 使用的最高学习率)很重要,它足够大,可以使重置跳转到函数的不同部分。
- SGDR 会在每个小批次中降低学习率,并且重置每个
cycle_len周期(在这种情况下设置为 1)。 - 问题:我们的主要目标是泛化,而不是陷入狭窄的最优解。在这种方法中,我们是否跟踪最小值并对其进行平均处理并集成它们?这是另一种复杂程度,您可以在图表中看到“快照集成”。我们目前没有这样做,但如果您希望泛化得更好,可以在重置之前保存权重并取平均值。但目前,我们只会选择最后一个。
- 如果您想要跳过,还有一个名为
cycle_save_name的参数,您可以添加它以及cycle_len,它将在每个学习率周期结束时保存一组权重,然后您可以将它们集成。
保存模型
learn.save('224_lastlayer') learn.load('224_lastlayer')
- 当您预计算激活或创建调整大小的图像(我们将很快学习到),会创建各种临时文件,您可以在
data/dogcats/tmp文件夹下看到。如果出现奇怪的错误,可能是因为预计算的激活只完成了一半,或者以某种方式与您正在进行的操作不兼容。因此,您可以随时继续并删除此/tmp文件夹,看看是否可以消除错误(相当于将其关闭然后重新打开)。 - 您还会看到一个名为
/models的目录,这是当您说learn.save时保存模型的位置。

微调和差分学习率
- 到目前为止,我们还没有重新训练任何预训练的特征 - 具体来说,卷积核中的任何权重。我们所做的只是在顶部添加了一些新层,并学会了如何混合和匹配预训练的特征。
- 像卫星图像、CT 扫描等图像具有完全不同类型的特征(与 ImageNet 图像相比),因此您需要重新训练许多层。
- 对于狗和猫,图像与模型预先训练的图像相似,但我们仍然可能发现微调一些后续层会有所帮助。
- 这是如何告诉学习者我们要开始实际更改卷积滤波器本身的方法:
learn.unfreeze()
- “冻结”层是一个未被训练/更新的层。
unfreeze会解冻所有层。 - 像第一层(检测对角边缘或梯度)或第二层(识别角落或曲线)这样的早期层可能根本不需要或只需要很少的更改。
- 后续层更有可能需要更多的学习。因此,我们创建了一个学习率数组(差分学习率):
lr=np.array([1e-4,1e-3,1e-2])
1e-4:用于前几层(基本几何特征)1e-3:用于中间层(复杂的卷积特征)1e-2:用于我们添加的顶部层- 为什么是 3?实际上它们是 3 个 ResNet 块,但现在,可以将其视为一组层。
问题:如果我的图片比模型训练的图片大怎么办?简短的答案是,使用这个库和我们正在使用的现代架构,我们可以使用任何大小的图片。
问题:我们可以只解冻特定的层吗?我们还没有这样做,但如果你想的话,你可以使用learn.unfreeze_to(n)(这将从第n层开始解冻层)。Jeremy 几乎从来没有发现这有帮助,他认为这是因为我们使用了不同的学习率,优化器可以学习到它需要的一样多。他发现有帮助的一个地方是,如果他使用一个真正大的内存密集型模型,而且他的 GPU 快要用完了,你解冻的层数越少,占用的内存和时间就越少。
使用不同的学习率,我们的准确率达到了 99.5%!
learn.fit(lr, 3, cycle_len=1, cycle_mult=2) ''' [ 0\. 0.04538 0.01965 0.99268] [ 1\. 0.03385 0.01807 0.99268] [ 2\. 0.03194 0.01714 0.99316] [ 3\. 0.0358 0.0166 0.99463] [ 4\. 0.02157 0.01504 0.99463] [ 5\. 0.0196 0.0151 0.99512] [ 6\. 0.01356 0.01518 0.9956 ] '''
- 之前我们说
3是周期的数量,但实际上是周期。所以如果cycle_len=2,它将执行 3 个周期,每个周期为 2 个周期(即 6 个周期)。那为什么是 7 个?这是因为cycle_mult。 cycle_mult=2:这会在每个周期后乘以周期的长度(1 个周期+2 个周期+4 个周期=7 个周期)。

直观地说,如果周期长度太短,它开始下降寻找一个好的位置,然后弹出,再次下降寻找一个好的位置,然后弹出,永远无法找到一个好的位置。在早期,你希望它这样做,因为它试图找到一个更平滑的位置,但后来,你希望它做更多的探索。这就是为什么cycle_mult=2似乎是一个好方法。
我们正在引入越来越多的超参数,告诉你没有很多。你可以只选择一个好的学习率,但添加这些额外的调整可以在不费力的情况下获得额外的提升。一般来说,好的起点是:
n_cycle=3,cycle_len=1,cycle_mult=2n_cycle=3,cycle_len=2(没有cycle_mult)
问题:为什么更平滑的表面与更广义的网络相关?

假设你有一个尖锐的东西(蓝线)。X 轴显示了当你改变这个特定参数时,它在识别狗和猫方面的表现如何。可泛化意味着当我们给它一个略微不同的数据集时,我们希望它能够工作。略微不同的数据集可能在这个参数和猫狗之间的关系上有略微不同。它可能看起来像红线。换句话说,如果我们最终到达蓝色尖锐部分,那么它在这个略微不同的数据集上不会表现良好。或者,如果我们最终到达较宽的蓝色部分,它仍然会在红色数据集上表现良好。
- 这里有一些关于峰值最小值的有趣讨论。
测试时间增强(TTA)
我们的模型已经达到了 99.5%。但我们还能让它变得更好吗?让我们看看我们错误预测的图片:

在这里,Jeremy 打印出了所有这些图片。当我们进行验证集时,我们模型的所有输入必须是正方形的。原因有点小的技术细节,但如果不同的图片有不同的尺寸,GPU 不会很快。它需要保持一致,以便 GPU 的每个部分都可以做同样的事情。这可能是可以解决的,但目前这是我们拥有的技术状态。
为了使它成为正方形,我们只需挑选中间的正方形——正如你所看到的,可以理解为什么这张图片被错误分类:

我们将进行所谓的“测试时间增强”。这意味着我们将随机进行 4 次数据增强,以及未增强的原始图像(中心裁剪)。然后我们将为所有这些图像计算预测,取平均值,并将其作为我们的最终预测。请注意,这仅适用于验证集和/或测试集。
要做到这一点,您只需learn.TTA()——这将将准确性提高到 99.65%!
log_preds,y = learn.TTA() probs = np.mean(np.exp(log_preds),0) accuracy(probs, y) ''' 0.99650000000000005 '''
关于增强方法的问题[01:01:36]:为什么不使用边框或填充使其变成正方形?通常 Jeremy 不会做太多填充,而是会做一点缩放。有一种叫做反射填充的东西在卫星图像中效果很好。一般来说,使用 TTA 加数据增强,最好的做法是尽可能使用尽可能大的图像。此外,固定裁剪位置加上随机对比度、亮度、旋转变化可能对 TTA 更好。
问题:非图像数据集的数据增强?[01:03:35] 没有人似乎知道。看起来会有帮助,但例子很少。在自然语言处理中,人们尝试替换同义词,但总体来说,这个领域研究不足,发展不足。
问题:fast.ai 库是开源的吗?[01:05:34] 是的。然后他讲解了Fast.ai 从 Keras + TensorFlow 切换到 PyTorch 的原因
随机笔记:PyTorch 不仅仅是一个深度学习库。它实际上让我们可以从头开始编写任意 GPU 加速的算法——Pyro 是人们现在在 PyTorch 之外进行的一个很好的例子。
分析结果[01:11:50]
混淆矩阵
分类结果的简单查看方式称为混淆矩阵——不仅用于深度学习,而且用于任何类型的机器学习分类器。如果你试图预测四五类,特别有帮助,可以看出你在哪个组别遇到了最大的困难。
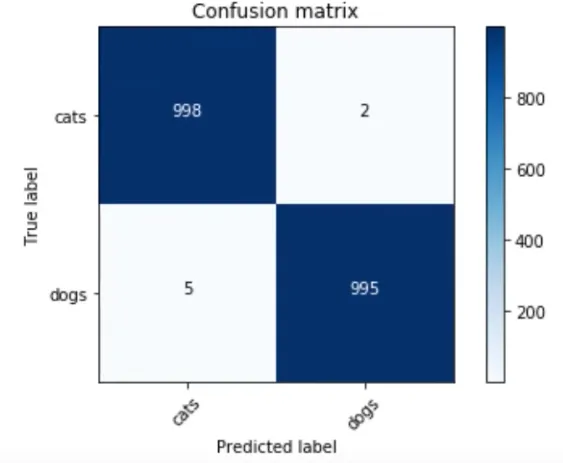
preds = np.argmax(probs, axis=1) probs = probs[:,1] from sklearn.metrics import confusion_matrix cm = confusion_matrix(y, preds) plot_confusion_matrix(cm, data.classes)
让我们再次看看图片[01:13:00]
大多数错误的猫(只有左边两个是错误的——默认显示 4 个):

大多数错误的点:

回顾:训练世界一流的图像分类器的简单步骤[01:14:09]
- 启用数据增强,
precompute=True - 使用
lr_find()找到损失仍然明显改善的最高学习率 - 从预计算的激活中训练最后一层 1-2 个时期
- 使用数据增强训练最后一层(即
precompute=False)2-3 个时期,cycle_len=1 - 解冻所有层
- 将前面的层设置为比下一层低 3 倍至 10 倍的学习率。经验法则:ImageNet 类似的图像为 10 倍,卫星或医学成像为 3 倍
- 再次使用
lr_find()(注意:如果您设置了不同的学习率并调用lr_find,它打印出的是最后几层的学习率。) - 使用
cycle_mult=2训练完整网络直到过拟合
让我们再做一次:狗品种挑战 [01:16:37]
- 您可以使用Kaggle CLI下载 Kaggle 竞赛的数据
- 笔记本没有公开,因为它是一个活跃的竞赛
%reload_ext autoreload %autoreload 2 %matplotlib inlinefrom fastai.imports import * from fastai.transforms import * from fastai.conv_learner import * from fastai.model import * from fastai.dataset import * from fastai.sgdr import * from fastai.plots import * PATH = 'data/dogbreed/' sz = 224 arch = resnext101_64 bs=16 label_csv = f'{PATH}labels.csv' n = len(list(open(label_csv)))-1 val_idxs = get_cv_idxs(n) !ls {PATH}

这与我们以前的数据集有点不同。它没有一个包含每个狗品种的单独文件夹的train文件夹,而是有一个带有正确标签的 CSV 文件。我们将使用 Pandas 读取 CSV 文件。Pandas 是我们在 Python 中用来进行结构化数据分析的工具,比如 CSV,通常被导入为pd:
label_df = pd.read_csv(label_csv) label_df.head()

label_df.pivot_table(index='breed', aggfunc=len).sort_values('id', ascending=False)

每个品种有多少狗图像
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1) data = ImageClassifierData.from_csv(PATH, 'train', f'{PATH}labels.csv', test_name='test', val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
max_zoom——我们将放大 1.1 倍ImageClassifierData.from_csv— 上次我们使用了from_paths,但由于标签在 CSV 文件中,我们将使用from_csv。test_name— 如果要提交到 Kaggle 比赛,我们需要指定测试集的位置val_idx— 没有validation文件夹,但我们仍然想要跟踪我们的本地表现有多好。因此你会看到上面的:
n = len(list(open(label_csv)))-1:打开 CSV 文件,创建一个行列表,然后取长度。 -1是因为第一行是标题。因此n是我们拥有的图像数量。
val_idxs = **get_cv_idxs**(n): “获取交叉验证索引” — 默认情况下,这将返回随机 20%的行(确切的索引)作为验证集。你也可以发送val_pct以获得不同的数量。

suffix='.jpg'— 文件名以.jpg结尾,但 CSV 文件没有。因此我们将设置suffix以便它知道完整的文件名。
fn = PATH + data.trn_ds.fnames[0]; fn ''' 'data/dogbreed/train/001513dfcb2ffafc82cccf4d8bbaba97.jpg' '''
- 你可以通过说
data.trn_ds来访问训练数据集,trn_ds包含很多东西,包括文件名(fnames)
img = PIL.Image.open(fn); img

img.size ''' (500, 375) '''
- 现在我们检查图像大小。如果它们很大,那么你必须非常仔细地考虑如何处理它们。如果它们很小,也是具有挑战性的。大多数 ImageNet 模型都是在 224x224 或 299x299 的图像上训练的
size_d = {k: PIL.Image.open(PATH+k).size for k in data.trn_ds.fnames}
- 字典推导 —
键: 文件名,值: 文件大小
row_sz, col_sz = list(zip(*size_d.values()))
*size_d.values()将解压缩一个列表。zip将元组的元素配对以创建一个元组列表。
plt.hist(row_sz);

行的直方图
- 如果你在 Python 中进行任何数据科学或机器学习,Matplotlib 是你想要非常熟悉的东西。Matplotlib 总是被称为
plt。
问题:我们应该使用多少图像作为验证集?[01:26:28] 使用 20%是可以的,除非数据集很小 — 那么 20%就不够了。如果你多次训练相同的模型并且得到非常不同的验证集结果,那么你的验证集太小了。如果验证集小于一千,很难解释你的表现如何。如果你关心准确度的第三位小数,并且验证集中只有一千个数据,一个图像的变化就会改变准确度。如果你关心 0.01 和 0.02 之间的差异,你希望这代表 10 或 20 行。通常 20%似乎效果不错。
def get_data(sz, bs): tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1) data = ImageClassifierData.from_csv(PATH, 'train', f'{PATH}labels.csv', test_name='test', num_workers=4, val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs) return data if sz>300 else data.resize(340, 'tmp')
- 这是常规的两行代码。当我们开始使用新数据集时,我们希望一切都能快速进行。因此,我们可以指定大小并从 64 开始,这样会运行得更快。稍后,我们将使用更大的图像和更大的架构,到那时,你可能会耗尽 GPU 内存。如果你看到 CUDA 内存不足错误,你需要做的第一件事是重新启动内核(你无法从中恢复),然后减小批量大小。
data = get_data(224, bs) learn = ConvLearner.pretrained(arch, data, precompute=True) learn.fit(1e-2, 5) ''' [0\. 1.99245 1.0733 0.76178] [1\. 1.09107 0.7014 0.8181 ] [2\. 0.80813 0.60066 0.82148] [3\. 0.66967 0.55302 0.83125] [4\. 0.57405 0.52974 0.83564] '''
- 对于 120 个类别来说,83%是相当不错的。
learn.precompute = False learn.fit(1e-2, 5, cycle_len=1)
- 提醒:一个
epoch是对数据的一次遍历,一个cycle是你说一个周期中有多少个 epoch
learn.save('224_pre') learn.load('224_pre')
增加图像大小 [1:32:55]
learn.set_data(get_data(299, bs))
- 如果你在较小尺寸的图像上训练了一个模型,然后可以调用
learn.set_data并传入一个更大尺寸的数据集。这将采用到目前为止已经训练过的模型,并让你继续在更大的图像上训练。
从小图像开始训练几个时期,然后切换到更大的图像,并继续训练是一个非常有效的避免过拟合的方法。
learn.fit(1e-2, 3, cycle_len=1) ''' [0\. 0.35614 0.22239 0.93018] [1\. 0.28341 0.2274 0.92627] [2\.* *0.28341**0.2274* *0.92627] '''
- 如你所见,验证集损失(0.2274)远低于训练集损失(0.28341) — 这意味着它是欠拟合。当你欠拟合时,意味着
cycle_len=1太短了(学习率在适当缩小之前被重置)。所以我们将添加cycle_mult=2(即第一个周期是 1 个时期,第二个周期是 2 个时期,第三个周期是 4 个时期)
learn.fit(1e-2, 3, cycle_len=1, cycle_mult=2) ''' [0\. 0.27171 0.2118 0.93192] [1\. 0.28743 0.21008 0.9324 ] [2\. 0.25328 0.20953 0.93288] [3\. 0.23716 0.20868 0.93001] [4\. 0.23306 0.20557 0.93384] [5\. 0.22175 0.205 0.9324 ] [6\. 0.2067 0.20275 0.9348 ]
- 现在验证损失和训练损失大致相同 — 这是正确的轨道。然后我们尝试
TTA:
log_preds, y = learn.TTA() probs = np.exp(log_preds) accuracy(log_preds,y), metrics.log_loss(y, probs) ''' (0.9393346379647749, 0.20101565705592733) '''
其他尝试:
- 尝试再运行一个 2 个时期的周期
- 解冻(在这种情况下,训练卷积层根本没有帮助,因为图像实际上来自 ImageNet)
- 删除验证集,只需重新运行相同的步骤,并提交 - 这样我们可以使用 100%的数据。
问题:我们如何处理不平衡的数据集?[01:38:46]这个数据集不是完全平衡的(在 60 和 100 之间),但不够不平衡,以至于 Jeremy 不会再考虑。最近的一篇论文说,处理非常不平衡的数据集的最佳方法是复制罕见情况。
问题:precompute=True和unfreeze之间的区别?
- 我们从预训练网络开始
- 我们在其末尾添加了几层,这些层最初是随机的。当所有内容都被冻结且
precompute=True时,我们学到的只是我们添加的层。 - 使用
precompute=True,数据增强不起作用,因为每次显示的激活完全相同。 - 然后我们将
precompute=False设置为假,这意味着我们仍然只训练我们添加的层,因为它被冻结,但数据增强现在正在工作,因为它实际上正在重新计算所有激活。 - 最后,我们解冻,这意味着“好的,现在您可以继续更改所有这些早期卷积滤波器”。
问题:为什么不从一开始就将precompute=False设置为假?将precompute=True的唯一原因是它速度更快(快 10 倍或更多)。如果您正在处理相当大的数据集,它可以节省相当多的时间。从来没有理由使用precompute=True来提高准确性。
获得良好结果的最小步骤:
- 使用
lr_find()找到损失仍然明显改善的最高学习率 - 使用数据增强(即
precompute=False)训练最后一层 2-3 个周期,cycle_len=1 - 解冻所有层
- 将较早的层设置为比下一层更高的层次低 3 倍至 10 倍的学习率
- 使用
cycle_mult=2训练完整网络直到过拟合
问题:减少批量大小只影响训练速度吗?[1:43:34]是的,基本上是这样。如果每次显示的图像较少,则使用较少的图像计算梯度 - 因此准确性较低。换句话说,知道要走哪个方向以及在该方向上走多远的准确性较低。因此,随着批量大小变小,它变得更加不稳定。它会影响您需要使用的最佳学习率,但实际上,将批量大小除以 2 与除以 4 似乎并没有太大变化。如果更改批量大小很大,可以重新运行学习率查找器进行检查。
问题:灰色图像与右侧图像之间有什么区别?

第一层,它们确实是滤波器的样子。很容易可视化,因为输入是像素。后来,变得更难,因为输入本身是激活,是激活的组合。Zeiler 和 Fergus 提出了一种聪明的技术,展示滤波器平均倾向于什么样子 - 称为反卷积(我们将在第 2 部分学习)。右侧是激活该滤波器的图像块的示例。
问题:如果狗在角落或很小,你会怎么做(关于狗品种识别)?[01:47:16]我们将在第 2 部分学习,但有一种技术可以让您大致确定图像的哪些部分最有趣。然后您可以裁剪出该区域。
进一步改进[01:48:16]
立即可以做两件事来使其更好:
- 假设您使用的图像大小小于您所获得的图像的平均大小,您可以增加大小。正如我们之前所看到的,您可以在训练期间增加它。
- 使用更好的架构。有不同的方法来组合卷积滤波器的大小以及它们如何连接在一起,不同的架构具有不同数量的层,内核大小,滤波器等。
我们一直在使用 ResNet34 — 一个很好的起点,通常也是一个很好的终点,因为它没有太多参数,并且在小数据集上表现良好。还有另一种架构叫做 ResNext,它是去年 ImageNet 比赛的第二名。ResNext50 的训练时间是 ResNet34 的两倍,内存使用量是其 2-4 倍。
这里是几乎与原始狗和猫相同的笔记本。使用了 ResNext50,实现了 99.75%的准确率。
卫星图像 [01:53:01]

代码基本与之前看到的相同。以下是一些不同之处:
transforms_top_down— 由于它们是卫星图像,所以在垂直翻转时仍然有意义。- 学习率更高 — 与这个特定数据集有关
lrs = np.array([lr/9,lr/3,lr])— 差异学习率现在变为 3 倍,因为图像与 ImageNet 图像非常不同sz=64— 这有助于避免卫星图像的过拟合,但对于狗和猫或狗品种(与 ImageNet 相似的图像)他不会这样做,因为 64x64 相当小,可能会破坏预训练权重。
如何设置您的 AWS [01:58:54]
您可以跟着视频或这里是一位学生写的很好的文章。
深度学习 2:第 1 部分第 3 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-3-74b0ef79e56译者:飞龙
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
第 3 课
学生们制作的有用材料:
我们接下来要做什么:

fast.ai 深度学习笔记(一)(4)/article/1482677
