问题一:Flink CDC里谁试过用superset连接starrocks的,报错要怎么办啊?
Flink CDC里谁试过用superset连接starrocks的,官网的方法好像不太行,报错要怎么办啊?
参考答案:
确保你在Superset的数据库连接设置中输入了正确的StarRocks主机地址、端口、数据库名、用户名和密码。
如果StarRocks集群仅允许特定的IP访问,确保Superset服务器的IP地址被允许。
关于本问题的更多回答可点击进行查看:
/ask/599194?spm=a2c6h.12873639.article-detail.67.50e24378TRW91E
问题二:flink cdc oracle 这个报错有遇到过的吗?
flink cdc oracle 这个报错有遇到过的吗? 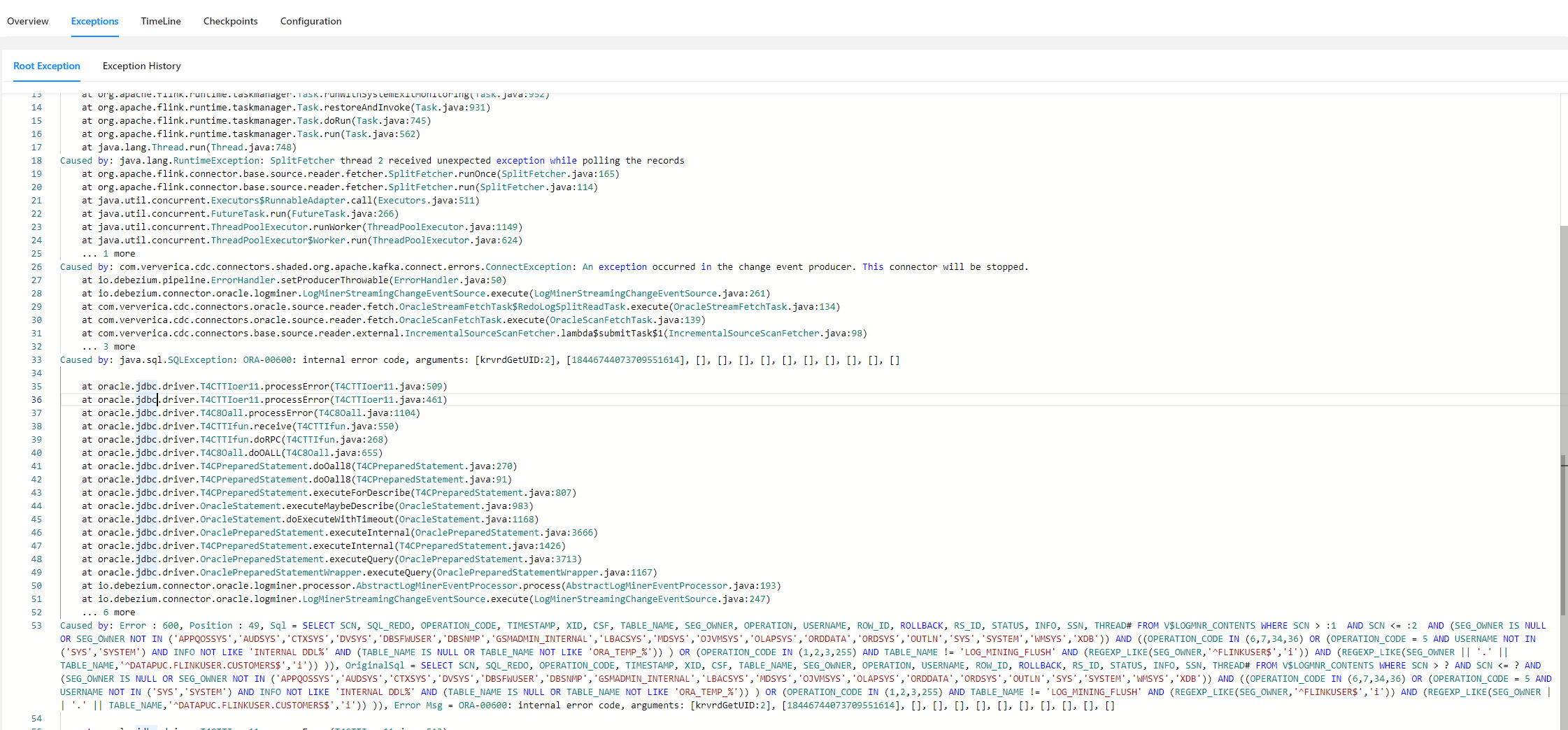
参考答案:
根据提供的信息,报错信息显示为 "ORA-00600: internal error code, arguments: [krvrdGetUID: 2], [18446744073709551614],[],[],[],[],[],[],[],[],[],[]},[],[],[],[],[]},[],[],[],[],[]},[],[]},[],[],[],[]},[],[],[]},[]},at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.Java:509)"。这个错误是Oracle数据库的内部错误代码,具体的错误原因需要进一步分析。
一般来说,当遇到ORA-00600这样的内部错误时,可以尝试以下步骤进行排查:
- 检查数据库日志:查看Oracle数据库的alert日志或trace文件,这些文件通常包含有关错误的详细信息。
- 检查网络连接:确保Flink CDC与Oracle数据库之间的网络连接正常,没有中断或延迟。
- 检查数据库配置:确认Oracle数据库的配置是否正确,包括内存、参数设置等。
- 检查驱动程序和版本:确保使用的JDBC驱动程序与Oracle数据库版本兼容,并且是最新版本。
- 检查SQL语句:仔细检查执行的SQL语句,特别是涉及表名、列名、数据类型等方面的内容,确保没有语法错误或逻辑错误。
关于本问题的更多回答可点击进行查看:
/ask/599193?spm=a2c6h.12873639.article-detail.68.50e24378TRW91E
问题三:Flink CDC里 任务重启由rocksdb状态后端改为hashmap行不行呢?
Flink CDC里 任务重启由rocksdb状态后端改为hashmap行不行呢?
参考答案:
Apache Flink 的任务在重启时更改状态后端,从 RocksDBStateBackend 更改为 HashMapStateBackend 并不是一个推荐的做法,且实际操作中可能不会按照预期工作。原因如下:1. 状态一致性:?当Flink作业使用RocksDBStateBackend持久化了状态,并在故障恢复时需要从检查点或者保存点进行恢复,这些状态是以RocksDB存储格式保存的。?如果直接切换到HashMapStateBackend,由于两种后端的数据结构和持久化方式完全不同,HashMapStateBackend无法直接读取RocksDB格式的状态数据。2. 内存限制:?RocksDB可以将大量状态数据存储在磁盘上,适合处理大规模状态数据的场景。?HashMapStateBackend则将状态数据完全保留在JVM堆内存中,如果状态数据量较大,可能会导致内存溢出(OOM)问题。3. 作业设计与配置:?通常在开发阶段确定了状态后端之后,在生产环境中不建议随意变更,因为这会改变整个作业的状态管理和容错机制。若确实需要更换状态后端,正确的做法是:?先停止当前使用RocksDBStateBackend的任务。?将之前保存的状态以兼容的方式迁移到新的状态后端所使用的格式。?配置新作业使用HashMapStateBackend,并设置好相应的内存限制策略。?启动新的作业,并从迁移后的状态进行恢复。但是请注意,对于大型或长时间运行的流处理作业,HashMapStateBackend由于其内存局限性,往往不适合用于处理大状态的情况。在生产环境部署时,应根据应用的实际需求选择合适的状态后端。
关于本问题的更多回答可点击进行查看:
/ask/599192?spm=a2c6h.12873639.article-detail.69.50e24378TRW91E
问题四:有没有用flink cdc做过mysql整库的实时同步?
有没有大神用flink cdc做过mysql整库的实时同步?
参考答案:
有使用Flink CDC实现MySQL整库的实时同步的案例。
Flink CDC(Change Data Capture)是Apache Flink中用于捕获数据库变化数据的一项技术,它能够实时地捕获和同步数据库中的数据变更。以下是一些关于使用Flink CDC进行MySQL整库实时同步的实践案例和相关信息:
- MysqlCDC项目:有一个基于Flink CDC的项目,通过datastream方式实现了MySQL之间的全量和增量同步。这个项目是用Java编写的,用户只需要配置好源数据库和目标数据库的信息,运行项目中的main函数,就能实现多库多表的同步。
- 数据同步到其他存储系统:在许多场景中,当数据库的数据发生变化时,可能需要将这些变化同步到其他存储中间件,如Kafka、Elasticsearch等。使用Flink CDC可以实现这种类型的数据同步,减少业务代码与数据同步操作的耦合,从而降低维护成本并减少代码冗余。
- 环境准备和配置:为了实现实时同步,需要准备相应的环境,包括安装JDK、Flink以及MySQL等。还需要创建用于同步的源数据库和目标数据库,并进行适当的配置以完成同步任务。
- 实时同步到Doris:有实践案例介绍了如何使用Flink CDC版本2.4将MySQL数据库实时同步到Doris数据库。这包括了环境的准备、Flink CDC的配置、数据同步流程以及需要注意的事项。
综上所述,Flink CDC确实可以用来做MySQL整库的实时同步,并且已经有相关的实践案例和项目。这些案例和项目展示了Flink CDC在数据同步方面的能力和实用性。在实施同步时,需要考虑到环境的配置、数据的一致性要求以及同步策略等多个方面,以确保同步过程的高效和可靠。
关于本问题的更多回答可点击进行查看:
/ask/598971?spm=a2c6h.12873639.article-detail.70.50e24378TRW91E
问题五:flink CDC中,同步任务重并没有同步mysql某张表,如果未被同步的表结构变更了怎么办?
flink CDC中,同步任务重并没有同步mysql某张表,如果未被同步的表结构变更了,flinkCDC 同步任务也会报错。按理说应该不会,是不是可以做些设置呢?
参考答案:
3.0.1 修复了。
关于本问题的更多回答可点击进行查看:
/ask/598742?spm=a2c6h.12873639.article-detail.71.50e24378TRW91E


