一篇由三位Hudi PMC在2018年做的关于Hudi的分享,介绍了Hudi产生的背景及设计,现在看来也很有意义。

分为产生背景、动机、设计、使用案例、demo几个模块讲解。

Uber的行程在2018年已经达到700个城市,70个国家,200w+司机的规模。
而数据在Uber中可分为摄取和查询,而摄取包括从kafka、hdfs上消费数据;查询则包括使用spark notebook的数据科学家,使用Hive/Presto进行ad hoc查询和dashboard展示,使用Spark/Hive构建数据管道或ETL任务等。引入Hudi,Hudi可以管理原始数据集,提供upsert、增量处理语义及快照隔离。

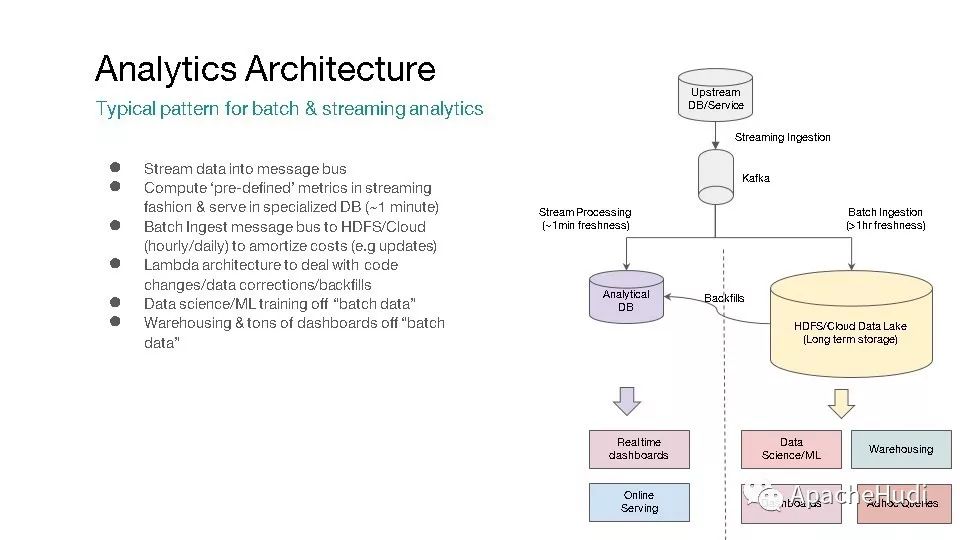
这是典型的流、批分析架构,可以看到,流、批处理会共同消费消息中间件(如kafka)的数据,流处理提供小于1min延迟的结果,批处理提供大约1小时延迟的结果,而批处理结果可修正流处理结果,这是一种典型的Lambda架构,即需要维护两套系统,维护成本会较高。
当使用数据湖后,会提供如下优势:1. 支持最新数据上的Ad hoc查询;2. 近实时处理(微批),很多业务场景并不需要完全实时;3. 对于数据的处理更为得当,如检查文件大小,这对HDFS这类存储非常重要,无需重写整个分区的处理;4. 维护成本更低,如不需要复制数据,也不需要维护多套系统。

Hudi作为Uber开源的数据湖框架,抽象了存储层(支持数据集的变更,增量处理);为Spark的一个Lib(任意水平扩展,支持将数据存储至HDFS);开源(现已在Apache孵化)。

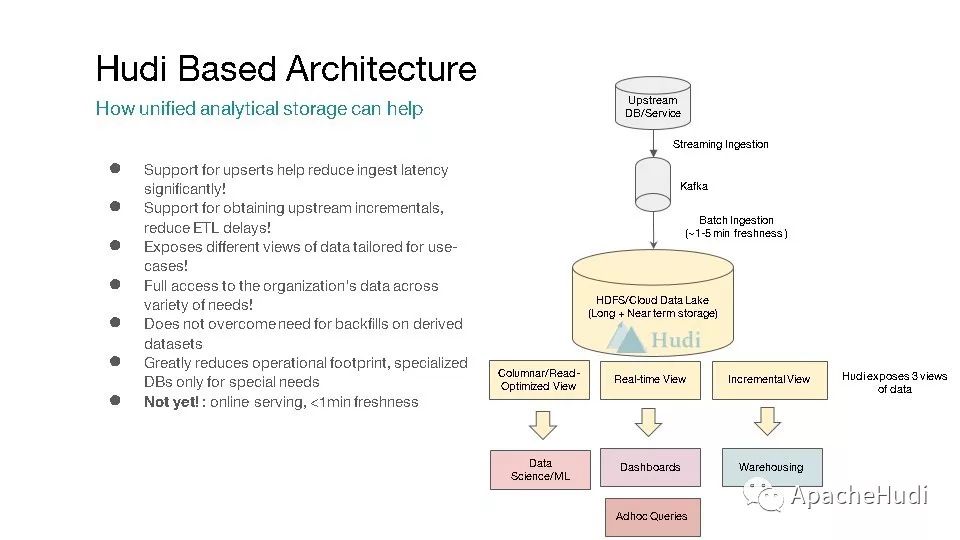
基于Hudi的架构设计,支持upsert,支持增量处理,支持不同的视图等等,可以看到与典型的Lambda框架不同,此时基于Hudi的分析架构只需要维护Hudi即可,由Hudi提供的能力来满足上层应用不同的需求。
Hudi在HDFS上管理了数据集,主要包括索引,数据文件和元数据,并且支持Hive/Presto/Spark进行查询。

Hudi提供了三种不同类型的视图,读优化视图、实时视图、增量视图,社区正在重构这三个定义,分别为读优化视图、快照视图、增量视图。

对于COW类型,支持读优化视图,对于MOR类型,支持读优化视图、实时视图,而对于最新的发布版而言,COW支持读优化视图和增量视图,MOR支持读优化视图、实时视图和增量视图。


在COW模式下,读优化视图仅仅读取parquet数据文件,在批次1upsert后,读优化视图读取File1和File2文件;在批次2upsert后,读优化视图读取File 1'和File2文件。
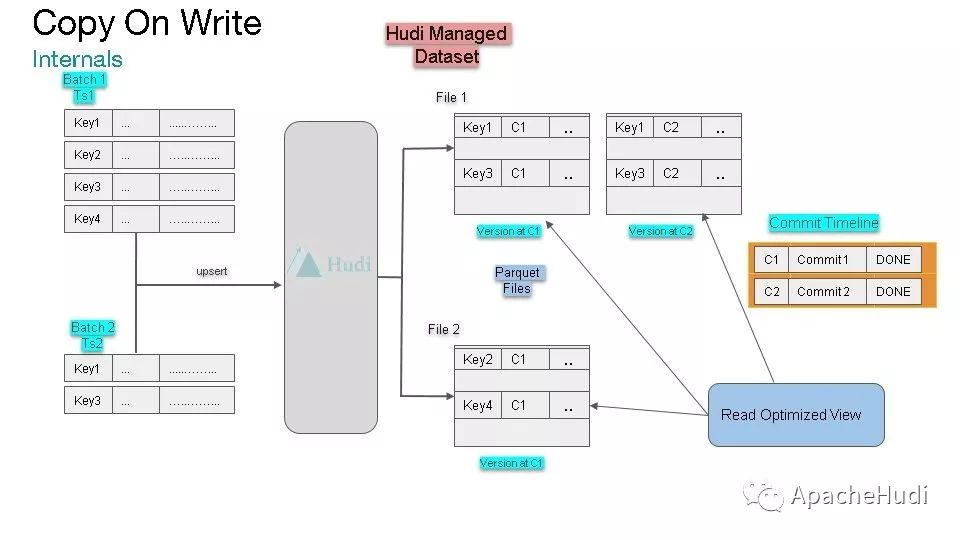
使用COW模式可以解决很多问题,但其也存在一些问题,如写方法,即更新的时延会比较大(由于复制整个文件导致)。

下面的工作流表示了如何处理延迟到达的更新,更新首先会反应至源表(Source table),然后源表更新至ETL table A,然后更新至ETL table B,这种工作流的延迟更大。

根据上面分析,可归纳出如下问题,高社区延迟、写放大、数据新鲜度受限以及小文件问题。
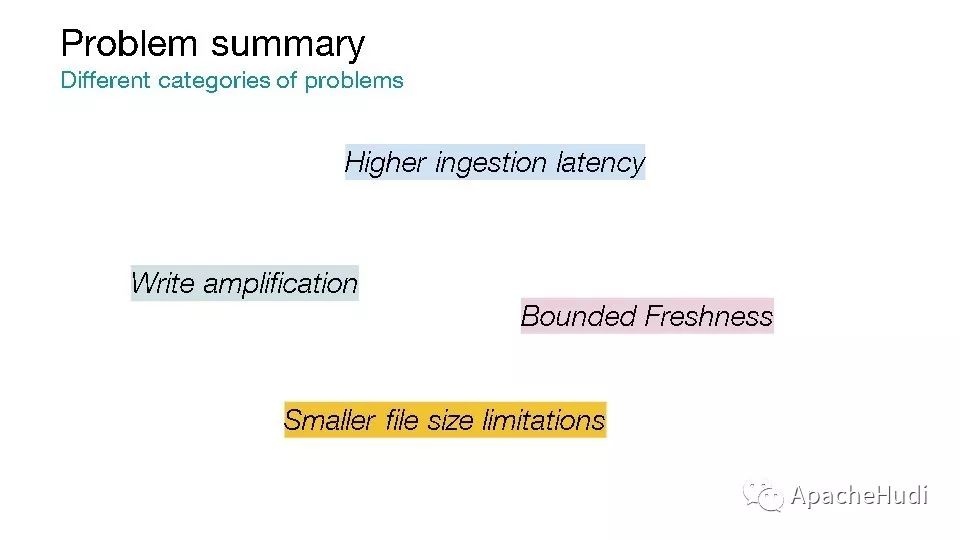
与COW模式下更新时复制整个文件不同,可以将更新写入一个增量文件,这样便可降低数据摄取延迟,降低写放大。

MOR模式下提供了读优化视图和实时视图。

在批次1upsert之后,读优化视图读取的也是Parquet文件,在批次2upsert之后,实时视图读取的是parquet文件和日志文件合并的结果。

对比Hudi上不同视图下的权衡,COW下的读优化视图拥有Parquet原生文件读取性能,但数据摄取较慢;MOR下的读优化视图也有parquet原生文件读取性能,但会读取到过期的数据(并未更新);MOR下实时视图数据摄取性能高,在读的时候会合并;合并(compaction)会将日志文件转化为parquet文件,从实时视图转化为读优化视图。

针对compaction(压缩),Hudi提供了基于MVCC无锁的异步压缩方式,这样便可解耦数据摄取,使得数据摄取不受影响。

异步压缩会将日志文件和数据文件合并形成新的数据文件,之后读优化视图便可反应最新的数据。
Hudi还提供了并发保证,如快照隔离,批次写入的原子性。

Hudi使用案例分享

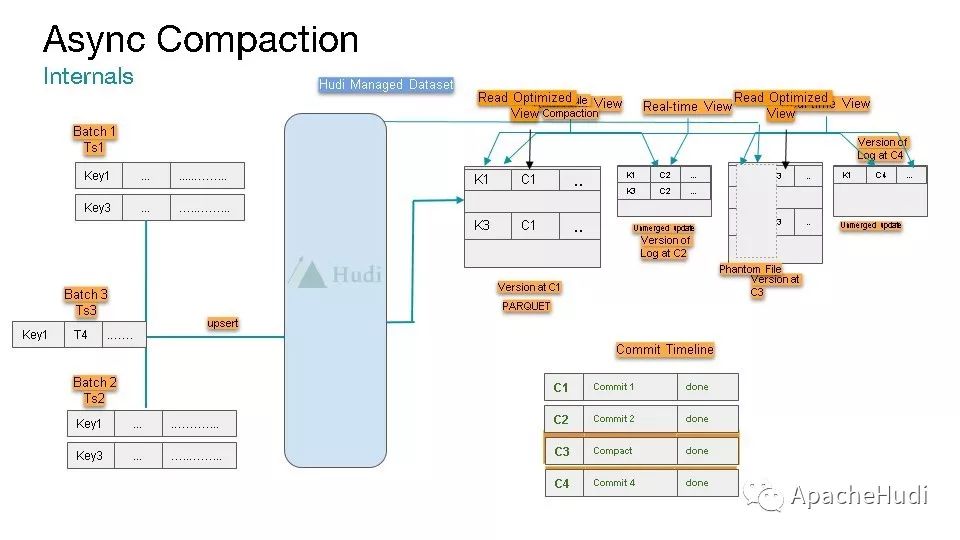
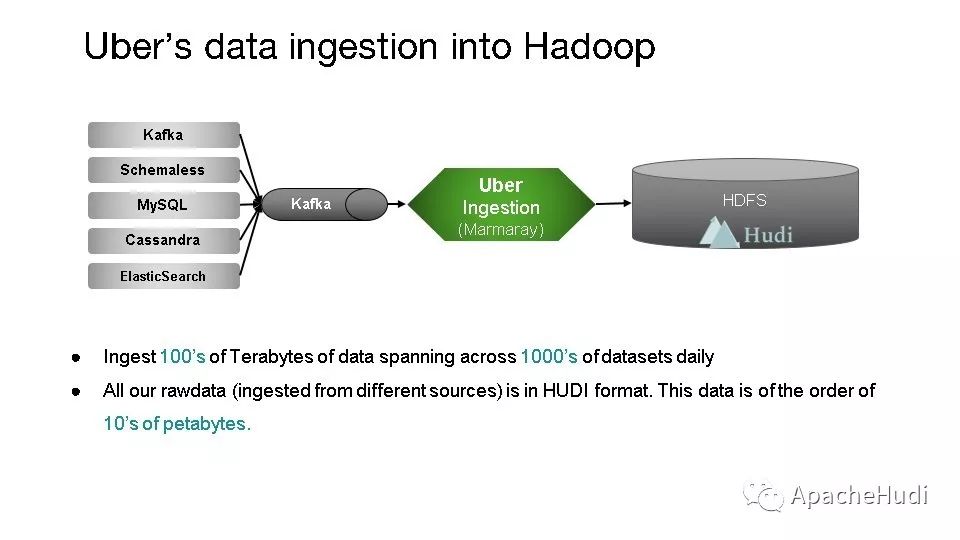
在Uber,通过Uber自研的Marmaray消费kafka中的数据,然后再写入Hudi数据湖,每天超过1000个数据集的100TB数据,Hudi管理的数据集大小已经达到10PB。
而对于HDFS的典型的小文件问题,Hudi在摄取数据时会自动处理小文件来减轻namenode的压力;支持大文件写入;支持对现有文件的增量更新。

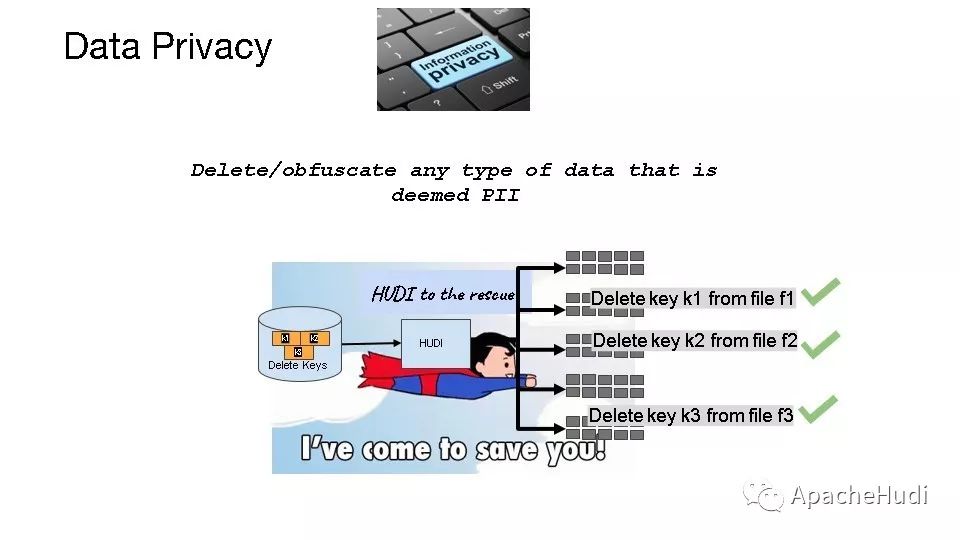
Hudi也考虑了数据隐私问题,即数据如何删除,Hudi提供了软删除和硬删除两种方式,软删除不会删除key,只会删除内容,而硬删除会删除key和内容。
使用Hudi的增量处理来构建增量管道和dashboard。


