问题一:Flink CDC里请问upsert-kafka增加参数报错是为什么?
Flink CDC里请问upsert-kafka增加参数: 'sink.buffer-flush.interval' = '5', 'sink.buffer-flush.max-rows' = '100'后报错是什么原因? 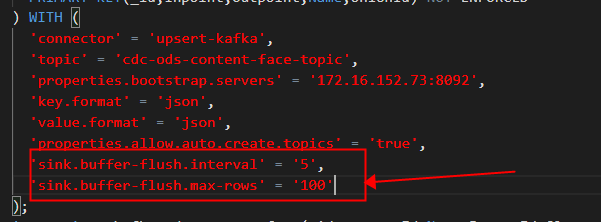

参考回答:
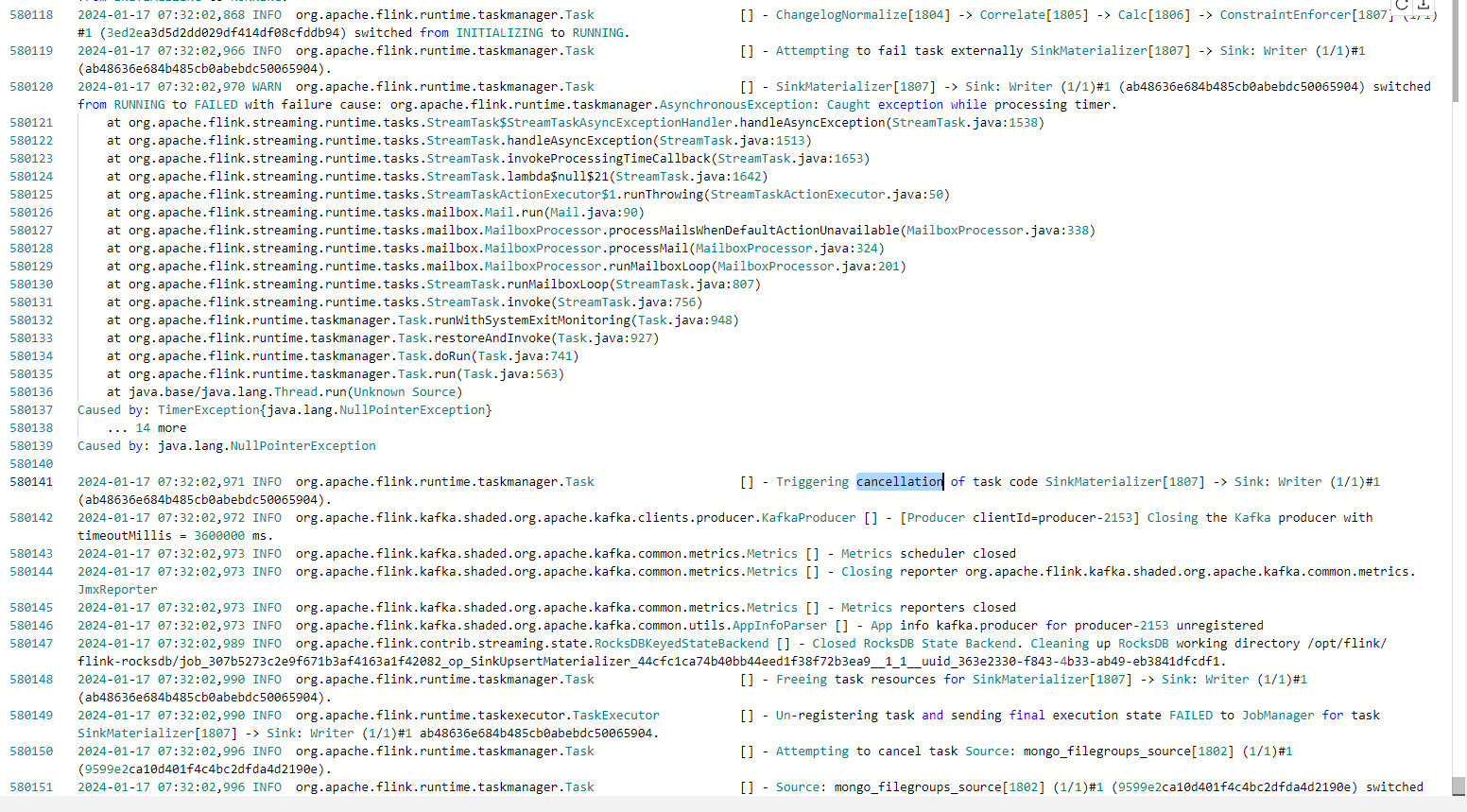
根据您提供的错误信息和截图,问题可能出在以下几个方面:
- 参数设置错误:请检查您的Flink CDC配置中的'sink.buffer-flush.interval'和'sink.buffer-flush.max-rows'参数是否正确设置。这两个参数分别表示缓冲区刷新的时间间隔和最大行数。请确保它们的值是合法的整数。
- 依赖版本不兼容:请检查您的Flink CDC连接器(如Debezium)和Kafka的版本是否兼容。如果不兼容,可能会导致配置错误或运行时错误。您可以查阅相关文档或社区讨论,了解不同版本之间的兼容性情况。
- 日志输出:查看Flink CDC的日志输出,以获取更详细的错误信息。日志中可能会包含有关错误的详细信息,帮助您定位问题所在。
- 网络连接问题:如果您的网络连接不稳定或存在防火墙限制,可能导致与Kafka的连接出现问题。请检查您的网络环境,确保Flink CDC能够正常连接到Kafka。
- 资源限制:如果Flink集群的资源不足,可能导致任务无法正常运行。请检查您的Flink集群资源使用情况,如有需要,可以调整资源配置以满足需求。
建议您根据以上建议逐一排查问题,找到具体原因并进行修复。
关于本问题的更多回答可点击原文查看:/ask/592317
问题二:Flink CDC中,想了解Flink 3.0是否提供了针对MySQL连接数限制的技术优化措施?
Flink CDC中,想了解Flink 3.0是否提供了针对MySQL连接数限制的技术优化措施?
参考回答:
针对Flink CDC从MySQL实时同步到目标库时遇到的MySQL连接数过多问题,可以考虑以下解决方案:
- 优化MySQL连接配置:可以通过调整MySQL的连接参数来减少连接数。例如,可以增加
max_connections的值,或者调整wait_timeout和interactive_timeout的值,以减少空闲连接的占用。 - 使用连接池:可以使用连接池来管理MySQL连接,避免频繁创建和关闭连接。连接池可以复用已经建立的连接,减少连接数。
- 限制并发度:在Flink任务中,可以通过限制并发度来控制同时处理的数据量。可以通过设置
StreamExecutionEnvironment的setMaxParallelism()方法来限制并发度。 - 优化SQL语句:对于需要执行多个INSERT语句的情况,可以考虑将多个INSERT语句合并为一个语句,以减少连接数。但是需要注意,这可能会影响数据的一致性和完整性。
- 考虑使用其他数据同步工具:如果以上方案无法满足需求,可以考虑使用其他数据同步工具,如Apache Nifi、DataX等,这些工具可能具有更好的性能和可扩展性。
需要注意的是,具体的解决方案需要根据实际的业务需求和环境进行选择和调整。
关于本问题的更多回答可点击原文查看:/ask/592319
问题三:Flink CDC里想升级下flink版本,现在是1.7版本好还是1.8版本好一些?
Flink CDC里想升级下flink版本,现在是1.7版本好还是1.8版本好一些?
参考回答:
1.8吧
关于本问题的更多回答可点击原文查看:/ask/592320
问题四:Flink CDC里这个cache内存咋占用那么大 怎么才能让它把资源释放出来 ?
Flink CDC里这个cache内存咋占用那么大 怎么才能让它把资源释放出来 ? 
参考回答:
Flink CDC的缓存内存占用较大可能是由于以下几个原因导致的:
- 数据量过大:如果CDC源的数据量非常大,缓存中需要存储大量的数据,从而导致缓存内存占用较大。可以考虑通过调整并行度或者使用分区来减少单个任务处理的数据量,从而降低缓存内存的占用。
- 缓存配置不合理:Flink CDC提供了一些缓存相关的配置参数,例如
debezium-source.buffer-flush.max-rows用于控制缓存中最大行数,debezium-source.buffer-flush.interval用于控制缓存刷新的时间间隔。可以尝试调整这些参数来减小缓存内存的占用。 - 长时间运行:如果Flink CDC任务长时间运行,缓存中的数据可能会逐渐积累,导致内存占用逐渐增加。可以尝试定期清理缓存,释放不再需要的数据。
- 其他因素:除了上述原因外,还可能存在其他因素导致缓存内存占用较大,例如数据结构设计不合理、内存泄漏等。可以通过分析任务的内存使用情况,找出具体的原因并进行优化。
针对以上情况,可以尝试以下方法来释放缓存内存:
- 调整缓存配置:根据实际需求和数据量大小,合理调整缓存相关的配置参数,例如减小缓存的最大行数或者缩短缓存刷新的时间间隔。
- 清理缓存:在合适的时机,手动触发缓存的清理操作,释放不再需要的数据。可以通过调用
clear()方法来清空缓存。 - 优化数据处理逻辑:检查数据处理的逻辑,确保没有不必要的数据存储或者冗余的操作。优化数据结构,减少内存占用。
- 重启任务:如果缓存内存占用过大且无法通过调整配置或者清理缓存来解决,可以考虑重启任务,释放缓存内存并重新开始处理数据。
关于本问题的更多回答可点击原文查看:/ask/592321
问题五:Flink CDC里如果要用timestamp启动, mysql数据库是不是要打开gtid?
Flink CDC里如果要用timestamp启动, mysql数据库是不是要打开gtid? 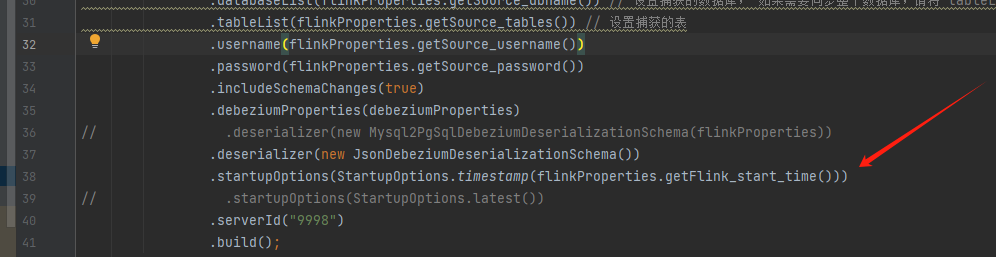
参考回答:
如果没有主备这种,cdc默认加上和主的gtid。如果你同步的是从库,那mysql是最好开启gtid的。
关于本问题的更多回答可点击原文查看:/ask/592323
