2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
1.大数据处理的常用方法
大数据处理目前比较流行的是两种方法,一种是离线处理,一种是在线处理,基本处理架构如下:
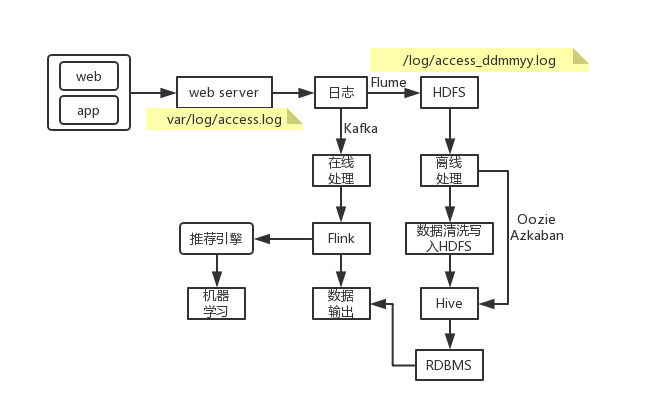
在互联网应用中,不管是哪一种处理方式,其基本的数据来源都是日志数据,例如对于web应用来说,则可能是用户的访问日志、用户的点击日志等。
如果对于数据的分析结果在时间上有比较严格的要求,则可以采用在线处理的方式来对数据进行分析,如使用Flink进行处理。比较贴切的一个例子是天猫双十一的成交额,在其展板上,我们看到交易额是实时动态进行更新的,对于这种情况,则需要采用在线处理。下面要介绍的是实时数据处理方式,即基于Flink的在线处理,在下面给出的完整案例中,我们将会完成下面的几项工作:
-
1.如何一步步构建我们的实时处理系统(Flume+Kafka+Flink+Redis)
-
2.实时处理网站的用户访问日志,并统计出该网站的PV、UV
-
3.将实时分析出的PV、UV动态地展示在我们的前面页面上
如果你对上面提及的大数据组件已经有所认识,或者对如何构建大数据实时处理系统感兴趣,那么就可以尽情阅读下面的内容了。
需要注意的是,核心在于如何构建实时处理系统,而这里给出的案例是实时统计某个网站的PV、UV,在实际中,基于每个人的工作环境不同,业务不同,因此业务系统的复杂度也不尽相同,相对来说,这里统计PV、UV的业务是比较简单的,但也足够让我们对大数据实时处理系统有一个基本的、清晰的了解与认识,是的,它不再那么神秘了。
2.实时处理系统架构
我们的实时处理系统整体架构如下:
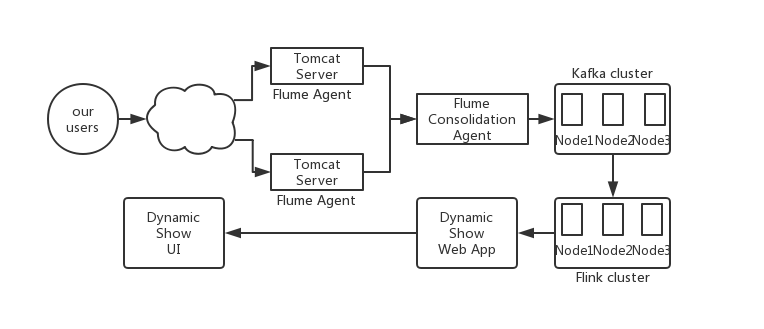
即从上面的架构中我们可以看出,其由下面的几部分构成:
-
Flume集群
-
Kafka集群
-
Flink集群
从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间打通(从上面的图示中也能很好地说明这一点),即需要做各个系统之前的整合,包括Flume与Kafka的整合,Kafka与Flink的整合。当然,各个环境是否使用集群,依个人的实际需要而定,在我们的环境中,Flume、Kafka、Flink都使用集群。
3.Flume+Kafka整合
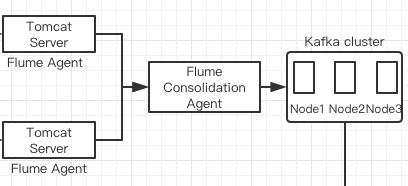
3.1整合思路
对于Flume而言,关键在于如何采集数据,并且将其发送到Kafka上,并且由于我们这里了使用Flume集群的方式,Flume集群的配置也是十分关键的。而对于Kafka,关键就是如何接收来自Flume的数据。从整体上讲,逻辑应该是比较简单的,即可以在Kafka中创建一个用于我们实时处理系统的topic,然后Flume将其采集到的数据发送到该topic上即可。
3.2整合过程:Flume集群配置与Kafka Topic创建
在我们的场景中,两个Flume Agent分别部署在两台Web服务器上,用来采集Web服务器上的日志数据,然后其数据的下沉方式都为发送到另外一个Flume Agent上,所以这里我们需要配置三个Flume Agent.
3.2.1.1 Flume Agent01
该Flume Agent部署在一台Web服务器上,用来采集产生的Web日志,然后发送到Flume Consolidation Agent上,创建一个新的配置文件
flume-sink-avro.conf,其配置内容如下:
#########################################################
##
##主要作用是监听文件中的新增数据,采集到数据之后,输出到avro
## 注意:Flume agent的运行,主要就是配置source channel sink
## 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
#########################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听文件中的新增数据 exec
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/data-clean/data-access.log
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = uplooking03
a1.sinks.k1.port = 44444
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置完成后, 启动Flume Agent,即可对日志文件进行监听:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-sink-avro.conf >/dev/null 2>&1 &
3.2.1.2 Flume Agent02
该Flume Agent部署在一台Web服务器上,用来采集产生的Web日志,然后发送到Flume Consolidation Agent上,创建一个新的配置文件
flume-sink-avro.conf,其配置内容如下:
#########################################################
##
##主要作用是监听文件中的新增数据,采集到数据之后,输出到avro
## 注意:Flume agent的运行,主要就是配置source channel sink
## 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
#########################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听文件中的新增数据 exec
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/data-clean/data-access.log
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = uplooking03
a1.sinks.k1.port = 44444
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置完成后, 启动Flume Agent,即可对日志文件进行监听:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-sink-avro.conf >/dev/null 2>&1 &
3.2.1.2 Flume Consolidation Agent
该Flume Agent用于接收其它两个Agent发送过来的数据,然后将其发送到Kafka上,创建一个新的配置文件
flume-source_avro-sink_kafka.conf,配置内容如下:
#########################################################
##
##主要作用是监听目录中的新增文件,采集到数据之后,输出到kafka
## 注意:Flume agent的运行,主要就是配置source channel sink
## 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
#########################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听avro
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
#对于sink的配置描述 使用kafka做数据的消费
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = f-k-s
a1.sinks.k1.brokerList = uplooking01:9092,uplooking02:9092,uplooking03:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
#对于channel的配置描述 使用内存缓冲区域做数据的临时缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置完成后, 启动Flume Agent,即可对avro的数据进行监听:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-source_avro-sink_kafka.conf >/dev/null 2>&1 &
3.2.2 Kafka配置
在我们的
Kafka中,先创建一个topic,用于后面接收Flume采集过来的数据:
kafka-topics.sh --create --topic f-k-s --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181 --partitions 3 --replication-factor 3
4.Kafka+Flink整合
Flink 提供了特殊的Kafka Connectors来从Kafka topic中读取数据或者将数据写入到Kafkatopic中,Flink的Kafka Consumer与Flink的检查点机制相结合,提供exactly-once处理语义。为了做到这一点,Flink并不完全依赖于Kafka的consumer组的offset跟踪,而是在自己的内部去跟踪和检查。
Kafka Consumer
Flink的kafka consumer叫做FlinkKafkaConsumer08(对于Kafka 0.9.0.X来说是09 等),它提供了对一个或者多个Kafka topic的访问。
FlinkKafkaConsumer08、09等的构造函数接收以下参数: 1、topic名称或者名称列表 2、反序列化来自kafka的数据的DeserializationSchema/Keyed Deserialization Schema 3、Kafka consumer的一些配置,下面的配置是必需的: "bootstrap.servers"(以逗号分隔的Kafka brokers列表) "zookeeper.connect"(以逗号分隔的Zookeeper 服务器列表) "group.id"(consumer组的id)
例如: Java 代码:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
// only required for Kafka 0.8
properties.setProperty("zookeeper.connect", "localhost:2181");
properties.setProperty("group.id", "test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer08<>("topic", new SimpleStringSchema(), properties));
Scala 代码:
val properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
// only required for Kafka 0.8
properties.setProperty("zookeeper.connect", "localhost:2181");
properties.setProperty("group.id", "test");
stream = env
.addSource(new FlinkKafkaConsumer08[String]("topic", new SimpleStringSchema(), properties))
.print
当前FlinkKafkaConsumer的实现会建立一个到Kafka客户端的连接来查询topic的列表和分区。
为此,consumer需要能够访问到从提交Job任务的服务器到Flink服务器的consumer,如果你在客户端遇到任何Kafka Consumer的问题,你都可以在客户端日志中看到关于请求失败的日志。
Kafka Consumers 和Fault Tolerance
Flink的checkpoint启用之后,Flink Kafka Consumer将会从一个topic中消费记录并以一致性的方式周期性地检查所有Kafka偏移量以及其他操作的状态。Flink将保存流程序到状态的最新的checkpoint中,并重新从Kafka中读取记录,记录从保存在checkpoint中的偏移位置开始读取。
checkpoint的时间间隔定义了程序在发生故障时可以恢复多少。
同时需要注意的是Flink只能在有足够的slots时才会去重启topology,所以如果topology由于TaskManager丢失而失败时,任然需要有足够的slot可用。Flink on YARN支持YARN container丢失自动重启。
5.Flink+Redis整合
其实所谓Flink和Redis的整合,指的是在我们的实时处理系统中的数据的落地方式,即在Flink中包含了我们处理数据的逻辑,而数据处理完毕后,产生的数据处理结果该保存到什么地方呢?显然就有很多种方式了,关系型数据库、NoSQL、HDFS、HBase等,这应该取决于具体的业务和数据量,在这里,我们使用Redis来进行最后分析数据的存储。
所以实际上做这一步的整合,其实就是开始写我们的业务处理代码了,因为通过前面Flume-Kafka-FLink的整合,已经打通了整个数据的流通路径,接下来关键要做的是,在Flink中,如何处理我们的数据并保存到Redis中。
Flink Redis Connector
Flink自带的connector提供了一种简洁的写入Redis的方式,只需要在项目中加入下面的依赖即可实现。
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
兼容版本:Redis 2.8.5 注意:Flink的connector并不是Flink的安装版本,需要写入用户的jar包并上传才能使用。
6.数据可视化处理
数据可视化处理目前我们需要完成两部分的工作:
-
1.开发一个Web项目,能够查询Redis中的数据,同时提供访问的页面
-
2.自行开发或找一个符合我们需求的前端UI,将Web项目中查询到的数据展示出来
对于Web项目的开发,因个人的技术栈能力而异,选择的语言和技术也有所不同,只要能够达到我们最终数据可视化的目的,其实都行的。这个项目中我们要展示的是pv和uv数据,难度不大,因此可以选择Java Web,如Servlet、SpringMVC等,或者Python Web,如Flask、Django等,Flask我个人非常喜欢,因为开发非常快,但因为前面一直用的是Java,因此这里我还是选择使用SpringMVC来完成。
至于UI这一块,我前端能力一般,普通的开发没有问题,但是要做出像上面这种地图类型的UI界面来展示数据的话,确实有点无能为力。好在现在第三方的UI框架比较多,对于图表类展示的,比如就有highcharts和echarts,其中echarts是百度开源的,有丰富的中文文档,非常容易上手,所以这里我选择使用echarts来作为UI,并且其刚好就有能够满足我们需求的地图类的UI组件。
对于页面数据的动态刷新有两种方案,一种是定时刷新页面,另外一种则是定时向后端异步请求数据。
目前我采用的是第一种,页面定时刷新,有兴趣的同学也可以尝试使用第二种方法,只需要在后端开发相关的返回JSON数据的API即可。
7.总结
那么至此,从整个大数据实时处理系统的构建到最后的数据可视化处理工作,我们都已经完成了,可以看到整个过程下来涉及到的知识层面还是比较多的,不过我个人觉得,只要把核心的原理牢牢掌握了,对于大部分情况而言,环境的搭建以及基于业务的开发都能够很好地解决。
写此文,一来是对自己实践中的一些总结,二来也是希望把一些比较不错的项目案例分享给大家,总之希望能够对大家有所帮助。
