2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
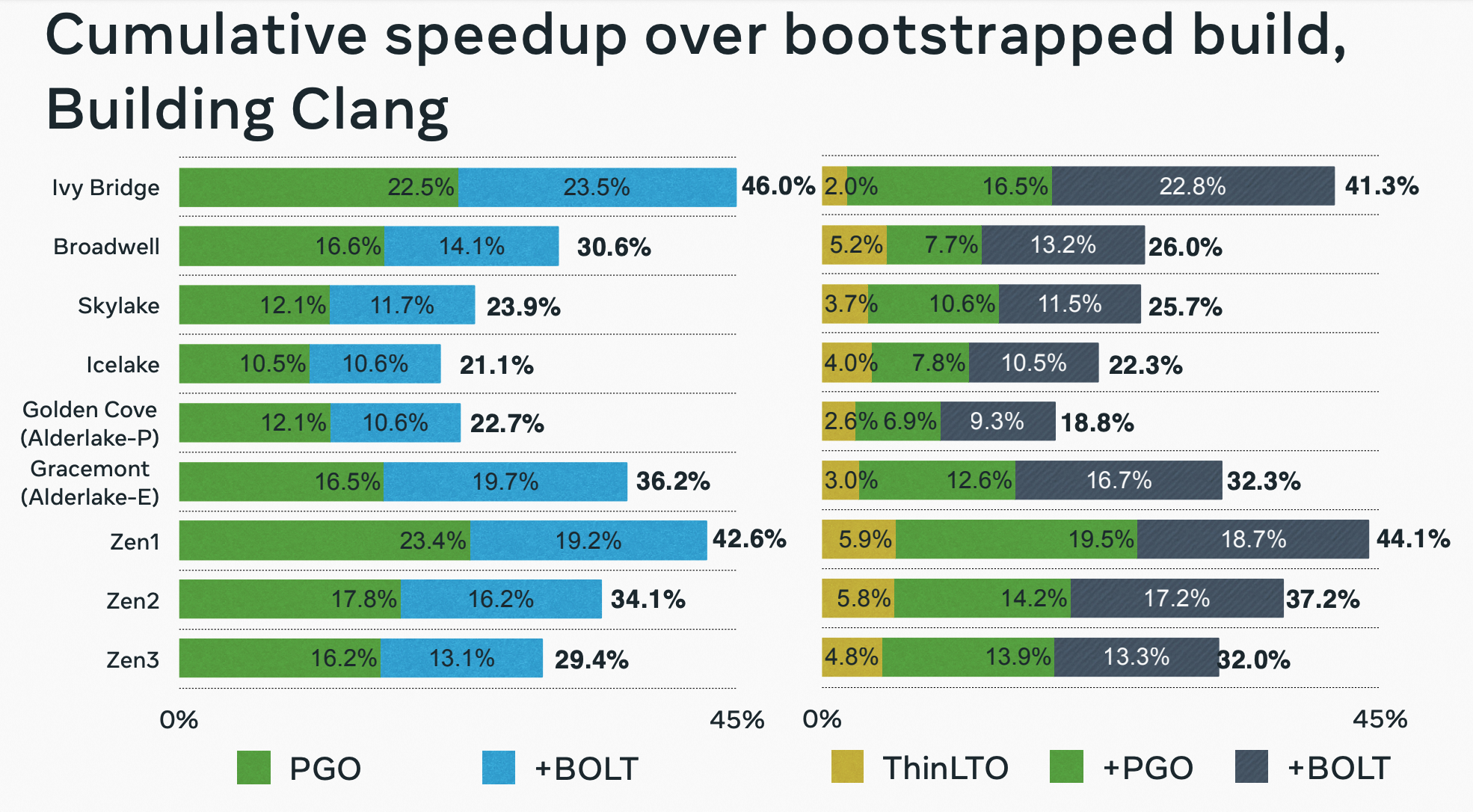
BOLT 二进制反馈优化技术
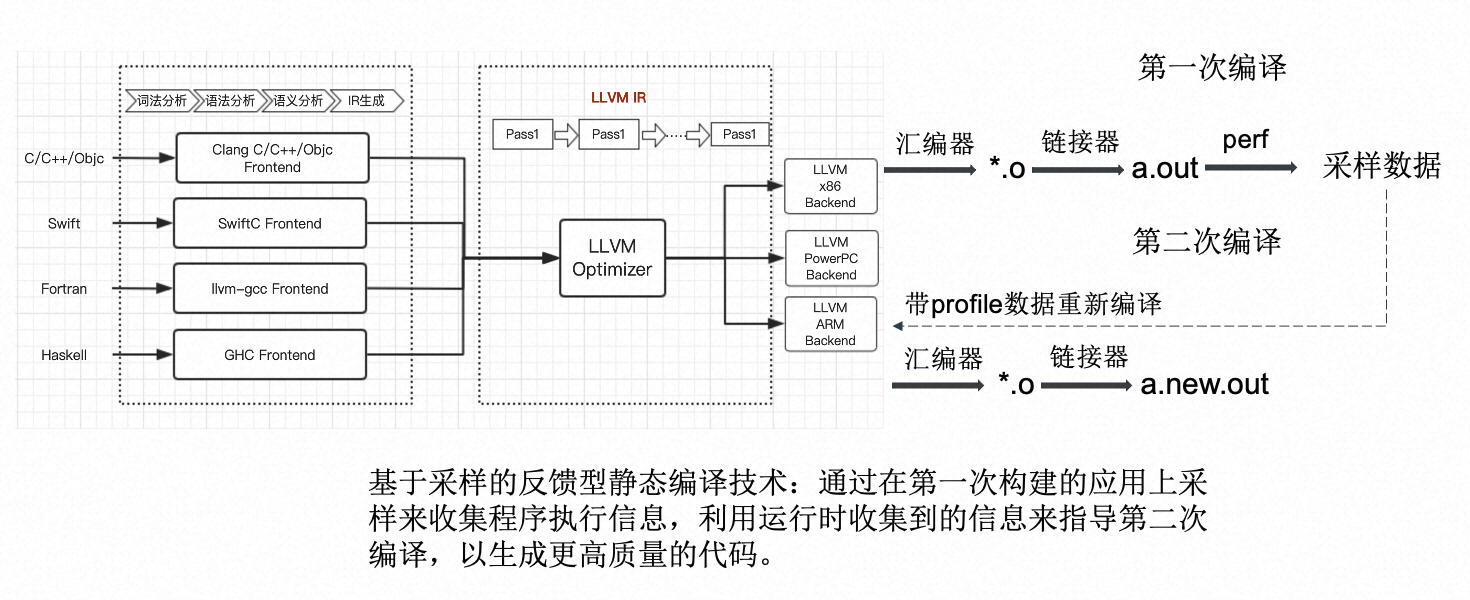
大型应用的代码往往达到数十甚至上百MB,这导致在程序执行时缓存机制无法充分利用,导致大量时间花费在CPU和内存链路上。通过对热点函数的布局进行优化,我们可以更好地利用CPU cache,从而获得较为可观的性能提升。针对这一问题,在编译技术上有PGO和Bolt两种解决办法,两者都是一种通过收集程序在运行时如跳转,调用关系,函数热度等执行信息,这些收集到的程序运行情况数据(profile data),可以更好地指导一些程序优化的策略,如是否对函数进行内联,以及对基本块和函数布局的排布来提高特定场景下的程序性能。
BOLT 的特点
PGO和Bolt两种方式都是基于收集到程序运行数据进行优化,但存在一定差异。不同于PGO通过编译器进行再次编译,Bolt是一个二进制优化和布局工具,直接对可执行文件/动态库ELF文件进行解析和进行修改,无需再次通过编译器进行构建。

在业务落地和优化结果方面,Bolt和PGO主要有以下两个方面的区别。
- Bolt在函数和基本块布局上能拿到更好的效果。
编译器对函数的布局通常都是在编译优化的最后一步。在使用PGO的过程中,一个无法避免的问题就是函数内联等优化会导致上下文发生变化进而收集数据不准确,尤其是基本块排布需要的分支概率。而Bolt避免了callsite等信息的改动,专注于函数和函数内部的排布进行优化,可以得到更好的效果。
因此,Bolt和PGO在编译优化方法中并不是互斥的,是可以相互弥补的。在实践中,我们发现PGO和Bolt的优化在很多场景下是可以串联的,同时使用可以获得更好的性能收益。
- Bolt在有大型项目的部署会更加友好。
这里的部署友好主要体现在三个方面,1) 更容易被集成到应用的构建系统中。Bolt在构建脚本中无需重复编译器的编译流程,这对于很多构建方式复杂的应用方来说构建修改更加友好,更方便落地。2)更快地构建速度。无需重复编译器流程也以为者通过Bolt进行优化能拿到比PGO更快的构建速度,比如编译器构建一次要20-30分钟的Clang使用Bolt只需要20~30秒。这对于单次编译就长达数小时的应用来说显然更容易接受。 3)Bolt可以对第三方的静态库进行优化。大型应用中往往很多第三方库的依赖,Bolt的好处之一就是可以其可以对静态链接进来的第三方库进行优化,而PGO则需要对第三方库逐个重新构建,在直接依赖于第三方静态库的场景中无法使用。
BOLT 在 Arm 当前现状
由于Bolt社区中,Arm后端当前只可以通过非LBR形式的运行时数据,数据无法记录函数调用关系和条件跳转指令上跳转发生的比率,因此Bolt后的结果相较X86差距较大。
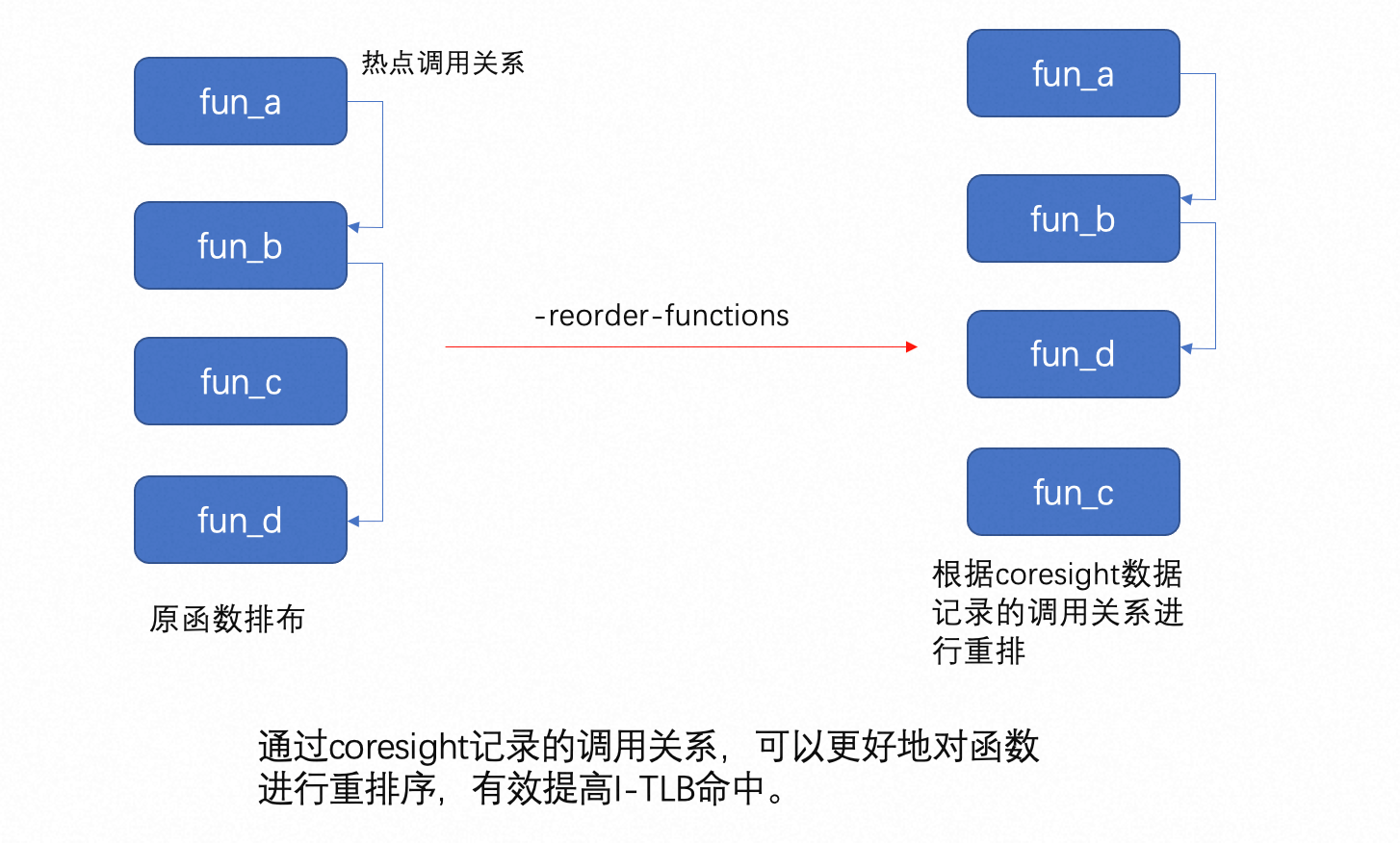
而通过coresight采样的数据有更精准的信息,我们能在倚天上获得同X86/LBR相同的精度,如跳转指令的起始和终止位置,以及函数间的调用。因此使用coresight采集出的数据能匹配到源代码中函数内的跳转发生方向和函数间的调用关系,对代码段进行重新布局提高热代码密度,降低I-cache/I-TLB miss进而优化程序性能表现。而非coresight的perf采样仅能获得函数及采样时pc相对于函数的偏移,无法满足反馈优化所需的信息。

其次,由于Arm后端尚不支持插桩的方式,当使用coresight数据时仍有不少bug,存在一定风险。 Alibaba Cloud Compiler对Bolt进行了集成,针对Arm和X86后端进行修复和优化,并在倚天上完成了多个项目的POC,目前在倚天上测试效果较Bolt on X86总体上有更好的性能提高。