2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
业务背景
自如目前线上有基于 Hive 的离线数仓和基于 Flink、Kafka 的实时数仓,随着业务发展,我们也在探索引入湖仓一体的架构更好的支持业务,我们对比了 Iceberg、Hudi、Paimon 后,最终选择 Paimon 作为我们湖仓一体的存储引擎,本文分享下自如在引入 Paimon 做数据集成的一些探索实践。
一、原始接入
自如目前使用的业务库入 Hive 的简略逻辑图如下(拿 MySQL 举例)
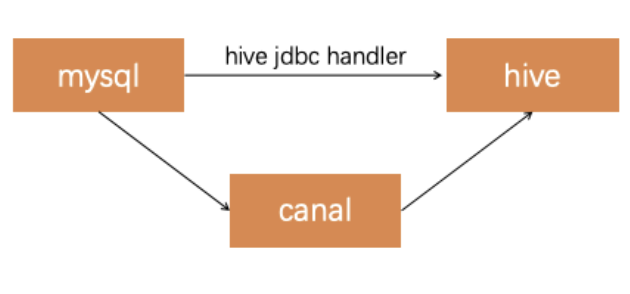
通过 Hive JDBC Handler 每天一个快照拉取数据到 Hive,如果需要更高新鲜度的业务场景,使用 canal 把数据接入 Kafka,然后通过 Flink 写入 HDFS,再通过 Hive Merge 方式合并获得最高 10 分钟延迟新鲜度的数据。这个架构运行起来有几个问题:
基于 Hive JDBC Handler 拉取数据每天都是一个全量业务库数据,表比较大的情况下,对业务库压力比较大,如果增量拉取也需要业务线增加 lastmodified 字段,业务不见得愿意配合修改,分库分表场景支持起来也比较繁琐
基于 canal 的准实时线由于链路比较长,出现问题后也比较难排查
引入 Paimon 之后数据接入的简略逻辑图如下:
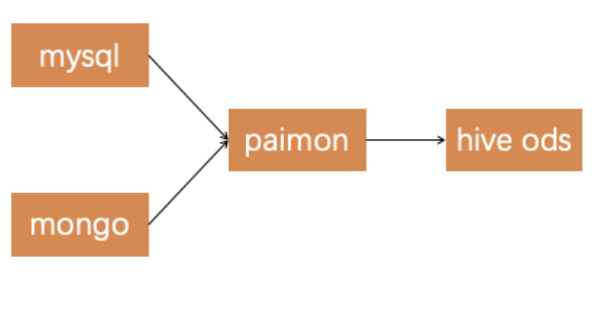
在整合 Paimon 到大数据平台后,我们对数据接入流程进行了很大简化。具体来说,Hive ODS 层的数据来源已经从原来的原始业务表迁移到了 Paimon 表。在我们的 T+1 离线分析场景中,仍然使用 Hive ODS 表;而对于需要实时数据的场景,则直接查询 Paimon 表。这种做法的一个显著优点是,夜间的批处理作业不再因为从原始业务数据库拉取数据而遭受延误。
我们还向社区贡献了 “Mongo 入 Paimon” 的实现方案,以支持 Mongodb 数据源到 Paimon 的数据同步https://cwiki.apache.org/confluence/display/Paimon/PIP-7%3A+SyncAction+based+on+MongoDB。
尽管 Paimon 提供了显著的效率提升,但我们仍然保持使用 Hive ODS 表,而没有直接以 Paimon 表替代它们。主要原因包括:
查询语法的一致性:为了确保上层查询逻辑不受影响,我们需要维持 Paimon 的标签(tag)查询和 Hive 的分区查询在语法上的一致性。这样做可以避免对现有大量 ETL任务进行修改。
历史数据的动态路由:在查询 Paimon 的标签时,如果数据属于历史的 Hive 分区数据,我们还需要实现一个动态路由机制,以确保查询能够正确地指向这些历史数据。
为了进一步优化这个流程,我们计划在未来和社区一起解决上述两个问题。这将进一步简化数据架构,提供更加灵活和高效的数据查询能力。
二、打宽接入
Paimon 中的数据接入直接打宽的实现使我们比较感兴趣的,但是 Paimon 中目前只支持主键打宽,不支持外键打宽,实际业务场景中很多都涉及外键打宽,对于这个场景我们做了自己的一个实现, 外键打宽涉及的核心问题是主外键关系的存储,我们把这个关系存储到外置的存储(比如 Redis 或者 MySQL)中。举例来说宽表构建逻辑如下:

如上图 A、B、C 三张表需要打宽按照主键 m 进行打宽,A、B 两张表都有主键 m,但是 C 没有,C 表和 B 表用 n 字段关联。

如上图,如果 A 表或者 B 表中来了一条数据,直接在 Flink 中 Lookup Join 关联 A、B、C 三张表,写入到下游宽表中(Paimon 或者 ClickHouse)。
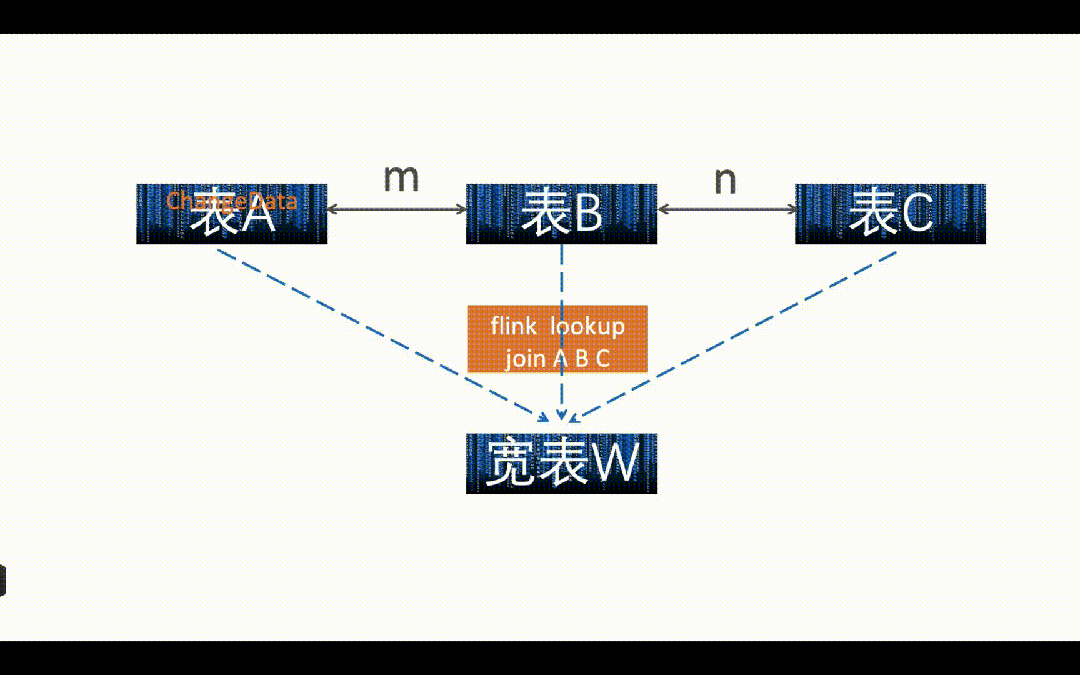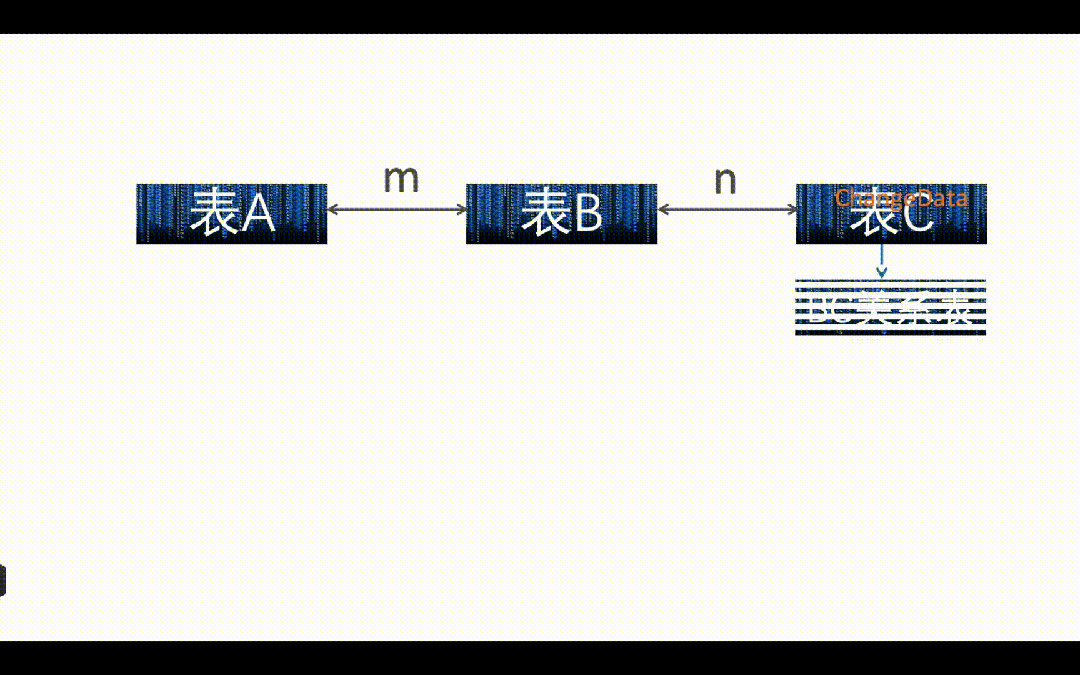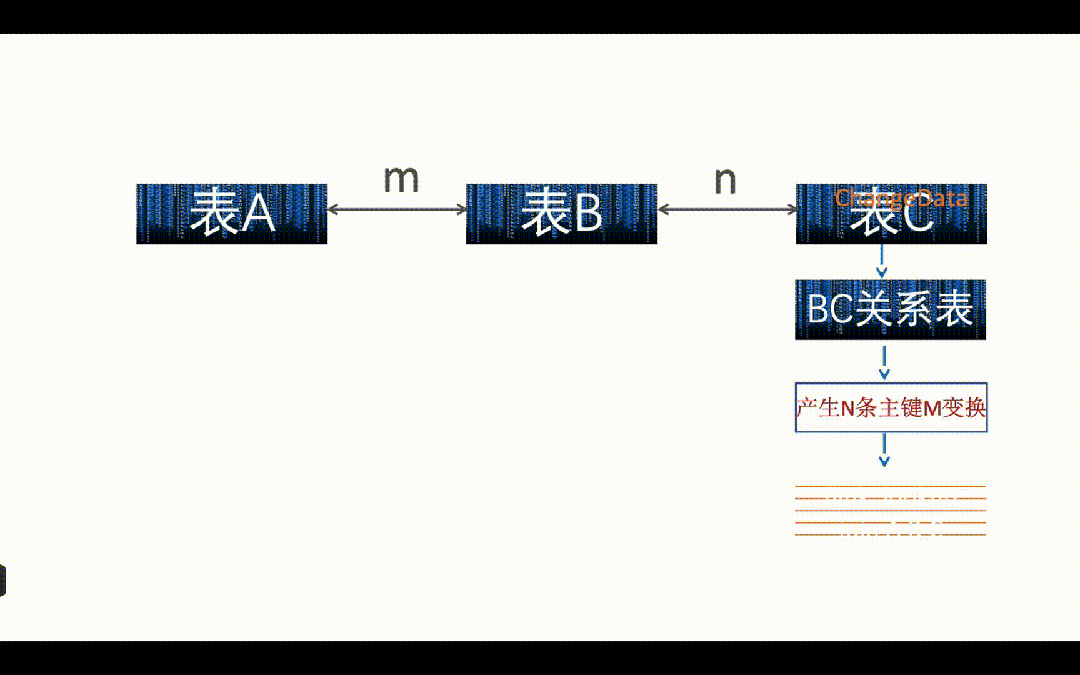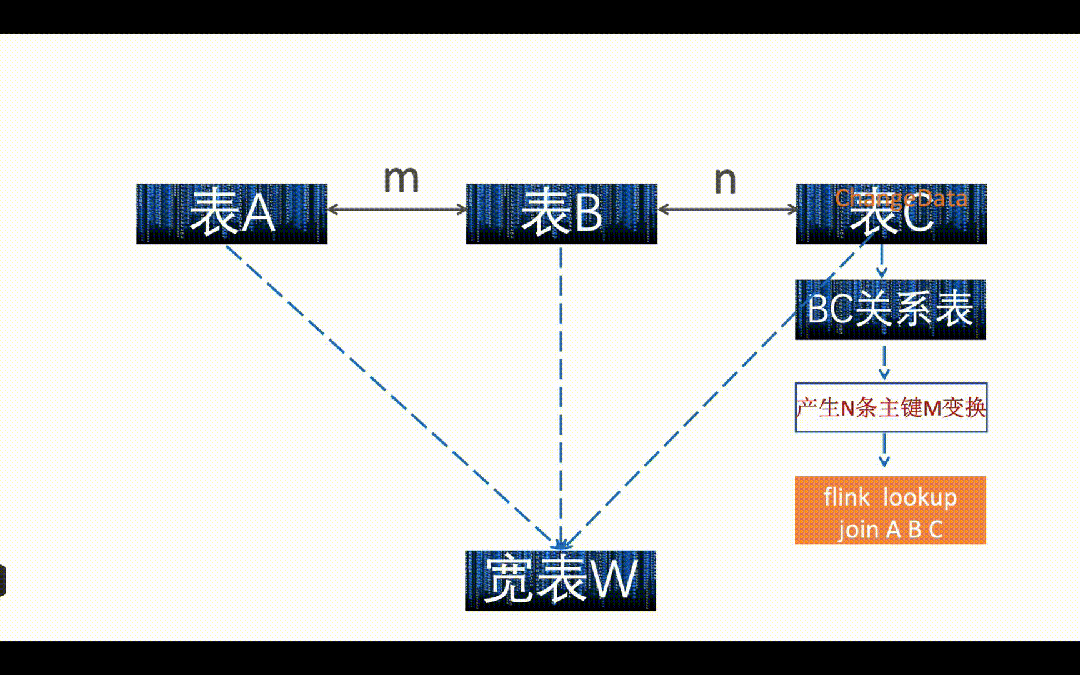
如上图所示,如果 C 表来了一条数据,需要从 B 表和 C 表的关系表中,查询到 C 表这条数据的变更涉及到多少主键 m 的变更,然后把影响到的主键 m 值全部重新再关联一遍写入到下游表。
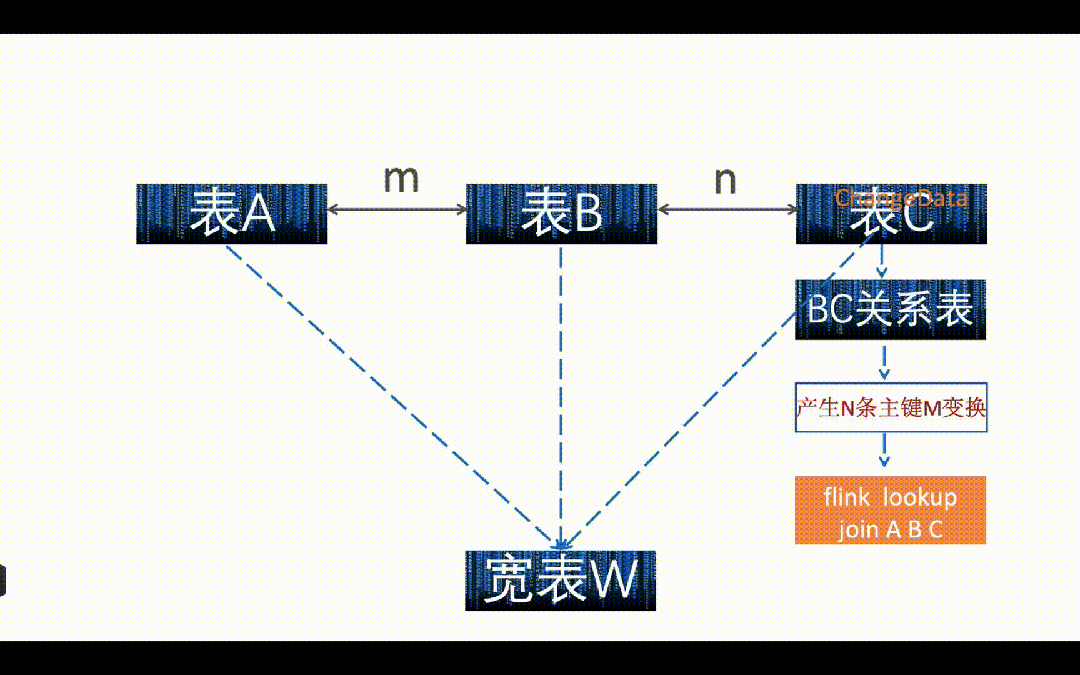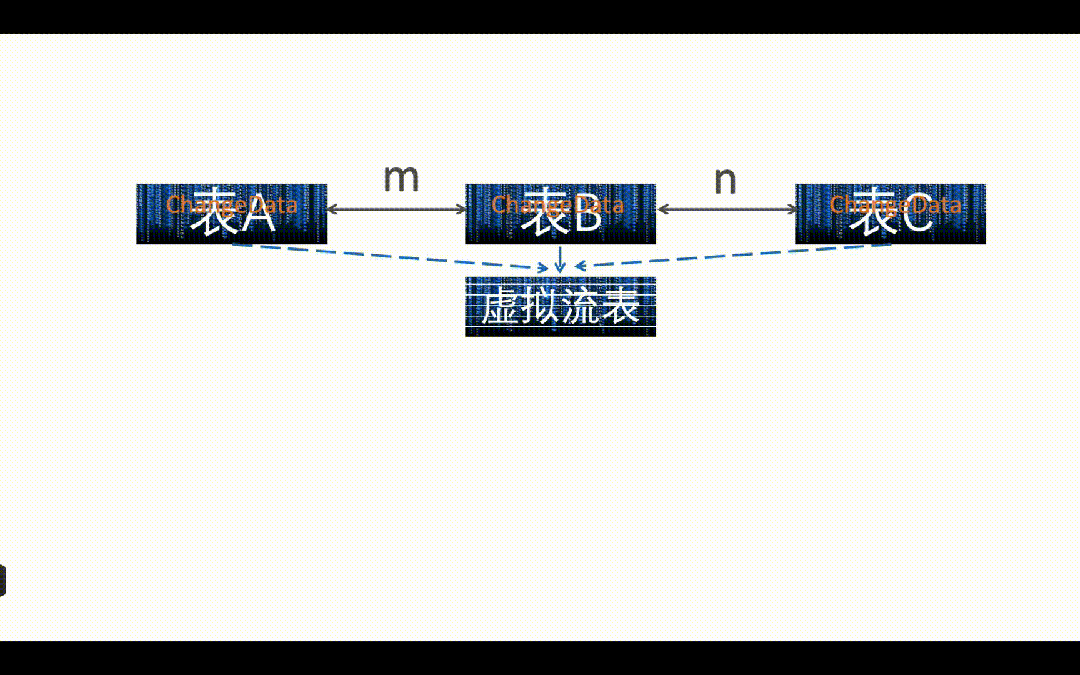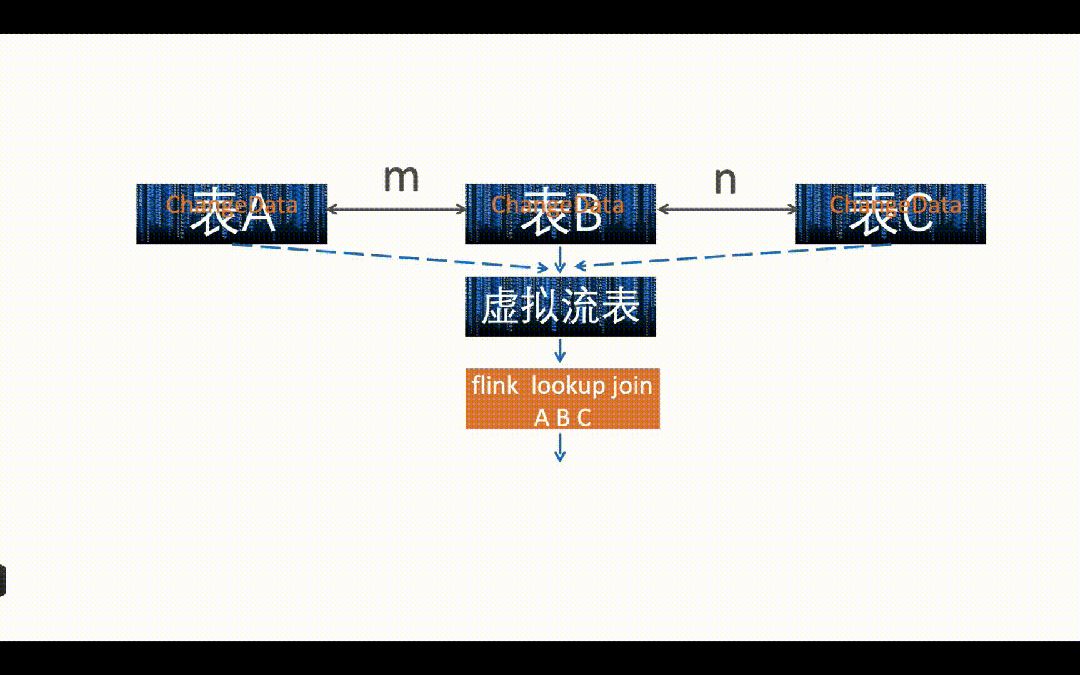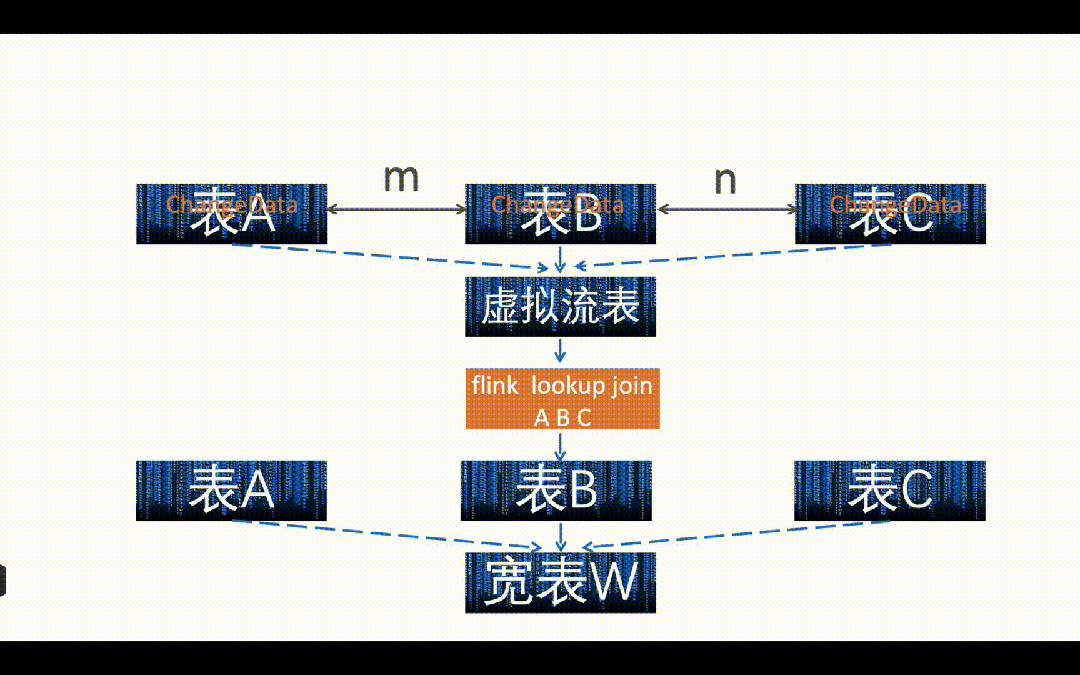
如上图所示,实际业务场景中是 A、B、C 三张表都会发生变化,就需要把所有表的变化影响到多少主键 m 变更都记录下来,并且重新关联写入下游宽表,相当于进行一个“暴力计算”。这里我们用的是 Flink Lookup Join, A、B、C 都是维表,那 Flink Lookup Join 的流表是哪个?其实这里我们构建了一个“虚拟流表”,这个流表只有一个字段就是主键 m, A、B、C 表的任何变更,涉及到多少的主键 m 的变更,都实时写入到这个虚拟流表中,这个虚拟流表可以用 Kafka 或者 Paimon 作为载体实现。
简单的逻辑如上面所述,实际真正使用的时候还会涉及业务的 A、B、C 源表并不能直接 Lookup Join,还需要构建对应的镜像表、构建外键索引表。具体的代码实现可以看下面的全部基于 MySQL 实现的简化版本的一个例子https://github.com/CNDPP/widetable/tree/main

代码中的例子是三张 MySQL 表按照 bus_opp_num 字段打宽写入一张 MySQL 表,从这个简化例子可以了解具体实现的细节。
三、下一步规划
1、原始表接入中使用 Paimon tag 替换掉目前的 Hive 分区,减少 HDFS 空间占用
2、Paimon 社区规划中也有支持外键打宽的规划,跟随社区引入测试使用
3、把 Paimon 引入到后续的数仓 ETL 加工之中,利用湖上的 zorder 等特性加速离线跑批
在落地 Paimon 实践的过程中,深切的感受到了 Paimon 社区的活跃和热情,之信老师给我们非常多的耐心指导,帮助我们在生产环境中快速落地,感谢 Paimon 社区,祝福 Paimon 越来越好!

Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可微信扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!

更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
0 元试用 实时计算 Flink 版(5000CU*小时,3 个月内)
了解活动详情:https://free.aliyun.com/?pipCode=sc




