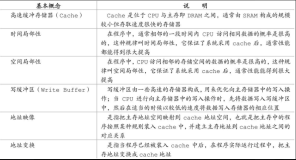
背景介绍
将多核多线程程序从x86架构的CPU迁移到Arm架构的CPU上往往会面临弱内存序问题。这个问题是迁移过程中的重大阻碍,也是很多业务方斟酌是否应该迁移到Arm机器上的一个关注焦点。因此如何正确且高效地解决这个问题意义重大,关乎Arm和倚天的生态建设。
有许多团队曾经遇到过此类问题,给业务稳定性带来隐患。
倚天团队针对弱内存序问题追本溯源,提供一个可以从根本上能够解决业务弱内存序困扰并能充分体验倚天高性能的解决方案。
弱内存序问题本质剖析
弱内存序问题产生的根本原因是两种架构的CPU具有不同的内存模型(x86:Total Store Order,Arm:Weak Memory Order)。
如下图,x86架构下write memory操作写入内存必须经过write buffer,这是一个FIFO结构,可以严格保证顺序;只有read memory操作可以直接从write buffer或内存中读取,因此可能乱序到write memory之前。而Arm架构下不存在这样的数据结构保证顺序,所有的write memory和read memory操作都可能互相被重排。这导致迁移后的程序在多核的环境中往往会出现由弱内存模型引发的内存读写的乱序现象,很多情况下这种乱序现象与程序原本的逻辑相违背。

下面是一个程序示意,在x86上该程序不会出现assert错误由TSO保证了内存访问按照代码逻辑顺序执行,而迁移到Arm上时,该程序很可能出现assert断言错误,原因是thread1对变量a和变量b的访问出现了乱序,变量a在变量b被赋值之前并没有被正确赋值,乱序到了b = 1对应的指令之后。
int a = 0; int b = 0; ------------------------------------ /* thread1 CPU1 */ a = 1; // Need Barrier b = 1; ------------------------------------ /* thread2 CPU2 */ while(b != 1); // Need Barrier assert(a == 1);
简单的解决方案是在程序中的乱序风险位置添加memory barrier,在Arm架构下我们通常使用类似“dmb ish”这样的指令。
一般我们在迁移过程中都是通过专家对程序进行逻辑分析和排查来解决这类问题,然而人工排查程序中存在的乱序问题对于大型程序来说费力且无法在正确性上得到保证,存在大量的漏报现象,因此亟需自动化的工具协助人工进行定位和检测。
我们的方案:Hawkeyes
Hawkeyes工具即是我们带来的弱内存序问题解决方案
workflow说明

原理介绍
基于Tsan抓取memory access conflicts
可以在前面的例子中看到出现弱内存序问题的场景实际上可以分解成多线程对于多个全局变量的异步访问存在逻辑顺序规定的问题。因此要定位弱内存序问题必须首先定位内存访问冲突,在此基础上我们可以通过分析同一个线程内。
我们基于Thread Sanitizer(Tsan)这一集成在gcc中的Data Race检测器来实现我们的内存冲突检测工具。通过定制化Tsan,使其在程序运行时能够动态地抓取并输出所有对于同一块内存区域进行过访问的线程及其调用栈信息。
具体的技术细节是通过编译时对所有内存访问指令位置插桩,在运行时通过shadow memory存储记录线程访问相关的信息,再在每次对shadow memory作更新时对这些存储的信息和新记录的信息进行处理并进行冲突分析。
插桩示意图如下:

shadow memory检测

基于Instruction window对冲突区域作过滤
指令窗口(Instruction Window)是现代处理器的硬件架构中被广泛使用的一个结构,可以简单理解为处于同一个指令窗口大小内的指令会被乱序发射,而指令窗口外的指令则互相之间不会存在乱序现象,指令窗口的大小在不同的处理器中是不一样的。
利用这个特性,我们可以在每一个线程中对前面抓取到的所有内存冲突位置进行指令区间大小的分析,分解所有指令为微指令micro-instruction,再与指令窗口大小作比较进行判断,位于同一个指令窗口内的指令即为潜在的存在乱序的位置。再将指令对应到源码层级,即可给出源码层级对于内存屏障的修改建议,方便开发者进行检查和修改。

检查不同线程间的乱序区间来进行精准定位
上一步的结果实际上只是帮助我们找到了程序中所有可能出现“乱序情况”的内存访问指令区间,而不能直接帮助我们定位乱序情况导致的弱内存序错误。弱内存序问题实际上需要多个线程包含相同的乱序区间才会真正产生,因为只有这种情况才会出现逻辑上的依赖关系。(当然直接在所有此类乱序区间添加屏障也不失为一种简单粗暴的解决办法,并且在Tsan无法输出足够多的信息时是更好的办法)
同样举典型的弱内存序问题例子来看,我们新增一个全局变量c,让thread3进行变量b和变量c的读操作,thread3进行变量c的写操作。我们可以从定制后的Tsan的结果中得到变量b和变量c均存在内存访问冲突的现象(因为都被不同的thread在不同的时间先后读取或写入),假设thread3的读b和读c的指令都在同一个指令窗口内,那么可以说明这两条指令之间会存在乱序现象,然而这种乱序情况对程序逻辑并没有任何影响,因为在thread4中并不存在对变量b的读写操作,因此他们之间实际上没有逻辑依赖关系。
int a = 0; int b = 0; int c = 0; ------------------------------------ /* thread1 CPU1 */ a = 1; // Need Barrier b = 1; ------------------------------------ /* thread3 CPU3 */ while(b != 1) // read b instruction ; //...... assert(c == 0); // read c instruction ------------------------------------ /* thread4 CPU4 */ c = 1;
因此单纯的乱序情况实际上是被我们所允许的,可以说Arm架构下更多的乱序情况本身就相对x86严格的保序情况有更大的性能提升,这也是Arm用作高性能计算的优势之一。
因此进一步的,我们需要对不同线程之间所有对应相同内存访问区域的乱序区间进行匹配,如果存在诸如thread1 和thread2的情况那样有相同的乱序区间(thread1中write a 和write b区间,thread2中read b和 read a区间),即可判定为严重的弱内存序问题风险位置,输出报告并由开发者进行进一步的分析判断。
Case演示
我们以内部某数据库团队遇到的无锁队列问题为例,使用我们的工具对源码进行重编译和检测。
源代码关键部分如下:

具体工具使用步骤:
- 在替换定制后的libtsan.so并在编译时加上-fsanitize=thread选项重新编译后,程序运行时输出中会有如下片段,将所有输出记录为output.log
================== WARNING: ThreadSanitizer: data race (pid=2491502) Write of size 4 at 0xffffa48ff004 by thread T2: #0 __rte_ring_mp_enqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/rte_ring.c:106 (rte_case+0x4011dc) #1 rte_ring_enqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/rte_ring.c:170 (rte_case+0x4011dc) #2 doEnqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:27 (rte_case+0x400e68) Previous write of size 4 at 0xffffa48ff004 by thread T1: #0 __rte_ring_mp_enqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/rte_ring.c:106 (rte_case+0x4011dc) #1 rte_ring_enqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/rte_ring.c:170 (rte_case+0x4011dc) #2 doEnqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:27 (rte_case+0x400e68) Location is heap block of size 8388736 at 0xffffa48ff000 allocated by main thread: #0 malloc /root/zhuzhangqi/obj/../gcc/libsanitizer/tsan/tsan_interceptors_posix.cpp:692 (libtsan.so.2+0x448e8) #1 rte_ring_create /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/rte_ring.c:34 (rte_case+0x400eec) #2 main /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:35 (rte_case+0x400bec) Thread T2 (tid=2491505, running) created by main thread at: #0 pthread_create /root/zhuzhangqi/obj/../gcc/libsanitizer/tsan/tsan_interceptors_posix.cpp:1048 (libtsan.so.2+0x45818) #1 main /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:39 (rte_case+0x400c0c) Thread T1 (tid=2491504, running) created by main thread at: #0 pthread_create /root/zhuzhangqi/obj/../gcc/libsanitizer/tsan/tsan_interceptors_posix.cpp:1048 (libtsan.so.2+0x45818) #1 main /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:39 (rte_case+0x400c0c) SUMMARY: ThreadSanitizer: data race /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/rte_ring.c:106 in __rte_ring_mp_enqueue ================== ================== WARNING: ThreadSanitizer: data race (pid=2491502) Atomic write of size 4 at 0x0000004200c8 by thread T3: #0 doEnqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:30 (rte_case+0x400e94) Previous atomic write of size 4 at 0x0000004200c8 by thread T1: #0 doEnqueue /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:30 (rte_case+0x400e94) Location is global 'g_count' of size 4 at 0x0000004200c8 (rte_case+0x4200c8) Thread T3 (tid=2491506, running) created by main thread at: #0 pthread_create /root/zhuzhangqi/obj/../gcc/libsanitizer/tsan/tsan_interceptors_posix.cpp:1048 (libtsan.so.2+0x45818) #1 main /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:39 (rte_case+0x400c0c) Thread T1 (tid=2491504, running) created by main thread at: #0 pthread_create /root/zhuzhangqi/obj/../gcc/libsanitizer/tsan/tsan_interceptors_posix.cpp:1048 (libtsan.so.2+0x45818) #1 main /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:39 (rte_case+0x400c0c) SUMMARY: ThreadSanitizer: data race /root/zhuzhangqi/memory_barrier/cases/rte_ring_case/main.c:30 in doEnqueue ==================
- 将二进制文件进行反汇编输出到obj.log中
- 将output.log和obj.log作为输入提供给我们的工具,最终我们的工具会提供类似如下形式的输出:

- 报告提供了源代码中存在风险的具体源文件和对应的行数,并提供了建议插入的源码,提供了相应的汇编形式的乱序区域供开发者进行进一步判断。这里建议27行和30行源码之间插入dmb内存屏障,符合问题的人工定位结果
使用说明
环境配置和要求
gcc版本:GCC 10以上 (低版本GCC有时会存在Tsan输出调用栈信息不全的情况)
架构环境:aarch64
运行指南
此工具还在不断开发完善中,当前工具可以完成基本的弱内存序问题检测功能,欢迎有程序迁移需求的团队发送邮件到zhuzhangqi.zzq@alibaba-inc.com
我们会提供当前最新版本的使用方式和环境配置等技术支持,欢迎在使用过程中提出的一切反馈与建议!