
2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
1.反馈优化概述
编译器优化分成静态优化与动态优化,静态优化指我们在使用编译器gcc/llvm时,增加的优化等级,如O1,O2,O3,Ofast,此时,编译器会依据编译优化等级增加一些优化算法,如函数inline、循环展开以及分支静态预测等等。一般情况下,优化等级越高,编译器做的优化越多,性能会更会好。在阿里生产环境中,单纯依赖于静态优化,并不能达到程序运行流畅目的,通过分析CPU硬件取指令、执行指令,往往会出现一些分支预测失败导致iCacheMiss率高的场景,限制了程序的性能进一步提升。基于此,业务引入了动态反馈优化工具,依据生产环境的实际运行数据,反哺指导编译器对程序代码进一步调整编译优化策略,提高分支预测准确率和指令Cache命中率,达到深度调优的目的。
业界反馈优化的方法,首先是Feedback-Driven Optimization,也称为PGO。主要原理是源代码里插桩指令,然后模拟生产环境内运行程序,以得到函数调用信息及跳转信息。进而指导编译器进行反馈优化。
其次,基于大部分处理器均已支持PMU基础上,通过LBR/BLBR/SPE等硬件设备按一定的频率采样程序运行数据,生成Profile数据,将数据进行转换应用于下一次二进制编译,以提高分支预测准确率和Cache命中率。
图1 基于Profile采样数据反馈优化图
如图1所示,Profile数据可应用于编译器的不同阶段,包含编译阶段(AutoFDO)、链接阶段(LIPO/HFSort)及POST-LINK阶段(Ispike/Bolt)。
1.1. PGO优化
目前,最常见的反馈优化是PGO(Profile Guided Optimization), 对程序的代码进行全部插桩,并根据运行时 profiling data 指导编译器优化的技术。由于PGO获取的Profile数据比较全面,所以通过PGO优化的性能可以提升10-15%,甚至超过30%。
PGO优化需要以下三步骤:
- 编译时,增加额外的编译选项(-fprofile-instr-generate),编译器会在生成二进制程序内插桩收集函数信息及跳转信息的指令,使发布程序变大;
- 在生产环境内或模拟生产环境运行,插桩后二进制会生成profile文件;
- 基于profile文件,重新编译二进制程序
此三步骤中,第一步编译的程序,由于额外生成采集指令,导致生成的程序,在实际生产环境中,性能较低,无法满足快速迭代、快速上线的目的。而此三步骤,在公司分布式部署发布的工程,会出现维护成本巨大,故PGO优化并不能适应主流的分布式场景。
1.2.AutoFDO
基于目前大多数处理器支持PMU(x86-64:LBR,aarch64:SPE)基础上,Google提出一个AutoFDO反馈优化工具,通过Perf工具采样生产环境上的硬件性能监视器事件,解析出编译器所需跳转数据,指导下一版本的编译与优化。而且基于Perf工具的采样,基本上不会损失额外的处理器性能,而且至少得到85%以上指令运行情况,甚至接近指令实际运行情况。
AutoFDO反馈优化优势:
- 直接采集生产环境的实际运行信息,相比PGO,无须模拟运行一次;
- 采集数据经过转换后,直接应用于下一次Release版本编译发布,无需额外的维护成本;
- 非常适用于分布式部署环境。
1.3. BOLT
目前业界上普遍认为,Profile数据应用于阶段越早,越能发挥Profile数据潜力,获得更大的收益,正基于此,Profile数据应用研究基本上在编译和链接阶段,对POST-LINK研究相对较少。
其实,Profile数据采集是机器码级别的采样数据,应用于编译阶段和链接阶段时,Profile数据与编译时的代码映射关系并不精准,从面导致了Profile数据并未发挥真正的作用。
基于上述问题,Facebook推出基于LLVM开源框架的二进制静态优化工具Bolt。Facebook基于Bolt技术,应用于其数据中心负载处理,即使数据中心已进行了PGO(AutoFDO)和LTO优化后,BOLT仍然能够提升其性能,最高达7%。未应用PGO与LTO优化二进制,Bolt可提升性能达到52.1%。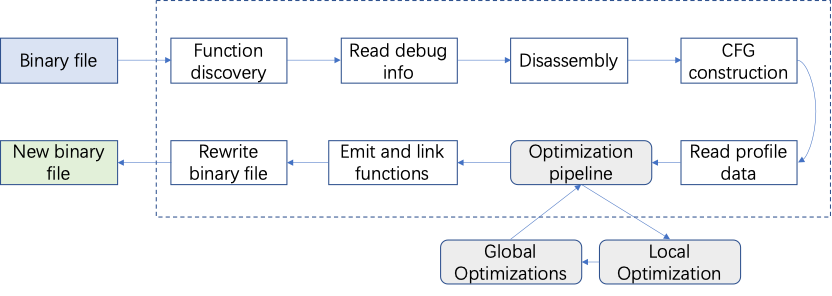
图2 BOLT内部流程图
BOLT框架大部分的优化收益来源于BasicBlock Reorder(Pass8)和Function reorder(Pass12)。Pass8基于function内部的BasicBlock的跳转信息,对BasicBlock进行重新排序,并且能够将冷的BasicBlock划分到新的section中。Pass12基于function之间的跳转信息,对function进行重新排序。Pass8和Pass12能够提高iCache和iTLB的利用率,从而提高性能。
2.应用反馈优化实践
结合倚天的硬件特性,通过SPE的采样分支跳转指令信息,研发自动化转换工具链,应用于公司核心业务场景,目前可一键式发布版本、自动化采集数据、自动化更新采样数据,业务无感知接入反馈优化系统。
目前在集团内核心业务,如即时通信系统、数据存储系统及数据库、地图导航等核心业务上,取得3-15%的性能提升,为集团节省上百万的成本。


