2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
1 背景
现代应用,如高性能计算(HPC)、大数据、数据库及数据处理等,对内存的时延大小很敏感。传统的解决方案是通过硬件模块检测规则的内存访问模式(循环步长)进行数据预取,也即是硬件预取方法。如此,处理器可将需要的数据提前加载到快速缓存内存中。然而,这些技术对非规则的内存访问模式,如链表形式的数据结构、通过index间接内存访问数组数据并不适用。
软件预取技术是编程者结合数据结构和算法知识,将访问内存的指令提前插入到程序,以此获得内存访取的最佳性能。然而,为了获取性能收益,预取数据与load加载数据,比依据指令时延调用减小cachemiss的收益更大。更为重要的是,过早预取数据,会导致数据cache超出,还未到用时,数据已经被弹出,进而数据再次load加载。若预取数据较晚,除了load自身数据的时延,还会增加冗余预取数据的时延。所以预取的时机不对常常导致软预取性能提升不明显,甚至性能下降。
结合业界提供了[论文]一种针对间接内存访问模式的自动化插入预取指令的优化算法,不仅可以处理更复杂的间接内存访问模式,而且可以规避提前加载导致的运行错误。核心是采用深度优化查找算法,找到load指令引用的循环归纳变量的路径指令集,进而对路径指令集进行数据提前加载,达到访存数据提前加载的目的。并在科学计算、HPC、大数据、数据库等商业应用,此方法在Intel Haswell架构上平均1.3X提升, Arm Cortex-A57架构有1.1X提升。发现软件预取的性能收益,和look-ahead预测距离、内存宽度、动态指令数及TLB大小强相关。
直观上理解,数据预取的方法,可以通过以下方法实现:
for (int i = 0; i < ARRAYLEN; i++) {
arrayC[i] = arrayA[i] * arrayB[i];
}
增加Prefetch指令的代码,如下所示:
Prefetch(&arrayA[0]);
Prefetch(&arrayB[0]);
for (int i = 0; i < ARRAYLEN - ARRAYLEN % 4; i+=4) {
Prefetch(&arrayA[i + 4]);
Prefetch(&arrayB[i + 4]);
arrayC[i] = arrayA[i] * arrayB[i];
arrayC[i + 1] = arrayA[i + 1] * arrayB[i + 1];
arrayC[i + 2] = arrayA[i + 2] * arrayB[i + 2];
arrayC[i + 3] = arrayA[i + 3] * arrayB[i + 3];
}
软件预取的方法实现原理基本上述方法类似。
假如数组之间存在间接调用的场景,如
1 for (i=0; i<base_array_size; i++) {
2 target_array[func(base_array[i])]++;
3 }
这里,顺序访问的内存数组base_array, 且定义func(x)=x,也即是base_array的结果作为target_array的访问index,故涉及到两种内存访问模式,base_array[i]和target_array[index].这两种械均适用于软预取。但访问target_array地址依赖于base_array结果。硬件预取却不无法精确识别并预取数据。通过软预取技术,可插入预取指令如下:
1 for (int i=0; i<NUM_KEYS; i++) {
2 // The intuitive case, but also
3 // required for optimal performance.
4 SWPF(key_buff1[key_buff2[i + offset]]);
5 // Required for optimal performance.
6 SWPF(key_buff2[i + offset*2]);
7 key_buff1[key_buff2[i]]++;
8 }
更重要的是,以合适的预测距离(当前迭代的偏移)插入正确的预取代码,对最终用户来说,是一个挑战。通过上述代码,在第4行插入prefetch指令,性能提升1.08X。然而,在key_buff2和间接数据kye_buffer1均插入prefetch指令,也即是在第6行也插入prefetch,性能提升1.30X。所以,选择合适的预测距离至关重要,可以避免过早或过晚预取数据问题。
2 软件预取
基于LLVM IR,开发软预取优化PASS,思路是通过查找load指令,判别是否可以在数组内预测预取,然后生成软件预取指令。首先生成分析信息,然后代码生成。算法1: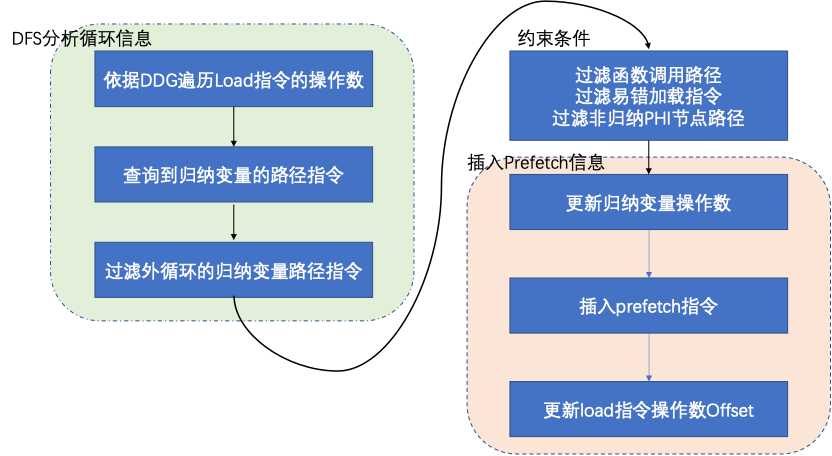
软预取流程图
3 Benchmark验证
目前,Prefetch优化算法作为LLVM的新增Pass,注册到LLVM-内部的PASS流程中,通过编译选项控制此优化的开关,具有通用性及普适性。
Noahbenchmark是基于服务器提取的权威性验证Benchmark,通过此benchmark可获取比较有说服力的数据。首先验证了noahbenchmark内prefetch内11个场景。通过前后优化对比,每个benchmark场景均有提升,最高达10%+。
基于Prefetch优化,验证SPEC2017性能,总体软预取带来5个benchmark提升,最大提升2.49%,3个benchmark持平,2个benchmark略有下降。

