xin在这_个人页

文章
235
问答
37453
视频
0
个人介绍
暂无个人介绍
擅长的技术

暂无更多信息
2024年05月
-
05.18 12:09:17
 发表了文章
2024-05-18 12:09:17
发表了文章
2024-05-18 12:09:17
实时计算 Flink版操作报错合集之无法将消费到的偏移量提交到Kafka如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 12:05:06发表了文章
2024-05-18 12:05:06
实时计算 Flink版操作报错合集之错误代码是130如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 11:58:18发表了文章
2024-05-18 11:58:18
实时计算 Flink版操作报错合集之错误信息"ORA-65040: operation not allowed from within a pluggable database"如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 11:51:04发表了文章
2024-05-18 11:51:04
实时计算 Flink版操作报错合集之报错:WARN (org.apache.kafka.clients.consumer.ConsumerConfig:logUnused)这个错误如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 11:48:22发表了文章
2024-05-18 11:48:22
实时计算 Flink版操作报错合集之部署war包的时候,错误提示 "No ExecutorFactory found to execute the application." 如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 11:37:06发表了文章
2024-05-18 11:37:06
实时计算 Flink版操作报错合集之hologres里报错:找不到字段如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 11:33:39发表了文章
2024-05-18 11:33:39
实时计算 Flink版操作报错合集之异常信息显示在Flink中找不到指定的ReplicationSlot如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 11:14:30发表了文章
2024-05-18 11:14:30
实时计算 Flink版操作报错合集之程序初始化mysql没有完成就报错如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 11:11:12发表了文章
2024-05-18 11:11:12
实时计算 Flink版操作报错合集之sqlserver mysql都用的胖包,sqlserver的成功了,mysql报这个错如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 10:58:18发表了文章
2024-05-18 10:58:18
实时计算 Flink版操作报错合集之连接器换成2.4.2之后,mysql作业一直报错如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 10:54:14发表了文章
2024-05-18 10:54:14
实时计算 Flink版操作报错合集之SQLserver表没有主键,同步的时候报错如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 10:34:09发表了文章
2024-05-18 10:34:09
实时计算 Flink版操作报错合集之在使用 Python UDF 时遇到 requests 包的导入问题,提示 OpenSSL 版本不兼容如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。 -
05.18 10:24:21发表了文章
2024-05-18 10:24:21
实时计算 Flink版产品使用合集之flink sql ROW_NUMBER()回退更新的机制,有相关文档介绍吗
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.18 10:21:58发表了文章
2024-05-18 10:21:58
实时计算 Flink版产品使用合集之将CURRENT_TIMESTAMP转换为长整型的数据(即毫秒数)如何解决
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.18 10:19:02发表了文章
2024-05-18 10:19:02
实时计算 Flink版产品使用合集之Flink on YARN 下,任务代码中通过 JobListener 监听任务状态,onJobSubmitted 和 onJobExecuted 同时触发如何解决
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.18 10:15:50发表了文章
2024-05-18 10:15:50
实时计算 Flink版产品使用合集之在抓取 MySQL binlog 数据时,datetime 字段会被自动转换为时间戳形式如何解决
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.18 10:12:54发表了文章
2024-05-18 10:12:54
实时计算 Flink版产品使用合集之可以支持批量写入HBase吗
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.18 10:09:50发表了文章
2024-05-18 10:09:50
实时计算 Flink版产品使用合集之在处理金额字段时,怎么才可以避免失真
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 23:10:59发表了文章
2024-05-17 23:10:59
实时计算 Flink版产品使用合集之在Flink Stream API中,可以在任务启动时初始化一些静态的参数并将其存储在内存中吗
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 23:03:41发表了文章
2024-05-17 23:03:41
实时计算 Flink版产品使用合集之支持在同步全量数据时使用checkpoint吗
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 22:31:38发表了文章
2024-05-17 22:31:38
实时计算 Flink版产品使用合集之配置的Managed Memory不生效如何解决
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 22:07:20发表了文章
2024-05-17 22:07:20
实时计算 Flink版产品使用合集之可以通过配置Oracle数据库的schema注册表来监测表结构的变化吗
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 22:00:53发表了文章
2024-05-17 22:00:53
实时计算 Flink版产品使用合集之可以通过JDBC连接器来连接Greenplum数据库吗
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 21:57:37发表了文章
2024-05-17 21:57:37
实时计算 Flink版产品使用合集之ClickHouse-JDBC 写入数据时,发现写入的目标表名称与 PreparedStatement 中 SQL 的表名不一致如何解决
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 21:54:20发表了文章
2024-05-17 21:54:20
实时计算 Flink版产品使用合集之在进行数据同步时,遇到了时区问题,怎么设置时区
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 21:46:26发表了文章
2024-05-17 21:46:26
实时计算 Flink版产品使用合集之每次服务启动时都会重新加载整个表的数据,是什么原因
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 21:42:51发表了文章
2024-05-17 21:42:51
实时计算 Flink版产品使用合集之 TaskManager 上的所有 Managed Memory 占用率达到了 100%,是什么导致的
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 21:38:57发表了文章
2024-05-17 21:38:57
实时计算 Flink版产品使用合集之多个任务合并一个宽表该怎么操作
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 21:35:15发表了文章
2024-05-17 21:35:15
实时计算 Flink版产品使用合集之遇到SQL Server锁表问题如何解决
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 21:31:27发表了文章
2024-05-17 21:31:27
实时计算 Flink版产品使用合集之全量快照是由多个线程同时进行的吗
实时计算Flink版作为一种强大的流处理和批处理统一的计算框架,广泛应用于各种需要实时数据处理和分析的场景。实时计算Flink版通常结合SQL接口、DataStream API、以及与上下游数据源和存储系统的丰富连接器,提供了一套全面的解决方案,以应对各种实时计算需求。其低延迟、高吞吐、容错性强的特点,使其成为众多企业和组织实时数据处理首选的技术平台。以下是实时计算Flink版的一些典型使用合集。 -
05.17 14:47:43
 回答了问题
2024-05-17 14:47:43
回答了问题
2024-05-17 14:47:43
钉钉应用不能发布时什么原因,有谁知道吗?
赞0 踩0 评论0 -
05.17 11:31:25回答了问题
2024-05-17 11:31:25
在什么场景下可以使用Saga方案?
赞0 踩0 评论0 -
05.17 11:31:21回答了问题
2024-05-17 11:31:21
RocketMQ是如何支持事务消息的?
赞1 踩0 评论0 -
05.17 11:30:07回答了问题
2024-05-17 11:30:07
在哪些场景下可以使用最大努力通知方案?
赞1 踩0 评论0 -
05.17 11:30:04回答了问题
2024-05-17 11:30:04
分布式事务处理策略中的最大努力通知方案是什么?
赞0 踩0 评论0 -
05.17 11:29:59回答了问题
2024-05-17 11:29:59
如何通过本地消息表实现分布式事务的最终一致性?
赞3 踩0 评论0 -
05.17 11:28:45回答了问题
2024-05-17 11:28:45
Saga方案适用于哪些场景?
赞1 踩0 评论0 -
05.17 11:28:42回答了问题
2024-05-17 11:28:42
TCC方案包括哪些阶段?
赞1 踩0 评论0 -
05.17 11:28:38回答了问题
2024-05-17 11:28:38
XA方案存在哪些问题?
赞1 踩0 评论0 -
05.17 11:26:22回答了问题
2024-05-17 11:26:22
分布式事务中的XA方案包括哪些阶段?
赞0 踩0 评论0 -
05.17 11:26:19回答了问题
2024-05-17 11:26:19
集群(Cluster)模式是什么,它如何解决主控节点的高可用性问题?
赞4 踩0 评论0 -
05.17 11:26:16回答了问题
2024-05-17 11:26:16
什么是互备(Active-Active)模式?
赞2 踩0 评论0 -
05.17 11:21:14回答了问题
2024-05-17 11:21:14
MySQL数据库主从复制是如何实现的?
赞1 踩0 评论0 -
05.17 11:21:10回答了问题
2024-05-17 11:21:10
什么是主备(Master-Slave)模式?
赞0 踩0 评论0 -
05.17 11:21:07回答了问题
2024-05-17 11:21:07
什么是分区容错性?
赞1 踩0 评论0 -
05.17 11:18:35回答了问题
2024-05-17 11:18:35
如何处理Binlog同步缓存的缺点?
赞2 踩0 评论0 -
05.17 11:18:32回答了问题
2024-05-17 11:18:32
使用Binlog同步缓存存在哪些缺点?
赞0 踩0 评论0 -
05.17 11:18:28回答了问题
2024-05-17 11:18:28
使用Binlog同步缓存有哪些优点?
赞1 踩0 评论0 -
05.17 11:16:34回答了问题
2024-05-17 11:16:34
在Raft算法中,如果Leader出现异常会发生什么?
赞0 踩0 评论0 -
05.17 11:16:31回答了问题
2024-05-17 11:16:31
Raft算法是什么?
赞0 踩0 评论0
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之遇到报错:"An OperatorEvent from an OperatorCoordinator to a task was lost. Triggering task failover to ensure consistency." ,该怎么办
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之在连接Oracle 19c时报错如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之写入 Kafka 报错 "Failed to send data to Kafka: Failed to allocate memory within the configured max blocking time 60000 ms",该怎么解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之报错显示“Unsupported SQL query! sqlUpdate() only accepts SQL statements of type INSERT and DELETE"是什么意思
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之报错io.debezium.DebeziumException: The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot. 是什么原因
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之本地打成jar包,运行报错,idea运行不报错,是什么导致的
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之使用 Event Time Temporal Join 关联多个 HBase 后,Kafka 数据的某个字段变为 null 是什么原因导致的
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之使用 Event Time Temporal Join 关联多个 HBase 后,Kafka 数据的某个字段变为 null 是什么原因导致的
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之查询sqlserver ,全量阶段出现报错如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之执行Flink job,报错“Could not execute SQL statement. Reason:org.apache.flink.table.api.ValidationException: One or more required options are missing”,该怎么办
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之恢复 checkpoint 时报 "userVisibleTail should not be larger than offset" 错误如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之向Hudi写入数据时遇到错误如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之在尝试触发checkpoint时遇到了报错如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之变更数据流转换为Insert-Only记录时,报错"datastream api record contains: Delete"如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之在运行过程中遇到"Could not upload job files"的问题如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之报错ClassCastException异常如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之报错 NoResourceAvailableException 是什么导致的
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之在尝试触发checkpoint时遇到了报错如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之遇到报错:“Lost leadership”和“Chk failure如何解决
-
发表了文章
2024-05-19
实时计算 Flink版操作报错合集之变更数据流转换为Insert-Only记录时,报错"datastream api record contains: Delete"如何解决
滑动查看更多
-
回答了问题
2024-05-20
请问有人遇到过阿里云E-MapReduce这个问题嘛?
没有访问临时目录的权限或者临时目录满了,看看fs.oss.tmp.data.dirs或者说spark.hadoop.fs.oss.tmp.data.dirs配了什么?如果没改过,那就是/tmp/的问题,此回答整理自钉群“JindoData 用户交流群”
赞0 踩0 评论0 -
回答了问题
2024-05-20
k8s集群内搭建了nacos集群,集群外的的服务怎么注册到nacos?
开放nodeport端口 ,此回答整理自钉群“Nacos社区群(1群满,请加4群:12810027056)”
赞0 踩0 评论0 -
回答了问题
2024-05-20
智能媒体管理需要oss批处理把目标文件下子目录下所以图片都处理,请问怎么设置规则?
可以参考这个文档 https://help.aliyun.com/zh/oss/user-guide/batch-processing , 对于图片可以通过制定过滤规则里的文件后缀的方式来限定,这种方式暂时还不支持,我们收到这个需求反馈给产品评估哈 ,此回答整理自钉群“智能媒体管理官网客户群②”
赞0 踩0 评论0 -
回答了问题
2024-05-20
请问智能媒体管理 Golang 最新sdk文档哪里有?
可以参考下这个文档 https://help.aliyun.com/zh/imm/developer-reference/go-sdk?spm=a2c4g.11186623.0.i1 ,此回答整理自钉群“智能媒体管理官网客户群②”
赞0 踩0 评论0 -
回答了问题
2024-05-20
智能媒体管理如果一直running 会一直使用流量费么?
不会的,以实际的打包过程为准,我这边看打包的任务已经完成了 ,此回答整理自钉群“智能媒体管理官网客户群②”
赞0 踩0 评论0 -
回答了问题
2024-05-20
智能媒体管理 这个的意思是 我将所有需要打包的文件链接,添加到这个里面是吗?
是的,这个文件会有具体的格式,然后这样的话,总打包的文件数可以到8w个 ,此回答整理自钉群“智能媒体管理官网客户群②”
赞0 踩0 评论0 -
回答了问题
2024-05-20
麻烦查一下智能媒体管理是什么问题导致的哈?
我们这边看压缩任务应该是成功了,只是发送异步消息有些问题,是因为输入的文件太多了导致的,解决办法可以是通过SourceManifestURI指定文件清单的办法。
另一块就是,您提到的这个产生的压缩包无法解压的问题,这个我们还需要在看一下,因为现在看压缩任务是成功了的,不应该会出现压缩包无法打开的问题 ,此回答整理自钉群“智能媒体管理官网客户群②”
赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute在窗口函数直接使用返回的值不对怎么办?
用tunnel。https://help.aliyun.com/zh/maxcompute/user-guide/tunnel-command-and-tunnel-sdk/?spm=a2c4g.11186623.0.0.196d11c1fbI3Hn&shareId=031508800d86009472e60842d18beeb0 ,此回答整理自钉群“MaxCompute开发者社区2群”
赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute使用stddev计算总体标准差的时候好像列的值类型对返回结果有影响?
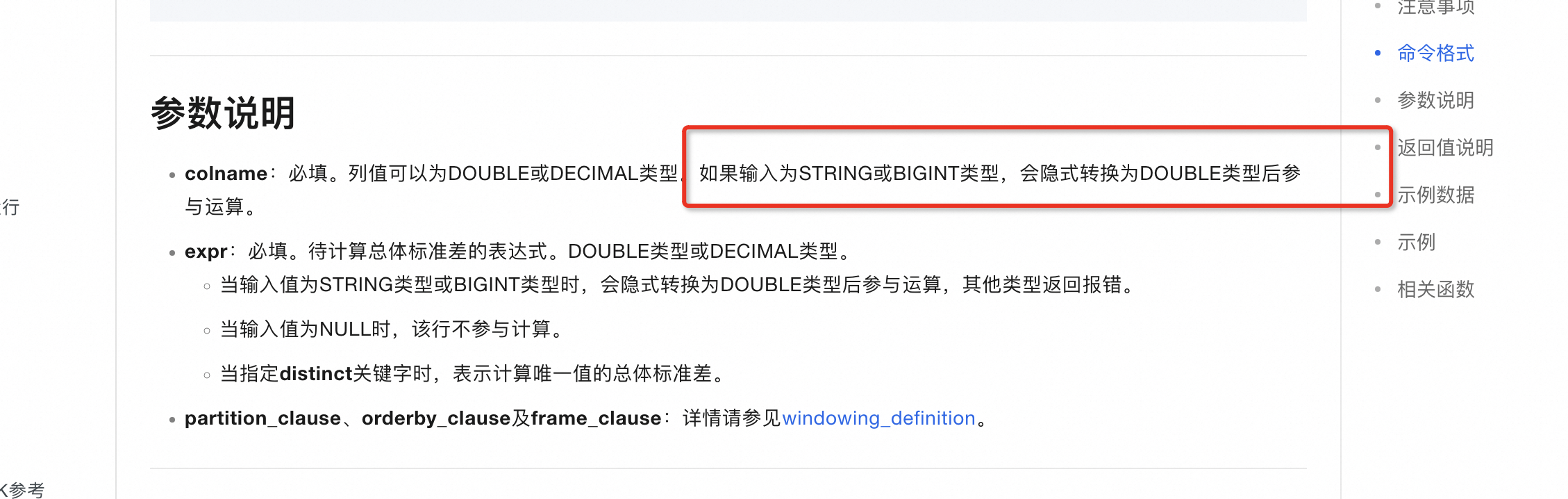
https://help.aliyun.com/zh/maxcompute/user-guide/stddev?spm=a2c4g.11186623.0.i3 ,此回答整理自钉群“MaxCompute开发者社区2群”赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute这个能帮我看看看怎么优化下?
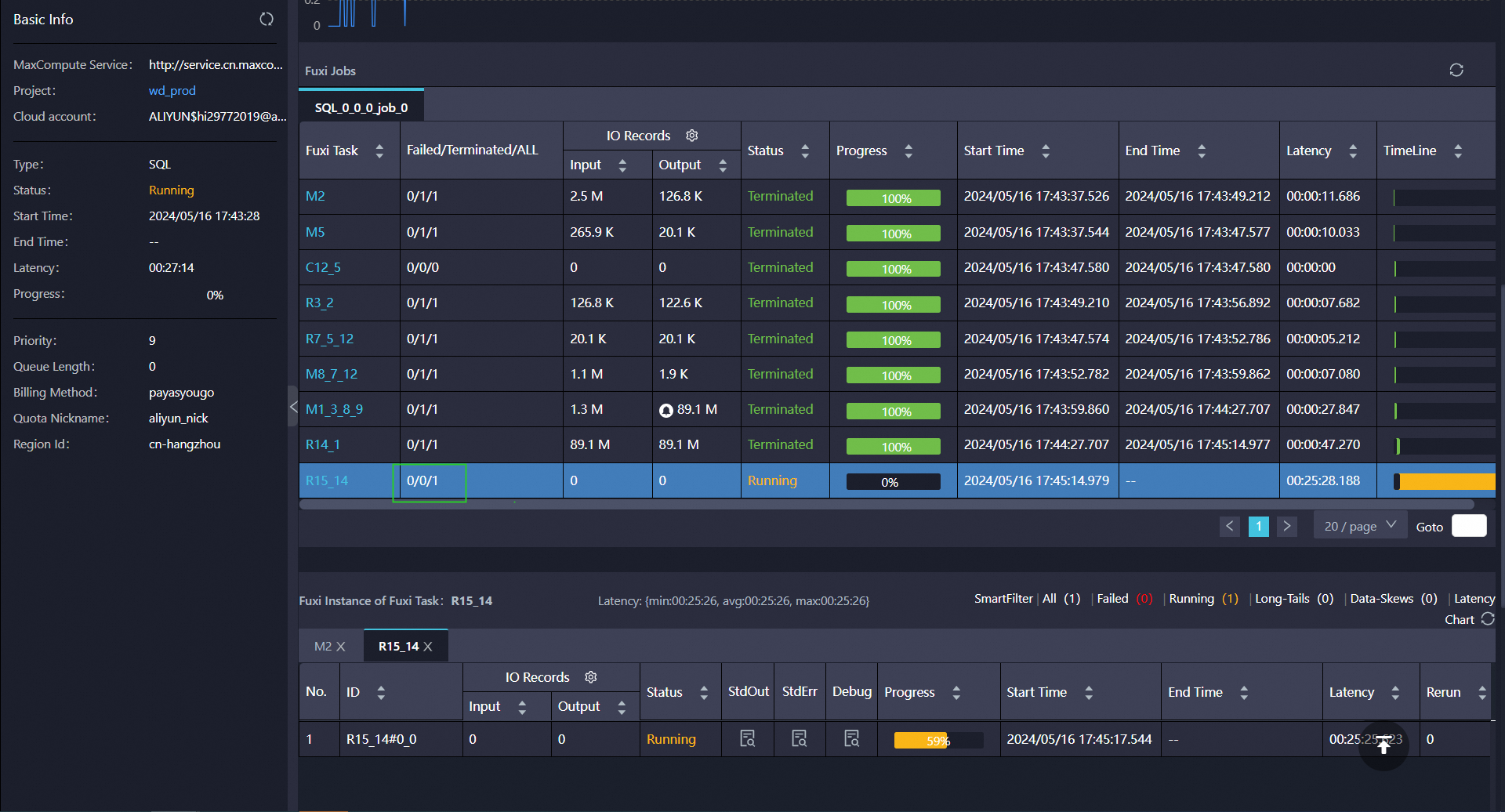
reduce阶段的mem和num设置大一些再看看https://help.aliyun.com/zh/maxcompute/user-guide/flag-parameters?spm=a2c4g.11186623.0.0.1ab532bfCVqk07 ,此回答整理自钉群“MaxCompute开发者社区2群”赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute一个几百万的表和一个几千的表,有什么方法优化吗?
看下mapjoin:https://help.aliyun.com/zh/maxcompute/user-guide/mapjoin-hints?spm=a2c4g.11186623.0.i57#section-cmz-kbp-e9u
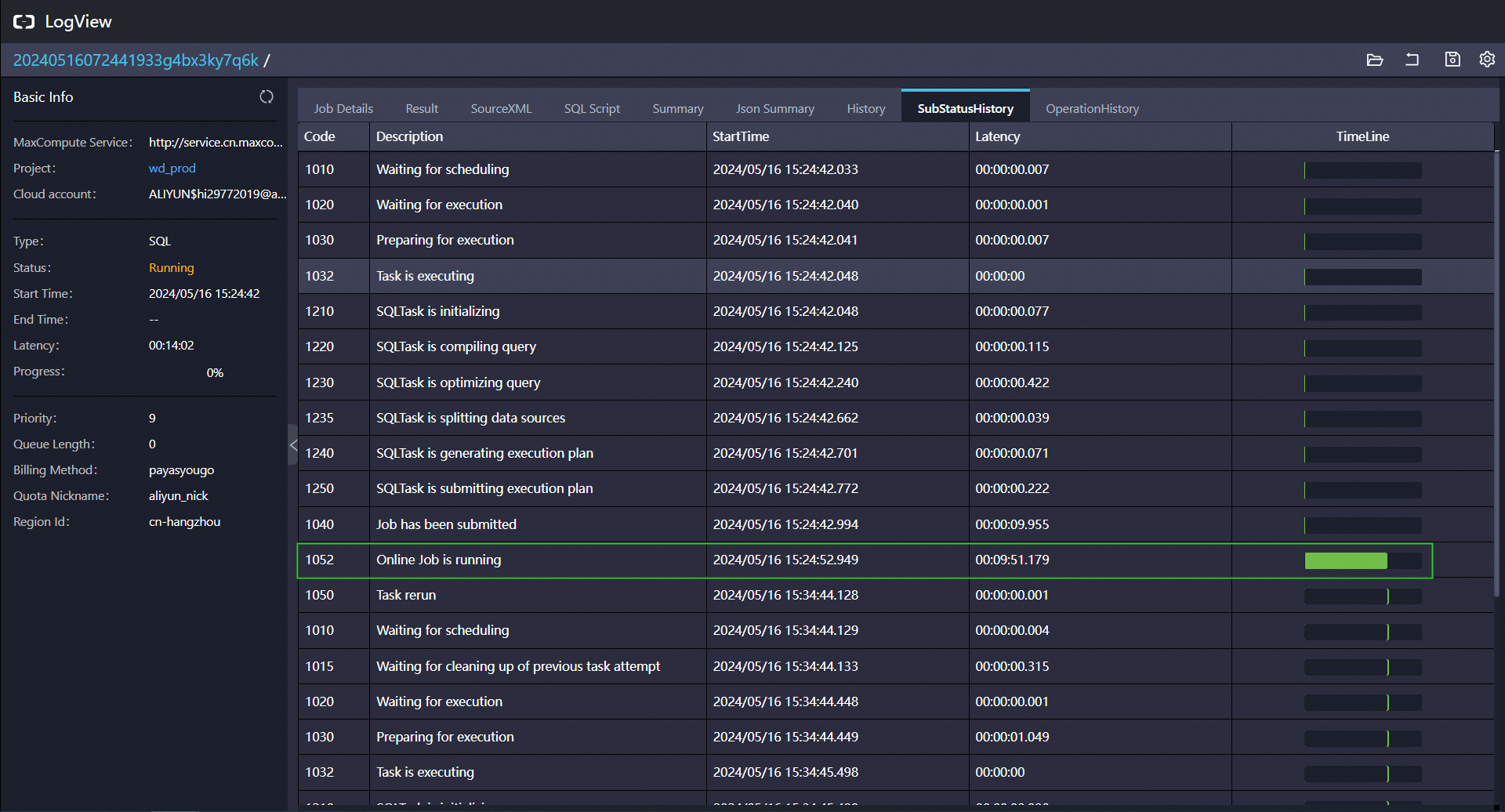
你把online关了再重跑一下Fuxi Job的两种作业类型:Online Job(service mode)和Offline Job。对于Offline的作业而言,当每次提交作业时在Fuxi上都会有一个环境准备的时间,针对大数据量并且不需要返回查询结果的作业比较合适,而对小数据量并且实时作业要求比较高的作业是不合适的。所以Fuxi提供为什么ServiceMode这种准实时的作业形式,也是online,首先会有一个服务去预先申请计算一些资源并加载出来,比如会预先分配一 万个nstance,当有作业提交时会根据作业规模分配一些Instance进行执行,这样就省去环境准备的时间,所以就会比较快。online不等资源且不保证成功。如果service mode失败,比如instance个数超过1000,或者运行超过10分钟,就会退回以Offline模式重跑。可以set odps.service.mode=off;这样就直接跑完了,不会再跑online ,此回答整理自钉群“MaxCompute开发者社区2群”赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute里面使用分区字段关联会和hive里面一样提升效率吗?
会,参考下:https://help.aliyun.com/zh/maxcompute/use-cases/check-whether-partition-pruning-is-effective?spm=a2c4g.11186623.0.i36#section-ebd-cyd-5db ,此回答整理自钉群“MaxCompute开发者社区2群”
赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute运行时出现这个错误是因为权限不够吗?
是,主账号给一下管理员权限。 ,此回答整理自钉群“MaxCompute开发者社区2群”
赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute DataWorks我是不是还要建跨项目的Package权限呀?
标准模式下,可以选择已有的project作为开发环境,同时可以选择已有的project作为生产环境。你可以创建一下试试
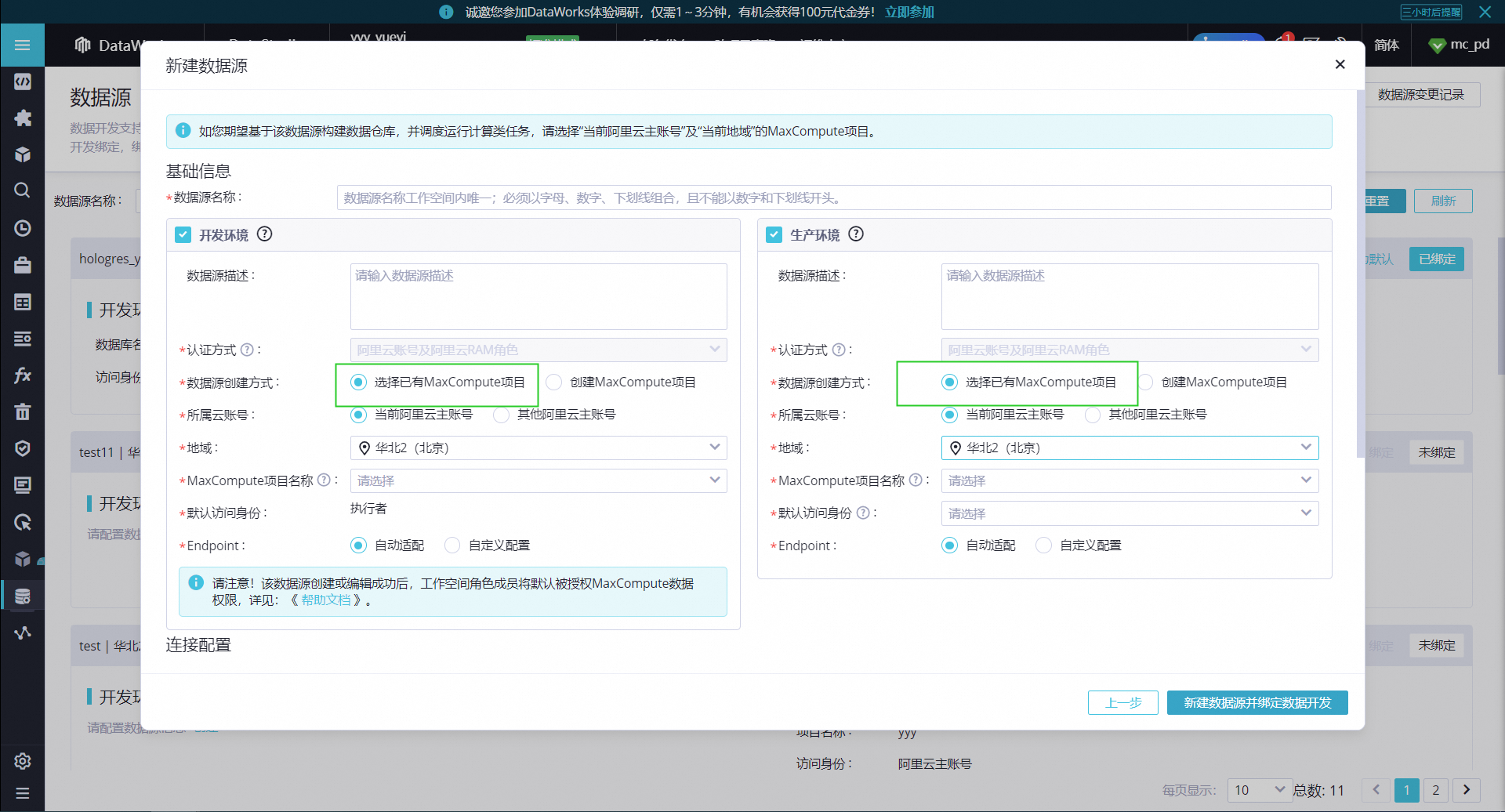
,此回答整理自钉群“MaxCompute开发者社区2群”赞0 踩0 评论0 -
回答了问题
2024-05-20
可以通过postgresql jdbc协议 连接大数据计算MaxCompute吗 ?
不支持 ,此回答整理自钉群“MaxCompute开发者社区2群”
赞0 踩0 评论0 -
回答了问题
2024-05-20
需求是powerbi直连大数据计算MaxCompute有什么解决方案?
抱歉,目前还不支持powerbi直连maxcompute ,此回答整理自钉群“MaxCompute开发者社区2群”
赞0 踩0 评论0 -
回答了问题
2024-05-20
可以使用odbc连接大数据计算MaxCompute吗?
文档暂时没有odbc连接MaxCompute的方式。 ,此回答整理自钉群“MaxCompute开发者社区2群”
赞1 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute这边可以点开了,刚刚点开一直报错怎么办?
用odpscmd试一下:https://help.aliyun.com/zh/maxcompute/user-guide/maxcompute-client?spm=a2c4g.11186623.0.i106
或者有DataWorks吗,在DataWorks用SQL节点加上参数重新试一下。
set odps.namespace.schema=true;这个参数没有加上,就会导致上边的报错。图里的租户级schema语法开关,和租户级别Information Schema,是两个概念。可以查看下这里的说明:https://help.aliyun.com/zh/maxcompute/product-overview/new-feature-trial-request?spm=a2c4g.11186623.0.i126#section-wa6-mdl-9w8
我看了你上边报错的log view,没有加上set odps.namespace.schema=true; 选中两条SQL一起点运行
在MaxCompute的SQL分析界面、DataWorks的SQL节点 执行带有参数的SQL时,需要全部选中一起点运行;如果在odpscmd客户端执行,当前窗口内,一般执行一次就能生效:https://help.aliyun.com/zh/maxcompute/user-guide/maxcompute-client?spm=a2c4g.11186623.0.i132 ,此回答整理自钉群“MaxCompute开发者社区2群”
赞0 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute这个模板哪些是需要我改的,应该只有这两个吧,这两个从哪里找啊?
主账号就照着步骤,复制粘贴授权就行。 ,此回答整理自钉群“MaxCompute开发者社区2群”
赞1 踩0 评论0 -
回答了问题
2024-05-20
大数据计算MaxCompute不能通过python任务删除吗?
那得参考下开源python的逻辑,连接上MySQL再操作。 ,此回答整理自钉群“MaxCompute开发者社区2群”
赞0 踩0 评论0
滑动查看更多
暂无更多信息