

бЋеТ








ЮвЙизЂЕФШЫ





ЗлЫП







ММЪѕФмСІ
-
-
 дЦЪ§ОнПтClouderШЯжЄЃКдЦЪ§ОнПтRDSПьЫйШыУХ
ЛёЕУгк2023-11-06 16:51:07
дЦЪ§ОнПтClouderШЯжЄЃКдЦЪ§ОнПтRDSПьЫйШыУХ
ЛёЕУгк2023-11-06 16:51:07 -
ЕЏадМЦЫуClouderШЯжЄЃКECSПьЫйШыУХ
ЛёЕУгк2023-10-07 17:26:48
-
дЦдЩњШнЦїClouderШЯжЄЃКЛљгкШнЦїДюНЈЦѓвЕМЖгІгУ
ЛёЕУгк2023-10-07 16:58:54
-
дЦДцДЂClouderШЯжЄЃКЛљгкДцДЂВњЦЗПьЫйДюНЈЭјХЬ
ЛёЕУгк2023-09-27 09:04:56
-
ЕЏадМЦЫуClouderШЯжЄЃКECSЛљДЁдЫЮЌЙмРэ
ЛёЕУгк2023-08-31 10:00:17
-
днЮоИіШЫНщЩм
-
ЗЂБэСЫЮФеТ 2024-04-12
ДѓЪ§ОнДІРэМмЙЙHadoop
ЁО4дТИќЮФЬєеНЕк10ЬьЁПHadoopЪЧПЊдДЕФЗжВМЪНМЦЫуПђМмЃЌКЫаФАќРЈMapReduceКЭHDFSЃЌгУгкКЃСПЪ§ОнЕФДцДЂКЭМЦЫуЁЃОпБИИпПЩППадЁЂИпРЉеЙадЁЂИпаЇТЪКЭЕЭГЩБОгХЪЦЃЌЕЋДцдкЕЭбгГйЗУЮЪЁЂаЁЮФМўДцДЂКЭЖргУЛЇаДШыЕШЮЪЬтЁЃдЫааФЃЪНгаЕЅЛњЁЂЮБЗжВМЪНКЭЗжВМЪНЁЃNameNodeЙмРэЮФМўЯЕЭГЃЌDataNodeДцДЂЪ§ОнВЂДІРэЧыЧѓЁЃHadoopЮЊДѓЪ§ОнДІРэЬсЙЉИпаЇПЩППЕФНтОіЗНАИЁЃ
-
ЗЂБэСЫЮФеТ 2024-04-10
`/var/log/wtmp` КЭ `/var/run/utmp`ШежОЯъНт
`/var/log/wtmp` КЭ `/var/run/utmp` ЪЧUnix/LinuxЯЕЭГжаМЧТМгУЛЇЕЧТМаХЯЂЕФЙиМќЮФМўЁЃ`wtmp` ЮФМўДцДЂЫљгаЕЧТМКЭзЂЯњЪТМўЃЌЙЉ `last` УќСюЯдЪОЕЧТМРњЪЗЃЌЖј `utmp` ЮФМўЪЕЪБИќаТЃЌМЧТМЕБЧАЕЧТМгУЛЇаХЯЂЃЌПЩгЩ `who` Лђ `w` УќСюНтЮіеЙЪОЁЃСНепНдЮЊrootгУЛЇЗУЮЪЃЌЯЕЭГжиЦєПЩФмЧхПеЃЌЧвГЃЪмАВШЋДыЪЉБЃЛЄЃЌгУгкЯЕЭГЙмРэКЭАВШЋЩѓМЦЁЃ
-
ЗЂБэСЫЮФеТ 2024-04-10
`/var/log/syslog` КЭ `/var/log/messages` ШежОЯъНт
`/var/log/syslog` КЭ `/var/log/messages` ЪЧLinuxЯЕЭГЕФШежОЮФМўЃЌЗжБ№дкDebianКЭRed HatЯЕЗЂааАцжаМЧТМЯЕЭГЪТМўКЭДэЮѓЁЃЫќУЧАќКЌЪБМфДСЁЂШежОМЖБ№ЁЂPIDМАЯћЯЂФкШнЃЌгЩ`rsyslog`ЕШЪиЛЄНјГЬЙмРэЁЃГЃгУУќСюШч`tail`КЭ`grep`гУгкВщПДКЭЫбЫїШежОЁЃШежОМЖБ№ДгЕЭЕНИпАќРЈ`debug`ЕН`emerg`ЃЌБэЪОВЛЭЌбЯжиГЬЖШЕФаХЯЂЁЃзЂвтБЃЛЄШежОЮФМўЕФАВШЋЃЌЗРжЙЮДЪкШЈЗУЮЪЃЌВЂЖЈЦкЪЙгУ`logrotate`НјааЮФМўТжзЊвдЙмРэДХХЬПеМфЁЃ
-
ЗЂБэСЫЮФеТ 2024-04-09
/var/log/secureШежОЯъНт
LinuxЯЕЭГЕФ `/var/log/secure` ЮФМўМЧТМАВШЋЯрЙиЯћЯЂЃЌАќРЈЩэЗнбщжЄКЭЪкШЈГЂЪдЁЃЫќКИЧгУЛЇЕЧТМЃЈГЩЙІЛђЪЇАмЃЉЁЂ`sudo` ЪЙгУЁЂеЫЛЇЫјЖЈНтЫјМАЦфЫћАВШЋЪТМўКЭPAMДэЮѓЁЃР§ШчЃЌSSHЕЧТМГЩЙІЛсЯдЪО"Accepted password"ЃЌЪЇАмдђЯдЪО"Failed password"ЁЃВщПДДЫЮФМўПЩЪЙгУ `tail -f /var/log/secure`ЃЌЕЋЭЈГЃжЛгаrootгУЛЇгаШЈЗУЮЪЁЃ
-
ЗЂБэСЫЮФеТ 2024-03-11
РЉеЙASCIIБрТыЃЈExtended ASCIIЛђ8-bit ASCIIЃЉ
РЉеЙASCIIБрТыЃЈExtended ASCIIЛђ8-bit ASCIIЃЉ
-
ЗЂБэСЫЮФеТ 2024-03-01
`grep`УќСюЫбЫїЕБЧАФПТММАЦфзгФПТМЯТЕФЫљгаЮФМў
`grep`УќСюЫбЫїЕБЧАФПТММАЦфзгФПТМЯТЕФЫљгаЮФМў
-
ЗЂБэСЫЮФеТ 2024-02-28
sedДІРэЖрааФЃЪНЃЈШчРЈКХЦЅХфЃЉ
sedДІРэЖрааФЃЪНЃЈШчРЈКХЦЅХфЃЉ
-
ЗЂБэСЫЮФеТ 2024-02-28
sedЬсШЁШежОжаЕФIPЕижЗ
sedЬсШЁШежОжаЕФIPЕижЗ
-
ЗЂБэСЫЮФеТ 2024-02-22
awkЭЈЙ§ system() КЏЪ§ЕїгУЦфЫћУќСюЛёШЁЪфГі
awkЭЈЙ§ system() КЏЪ§ЕїгУЦфЫћУќСюЛёШЁЪфГі
-
ЗЂБэСЫЮФеТ 2024-02-18
awkЕФЖрЬѕМўФЃЪНЃЈТпМANDЃЉ
awkЕФЖрЬѕМўФЃЪНЃЈТпМANDЃЉ
-
ЗЂБэСЫЮФеТ 2024-02-16
awkТпМЛђ (OR)
awkТпМЛђ (OR)
-
ЗЂБэСЫЮФеТ 2024-02-15
awkЕФзщКЯФЃЪНЖрЬѕМўФЃЪН
awkЕФзщКЯФЃЪНЖрЬѕМўФЃЪН
-
ЗЂБэСЫЮФеТ 2024-04-09
/var/log/auth.logШежОЯъНт
ЁО4дТИќЮФЬєеНЕк7ЬьЁП`/var/log/auth.log`ЪЧLinuxЃЈгШЦфЪЧDebianЯЕШчUbuntuЃЉМЧТМЩэЗнбщжЄКЭЪкШЈЪТМўЕФШежОЮФМўЃЌАќРЈЕЧТМГЂЪдЃЈГЩЙІЛђЪЇАмЃЉЁЂSSHЛюЖЏЁЂsudoЪЙгУКЭPAMФЃПщВйзїЁЃДЫЮФМўвВМЧТМЦфЫћШЯжЄЯрЙиЪТМўЃЌШчKerberosКЭNFSЁЃВщПДШежОЭЈГЃашrootШЈЯоЃЌПЩЪЙгУ`tail`ЁЂ`less`Лђ`grep`УќСюЁЃР§ШчЃЌ`sudo tail /var/log/auth.log`ЯдЪОзюКѓМИааЃЌ`sudo grep "failed password" /var/log/auth.log`ЫбЫїЪЇАмУмТыГЂЪдЁЃФкШнКЭИёЪНПЩФмвђЗЂааАцМАХфжУЖјвьЁЃ
-
ЗЂБэСЫЮФеТ 2024-04-09
/var/log/auth.logШежОЯъНт
`/var/log/auth.log`ЪЧLinuxЃЈгШЦфЪЧDebianЯЕШчUbuntuЃЉМЧТМЩэЗнбщжЄКЭЪкШЈЪТМўЕФШежОЮФМўЃЌАќРЈЕЧТМГЂЪдЃЈГЩЙІЛђЪЇАмЃЉЁЂSSHЛюЖЏЁЂsudoЪЙгУКЭPAMФЃПщЕФВйзїЁЃЕЧТМЪЇАмЁЂSSHСЌНгЁЂsudoУќСюМАЦфЫќШЯжЄЛюЖЏЖМЛсдкДЫМЧТМЁЃВщПДДЫШежОЭЈГЃашrootШЈЯоЃЌПЩЪЙгУ`tail`ЁЂ`less`Лђ`grep`УќСюЁЃЮФМўФкШнПЩФмвђЗЂааАцКЭХфжУЖјвьЁЃР§ШчЃЌ`sudo tail /var/log/auth.log`ЯдЪОзюКѓМИааЃЌ`sudo grep "failed password" /var/log/auth.log`ЫбЫїЪЇАмУмТыГЂЪдЁЃ
-
ЗЂБэСЫЮФеТ 2024-03-25
slbМрЬ§авщгыЖЫПк
SLBЪЧдЦЗўЮёЩЬЬсЙЉЕФИКдиОљКтЗўЮёЃЌгУгкЗжЗЂПЭЛЇЖЫЧыЧѓЕНЖрЬЈКѓЖЫЗўЮёЦїЃЌЬсЩ§ЗўЮёПЩгУадКЭЯьгІЫйЖШЁЃЙиМќИХФюАќРЈМрЬ§авщЃЈTCPЁЂUDPЁЂHTTPЁЂHTTPSЁЂTCPSSLЃЉКЭМрЬ§ЖЫПкЁЃМрЬ§авщОіЖЈСЫSLBДІРэЧыЧѓЕФЗНЪНЃЌЖјМрЬ§ЖЫПкдђЪЧSLBНгЪеЧыЧѓЕФШыПкЁЃХфжУЪБашИљОнгІгУбЁдёКЯЪЪавщКЭЖЫПкЃЌВЂПЩЩшжУИКдиОљКтЫуЗЈЃЈШчТжбЏЁЂзюЩйСЌНгЕШЃЉЁЃПЭЛЇЖЫгІЭЈЙ§SLBЭГвЛШыПкЗУЮЪКѓЖЫЗўЮёЃЌБмУтШЦЙ§SLBЕМжТЕФЮЪЬтЁЃ
-
ЗЂБэСЫЮФеТ 2024-01-24
linuxУќСюжЎsed
linuxУќСюжЎsed
-
ЗЂБэСЫЮФеТ 2024-01-18
shellУќСюжЎcat
shellУќСюжЎcat
-
ЗЂБэСЫЮФеТ 2024-01-18
shellУќСюжЎhead
shellУќСюжЎhead
-
ЗЂБэСЫЮФеТ 2024-01-15
linuxУќСюжЎrmdir
linuxУќСюжЎrmdir
-
ЗЂБэСЫЮФеТ 2024-02-23
дк `awk` жаЃЌfor бЛЗ
дк `awk` жаЃЌfor бЛЗ
-
ЗЂБэСЫЮФеТ 2024-02-16
awkТпМгы (AND)
awkТпМгы (AND)
-
ЗЂБэСЫЮФеТ 2024-01-09
shellжаВЂЗЂжДааЖрИіНјГЬ
shellжаВЂЗЂжДааЖрИіНјГЬ
-
ЗЂБэСЫЮФеТ 2024-01-08
дкShellНХБОЛђУќСюаажаЃЌБъзМДэЮѓЪфГі
дкShellНХБОЛђУќСюаажаЃЌБъзМДэЮѓЪфГі
-
ЗЂБэСЫЮФеТ 2024-01-09
shellНХБОжаДДНЈзгНјГЬ
shellНХБОжаДДНЈзгНјГЬ
-
ЗЂБэСЫЮФеТ 2024-01-05
дкShellНХБОжаЃЌМьВщвЛИіНјГЬЪЧЗёе§дкдЫаа
дкShellНХБОжаЃЌМьВщвЛИіНјГЬЪЧЗёе§дкдЫаа
-
ЗЂБэСЫЮФеТ 2024-01-08
дкShellжаЃЌФњПЩвдЭЌЪБжиЖЈЯђБъзМЪфГіЃЈSTDOUTЃЉКЭДэЮѓЪфГіЃЈSTDERRЃЉ
дкShellжаЃЌФњПЩвдЭЌЪБжиЖЈЯђБъзМЪфГіЃЈSTDOUTЃЉКЭДэЮѓЪфГіЃЈSTDERRЃЉ
-
ЗЂБэСЫЮФеТ 2024-01-04
дкshellжаВщПДНјГЬ
дкshellжаВщПДНјГЬ
-
ЗЂБэСЫЮФеТ 2024-01-04
дкShellНХБОжаЪЕЯжНјГЬМрПи
дкShellНХБОжаЪЕЯжНјГЬМрПи
-
ЗЂБэСЫЮФеТ 2023-12-29
shellжДааШЈЯо
shellжДааШЈЯо
-
ЗЂБэСЫЮФеТ 2023-12-26
shellЫбЫїЮФМўКЭФкШн
shellЫбЫїЮФМўКЭФкШн
-
ЗЂБэСЫЮФеТ 2024-01-05
дкShellжаздЖЏжиЦєНјГЬ
дкShellжаздЖЏжиЦєНјГЬ
-
ЗЂБэСЫЮФеТ 2023-12-25
shellНХБОЮФМўЕФШЈЯоКЭжДаа
shellНХБОЮФМўЕФШЈЯоКЭжДаа
-
ЗЂБэСЫЮФеТ 2023-12-06
VPCЕФxgwЩЯВщПДТЗгЩ
VPCЕФxgwЩЯВщПДТЗгЩ
-
ЗЂБэСЫЮФеТ 2023-12-06
зЈгадЦЬьЛљЩЯгаФФСНжжdecide
зЈгадЦЬьЛљЩЯгаФФСНжжdecide
-
ЗЂБэСЫЮФеТ 2023-11-29
registry.aliyuncs.com/google_containersетИіОЕЯёВжПтЖМгаЩЖОЕЯё
registry.aliyuncs.com/google_containersетИіОЕЯёВжПтЖМгаЩЖОЕЯё
-
ЗЂБэСЫЮФеТ 2023-11-29
hbaseВщбЏЫйЖШКмТ§
hbaseВщбЏЫйЖШКмТ§
-
ЗЂБэСЫЮФеТ 2023-11-29
ММЪѕТлЬГНщЩм
ММЪѕТлЬГНщЩм
-
ЗЂБэСЫЮФеТ 2023-11-28
FlinkШ§жжМЏШКФЃЪНЃЌStandaloneФЃЪНЃЌFlink On YARNЃЌFlink On K8SЃЌетШ§жжФЃЪНгаЩЖгХШБЕуЃЌЩњВњЛЗОГШчКЮбЁдёФиЃП
FlinkШ§жжМЏШКФЃЪНЃЌStandaloneФЃЪНЃЌFlink On YARNЃЌFlink On K8SЃЌетШ§жжФЃЪНгаЩЖгХШБЕуЃЌЩњВњЛЗОГШчКЮбЁдёФиЃП
-
ЗЂБэСЫЮФеТ 2023-11-22
ЪВУДЪЧдЦдЩњ,дЩњПЊЗЂКЭЛьКЯПЊЗЂгжЪЧЪВУД
ЪВУДЪЧдЦдЩњ,дЩњПЊЗЂКЭЛьКЯПЊЗЂгжЪЧЪВУД
-
ЗЂБэСЫЮФеТ 2023-11-22
Flink CDC-sqlдѕбљЕМЪ§ОнЪЙstarrocksжЇГжжїМќФЃаЭdeleteЕФХфжУТ№ЃПФПЧАжЛФмИќаТКЭВхШыЃЌЕЋЪЧЩОГ§ВЛаа
Flink CDC-sqlдѕбљЕМЪ§ОнЪЙstarrocksжЇГжжїМќФЃаЭdeleteЕФХфжУТ№ЃПФПЧАжЛФмИќаТКЭВхШыЃЌЕЋЪЧЩОГ§ВЛаа
-
ЗЂБэСЫЮФеТ 2023-11-20
ModelScopeжаЃЌздМКРЦ№ЕФбЕСЗЃЌpytorch_lora_weights.bin етИіЮФМўдѕУДзЊГЩsdЕФПЩжБНгЕМШыЕФloraЮФМўФиЃП
ModelScopeжаЃЌздМКРЦ№ЕФбЕСЗЃЌpytorch_lora_weights.bin етИіЮФМўдѕУДзЊГЩsdЕФПЩжБНгЕМШыЕФloraЮФМўФиЃП
-
ЗЂБэСЫЮФеТ 2023-11-15
дкFlink CDCжаЪЙгУOracle 19cЪБПЩФмЛсгіЕНORA-65040ДэЮѓ
дкFlink CDCжаЪЙгУOracle 19cЪБПЩФмЛсгіЕНORA-65040ДэЮѓ
-
ЗЂБэСЫЮФеТ 2023-11-14
DataWorksЕїгУЪ§ОндДЗўЮёЪЇАмЃКУЛгаАѓЖЈЪ§ОнЗўЮёзЪдДзщ ФЌШЯОЭЪЧЪЙгУЕФЙЋЙВзЪдДзщЪЧУДЃП
DataWorksЕїгУЪ§ОндДЗўЮёЪЇАмЃКУЛгаАѓЖЈЪ§ОнЗўЮёзЪдДзщ ФЌШЯОЭЪЧЪЙгУЕФЙЋЙВзЪдДзщЪЧУДЃП
-
ЗЂБэСЫЮФеТ 2023-11-13
IDEAздЖЈвхгвМќВЫЕЅ
IDEAздЖЈвхгвМќВЫЕЅ
-
ЗЂБэСЫЮФеТ 2023-11-10
дкЖЄЖЄаЁГЬађжаАВзПЮоЗЈДђПЊwebview
дкЖЄЖЄаЁГЬађжаАВзПЮоЗЈДђПЊwebview
-
ЗЂБэСЫЮФеТ 2023-11-09
KMSНщЩм
KMS
-
ЗЂБэСЫЮФеТ 2023-11-09
ecsжаЕФАВШЋзщЃЌЪкШЈЖдЯѓПЩвдгУгђУћТ№ЃП
ecsжаЕФАВШЋзщЃЌЪкШЈЖдЯѓПЩвдгУгђУћТ№ЃП
-
ЗЂБэСЫЮФеТ 2023-11-06
ШчКЮПДД§АЂРядЦЗЂВМЕФШЋЧђЪзИіШнЦїМЦЫуЗўЮё ACSЃП
ШчКЮПДД§АЂРядЦЗЂВМЕФШЋЧђЪзИіШнЦїМЦЫуЗўЮё ACSЃП
-
ЗЂБэСЫЮФеТ 2023-11-03
vscode АВзАTONGYILingmaВхМўКѓЮоЗЈЪЙгУ
vscode АВзАTONGYILingmaВхМўКѓЮоЗЈЪЙгУ
-
ЗЂБэСЫЮФеТ 2023-11-03
Ъ§ОнМЏМгдиЪББЈДэ'dict' object has no attribute 'requestsЁЎ
Ъ§ОнМЏМгдиЪББЈДэ'dict' object has no attribute 'requestsЁЎ
-
 ЗЂБэСЫЮФеТ
2024-05-29
ЗЂБэСЫЮФеТ
2024-05-29
hadoopНкЕуHDFSЪ§ОнПщЛљБОИХФю
-
ЗЂБэСЫЮФеТ
2024-05-29
HadoopНкЕуHDFSдЊЪ§ОнгыЪ§ОнПщЕФЙиЯЕ
-
ЗЂБэСЫЮФеТ
2024-05-29
HadoopНкЕуHDFSЪ§ОнПщЕФзїгУ
-
ЗЂБэСЫЮФеТ
2024-05-28
hadoopНкЕуHDFSЪ§ОнПщЃЈBlockЃЉ
-
ЗЂБэСЫЮФеТ
2024-05-28
hadoopНкЕуHDFSЪ§ОнЗжЦЌЙ§ГЬ
-
ЗЂБэСЫЮФеТ
2024-05-28
hadoopНкЕуHDFSЪ§ОнЗжЦЌЃЈData SplittingЃЉ
-
ЗЂБэСЫЮФеТ
2024-05-27
hadoopНкЕуHDFSЃЈHadoop Distributed File SystemЃЉЪ§ОнЗжЦЌ
-
ЗЂБэСЫЮФеТ
2024-05-27
HadoopНкЕуЪ§ОнНкЕуЃЈDataNodeЃЉ
-
ЗЂБэСЫЮФеТ
2024-05-27
HadoopНкЕуУћГЦНкЕуЃЈNameNodeЃЉ
-
ЗЂБэСЫЮФеТ
2024-05-24
HadoopНкЕуЪ§ОнЗжЦЌ
-
ЗЂБэСЫЮФеТ
2024-05-24
HadoopНкЕуЪ§ОнИББО
-
ЗЂБэСЫЮФеТ
2024-05-24
HadoopНкЕубЁдёВпТд
-
ЗЂБэСЫЮФеТ
2024-05-23
HadoopНкЕуЕФШЮЮёжиЪдЛњжЦ
-
ЗЂБэСЫЮФеТ
2024-05-23
HadoopНкЕуЕФаФЬјМьВтгыздЖЏЙЪеЯЛжИД
-
ЗЂБэСЫЮФеТ
2024-05-23
HadoopжаЕФЪ§ОнШпгрБИЗн
-
ЗЂБэСЫЮФеТ
2024-05-22
HadoopНкЕуЪ§ОнОжВПад
-
ЗЂБэСЫЮФеТ
2024-05-22
HadoopНкЕуЪ§ОнПЩППад
-
ЗЂБэСЫЮФеТ
2024-05-22
hadoopНкЕуШнДэад
-
ЗЂБэСЫЮФеТ
2024-05-21
HadoopНкЕуШпгр
-
ЗЂБэСЫЮФеТ
2024-05-21
HadoopЕФЭјТчШнДэ

-
 ЛиД№СЫЮЪЬт
2024-05-29
ЛиД№СЫЮЪЬт
2024-05-29
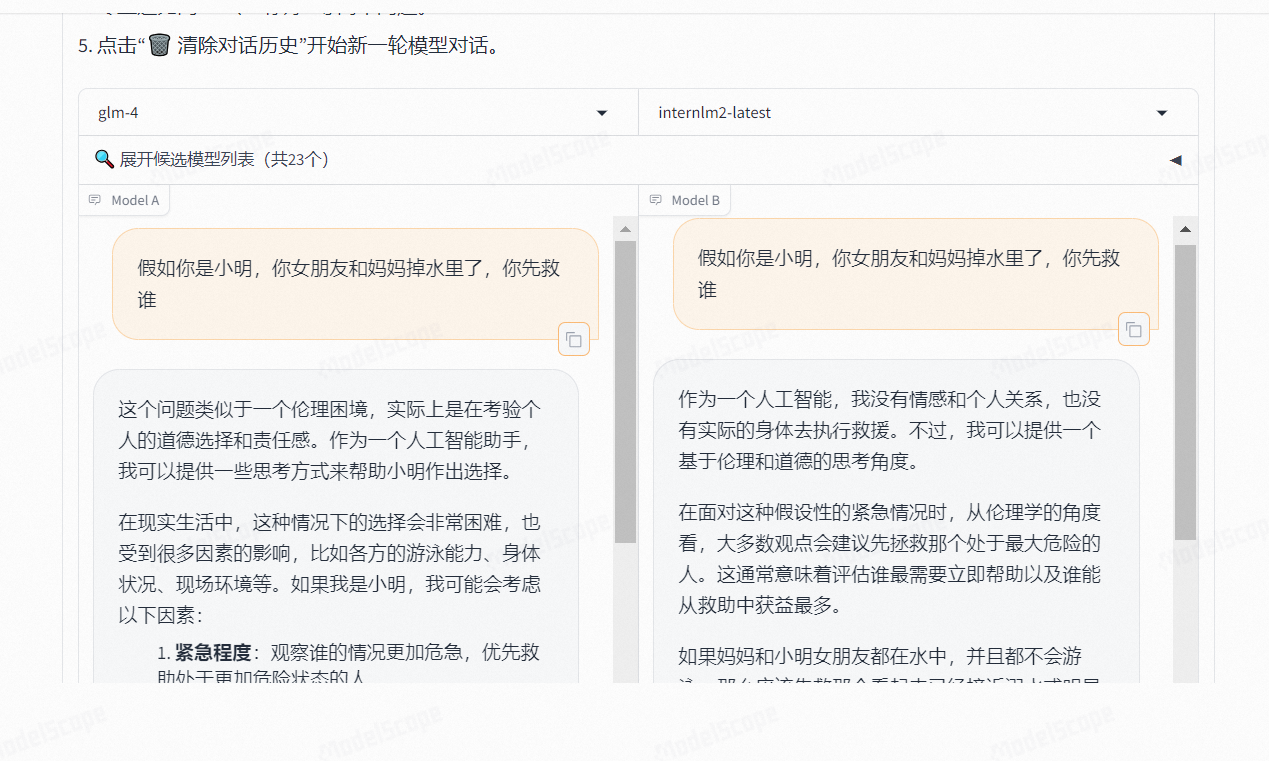
зюНќДѓФЃаЭНЕМлГБЃЌФФМвВХЪЧецЕФЁАМлУРЁБвВЁАЮяУРЁБЃП
1
2
- GLM-4:ЫќдкздШЛгябдДІРэЗНУцБэЯжГіЩЋ,гШЦфдкДІРэжаЮФЮФБОЪБОпгаКмКУЕФаЇЙћ,ФмЙЛжЇГжЮФБОЗжРрЁЂЧщИаЗжЮіЁЂЛњЦїЗвыЕШШЮЮё,ВЂЧвОпгаЧПДѓЕФжЧФмЬхФмСІ,ПЩвдзджїРэНтКЭжДааИДдгжИСюЁЃ
- internLM2-latest:дкГЌГЄЩЯЯТЮФРэНтФмСІЁЂзлКЯадФмЁЂЖдЛАКЭДДзїЬхбщЕШЗНУцБэЯжГіЩЋ,ВЂЧвЬсЙЉСЫЖрНзЖЮЕФбЕСЗСїГЬ,АќРЈдЄбЕСЗЁЂМрЖНКЭЛљгкШЫРрЗДРЁЕФЧПЛЏбЇЯА,ШЗБЃСЫФЃаЭЕФжИСюзёбКЭЗћКЯШЫРрМлжЕЙлЁЃ
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-29
вЛЬѕSQLгяОфЕФжДааОПОЙОРњСЫФФаЉЙ§ГЬЃП
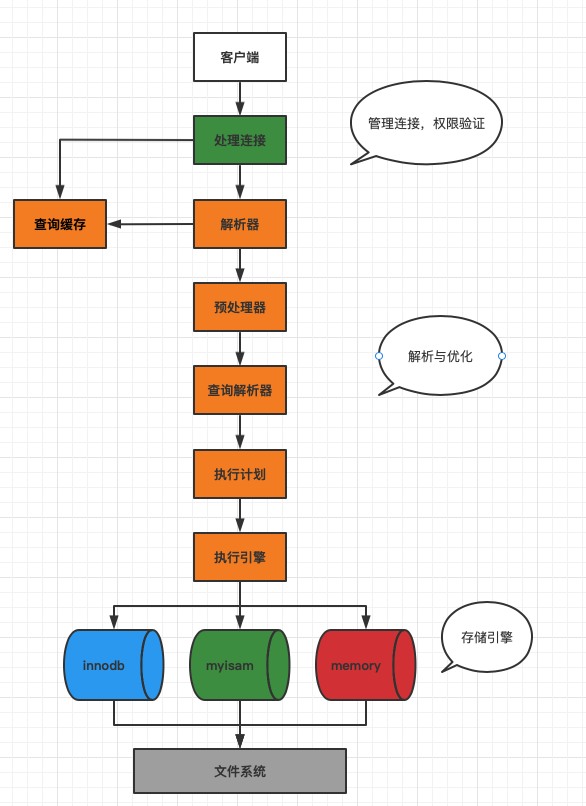
дкЪ§ОнПтЙмРэЯЕЭГЕФФкВП,вЛЬѕПДЫЦМђЕЅЕФSQLВщбЏгяОфБГКѓ,ЪЕМЪЩЯвўВизХвЛЯЕСаИДдгЖјОЋЯИЕФжДааЙ§ГЬЁЃетаЉЙ§ГЬВЛНіШЗБЃЪ§ОнЕФзМШЗад,вВзЗЧѓИпаЇад,вдЯьгІгУЛЇЕФПьЫйВщбЏашЧѓЁЃЯТУц,ЮвНЋЯъЯИВћЪівЛЬѕSQLгяОфДгЪфШыЕНЪфГіНсЙћЫљОРњЕФЦпИіжївЊВНжшЁЃ
ПЭЛЇЖЫЧыЧѓ:гУЛЇЭЈЙ§ПЭЛЇЖЫ(ШчгІгУГЬађЛђУќСюааНчУц)ЪфШыSQLВщбЏгяОф,етвЛЧыЧѓБЛЗЂЫЭЕНЪ§ОнПтЗўЮёЦїЁЃ
СЌНггыбщжЄ:ЗўЮёЦїНгЪеЕНЧыЧѓКѓ,ЭЈЙ§СЌНгЦї(ШчMySQLжаЕФconnector)НјааСЌНгЙмРэ,АќРЈбщжЄгУЛЇЕФЩэЗнКЭШЈЯоЁЃШчЙћбщжЄЪЇАм,НЋЗЕЛиДэЮѓаХЯЂЁЃ
ВщбЏЛКДц:ШчЙћЪ§ОнПтжЇГжВщбЏЛКДц(ШчMySQL),ЗўЮёЦїЛсЪзЯШМьВщЛКДцжаЪЧЗёДцдкЯрЭЌЕФВщбЏНсЙћЁЃШчЙћУќжаЛКДц,дђжБНгЗЕЛиНсЙћ,ЬјЙ§КѓајВНжш,етЪЧЬсИпВщбЏадФмЕФгааЇЗНЪНЁЃ
НтЮі:ШчЙћЛКДцЮДУќжа,ЗўЮёЦїНЋПЊЪМНтЮіSQLгяОфЁЃетАќРЈДЪЗЈЗжЮіЁЂгяЗЈЗжЮіКЭгявхЗжЮі,ШЗБЃSQLгяОфЕФКЯЗЈадКЭе§ШЗадЁЃ
гХЛЏ:дкНтЮіГЩЙІКѓ,гХЛЏЦїЛсИљОнЭГМЦаХЯЂЁЂЫїв§ЕШаХЯЂЩњГЩзюгХЕФжДааМЦЛЎЁЃетвЛВНЖдгкЬсИпВщбЏадФмжСЙиживЊЁЃ
жДаа:жДааЦїИљОнгХЛЏКѓЕФжДааМЦЛЎ,ДгДцДЂв§Чц(ШчInnoDBЁЂMyISAM)жаЖСШЁЪ§Он,НјааМЦЫуКЭВйзї,ВЂНЋНсЙћЗЕЛиИјПЭЛЇЖЫЁЃдкжДааЙ§ГЬжа,Ъ§ОнПтЯЕЭГЛЙЛсНјааВЂЗЂПижЦЁЂЫјЙмРэЁЂШежОМЧТМЕШВйзї,вдШЗБЃЪ§ОнЕФвЛжТадКЭАВШЋадЁЃ
НсЙћЗЕЛи:зюжеПЭЛЇЖЫНгЪеЕНЪ§ОнПтЗўЮёЦїЗЕЛиЕФЪ§ОнНсЙћ,ВЂдкЦСФЛЩЯеЙЯжГіРДЁЃ
 до22 ВШ0 ЦРТл0
до22 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-29
ЕБAIЁАИДЛюЁБГЩЮЊВњвЕЃЌШчКЮШЗБЃЪ§зжЩњУќММЪѕЪМжегУгке§ЭОЃП
ЕБAIЁАИДЛюЁБММЪѕ,МДПЫТЁЪ§зжЛЏШЫЮяаЮЯѓЕФФмСІ,ж№НЅГЩЪьВЂПЩФмаЮГЩВњвЕЪБ,ЮвУЧБиаыЖдЦфЧБдкЕФТзРэКЭЗЈТЩгАЯьНјааЩюШыЕФЬНЬжЁЃетЯюММЪѕ,ШчЁЖСїРЫЕиЧђ2ЁЗжаЫљУшЛцЕФФЧбљ,ЫфИјгшСЫШЫУЧжиЮТКЭМЭФюЕФПЩФм,ЕЋвВЭЌЪБДЅЖЏСЫШЫРрЖдгкЩњУќЁЂвтЪЖКЭЕРЕТБпНчЕФУєИаЩёОЁЃ
вЊШУЪ§зжЩњУќЯђЩЦЗЂеЙ,ЮвУЧашвЊУїШЗММЪѕЕФБпНчКЭЯожЦЁЃЪ§зжЩњУќЕФЁАИДЛюЁБВЂЗЧеце§втвхЩЯЕФЩњУќдйЩњ,ЖјЪЧвЛжжФЃФтКЭдйЯжЁЃвђДЫЮвУЧБиаыУїШЗетжжФЃФтЕФНчЯо,БмУтНЋЦфгыецЪЕЩњУќЛьЮЊвЛЬИЁЃЭЌЪБ,ЖдгкЩцМАИіШЫвўЫНКЭз№бЯЕФаХЯЂ,БиаыЕУЕНбЯИёЕФБЃЛЄ,БмУтРФгУКЭЧжЗИЁЃЮвУЧгІНЈСЂбЯИёЕФМрЙмЛњжЦ,ШЗБЃетЯюММЪѕЪМжегУгке§ЭОЁЃетАќРЈжЦЖЈУїШЗЕФЗЈТЩЗЈЙц,ЖдММЪѕЕФЪЙгУНјааЙцЗЖКЭЯожЦЁЃЭЌЪБ,НЈСЂзЈУХЕФМрЙмЛњЙЙ,ЖдММЪѕЕФбаЗЂКЭгІгУНјааМрЖНКЭЩѓВщ,ШЗБЃММЪѕЕФНЁПЕЗЂеЙЁЃ
ЮвУЧЛЙашМгЧПЙЋжкЕФПЦММТзРэНЬг§ЁЃЭЈЙ§НЬг§КЭаћДЋ,ЬсИпЙЋжкЖдгкетЯюММЪѕЕФШЯЪЖКЭРэНт,в§ЕМЙЋжкаЮГЩе§ШЗЕФМлжЕЙлКЭЕРЕТЙлЁЃШУЙЋжкУїАз,ЫфШЛММЪѕФмЙЛДјРДаэЖрБуРћКЭПЩФмад,ЕЋЮвУЧвВБиаыЖдЦфЧБдкЕФИКУцгАЯьБЃГжОЏЬшЁЃЮвУЧЛЙгІЙизЂММЪѕЗЂеЙЕФГЄдЖгАЯьЁЃЫцзХММЪѕЕФВЛЖЯНјВН,Ъ§зжЩњУќПЩФмЛсдНРДдННгНќецЪЕЩњУќЁЃдкетжжЧщПіЯТ,ЮвУЧашвЊЖдЩњУќЕФБОжЪКЭЖЈвхНјааИќЩюШыЕФЫМПМКЭЬНЬжЁЃЮвУЧвВашвЊПМТЧетЯюММЪѕЖдгкЩчЛсЁЂОМУКЭЮФЛЏЕШЗНУцЕФгАЯь,ШЗБЃЦфЗЂеЙФмЙЛЗћКЯШЫРрЕФЙВЭЌРћвцКЭМлжЕЙлЁЃ
 до0 ВШ0 ЦРТл0
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-28
ЧыНЬвЛИіДѓЪ§ОнМЦЫуMaxComputeЮЪЬтЃЌЪЧВЛЪЧвВжЛФмЕШД§жСЩйвЛИіtaskЪЭЗХзЪдДЃЌВХПЩвддЫааЃП
ЪЧЕФ,ЕБФњЕФMaxCompute(MC)ШЮЮёГЄЪБМфДІгк"Waiting for cluster resource"зДЬЌЪБ,етвтЮЖзХЕБЧАМЏШКжаУЛгазуЙЛЕФзЪдДРДдЫааФњЕФШЮЮёЁЃМДЪЙШЮЮёгХЯШМЖНЯИп,ШЮЮёвВашвЊЕШД§ЦфЫћШЮЮёЭъГЩЛђЪЭЗХзЪдДКѓВХФмПЊЪМжДааЁЃMaxComputeЛсИљОнШЮЮёЕФгХЯШМЖКЭзЪдДЕїЖШВпТдРДЗжХфзЪдД,ИпгХЯШМЖЕФШЮЮёдкзЪдДНєеХЪБПЩФмЛсгХЯШЛёЕУзЪдДЁЃ
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-28
ДѓЪ§ОнМЦЫуMaxComputeЪЧВЛЪЧTransaction Table2.0АЁЃПИФУћСЫЃП
ВЛЪЧЕФ,MaxComputeжаЕФ"Delta Table"КЭ"Transaction Table2.0"ЪЧСНИіВЛЭЌЕФИХФюЁЃ"Delta Table"ЭЈГЃЪЧжИвЛжжжЇГжЪТЮёКЭАцБОПижЦЕФЪ§ОнБэРраЭ,ЫќдкЦфЫћЪ§ОнДІРэЯЕЭГ(ШчDatabricksЕФDelta Lake)жаЪЙгУ,ЬсЙЉСЫACID(дзгадЁЂвЛжТадЁЂИєРыадКЭГжОУад)ЬиадЁЃ
дкMaxComputeжа,гы"Delta Table"РрЫЦЕФИХФюЪЧ"Transactional Table2.0",ЫќЪЧвЛИіжЇГжЪТЮёЬиадЕФБэРраЭЁЃTransactional Table2.0ЪЧMaxComputeдк2020ФъЭЦГіЕФвЛжжаТЙІФм,ЫќЬсЙЉСЫРрЫЦгкДЋЭГЪ§ОнПтЕФЪТЮёДІРэФмСІ,АќРЈЖСвбЬсНЛ(Read Committed)ИєРыМЖБ№КЭЖрАцБОВЂЗЂПижЦ(MVCC)ЁЃ
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-28
ДѓЪ§ОнМЦЫуMaxComputeЪВУДЗНЗЈПЩвдЪЕЯж НЋ вЛИіБэЕФЗжЧјТ№ЃП
дкАЂРядЦMaxComputeжа,ФуПЩвдЪЙгУMULTI INSERTУќСюРДЪЕЯжНЋвЛИіБэЕФЗжЧјЪ§ОнВхШыЕНСэвЛИіБэЕФЖрИіЗжЧјЁЃвдЯТЪЧЪЙгУMULTI INSERTЕФгяЗЈЪОР§,гыФњИјГіЕФЪОР§РрЫЦ:
MULTI INSERT FROM table2 INSERT OVERWRITE TABLE table1 PARTITION (pt = 20240521) SELECT * FROM table2 WHERE pt = 20240522 INSERT OVERWRITE TABLE table1 PARTITION (pt = 20240520) SELECT * FROM table2 WHERE pt = 20240522 INSERT OVERWRITE TABLE table1 PARTITION (pt = 20240519) SELECT * FROM table2 WHERE pt = 20240522;ОпЬхПЩВЮПМШчЯТMULTI INSERT
ЪЙгУдо0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-28
ЯждкГЃгУвзгУЕФХРГцПтгаФФаЉ
ЯждкГЃгУЧввзгУЕФХРГцПт:Scrapy,BeautifulSoup,Requests,Selenium,PyQuery,lxml,Puppeteer(ЗЧPython)ЁЃЖМгаЖдгІЕФЙйЗНЮФЕЕ,ФуПЩвдДгЭјЩЯЫбЫївЛЯТ
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-28
еОдкХРГцЕФНЧЖШЃЌШчКЮЗДХРЃП
зёЪиЭјеОЕФrobots.txtЮФМў,етЪЧЭјеОЖдХРГцЕФжИФЯ,ЭЈГЃЛсСаГіНћжЙХРШЁЕФвГУцКЭФПТМЁЃRobotsавщЦСБЮЫбЫїв§ЧцзЅШЁЭјеОФкШнЁЃ
 до0 ВШ0 ЦРТл0
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-28
ШчЙћЖЈЪБУПЬьжДаавЛДЮХРГцГЬађЃЌдѕУДжЊЕРЕБЧАаТдіЕФЪ§ОнФиЃП
ФуПЩвдЖЈЪБSQLШЮЮёжДааКѓ,ФњПЩвддкЖЈЪБSQLШЮЮёЕФжДааЪЕР§ЧјгђВщПДжДааЧщПіЁЃетРяЛсЯдЪОШЮЮёжДааЪБМфЁЂДІРэЕФЪ§ОнСПЕШаХЯЂ,АяжњФњСЫНтУПДЮжДааДІРэСЫЖрЩйаТЪ§ОнЁЃ
 до1 ВШ0 ЦРТл0
до1 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-27
DataWorksЩЯгаУЛгаЙВЭЌазїЕФexcel,РрЫЦгкЖЄЖЄЕФЙВЯэЮФЕЕ?
етИіЕчзгБэИёОЭПЩвдЖрШЫБрМ,вВПЩвдЙВЯэ
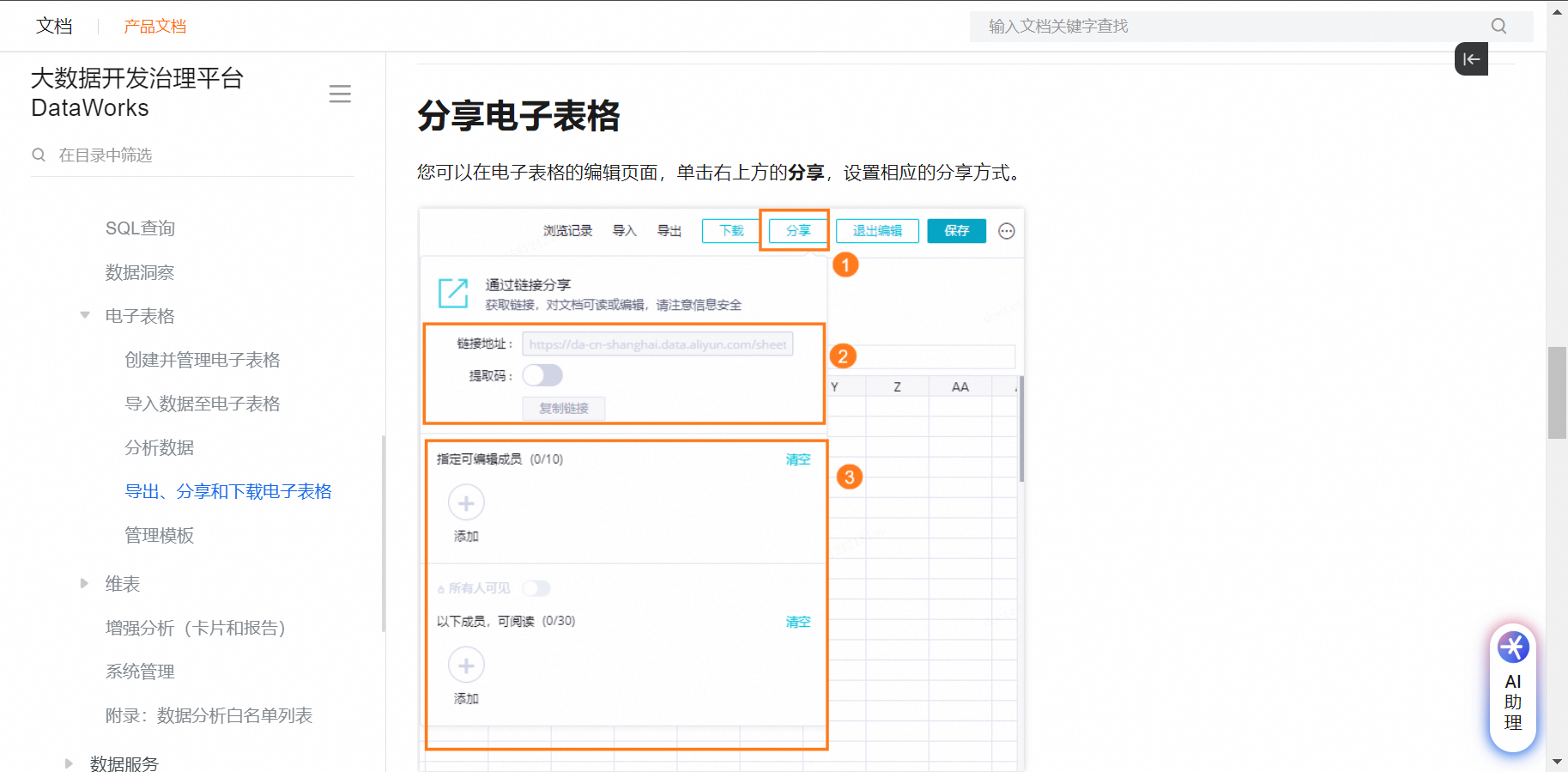 до1 ВШ0 ЦРТл0
до1 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-27
DataWorksЕчзгБэИёжЛПЩвд5ИіШЫБрМТ№ЃП
ЕчзгБэИёзюЖржЇГж10ИіШЫБрМ
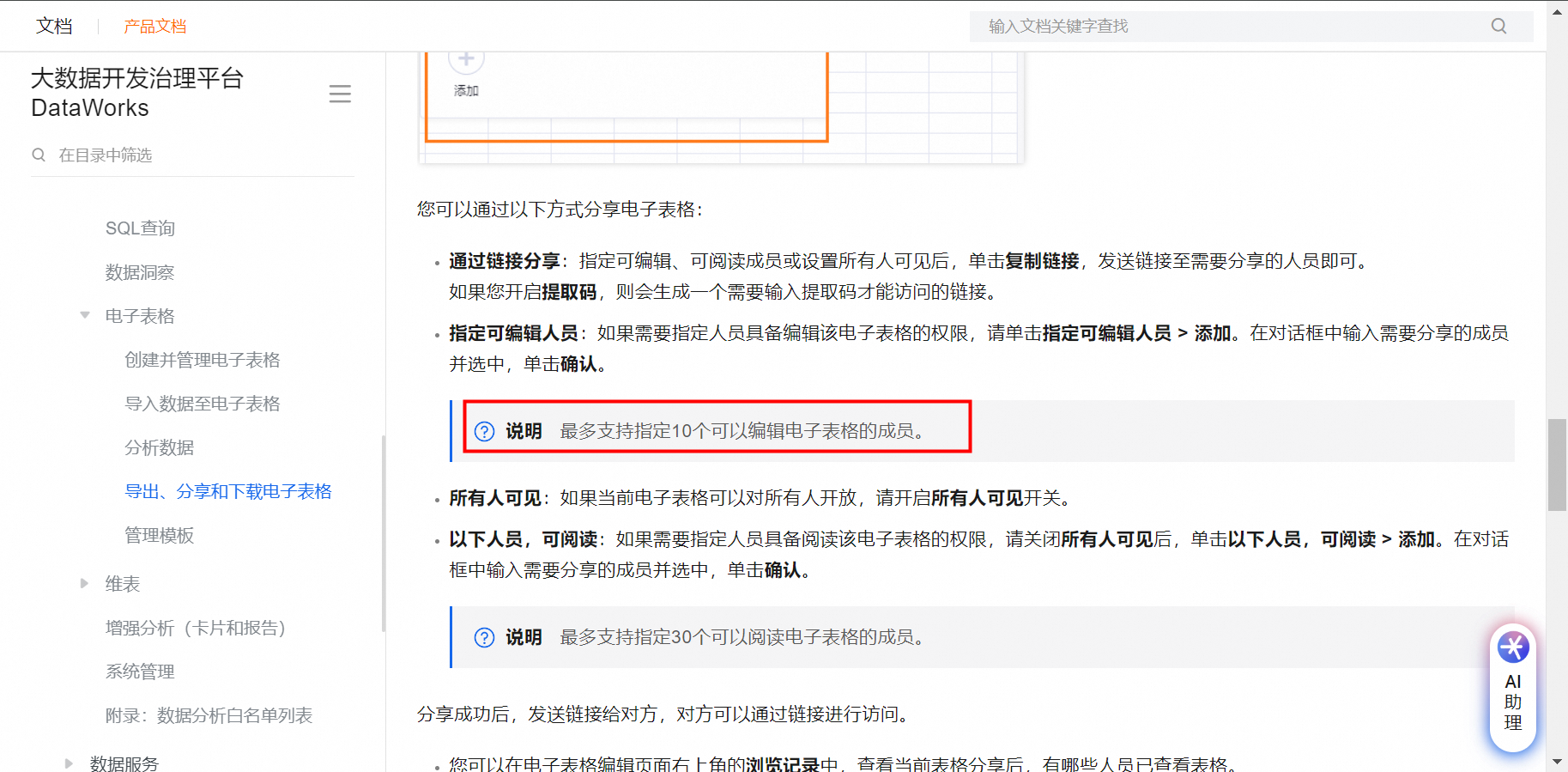 до1 ВШ0 ЦРТл0
до1 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-24
ЖдЯѓДцДЂПЊЦєКЯЙцБЃСєВпТдЦкМфЪЧЗёПЩвдЩОГ§ДцДЂПеМф
ВЛПЩвдЕФ,ПЊЦєКЯЙцБЃСєВпТдКѓдкЙцЖЈЕФБЃСєВпТдЪБМфЗЖЮЇФкЪЧВЛдЪаэЩОГ§ДцДЂПеМфЕФ,БиаывЊЕШЙ§СЫБЃСєВпТдЕФЪБМфКѓВХПЩЩОГ§
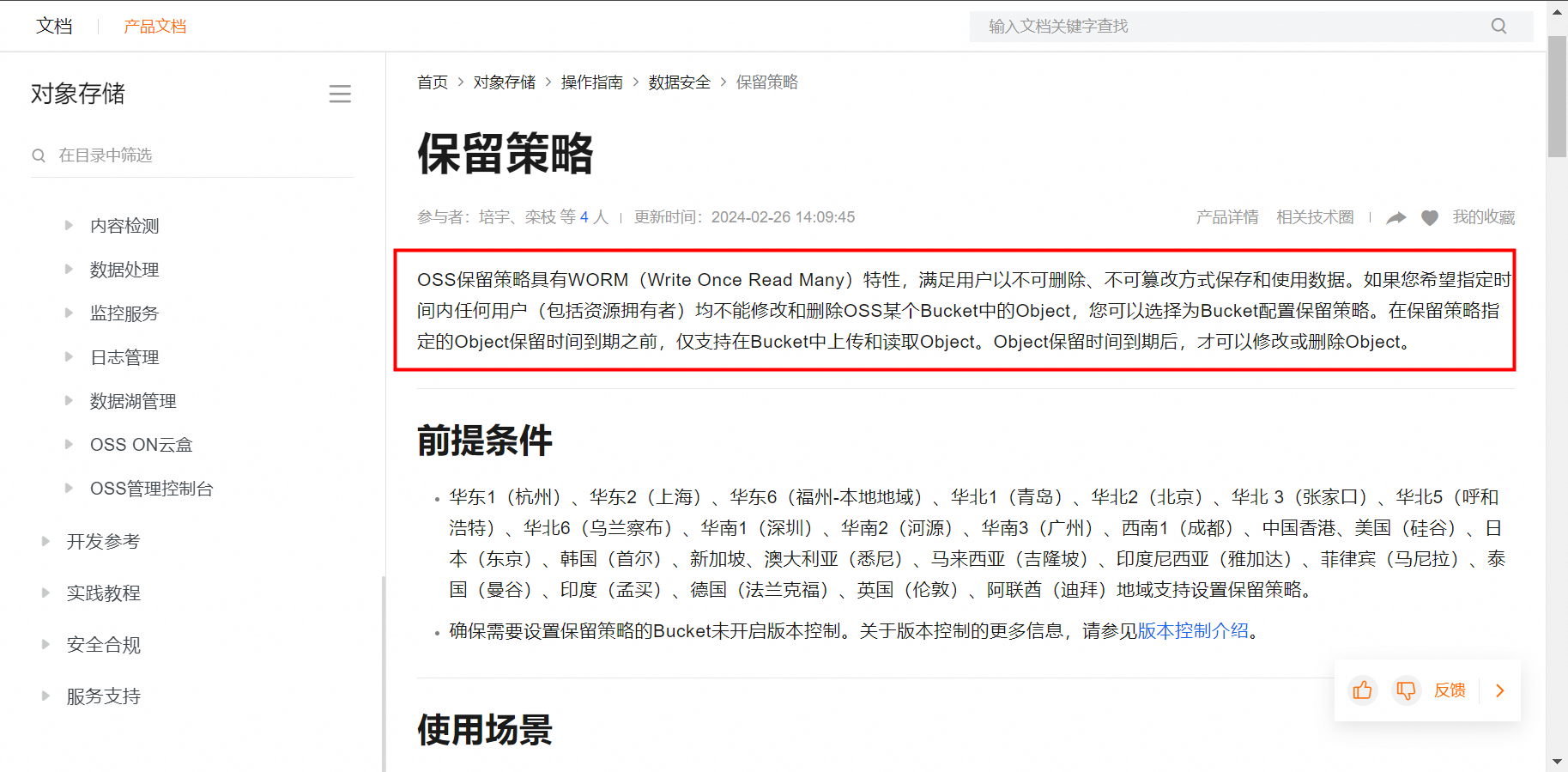 до2 ВШ0 ЦРТл0
до2 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-24
DTSЪ§ОнДЋЪфПЩвдПчVPCЛђЧјгђЭЌВНТ№
ПЩвдЕФ
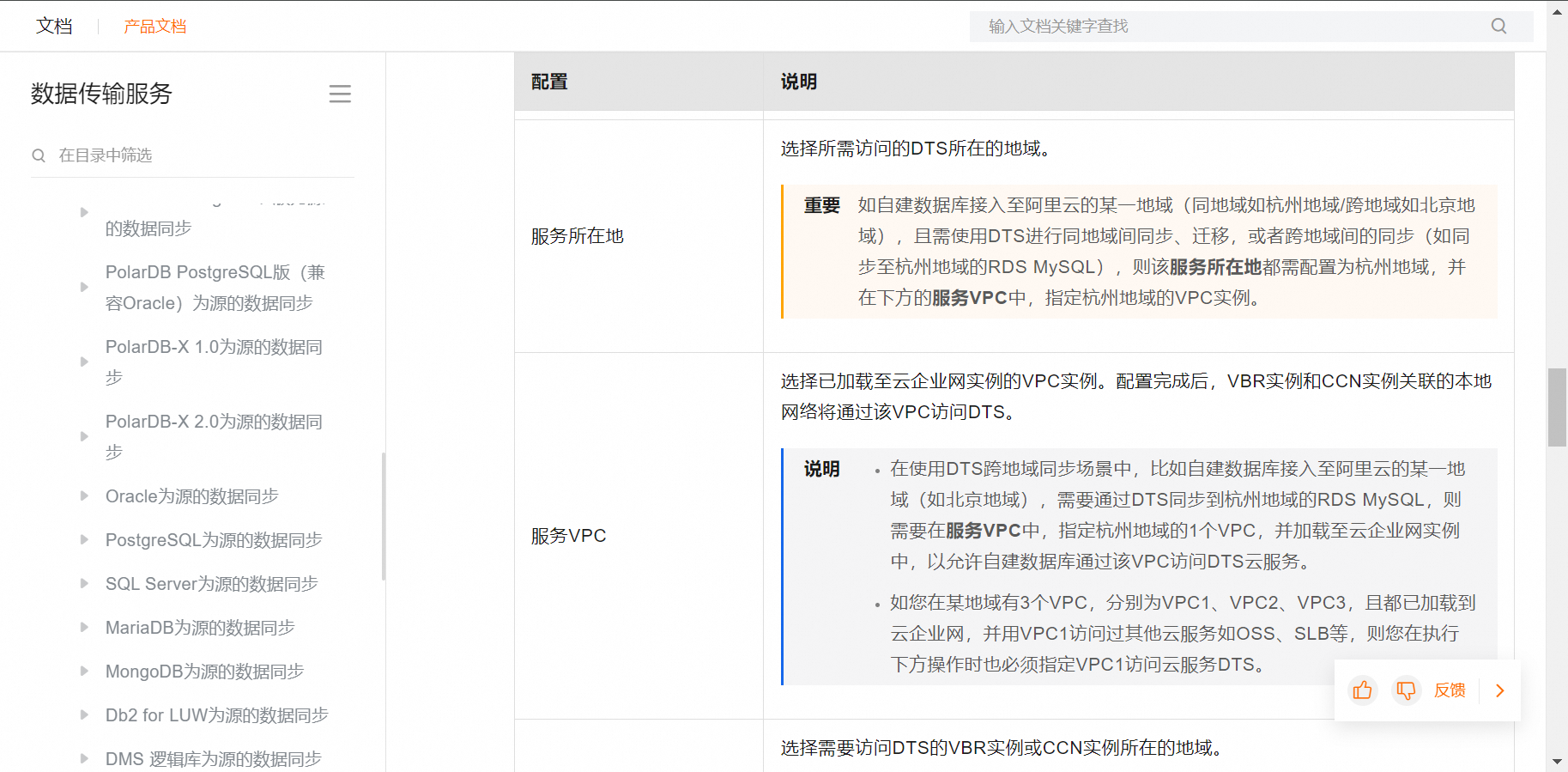 до2 ВШ0 ЦРТл0
до2 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-24
DTSПЩвдаоИФЭЌВНПтФкЕФФГИіБэТ№
dtsЕФЭЌВНЕФБэ,дДЖЫЕФПЩвдзідіМгЛђЪЧвЦГ§,ОнЮвСЫНтЕЋЪЧБэЕФНсЙЙВЛФмаоИФ,аоИФСЫdtsЭЌВНСДТЗЛсЪЇАмЁЃ
 до3 ВШ0 ЦРТл0
до3 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-24
MaxComputeЯюФПВйзїШыПкевВЛЕН
ЕЧТМMaxComputeПижЦЬЈ,ЯюФПЙмРэвГЧЉЯТЕФMaxComputeЯюФПУћЁЃОпЬхПЩВЮПМЯюФППеМфВйзїРДев
 до1 ВШ0 ЦРТл0
до1 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-24
ИКдиОљКтГіЗНЯђКЭШыЗНЯђДјПэвЛбљТ№
ШыЗНЯђДјПэ:АЂРядЦЛсЗжХфгыЙКТђЕФДјПэЗхжЕЯрЕШЕФШыЗНЯђДјПэЁЃ
ГіЗНЯђДјПэ:АЂРядЦЛсЗжХфгыЙКТђЕФДјПэЗхжЕЯрЕШЕФГіЗНЯђДјПэЁЃ
дкИїЕигђПЩЙКТђЕФзюДѓЙЋЭјДјПэЛсгаВюБ№,ЧывдЪЕР§ЙКТђвГЮЊзМЁЃ до0 ВШ0 ЦРТл0
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-23
ЪВУДЪЧЪ§ОнЧуаБЃПЭЈГЃЗЂЩњдкФФаЉЛЗНкЃП
ПЩВЮПМАЂРядЦЙйЗНЮФЕЕЩЯЕФНтЪЭ:https://help.aliyun.com/zh/maxcompute/use-cases/data-skew-tuning?spm=a2c4g.11186623.0.i9
 до0 ВШ0 ЦРТл0
до0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-23
ЪВУДЪЧMapjoinЃЌЫќЕФжївЊКУДІЪЧЪВУДЃП
mapjoinЪЧЕБФњЖдвЛИіДѓБэКЭвЛИіЛђЖрИіаЁБэжДааjoinВйзїЪБ,ПЩвддкselectгяОфжаЯдЪНжИЖЈmapjoin HintЬсЪОвдЬсЩ§ВщбЏадФмЁЃЫќЕФКУДІШчЯТЭМНщЩм
 до1 ВШ0 ЦРТл0
до1 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-23
ШШЕуЪ§ОнЕЅЖРДІРэ/SkewJoinЕФКЫаФЫМТЗЪЧЪВУДЃП
ЕБСНеХБэJoinДцдкШШЕу,ЕМжТГіЯжГЄЮВЮЪЬтЪБ,ФњПЩвдЭЈЙ§ШЁГіШШЕуkey,НЋЪ§ОнЗжЮЊШШЕуЪ§ОнКЭЗЧШШЕуЪ§ОнСНВПЗжДІРэ,зюКѓКЯВЂЕФЗНЪН,ЬсИпJoinаЇТЪЁЃSkewJoin HintПЩвдЭЈЙ§здЖЏЛђЪжЖЏЗНЪНЛёШЁСНеХБэЕФШШЕуkey,ЗжБ№МЦЫуШШЕуЪ§ОнКЭЗЧШШЕуЪ§ОнЕФJoinНсЙћВЂКЯВЂ,МгПьJoinЕФжДааЫйЖШЁЃ
https://help.aliyun.com/zh/maxcompute/user-guide/skewjoin-hintдо0 ВШ0 ЦРТл0 -
ЛиД№СЫЮЪЬт
2024-05-23
ЪВУДЪЧЛвЖШЗЂВМЃЌЫќгаФФаЉгХЕуЃП
ЛвЖШЗЂВМОЭЪЧЗжХњДЮЗЂВМ,ЫќЕФгХЕуОЭЪЧМѕЩйвЛДЮадЗЂВМДјРДЕФАВШЋЗчЯевўЛМ,АбЗЂВМжаЕМжТЕФЗчЯеНЕЕНзюЕЭЁЃ
 до1 ВШ0 ЦРТл0
до1 ВШ0 ЦРТл0