 SheepRunner
SheepRunner
SheepRunner_个人页
SheepRunner



文章
0
问答
75
视频
0
个人介绍
breaking into a run
擅长的技术
获得更多能力

通用技术能力:
-
Java
高级
能力说明:
精通JVM运行机制,包括类生命、内存模型、垃圾回收及JVM常见参数;能够熟练使用Runnable接口创建线程和使用ExecutorService并发执行任务、识别潜在的死锁线程问题;能够使用Synchronized关键字和atomic包控制线程的执行顺序,使用并行Fork/Join框架;能过开发使用原始版本函数式接口的代码。
-
Linux
初级
能力说明:
掌握计算机基础知识,初步了解Linux系统特性、安装步骤以及基本命令和操作;具备计算机基础网络知识与数据通信基础知识。
云产品技术能力:
-
Clouder
-
Apsara Clouder云原生专项技能认证:函数计算入门和实战
获得于2023-05-04 21:18:59
-
Apsara Clouder云计算专项技能认证:云服务器ECS入门
获得于2023-05-04 21:04:58
-
Apsara Clouder云计算技能认证:超大流量网站的负载均衡
获得于2023-05-04 06:38:23
-
Apsara Clouder云计算技能认证:云服务器基础运维与管理
获得于2023-05-03 21:30:37
-
Apsara Clouder云计算技能认证:网站建设:部署与发布
获得于2023-05-03 19:54:35
-
Apsara Clouder云原生专项技能认证:函数计算入门和实战
阿里云技能认证
详细说明

暂无更多信息
2024年04月
-
04.20 22:15:39
 回答了问题
2024-04-20 22:15:39
回答了问题
2024-04-20 22:15:39
作为一个经典架构模式,事件驱动在云时代为什么会再次流行呢?
赞40 踩0 评论0 -
04.20 19:05:55回答了问题
2024-04-20 19:05:55
在做程序员的道路上,你掌握了什么关键的概念或技术让你感到自身技能有了显著飞跃?
赞53 踩0 评论0 -
04.20 18:46:43回答了问题
2024-04-20 18:46:43
如何看待首个 AI 程序员入职科技公司?
赞20 踩0 评论0 -
04.12 06:38:44回答了问题
2024-04-12 06:38:44
在图像处理应用场景下,Serverless架构的优势体现在哪些方面?
赞52 踩0 评论0 -
04.10 22:18:12回答了问题
2024-04-10 22:18:12
如何处理线程死循环?
赞8 踩0 评论0 -
04.10 22:14:54回答了问题
2024-04-10 22:14:54
如何写出更优雅的并行程序?
赞36 踩0 评论0
2024年03月
-
03.27 21:32:30回答了问题
2024-03-27 21:32:30
你的数据存储首选网盘还是NAS?
赞4 踩0 评论0 -
03.27 21:26:59回答了问题
2024-03-27 21:26:59
如何看待云原生数据库一体化的技术趋势?
赞13 踩0 评论0 -
03.27 20:56:16回答了问题
2024-03-27 20:56:16
人工智能大模型如何引领智能时代的革命?
赞10 踩0 评论0 -
03.27 20:49:56回答了问题
2024-03-27 20:49:56
-
03.21 06:39:59回答了问题
2024-03-21 06:39:59
程序员为什么不能一次性写好,需要一直改Bug?
赞1 踩0 评论0 -
03.20 06:36:33回答了问题
2024-03-20 06:36:33
你体验过让大模型自己写代码、跑代码吗?
赞5 踩0 评论0 -
03.14 06:02:18回答了问题
2024-03-14 06:02:18
人工智能带来新机遇,国产服务器操作系统如何加快发展?
赞13 踩0 评论0 -
03.12 06:20:17回答了问题
2024-03-12 06:20:17
让 AI 写代码,能做出什么样的项目?
赞1 踩0 评论0 -
03.09 06:38:37回答了问题
2024-03-09 06:38:37
开发者,你在云上建设过怎样的世界?
赞9 踩0 评论0 -
03.07 06:43:52回答了问题
2024-03-07 06:43:52
你使用过代码生成工具吗?
赞31 踩0 评论0
2024年02月
-
02.28 21:00:12回答了问题
2024-02-28 21:00:12
Agent一路狂飙,未来在哪?
赞2 踩0 评论0 -
02.28 20:31:09回答了问题
2024-02-28 20:31:09
如何看待阿里云PolarDB登顶2024最新一期中国数据库流行榜?
赞4 踩0 评论0 -
02.28 20:24:09回答了问题
2024-02-28 20:24:09
开动脑洞,你最想用Sora生成什么样的视频?
赞2 踩0 评论0 -
02.28 20:03:25回答了问题
2024-02-28 20:03:25
你会在Vision Pro里编程吗?
赞2 踩0 评论0 -
02.22 20:43:30回答了问题
2024-02-22 20:43:30
Sora面世,你有哪些畅想?
赞4 踩0 评论0 -
02.22 20:28:53回答了问题
2024-02-22 20:28:53
阿里云容器服务 ACK AI 助手正式上线,你都有哪些期待?
赞5 踩0 评论0 -
02.21 06:30:03回答了问题
2024-02-21 06:30:03
国产算力土壤之上,能孕育出怎样的AI创新之花?
赞4 踩0 评论0 -
02.20 10:15:21回答了问题
2024-02-20 10:15:21
如果用你的专业送上新春祝福,会是什么样的?
赞2 踩0 评论1 -
02.07 15:55:04回答了问题
2024-02-07 15:55:04
如何看待阿里云数据库走向Serverless与AI驱动的一站式数据平台?
赞45 踩0 评论0 -
02.06 15:12:09回答了问题
2024-02-06 15:12:09
开发者如何应对职业压力?
赞3 踩0 评论0 -
02.04 14:20:58回答了问题
2024-02-04 14:20:58
2023年你读了哪些社区电子书?
赞2 踩0 评论0 -
02.03 20:59:38回答了问题
2024-02-03 20:59:38
我对ECS的付费方式有话说
赞6 踩0 评论0 -
02.02 14:54:39回答了问题
2024-02-02 14:54:39
全球 IPv4 地址即将耗尽意味着什么?
赞8 踩0 评论0
2024年01月
-
01.31 23:44:42回答了问题
2024-01-31 23:44:42
如何让系统长期“三高”?
赞4 踩0 评论0 -
01.31 22:58:26回答了问题
2024-01-31 22:58:26
你会选择成为一名独立开发者吗?
赞8 踩0 评论0 -
01.24 21:10:52回答了问题
2024-01-24 21:10:52
你完整阅读过源码吗?
赞1 踩0 评论0
2023年12月
-
12.19 20:55:21回答了问题
2023-12-19 20:55:21
代码优化与过度设计,你如何平衡?
赞6 踩0 评论0 -
12.17 20:52:53回答了问题
2023-12-17 20:52:53
偏向锁被废弃了?谈谈你背的那些“八股文”
赞1 踩0 评论0 -
12.14 22:16:48回答了问题
2023-12-14 22:16:48
站在业务技术团队的开发视角,你认同“可读性”是代码的第一优先级要求吗?
赞8 踩0 评论0
2023年11月
-
11.10 22:31:45回答了问题
2023-11-10 22:31:45
每个开发者都应该有一台云服务器吗?
赞62 踩0 评论0 -
11.10 22:17:09回答了问题
2023-11-10 22:17:09
如何看待云计算的第三次浪潮?
赞6 踩0 评论0
2023年10月
-
10.25 06:40:22回答了问题
2023-10-25 06:40:22
算力是开发的源头之水吗?
赞0 踩0 评论0 -
10.07 21:46:22回答了问题
2023-10-07 21:46:22
Node.js 未来会在前端领域一家独大吗?
赞14 踩0 评论1 -
10.03 16:05:55回答了问题
2023-10-03 16:05:55
推荐算法真的是用户最优选择吗?
赞4 踩0 评论0
2023年09月
-
09.25 22:13:57回答了问题
2023-09-25 22:13:57
亚运会&开发者,你觉得有哪些创意的参与方式?
赞3 踩0 评论0 -
09.24 06:29:36回答了问题
2023-09-24 06:29:36
你见过哪些真正“精通Excel”操作?
赞3 踩0 评论0 -
09.21 23:37:39回答了问题
2023-09-21 23:37:39
哪些事情是你成为程序员之后才知道的?
赞6 踩0 评论0 -
09.21 23:06:42回答了问题
2023-09-21 23:06:42
对程序员来说,技术能力和业务逻辑哪个更重要?
赞1 踩0 评论0 -
09.16 22:30:51回答了问题
2023-09-16 22:30:51
日常工作中,你对于日志数据都是如何利用的?
赞8 踩0 评论0 -
09.12 21:34:50回答了问题
2023-09-12 21:34:50
手撕代码是程序员的基本功吗?
赞2 踩0 评论0
2023年08月
-
08.31 22:52:21回答了问题
2023-08-31 22:52:21
-
08.31 22:20:16回答了问题
2023-08-31 22:20:16
高端的程序员,都有哪些朴素的编程方式?
赞10 踩0 评论0 -
08.19 13:36:32回答了问题
2023-08-19 13:36:32
你拥有自己搭建的博客吗?
赞8 踩0 评论0 -
08.12 23:37:16回答了问题
2023-08-12 23:37:16
如何训练属于自己的“通义千问”呢?
赞49 踩0 评论0
暂无更多信息
-
回答了问题
2024-04-20
作为一个经典架构模式,事件驱动在云时代为什么会再次流行呢?
异步通信与松耦合:
随着系统规模的扩大和复杂性的增加,传统的同步请求-响应模型容易导致性能瓶颈和系统僵化。事件驱动架构通过发布-订阅模式实现了异步通信,各组件间无需直接交互,而是通过共享消息队列或事件流来传递信息。这种松耦合特性极大地提升了系统的可伸缩性和容错能力,使得系统能够更灵活地应对高并发场景和大规模数据处理需求。实时响应与业务敏捷性:
在数字化商业环境中,对实时数据处理和快速响应业务变化的需求日益增长。EDA的核心在于对事件的即时捕获和处理,使得企业能够近乎实时地感知并响应内外部变化,如用户行为、市场动态、设备状态等。这种能力有助于提升业务敏捷性,快速迭代产品功能,优化用户体验,甚至实现预测性维护、智能决策等高级应用场景。大数据与云计算环境:
大数据的爆发式增长和云计算基础设施的成熟为EDA的广泛应用提供了土壤。云平台提供了弹性的计算资源、高效的存储与传输服务,以及丰富的消息中间件和流处理工具,极大地简化了构建和运维事件驱动系统的复杂性。同时,云原生架构如Kubernetes等对微服务和容器的支持,进一步促进了EDA与云环境的深度融合。微服务与服务网格:
微服务架构强调服务的细粒度拆分和独立部署,而EDA能够有效地协调微服务间的通信和协作。通过事件而非直接API调用来触发服务间的交互,有助于降低服务间依赖,提高系统的可扩展性和容错性。服务网格技术(如Istio)进一步强化了这一点,通过提供统一的事件路由、熔断、重试、追踪等功能,简化了微服务在EDA环境中的管理和运维。DevOps与持续交付:
EDA与DevOps文化相辅相成。事件驱动的架构设计鼓励开发团队关注业务逻辑而非底层通信细节,有利于实现快速迭代和持续交付。同时,EDA的模块化和松耦合特性使得新功能或服务可以独立开发、测试和部署,符合DevOps的“小步快跑”理念。跨组织协同与业务流程自动化:
在企业内部及跨组织的业务流程中,EDA能够促进不同系统、部门甚至合作伙伴之间的数据共享和流程协调。事件可以作为触发业务流程自动化、工作流引擎或业务规则引擎的依据,实现端到端的业务流程自动化,提升运营效率和透明度。
赞40 踩0 评论0 -
回答了问题
2024-04-20
在做程序员的道路上,你掌握了什么关键的概念或技术让你感到自身技能有了显著飞跃?
学习了设计模式,准确说是理解了面向接口编程之后,感觉才真正理解了面向对象的含义,才敢说"入门”了。
面向接口编程,其实是多个设计原则的融合,比如开闭原则、接口隔离原则和依赖倒置原则。
传递接口而非实现,就能在后续优化、运维时做到做小的影响。赞53 踩0 评论0 -
回答了问题
2024-04-20
如何看待首个 AI 程序员入职科技公司?
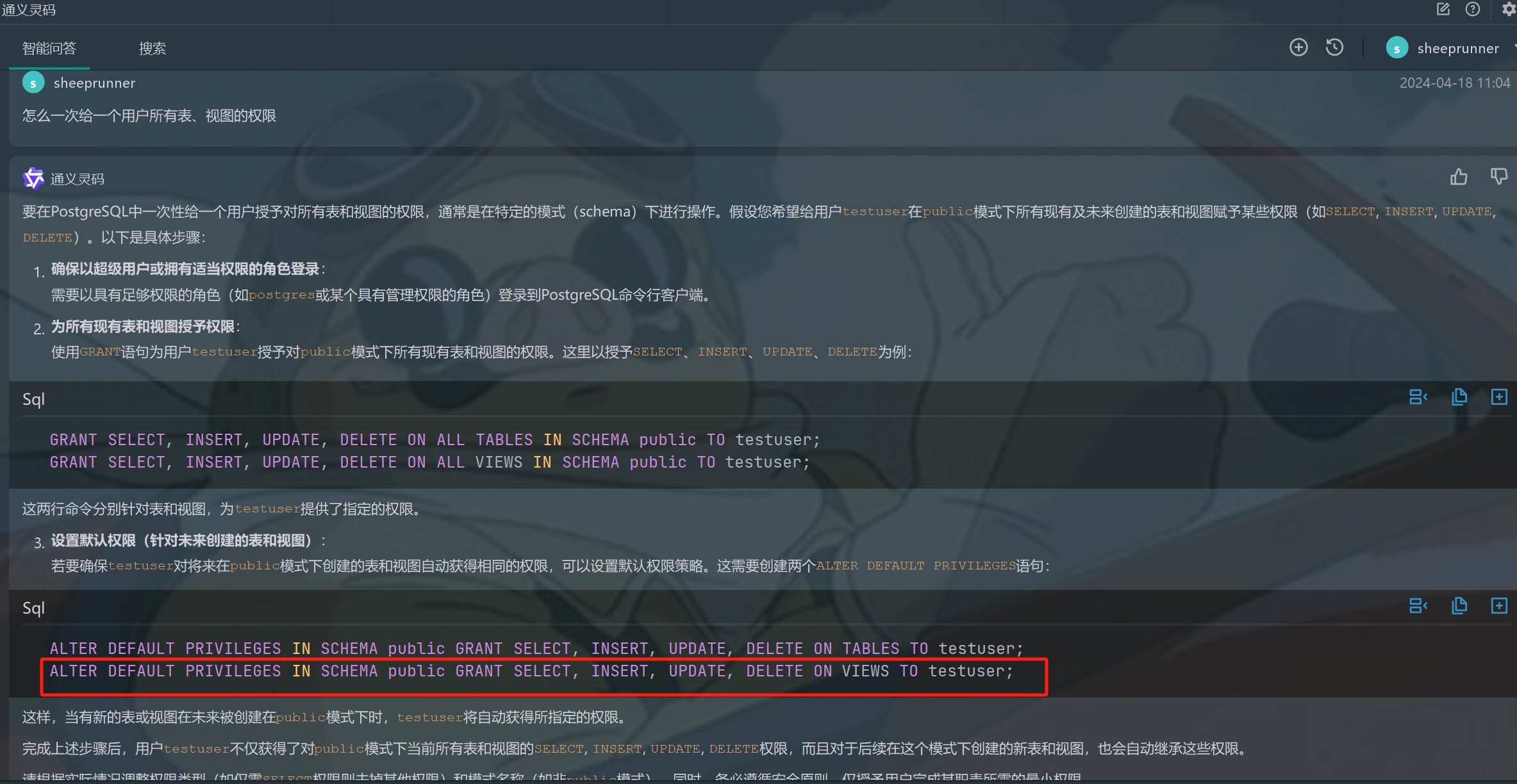
自从安装了通义灵码,确实得到了一些有益的效率提升,当然跟同事朋友们聊天,也有一些吐槽。
有益的:- 在对已有代码进行优化时,可能是基于上下文(代码、注释等)的理解,给出的提示都非常有参考性;
- 用户体验上,现在在IDEA中就能直接使用,不用打开其他客户端,更加丝滑;
- 回答的连续性更加完整,对话的前后逻辑更加严谨,给出的答案也越来越准确。
吐槽的:
- 对于有些他不清楚的逻辑,往往会根据上下文胡乱提示,有时候不小心按到Tab,很影响编程体验,特别是使用灵码初期;
- 回复内容有时会出现错误,这也无可厚非,可能是版本差异或者网上“专家”本来就给出了讹误的答案,但是为了回答的简洁而省略了必要的说明,确实容易给人误导;
- 打开多个IDE情况下,回答不能互通,还要一个个翻是在哪个IDE上提问,有点不方便。
以上吐槽为个人使用感受,因个人操作认知可能受限,不代表其他方的意见。
赞20 踩0 评论0 -
回答了问题
2024-04-12
在图像处理应用场景下,Serverless架构的优势体现在哪些方面?
1. 按需伸缩与成本效益:
- Serverless 架构能够根据实际处理需求自动、即时地伸缩计算资源,这意味着在图像处理任务量激增时,平台能迅速分配更多的计算实例来并行处理任务,而在低峰期则自动减少资源,避免闲置浪费。这种按需付费模式大大降低了固定成本投入,仅需为实际使用的计算时间付费,特别适合图像处理工作负载的突发性和间歇性特点。
2. 快速响应与高并发处理:
- Serverless 架构天然支持大规模并行处理,由于函数实例可以独立且迅速地启动,当面临大量并发的图像处理请求时,平台能够近乎实时地创建足够数量的函数实例来同时处理这些任务,确保高吞吐量和低延迟响应。这对于实时图像分析、批量图片转换、社交媒体平台的图片上传处理等场景至关重要。
3. 简化开发与运维:
- 开发者只需关注图像处理的业务逻辑,无需关心底层服务器的运维管理工作,如服务器配置、操作系统更新、负载均衡、容错机制等。Serverless 提供了封装好的服务化组件,使得开发者可以更快速地编写和部署代码,大大缩短了开发周期,降低了运维复杂度。
4. 无缝集成与服务编排:
- Serverless 平台通常与云服务商的其他服务(如对象存储、消息队列、API 网关等)深度集成,使得图像处理任务能够轻松对接数据源、触发机制和输出目的地。此外,通过函数间的触发和编排,可以构建复杂的工作流,如自动化处理上传的图片、执行一系列图像处理步骤(裁剪、压缩、水印、识别等)、并将结果存储或推送到指定位置。
5. 高可用性与灾备恢复:
- 云服务商提供的 Serverless 平台具备内置的高可用性和容错机制,如跨区域复制、故障自动切换等,确保即使在部分基础设施故障的情况下,图像处理服务仍能保持稳定运行。此外,由于数据和处理逻辑通常与云服务商的其他服务紧密集成,灾备恢复策略可以更加便捷地实施,进一步保障业务连续性。
6. 灵活的技术栈与技术创新:
- Serverless 架构支持多种编程语言和框架,开发者可以根据项目需求和团队技术栈自由选择。同时,由于无需管理服务器,团队可以快速尝试和采用新的图像处理算法、库或服务,无需顾虑底层环境的兼容性问题,有利于技术创新和快速迭代。
赞52 踩0 评论0 -
回答了问题
2024-04-10
如何处理线程死循环?
1. 代码审查与设计优化:
- 设计线程任务时,确保每个线程都有明确的终止条件,避免无限循环。
- 使用适当的设计模式,比如生产者-消费者模式、Future和CompletableFuture等异步处理机制,这些机制可以设置超时或者取消操作,有助于避免死循环。
- 对于条件判断循环,尤其是那些涉及共享资源访问和同步控制的循环,应仔细检查条件表达式是否可能出现无法满足的情况,以及锁竞争可能导致的死锁问题。
2. 日志与监控:
- 在代码中添加适当的日志输出,特别是在线程循环的关键位置,记录下循环变量、条件状态等信息,以便在出现问题时追踪回溯。
- 利用性能监控工具,观察线程CPU占用率、堆栈信息等,如果发现某个线程长期处于高负载状态且无明显进展,可能是陷入了死循环。
3. 调试与诊断:
- 使用调试器(如Java的JDB、Python的pdb等)挂起线程并查看当前堆栈,了解线程卡在哪里,为何没有跳出循环。
- 对于Java等语言,可以通过jstack命令获取线程的堆栈信息,分析线程是否在等待某个条件不满足而无法继续执行。
4. 异常处理与退出机制:
- 在循环内部适当地加入异常处理机制,当检测到可能导致死循环的异常情况时,能够主动抛出异常或者结束线程。
- 设计线程间的通信机制,如中断标识、信号量等,主线程或其他守护线程可在必要时强制停止死循环线程。
5. 测试与持续集成:
- 编写单元测试和集成测试,覆盖可能导致死循环的各种场景,确保在测试阶段就能发现问题。
- 在持续集成/持续部署(CI/CD)流程中,增加压力测试和长时间运行测试,模拟长时间运行下是否存在死循环的风险。
赞8 踩0 评论0 -
回答了问题
2024-04-10
如何写出更优雅的并行程序?
并行编程在实际场景中很常见,可以提高系统使用效率和运行性能,但是并行的点很容易发生“过载”的情况,导致系统崩溃。
常见的运用就是多线程。
在我工作的场景中,常有投标人解密、导入文件的环节,这个环节向来是耗时长占用资源大,所以使用线程池进行优化。但是客户提供的服务器性能可能比较差,有时候几千线程也能跑,有时一两百就崩溃。重要的是需要提前了解产品的性能指标,什么性能的服务器,开多少线程,对此进行限流。
当然还要考虑到数据库、网络等很多因素。赞36 踩0 评论0 -
回答了问题
2024-03-27
你的数据存储首选网盘还是NAS?
两者都是非常很好的方案,对于不同的场景选择适合的方案,才能发挥每种存储方式的最佳性能。
比如,对于资源需要多端同步的资源,且保密性不高,比如一些视频和文本,使用网盘就很合适,而且还能再网盘浏览,也很便捷。
而对于一些企业或者个人私密度高的资源,还是NAS比较符合要求,当然成本相较网盘也高出不少。
在实际使用者,两者都会考虑。赞4 踩0 评论0 -
回答了问题
2024-03-27
如何看待云原生数据库一体化的技术趋势?
一、在业务处理分析一体化的背景下,开发者如何平衡OLTP和OLAP数据库的技术需求与选型?
混合负载支持:选用能同时高效处理事务和分析查询的数据库技术,如支持HTAP(混合事务/分析处理)的数据库,这类数据库能够在一个平台上整合OLTP和OLAP的需求,减少数据迁移和同步的成本及复杂度。
架构灵活性:采用可水平扩展、支持分区、分片或行列混存的数据库架构,确保在保证事务处理性能的同时,也能快速响应复杂的分析查询。
数据一致性与实时性:对于需要实时分析的应用场景,确保数据库能够实现实时或近实时的数据更新同步到分析层,以便分析结果及时反映最新的业务状态。
资源隔离与优化:设计合理的资源分配策略,确保事务处理和分析处理之间不会互相抢占资源,可通过物理或逻辑上的隔离,以及针对不同类型操作的索引、缓存、预计算等方式进行优化。
成本与运维考量:评估云服务商提供的云原生一体化数据库服务,比如阿里云的PolarDB或AWS的Aurora等,这些服务提供了统一管理和运维,降低TCO(总体拥有成本),且能按需扩展,简化开发和运维工作。
二、集中式与分布式数据库的边界正在模糊,开发者如何看待这一变化?这种变化对数据库的设计和维护会带来哪些影响?
看待变化:应当积极拥抱分布式和云原生技术,认识到分布式数据库在扩展性、容错性和并发处理等方面的优势,同时也能够通过分布式的特性解决传统集中式数据库在处理海量数据和复杂查询时面临的瓶颈。
设计影响:在设计阶段要考虑到数据分片、分布式事务处理、分布式查询优化等挑战,同时也要利用分布式数据库带来的高可用性、数据冗余备份、地理分布等优点。
维护影响:维护工作则需要更加注重监控整个分布式系统的健康状况,包括网络延迟、数据一致性、节点故障转移等问题,同时也需要熟悉新的运维工具和自动化流程。
三、作为一名开发者,你会选择云原生一体化数据库吗?会在什么场景中使用呢?请结合实际需求谈一谈。
会选择。一下场景可供参考:
实时决策支持:当业务需要实时分析交易数据来驱动决策时,如电商网站实时分析销售趋势、金融风控领域实时监控异常交易等。
大数据量应用场景:在面对大量并发交易和复杂分析查询的场景,如电信行业的计费和用户行为分析、社交网络平台的内容推荐系统等。
敏捷开发与快速迭代:云原生一体化数据库能够快速部署、动态扩容,便于初创企业或项目初期快速验证业务假设和市场反馈,缩短产品上市周期。
成本敏感场景:对于中小企业或预算有限的项目,云原生数据库能够提供灵活的付费模式,无需高额的前期投入,可根据实际用量调整资源规模。
赞13 踩0 评论0 -
回答了问题
2024-03-27
人工智能大模型如何引领智能时代的革命?
一、人机交互革命:大模型如何提升我们与机器沟通的自然性和智能化程度?
自然语言理解与生成:大模型,如GPT系列、阿里云的通义千问等,通过深度学习和大规模预训练,极大地增强了对自然语言的理解能力,使得机器能够以接近人类的方式回应用户的请求、解答问题和执行指令。这种进步使得人机交流如同与真人交谈般流畅,消除了过去机械式的交互方式。
多模态交互:结合视觉、听觉等多种感官输入的大模型,允许用户通过语音、图像、视频等多种媒介与机器进行交互,提升了交互方式的多样性与直观性,例如通过语音识别和AI视觉技术,用户可以直接通过手势或者口头指令控制设备。
个性化和情境感知:大模型通过学习用户的交互历史和个人偏好,能够提供更为个性化的服务,同时还能根据上下文情境做出反应,从而更好地满足用户需求。
二、计算范式革命:大模型如何影响现有的计算模式,并推动新一代计算技术的演进?
分布式与并行计算:训练和运行大模型需要强大的计算资源和高效的分布式计算框架,促进了高性能计算集群的发展,也推动了新型硬件(如GPU、TPU)和云计算架构的进步。
数据驱动与自我迭代:大模型摒弃了传统的程序设计范式,转而依赖大数据训练,这种范式转变催生了自学习和持续优化的计算模式,使得机器可以自动从海量数据中学习和进化。
模型压缩与边缘计算:虽然原始大模型体积庞大,但随着技术发展,模型压缩技术日益成熟,使得大模型能够在有限资源的设备上部署,进而促进物联网和移动设备端的智能化交互。
三、认知协作革命:大模型将如何使人类和机器在认知任务上更紧密地协作?
知识助手与创造性辅助:大模型可以作为强大的知识引擎,协助人类进行复杂的研究分析、创新设计等工作,减轻重复劳动,提升创造力和决策效率。
协同学习与适应:通过与人的实时互动,大模型不仅可以提供信息和服务,还可以通过反馈不断调整自身的性能,形成有效的协同学习机制,共同完成复杂的认知任务。
突破人类局限:在一些超出人类认知负荷的任务中,如高速数据分析、大规模模拟预测等,大模型能够迅速提炼关键信息和洞察,与人类专家形成互补,共同解决原本难以攻克的问题。
赞10 踩0 评论0 -
回答了问题
2024-03-27
通义千问升级后免费开放 1000 万字长文档处理功能,将会带来哪些利好?你最期待哪些功能?
一、带来的利好
- 提高效率:专业人士可以利用这项功能快速处理大量文档,节省人力成本和时间,尤其在金融、法律、科研、医疗、教育等领域,能够高效地阅读、分析和整理海量信息,极大提升工作效率。
- 增强决策支持:通过智能摘要、关键信息提取等功能,帮助用户更快地理解和吸收长篇复杂文档的核心内容,辅助决策制定。
- 拓宽应用场景:长文档处理不仅限于单一领域,还可应用于跨学科研究、大数据分析、新闻报道整合、政策法规解读等多种场景,进一步拓宽了AI在各行各业的应用范围。
- 降低技术门槛:免费开放意味着更多用户可以接触并使用高级AI工具,无论是个人学习还是企业运营,都能更容易地享受到人工智能技术带来的便利。
二、未来值得期待的功能
- 更精细的文档结构化理解与重构
- 自动文献综述与关联研究发现
- 文档级别的问答系统,实现精准定位文档内答案
- 多语言文档处理能力的增强,支持全球化的信息处理需求
- 结合专业知识图谱提供深度知识推理服务
- 针对特定行业的定制化文档处理解决方案
赞4 踩0 评论0 -
回答了问题
2024-03-21
程序员为什么不能一次性写好,需要一直改Bug?
为何程序员在编写程序时难以一次性将所有代码完美无瑕地完成,而是需要经历反复修改Bug的过程呢?明明在设计之初已经尽力思考全面,实际操作中也力求精确,但为何仍需投入大量时间和精力在后期的调试与维护上?欢迎分享你的看法!
一、为什么需要反复修改bug?
- 需求理解偏差。从客户到产品经理,再到SE,再到开发,需求设计文档可能会存在偏差,需要在开发前的各个阶段做好沟通确认工作。
- 敏捷开发。现在很多企业使用敏捷开发方式,让客户全程参与进来,所以开发的产品也需要一个反复打磨的过程。
- 外部因素。硬件的升级、漏洞的发布、设置一些三方包的调整,都可能导致原来的代码出现问题,需要兼容调试。
- 性能。在开发时,开发人员很难带入实际运行场景,去考虑所有的情况,就会导致本地运行、测试运行皆顺畅,但是上线之后却问题不断。这里比较多的原因是编码没有考虑性能问题。
二、为什么还需要投入大量时间和精力在后期的调试和维护上?
首先,运维是系统生命周期中最长的环节。
从系统上线的那一刻起,对系统真正的挑战才刚刚开始。从此,你不得不及时响应各种问题,解决各种系统运行异常或用户操作一样;会遇到各种疑难问题,会在各种取舍间左右为难。
种种抉择到最终,就是我们要不要对系统进行改造。是优化代码,还是调整资源,亦或是增加组件,或者推到重来。
后期维护上,我们应当以系统稳定运行为前提,保证最少影响用户。所以外部的调整,如资源优化,中间件部署是常用的手段;如果确实发现代码漏洞或是优化点,那么必须经过详细的测试,更新重启应该发布系统升级说明等;当系统运行多年,已无法通过内外部优化调整,比如最常见的是业务需求无法满足,也有硬件升级、系统漏洞等,那就必须要对系统进行重构,重新规划设计开发,开启下一段生命周期。
而调试可以说是贯穿开发、运维阶段,准确的说,调试作为一种自测或发现问题的工具手段存在,本身已经是程序员的必须技能。
赞1 踩0 评论0 -
回答了问题
2024-03-20
你体验过让大模型自己写代码、跑代码吗?
一、你用体验过用通义千问自己写代码、跑代码吗?体验如何?
暂时还没有体验通义千问自己写代码跑代码,但是基于AI模型的能力,体验应该还可以。阅读文档后确实有几个疑问。
- 能够适配所有主流语言吗?
- 能否按照预期工作,还是需要反复提示?
二、目前大模型生成的代码可能会曲解开发者需求,遇到这种情况如何优化?
这是一个不可避免的情况。
人类还不能将所有语言环境搬到计算机中,但是我们可以通过反复提示,或者使用一种更贴合计算机理解的方式描述需求。赞5 踩0 评论0 -
回答了问题
2024-03-14
人工智能带来新机遇,国产服务器操作系统如何加快发展?
一、云智融合浪潮下,您认为服务器操作系统产业未来发展将走向何方?
服务器操作系统未来应该更加稳定和健壮,就是房屋的地基,作为所有软件的底座,应该要具备更好的扩展性,能够应对可预知的变化。
二、您认为英特尔和龙蜥的合作,能为国产操作系统的发展带来什么?双方如何通过合作布局“ 云+AI”时代的未来?
英特尔作为芯片行业的翘楚,一直依赖引领者行业的潮流。如果能够深入合作,国产操作系统将能够更加深入到芯片底层,发挥处理器的全部性能,而且为国产操作系统定制也不是不可能的。
三、Alibaba Cloud Linux 是阿里云打造的 Linux 服务器操作系统发行版,是阿里云上最佳操作系统,它具有哪些特性和优势?(提示:点击 Alibaba Cloud Linux 找参考资料)
Alibaba Cloud Linux是阿里云推出的一款基于CentOS的定制化Linux发行版,具有以下特性和优势:
安全性强:Alibaba Cloud Linux提供了安全增强功能,包括安全内核、SELinux、堆栈保护等,有助于保护系统免受恶意攻击。
高性能:Alibaba Cloud Linux针对阿里云云计算环境进行了优化,提供了更高的性能和稳定性,适用于处理大规模的工作负载。
易于管理:Alibaba Cloud Linux集成了阿里云的管理工具和服务,使用户可以更轻松地管理和监控其云服务器实例。
兼容性强:作为基于CentOS的发行版,Alibaba Cloud Linux与CentOS兼容,可以无缝迁移现有的CentOS应用程序和工作负载。
持续更新:Alibaba Cloud Linux会定期发布更新和补丁,以确保系统的安全性和稳定性,同时提供最新的功能和性能优化。
总的来说,Alibaba Cloud Linux具有安全性强、高性能、易于管理、兼容性强和持续更新等优势,适合在阿里云云计算环境中部署和运行各种应用程序和服务。
四、您认为英特尔与Alinux 的合作哪些方面最值得期待?您最希望龙蜥和英特尔带来哪些方面的惊喜?
合作后的alinux能够更加发挥芯片的性能,可能选择处理器和系统时需要更多考量,最期待的还是性能提升。
赞13 踩0 评论0 -
回答了问题
2024-03-12
让 AI 写代码,能做出什么样的项目?
1.晒一晒你开出了什么奖品,上传开盲盒奖品截图
2.用AI写代码是什么样的体验,分享一下你使用通义灵码的感受
首先,将通义千问集成到了IDE中,方便开发中查询,免去了切换;
其次,提供了代码补全、评审、测试等增强功能,帮助开发者提高效率。
使用下来的整体感受很好。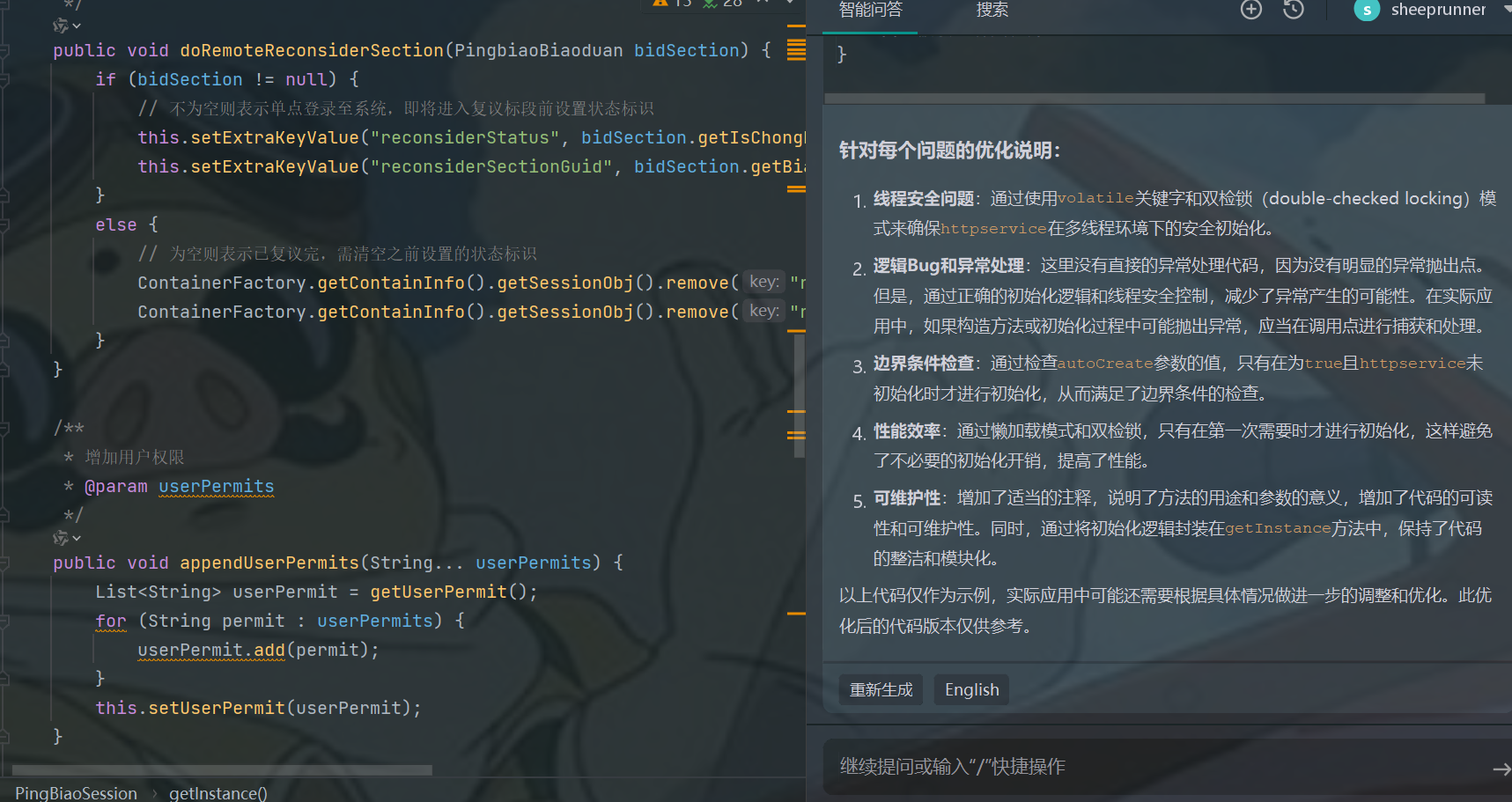 赞1 踩0 评论0
赞1 踩0 评论0 -
回答了问题
2024-03-09
开发者,你在云上建设过怎样的世界?
一、本次活动提供的五大场景中你最感兴趣的是哪个,为什么?
最感兴趣的是个人云笔记的搭建。
因为自己也一直再用云笔记产品,从有道云笔记、腾讯文档,到印象笔记、石墨,然后又到语雀,目前锁定了有道云笔记和语雀两款产品。但是在使用过程中多少感觉有点可以更加适配个人操作的个性化点,而产品本身又不会因为我的需求适配。二、你曾经在云上搭建过哪些应用,这些应用为你带来了怎样的价值?
目前主要使用时项目线上环境使用的oss存储,对于云上搭建应用还没有正式运用。
通过多次的试用情况来看,云上搭建应用的安全性、稳定性和可靠性能够达到要求,等到预算到位可以讨论部分应用迁移的方案。三、在使用云服务时,你遇到过哪些挑战,又是如何克服这些挑战的?
主要还是一开始接触时的不熟悉,以及后续使用过程中新功能的适应。
这个过程中有大量的文档要看,学习成本不低,对资源及成本需要充分考虑。赞9 踩0 评论0 -
回答了问题
2024-03-07
你使用过代码生成工具吗?
1、在日常工作中,你会用到代码生成工具吗?最喜欢哪一种呢?
会使用。如今使用代码生成工具似乎不可避免。
最喜欢sider和通义灵码。- sider插件:浏览器上安装,因为日常使用OA平台,打开侧边栏就能使用,非常方便。基于ChatGPT 3.5的代码生成也比较准确便捷;
- 通义灵码:日常开发使用IDEA,加上灵码插件,效率杠杠滴,有时候也会基于网页的通义千问进行代码优化,评审,使用上来说跟GPT类似,都挺方便。
2、你一般使用代码生成工具来做什么?
- 框架搭建:比如“使用spring技术生成一个Javaweb登录框架,生成具体代码”;
- 代码优化:一些语法和性能调优;
- 设计方案:输入需求,给出实现方案。
3、面对尚处于“成长期”的代码生成工具,你有哪些期待和诉求呢?
- 目前来看日常的工作基本够用;
- 如果说还有什么期待,是能够出现增加适应具体行业或业务的代码生成工具,可能对具体细分领域的开发帮助会比较大;
- 最终是否能达到输入需求直接生成所有代码,并自动提交测试、上线?(没程序员啥事了
哈哈哈哈)
以下是一个简单的基于Spring Boot和Spring Security的Java Web登录框架的代码示例:
创建Spring Boot项目:
- 使用Spring Initializr创建一个Spring Boot项目,并添加
spring-boot-starter-web和spring-boot-starter-security依赖。
- 使用Spring Initializr创建一个Spring Boot项目,并添加
创建Spring Security配置类:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity; import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter; @Configuration @EnableWebSecurity public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/login", "/css/**").permitAll() .anyRequest().authenticated() .and() .formLogin() .loginPage("/login") .permitAll() .and() .logout() .permitAll(); } }创建登录页面:
- 在
src/main/resources/templates目录下创建login.html文件:<!DOCTYPE html> <html lang="en" xmlns:th="http://www.thymeleaf.org"> <head> <meta charset="UTF-8"> <title>Login</title> </head> <body> <h2>Login</h2> <form th:action="@{/login}" method="post"> <label for="username">Username:</label> <input type="text" id="username" name="username"><br> <label for="password">Password:</label> <input type="password" id="password" name="password"><br> <button type="submit">Login</button> </form> </body> </html>
- 在
创建Controller处理登录请求:
import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.GetMapping; @Controller public class LoginController { @GetMapping("/login") public String login() { return "login"; } }创建简单的用户实体类:
import lombok.Data; @Data public class User { private String username; private String password; }测试登录功能:
- 启动应用程序,访问
http://localhost:8080/login可以看到登录页面。 - 输入用户名和密码进行登录测试,验证登录功能是否正常工作。
- 启动应用程序,访问
这是一个简单的示例,你可以根据实际需求进行定制和扩展,例如添加数据库支持、用户权限管理等功能。
赞31 踩0 评论0 -
回答了问题
2024-02-28
Agent一路狂飙,未来在哪?
1、如何看待Agent的“成本效益比”?
- 在企业中,可能使用自动化工具(即Agent)来处理日常业务流程。
- Agent的成本包括了购买和维护自动化系统的费用、能源消耗、升级成本等;
- 效益则可能是通过提高工作效率、减少人工错误、降低人力成本等方式实现的经济效益。
- 计算并把控这个成本效益比可以帮助公司评估是否值得投资这项技术,并确定其长期运营的合理性。
- 不同的行业和应用场景,计算成本效益比的方式可能不同,但是成本效益比无疑是一个很好的指标。
2、你对未来Agent的发展趋势有哪些见解和期待?
多模态智能集成:随着AI技术的进步,未来的Agent将更加强调多模态输入输出能力,能够理解并整合文本、语音、图像等多种数据形式。这种跨模态的交互将使Agent更加智能化和人性化,能够更好地适应复杂的人机交互场景。
具身智能与环境感知:AIAgent将发展出更强的环境感知能力和行动能力,成为具身智能体,不仅在虚拟空间中执行任务,还能在现实世界中通过机器人或物联网设备实现物理操作,进一步模糊数字世界和物理世界的边界。
深度学习与强化学习结合:Agent会越来越多地利用深度学习进行模式识别和预测,并结合强化学习自我优化行为策略,在无监督或半监督情况下不断学习和进步,以应对复杂动态环境中的挑战。
自主决策与协同工作:随着分布式计算和群体智能技术的发展,多个AI Agent之间将能高效协作,共同解决复杂问题,同时,Agent将具备更高的自主决策能力,能够在限定范围内根据上下文自主制定并执行计划。
伦理约束与价值对齐:鉴于AI伦理的重要性日益凸显,未来的Agent开发将更注重融入道德规范和法律约束,确保其决策过程符合人类社会的价值观,实现人机和谐共生。
行业应用深化:Agent将在医疗、教育、制造、金融等更多行业中发挥关键作用,通过自动化和智能化的方式降低成本、提高效率,甚至引领新的业务模式和产业变革。
安全性与隐私保护:设计者需关注Agent的安全性和隐私保护机制,确保在提供服务的同时,用户的数据安全得到保障,且Agent不会被滥用或误用,造成不良后果。
3、从一个先进工具走向行业专家,你认为Agent面临的关键瓶颈是什么?
领域知识的深度学习与理解:
- Agent虽然可以通过大量数据训练和深度学习来模拟人类行为并解决一些复杂问题,但要达到行业专家水平,需要对特定领域的专业知识有深入理解和运用能力。目前,AI系统在处理抽象、非结构化的复杂知识时仍然存在困难。
自主性与创造性决策:
- 行业专家通常具备根据情境做出创新或独特判断的能力,而当前Agent在面对未曾遇到的问题时,往往依赖于预设的规则和模型,缺乏真正的原创性和灵活性。
情景感知与情感智能:
- 人类专家能够通过察言观色、体悟情境等手段进行沟通交流,而Agent尚无法完全模拟这种高度的情境感知能力和情绪识别能力,这在很多需要高情商的行业领域尤为关键。
伦理道德及法规约束:
- 成为行业专家意味着不仅要解决问题,还需要遵循严格的道德规范和法律法规。目前AI Agent在处理涉及伦理、隐私和安全等方面的决策时,很难自动适应不断变化的社会规范和法律要求。
持续学习与自我更新机制:
- 真正的行业专家能够通过终身学习不断完善自己的知识体系。尽管现代Agent具有一定的在线学习能力,但在快速吸收新知识、整合新信息以及迭代自身策略方面的效率和效果仍有待提高。
可解释性与透明度:
- AI Agent的决策过程应具有足够的透明度,以便人们了解其工作原理和逻辑,这对于许多行业来说是至关重要的。然而,目前很多高级AI系统的黑箱特性限制了它们作为“可信专家”的接受程度。
跨领域协同与集成:
- 实际业务场景中,行业专家往往需要跨界协作,并能将不同领域的知识融会贯通。对于Agent而言,如何实现跨学科、跨领域的知识融合和综合应用也是一个重要挑战。
赞2 踩0 评论0 -
回答了问题
2024-02-28
如何看待阿里云PolarDB登顶2024最新一期中国数据库流行榜?
1、数据库流行度排行榜会影响你的数据库选型吗?
不会。
目前更多的还是选择习惯的,或者工作中需要用到的,抛开上述两点应该会选择容易获取和学习的。
但是不可否认的是,排行榜从一定程度上也决定了排名靠前的应该是常用的、容易获取和有丰富教程和社群的数据库。2、对于 PolarDB 的本次登顶,你认为关键因素是什么?
云原生设计与技术创新:PolarDB作为云原生数据库,采用存储计算分离、软硬一体化等创新架构设计,提供了弹性扩展、高可用性以及低成本运维的优势,满足了企业快速变化的业务需求和对云计算资源高效利用的要求。
性能优化与规模优势:PolarDB在处理海量数据和高并发请求场景下表现卓越,通过高效的分布式架构和先进的并行处理技术,能够在保证事务一致性和数据安全性的同时,提供线性可扩展的高性能服务。
市场占有率与客户认可:随着越来越多的企业选择上云和数字化转型,PolarDB凭借其稳定可靠的服务和行业解决方案,在多个行业中获得了广泛的部署和应用,积累了大量的成功案例和客户基础,提升了品牌影响力和市场份额。
持续研发投入与迭代升级:阿里云对PolarDB进行了持续的技术研发和产品迭代,不断推出适应市场需求的新功能和服务,保持产品的竞争力和领先地位。
生态建设与合作推广:构建起丰富的合作伙伴生态系统,整合产业链上下游资源,共同推动云数据库解决方案在各行业的普及和落地。
政策支持与国产化趋势:国家层面对于信息技术自主创新的支持,以及国内企业对于自主可控数据库产品的需求增长,为PolarDB这样的国产数据库产品提供了良好的发展环境和市场机遇。
3、PolarDB“三层分离”新版本发布,对于开发者使用数据库有何影响?
阿里云自研的云原生数据库PolarDB发布“三层分离”新版本,对开发者使用数据库有以下几个方面的显著影响:
架构简化与资源管理优化:
- “三层分离”设计意味着数据库系统在逻辑层、计算层和存储层实现了独立可扩展。这种架构使得开发者可以更灵活地管理和分配计算与存储资源,根据业务需求进行独立扩展或收缩,从而降低运维复杂度和成本。
性能提升与成本节省:
- 通过技术革新,如智能决策系统的接入和IO性能的10倍提升,开发者能够利用更高的处理能力和更低延迟的数据读写操作来构建高性能应用,同时,由于资源利用率的提高,整体上能实现高达50%的成本节省。
敏捷开发与快速迭代:
- 阿里云PolarDB新版本提供的易用性改进,让数据库的搭建和使用变得更加简单,类似于“搭积木”,这有助于开发者更快地部署和调整数据库配置,支持敏捷开发和快速迭代的需求。
智能体验与场景化服务:
- 新版本还引入了大语言模型等智能化组件,提升了数据库的智能决策水平,这可能意味着开发者在面对复杂查询优化、故障诊断、容量规划等问题时,能得到更为智能的支持和建议。
社区与开源生态:
- 如果PolarDB已正式开源,那么开发者不仅可以享受到开源软件带来的透明性和灵活性,还能参与到社区中贡献代码、获取技术支持以及与其他开发者共同成长。
赞4 踩0 评论0 -
回答了问题
2024-02-28
开动脑洞,你最想用Sora生成什么样的视频?
一、Sora会给那些行业带来显著变化
- 影视行业:
- 通过文本到视频(Text-to-Video)技术,Sora极大地简化了视频制作流程,降低了门槛和成本。
- 可以根据简单的文字提示生成内容丰富、画面逼真的视频,包括分镜、切换景别等复杂工作,改变了传统影视制作的精细分工模式。
- 预计将重塑影视行业的生产方式,使得小规模创作者和工作室能够更快捷地创作高质量视频内容。
- 市场营销与广告行业:
- Sora提升了广告相关视频的创意效率,可以根据品牌需求快速生成符合品牌形象的广告视频,减少拍摄和后期制作的成本。
- 提供灵感来源,可以部分替代低创造性、可复制的视频内容,并能低成本定制大量个性化视频内容,提高客户转化率及留存率。
- 游戏与动画行业:
- Sora对物理世界的理解和模拟能力有助于游戏场景开发,可以用来创建角色动画、背景故事等,降低3D模型和动画制作的成本。
- 可能会推动游戏内动态事件生成和剧情自动生成技术的发展,提升游戏内容的多样性和创新性。
- 短视频行业:
- 简化短视频创作过程,创作者可以直接通过文字输入实现视频内容转换,激发更多个性化和创新内容的产生。
- 销售行业:
- AI技术如Sora的应用可能会影响展会活动的内容创造和展示形式,通过自动化的视觉内容生成,为销售行业带来新的营销和展示手段。
二、我希望使用sora制作的内容
我特别喜欢科幻和武侠,如果能要改过我想生成的视频的描述如下:未来世界的科技武侠风格,既有侠骨柔情,又有科学幻想,东方美学和钛合金科技融合,竹林与光速飞船的辉映。
三、生成式AI目前还存在待解决的关键问题
技术层面的关键问题:
- 准确性与可靠性:尽管生成式AI在内容创作方面表现出色,但仍然存在提供不准确信息的风险,包括事实性错误、逻辑矛盾等。
- 可控性与可解释性:如何确保模型的输出符合预期且能够追溯其生成过程和决策依据,提高算法透明度。
- 偏见与歧视:AI模型可能吸收训练数据中的社会偏见,并反映在生成的内容中,导致不公平或有偏见的信息传播。
- 安全与隐私保护:大模型可能无意间泄露训练数据中的敏感信息,同时在处理用户请求时也需要保障用户隐私不受侵犯。
- 版权与知识产权:生成的内容可能涉及未经授权的复制他人作品,需要解决版权归属和原创性的问题。
伦理道德层面的问题:
- 责任归属:当AI生成内容引发不良后果时,如何确定法律责任,是开发者、使用者还是模型本身负责?
- 人类价值与道德规范:AI系统能否理解和遵循人类社会的道德准则,在生成内容时不违背伦理底线。
- 社会影响:生成式AI对新闻媒体、教育、艺术等领域的影响可能导致传统职业受到冲击,需要权衡技术进步与社会稳定的关系。
- 虚假信息与欺骗行为:AI可以轻易生成逼真的文本、图像乃至视频,这为制造假新闻、欺诈活动提供了新的手段,如何防止恶意利用成为重要议题。
- 法律法规:目前尚无适用于AI的完善法律,可能有许多漏洞亟待解决。
赞2 踩0 评论0 - 影视行业:
-
回答了问题
2024-02-28
你会在Vision Pro里编程吗?
一、作为一位开发者,你会考虑将Vision Pro应用到编程中吗?你对此持有怎样的看法呢?
首先,作为一名开发者,非常希望能够体验这款新产品,当然会考虑将其应用到编程开发中。
当下国内体验门店非常少,所以大众的热情期待非常高。试想一下,脱离了沉闷刻板的办公桌和显示器,办公空间理论上可以无限放大,并且对于增强混合现实的期待,都赋予了这款产品极高的期望度。
但是就目前来看,也不是没有问题的,以下是部分了解及看了体验者反馈后的解读,如有误解还请见谅:- 在介绍视频中,visionpro的办公环境展示最多的是图片、视频、网页,并没有展示多少交互上的优势,并且也有体验者反馈交互并不便捷,虚拟键盘和手势操作感觉也不是很稳定,对于开发这种需要很多交互的场景真的好吗?
- 在舒适度上,个人对头戴式二级都比较排斥,英语听力基本靠蒙,虽然vision pro已经努力做到轻便与舒适,但是对于我这样不喜欢束缚的人,可能还是不能长时间佩戴,更不用说进行需要几种注意力的编程工作。
- 在使用场景上,虽然Vision Pro做了对现实的增强,但是在办公环境下,可能还是在开会和设计等层面,更不用说其价格也不太亲民。
4.在生态上,目前Vision pro的生态并不完备,Apple后期对其的规划会走向哪里,人们对其的期望和满意度是否匹配也还未可知,或许最终他还是会沉淀到娱乐和游戏领域。
编程需要的可能更多的是想法和灵感,而Vision Pro 无疑会给开发者带来很多新东西,我们渴望改变沉闷,但是从给中角度看,Vision Pro都不会短期内进入大众编程的范畴。
二、你认为Vision Pro有可能改变开发者的工作模式与效率吗?欢迎分享~
正如第一部分所述,作为开发者,Vision Pro在编程领域的实用性我并不乐观,我担心他最终会慢慢走娱乐向(就如同斯皮尔伯格的《头号玩家》)。
虽然我期待它来改变开发者的工作模式,提高开发者的工作效率,但是相比之下,我其实也更想体验使用Vision Pro在观影和游戏上的体验,而不是工作。赞2 踩0 评论0
滑动查看更多
暂无更多信息