
必嘫

已加入开发者社区1829天
勋章

星级博主
星级博主

阿里博主
阿里博主

开发者认证勋章
开发者认证勋章

初入江湖
初入江湖



我关注的人









粉丝






阿里云技术专家,在应用性能监控和软件交付方面有丰富的实践经验,目前专注于容器服务,微服务以及机器学习等领域。
暂无精选文章
暂无更多信息
2024年05月
-
04.02 15:34:39
 发表了文章
2024-04-02 15:34:39
发表了文章
2024-04-02 15:34:39
Fluid 携手 Vineyard,打造 Kubernetes 上的高效中间数据管理
本文阐述了如何利用 Fluid 和 Vineyard 在 Kubernetes 上优化中间数据管理,解决开发效率、成本和性能问题。 Fluid 提供数据集编排,使数据科学家能用 Python 构建云原生工作流,而 Vineyard 通过内存映射实现零拷贝数据共享,提高效率。两者结合,通过数据亲和性调度减少网络开销,提升端到端性能。 同时通过一个真实事例介绍了安装 Fluid、配置数据与任务调度及使用 Vineyard 运行线性回归模型的步骤,展示了在 Kubernetes 上实现高效数据管理的实践方法。未来,项目将扩展至 AIGC 模型加速和 Serverless 场景。
2023年12月
-
11.23 18:48:06发表了文章
2023-11-23 18:48:06
Fluid支持分层数据缓存本地性调度(Tiered Locality Scheduling)
依赖容器化带来的高效部署、敏捷迭代,以及云计算在资源成本和弹性扩展方面的天然优势,以 Kubernetes 为代表的云原生编排框架吸引着越来越多的 AI 与大数据应用在其上部署和运行。但是数据密集型应用计算框架的设计理念和云原生灵活的应用编排的分歧,导致了数据访问和计算瓶颈。 CNCF开源项目Fluid作为 AI 与大数据云原生应用提供一层高效便捷的数据抽象,将数据从存储抽象出来,针对具体的场景(比如大模型),加速计算访问数据。
2022年12月
-
12.20 15:00:58发表了文章
2022-12-20 15:00:58
Fluid支持子数据集
当然随着Fluid使用的深入,也有不同的需求出现。其中社区一个比较共性的需求: 1. 可以跨namespace访问数据集缓存 2. 只允许用户访问数据集的某个子目录 特别是JuiceFS的用户,他们倾向于使用Dataset指向JuiceFS的根目录。然后对于不同数据科学家组分配不同的子目录作为不同的数据集,并且希望彼此间的数据集不可见;同时还支持子数据集的权限收紧,比如根数据集支持读写,子数据集可以收紧为只读。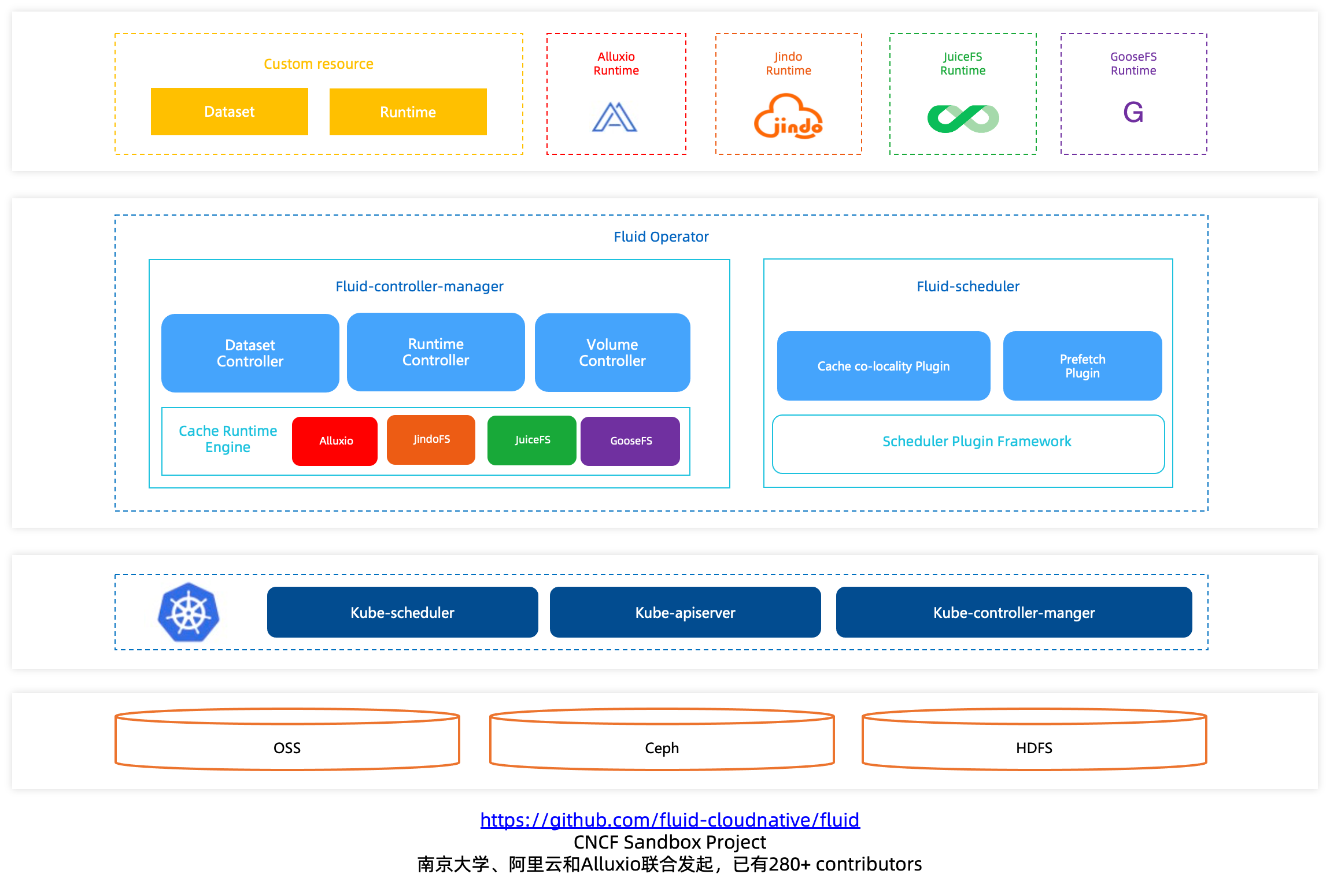
-
12.08 11:38:06发表了文章
2022-12-08 11:38:06
Fluid新魔法:跨Kubernetes Namespace共享数据集
Fluid帮助数据科学家优化数据访问。不同的数据科学家团队会在多个不同的Namespace中创建数据密集型作业,且这些作业将访问相同的数据集。多个数据科学家复用相同的数据集,特别是开源数据集。各数据科学家拥有自己独立的Namespace提交作业。如果对于每个Namespace运行缓存运行时并进行缓存预热,会造成缓存资源浪费和作业启动延迟问题。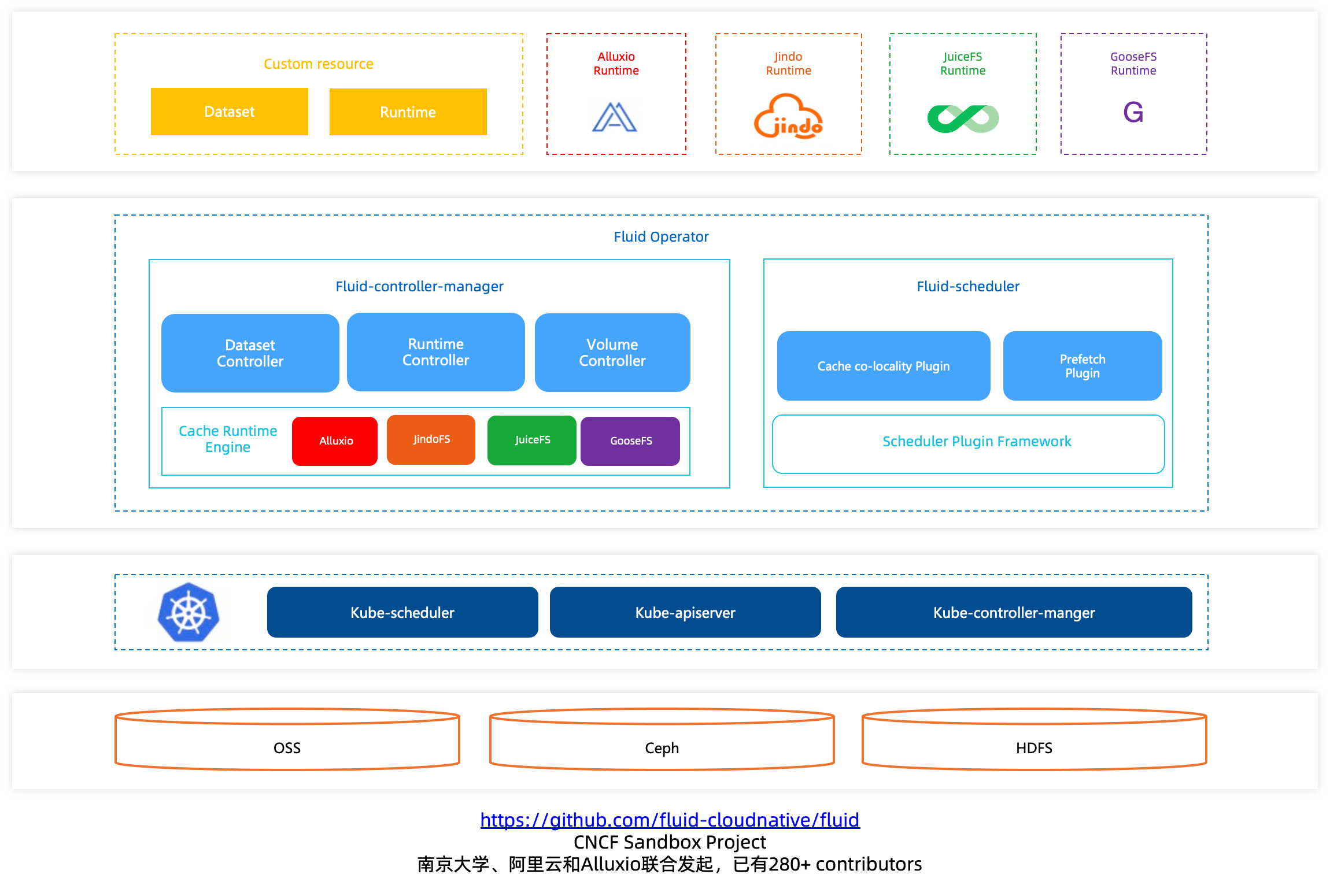
2021年04月
-
04.24 15:09:14发表了文章
2021-04-24 15:09:14
Fluid给数据弹性一双隐形的翅膀 (2) -- 定时弹性伸缩
Fluid提供了数据缓存的弹性伸缩能力, 甚至可将缓存能力缩减为0。而且动态调整缓存容量变得非常简单,只需要Runtime的就可以完成数据缓存的扩缩容。与开源社区的kubernetes-cronhpa-controller可以很好的解决拥有周期性资源画像的负载弹性问题,平衡资源的使用效率和避免弹性的滞后问题。
-
04.09 23:20:35发表了文章
2021-04-09 23:20:35
Fluid给数据弹性一双隐形的翅膀 (1) -- 自定义弹性伸缩
弹性伸缩作为Kubernetes的核心能力之一,但它一直是围绕这无状态的应用负载展开。而Fluid提供了分布式缓存的弹性伸缩能力,可以灵活扩充和收缩数据缓存。 它基于Runtime提供了缓存空间、现有缓存比例等性能指标, 结合自身对于Runtime资源的扩缩容能力,提供数据缓存按需伸缩能力。
2020年10月
-
10.19 19:42:26发表了文章
2020-10-19 19:42:26
Fluid 0.3 新版本正式发布:实现云原生场景通用化数据加速
为了解决大数据、AI 等数据密集型应用在云原生计算存储分离场景下,存在的数据**访问延时高、联合分析难、多维管理杂**等痛点问题,南京大学 PASALab、阿里巴巴、Alluxio 在 2020 年?9 月份联合发起了开源项目 Fluid。近期我们更新了0.3版本
-
10.13 11:07:19发表了文章
2020-10-13 11:07:19
Fluid: 让大数据和 AI 拥抱云原生的一块重要拼图
得益于容器化带来的高效部署、敏捷迭代,以及云计算在资源成本和弹性扩展方面的天然优势,以 Kubernetes 为代表的云原生编排框架吸引着越来越多的 AI 与大数据应用在其上部署和运行。然而,云原生计算基金会(CNCF)全景图中一直缺失一款原生组件,以帮助这些数据密集型应用在云原生场景下高效、安全、便捷地访问数据。
-
10.04 16:41:53发表了文章
2020-10-04 16:41:53
Fluid: 让大数据和 AI 拥抱云原生的一块重要拼图
得益于容器化带来的高效部署、敏捷迭代,以及云计算在资源成本和弹性扩展方面的天然优势,以 Kubernetes 为代表的云原生编排框架吸引着越来越多的 AI 与大数据应用在其上部署和运行。然而,云原生计算基金会(CNCF)全景图中一直缺失一款原生组件,以帮助这些数据密集型应用在云原生场景下高效、安全、便捷地访问数据。
-
发表了文章
2024-05-15
Fluid 携手 Vineyard,打造 Kubernetes 上的高效中间数据管理
-
发表了文章
2023-12-01
Fluid支持分层数据缓存本地性调度(Tiered Locality Scheduling)
-
发表了文章
2022-12-20
Fluid支持子数据集
-
发表了文章
2022-12-19
Fluid新魔法:跨namespace共享数据
-
发表了文章
2022-12-19
Fluid支持子数据集
-
发表了文章
2022-12-08
Fluid新魔法:跨Kubernetes Namespace共享数据集
-
发表了文章
2021-04-24
Fluid给数据弹性一双隐形的翅膀 (2) -- 定时弹性伸缩
-
发表了文章
2021-04-09
Fluid给数据弹性一双隐形的翅膀 (1) -- 自定义弹性伸缩
-
发表了文章
2020-10-19
Fluid 0.3 新版本正式发布:实现云原生场景通用化数据加速
-
发表了文章
2020-10-13
Fluid: 让大数据和 AI 拥抱云原生的一块重要拼图
-
发表了文章
2020-10-04
Fluid: 让大数据和 AI 拥抱云原生的一块重要拼图
-
发表了文章
2020-04-30
从监控到隔离,阿里云容器服务提升您的GPU资源使用体验
-
发表了文章
2020-04-24
Alluxio深度学习实战-1:体验在HDFS上运行PyTorch框架
-
发表了文章
2020-04-15
阿里云容器服务团队实践——Alluxio优化数倍提升云上Kubernetes深度学习训练性能
-
发表了文章
2020-04-08
体验托管Prometheus监控阿里云容器服务Kubernetes的GPU资源
-
发表了文章
2019-12-02
妙到毫巅,在阿里云容器服务中体验RAPIDS加速数据科学
-
发表了文章
2019-05-17
像Google一样构建机器学习系统3 - 利用MPIJob运行ResNet101
-
发表了文章
2019-04-28
像Google一样构建机器学习系统2 - 开发你的机器学习工作流
-
发表了文章
2019-04-26
像Google一样构建机器学习系统 - 在阿里云上搭建Kubeflow Pipelines
-
发表了文章
2019-02-18
开源工具GPU Sharing:支持Kubernetes集群细粒度
滑动查看更多
暂无更多信息
暂无更多信息