
-

2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
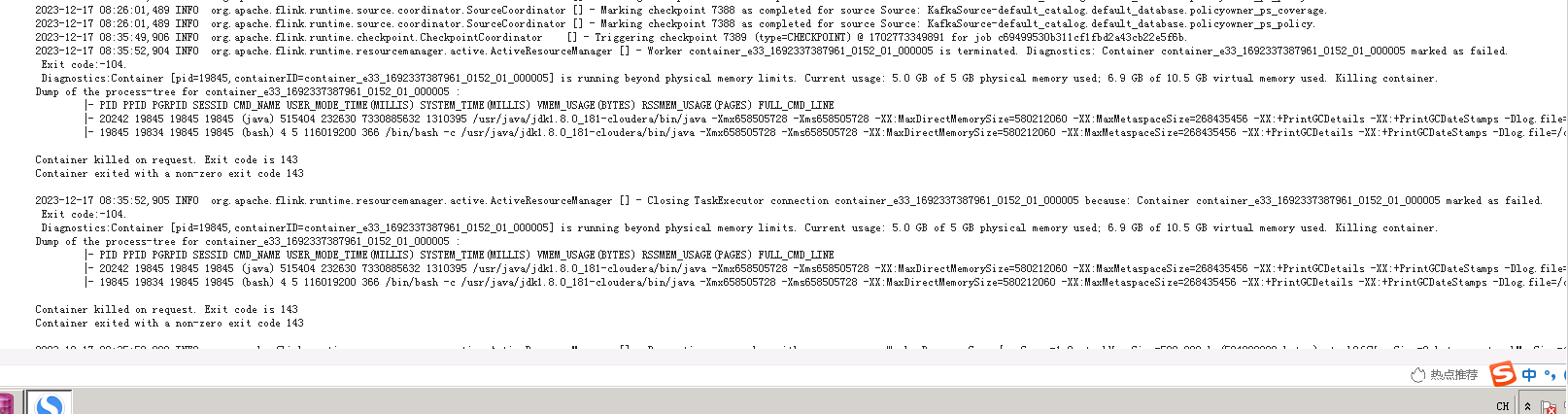
这个错误提示表示你的 Flink 任务使用的内存超过了物理内存的限制。具体来说,你的容器使用了 5.0GB 的物理内存,但是只分配了 5GB 的物理内存。此外,你还使用了 6.9GB 的虚拟内存,总共使用了 10.5GB 的内存。
解决这个问题的方法有两个:
增加你的 Flink 任务的内存限制。你可以通过修改 Flink 的配置文件来增加每个 taskmanager 的 heap memory 和 network memory 的限制。但是请注意,这可能会增加你的 Flink 任务的资源消耗,可能会导致其他问题。
优化你的 Flink 任务。你可以检查你的 Flink 任务的代码,看看是否有任何不必要的内存使用,或者是否可以优化你的数据处理逻辑来减少内存的使用。
另外,你的 Flink 任务还出现了 "Container exited with a non-zero exit code 143" 的错误。这个错误通常表示你的 Flink 任务因为某种原因被 kill 掉了。这可能是因为你的 Flink 任务使用了过多的资源,或者是因为你的 Flink 任务遇到了无法处理的异常。你可以查看你的 Flink 任务的日志,看看是否有任何异常的输出,以确定具体的原因。
2024-01-05 15:12:35赞同 展开评论 打赏 -
 面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
根据您提供的错误消息,看起来Flink作业由于容器超出了物理内存限制而失败。这可能是由于以下几个原因之一导致的:
- 数据倾斜:如果某个分区的数据分布非常不平衡,那么它将会消耗大量的内存空间。这种现象被称为“数据倾斜”,并且会影响整个集群的工作效率。解决方法通常是设计合理的数据划分规则以及实现自适应的聚合操作,以便更好地平衡各个分区之间的数据大小差异。
- 大对象频繁创建/删除:如果程序中有大型的对象被频繁创建和销毁,那么这也将显著影响内存利用率。为避免这类问题,尽量减小对象尺寸,合理组织数据结构,尽可能复用已存在的对象而不是经常创建新对象。
- 磁盘IO密集型任务:如果作业依赖于大量的磁盘I/O操作,那么这将降低整体性能并增大内存负担。为了改善这种情况,您可以尝试优化读取路径,缓存热点数据,甚至采用分布式文件系统(如HDFS),从而减轻单台机器的压力。
- 网络延迟:在网络环境中,长距离传输数据会产生额外的时间开销,尤其是在大数据场景下尤为明显。确保网络环境稳定,适当配置心跳包频率,以及优化数据压缩方式都是有助于提升网络性能的有效手段。
此外,还可以采取以下步骤来进一步定位问题所在:
- 监视集群资源使用状况:检查集群上其他节点是否有类似的资源使用过高问题,如果有则可能存在全局性的资源竞争问题。
- 深入理解业务逻辑:深入了解源码级别的业务流程,找出是否存在特别消耗资源的操作序列,针对性地对其进行优化。
- 扩展集群规模:如果以上两种方法都无法解决问题,可以考虑扩大集群规模,提供更多可用的资源给Flink作业使用。
2024-01-04 16:16:30赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
热门讨论
热门文章
相关课程
更多

相关电子书
更多


