2000元阿里云代金券免费领取,2核4G云服务器仅664元/3年,新老用户都有优惠,立即抢购>>>
阿里云采购季(云主机223元/3年)活动入口:请点击进入>>>,
阿里云学生服务器(9.5元/月)购买入口:请点击进入>>>,
长求总:
-
-
异步提交
-
增加并发,经验值当活跃的进程数等于核数的2倍时可以发挥CPU的最大能力
-
批次提交
-
关闭pg_log
-
-
使用函数封装业务逻辑
-
COPY
-
拆表
-
hotstandby读写分离
-
分区表(主表并发有性能问题)PG11后可用或者使用PGPATHMAN -
连接池:短连接大量并发场景
title: Postgresql优化案例 date: 2019-04-16 15:59:00 categories: Postgresql
PGSQL优化案例
硬件
CPU: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz - 64cores
SSD: INTEL SSDSCKHB34
HDD: ST8000NM0055-1RM
MEM: 516754MB
软件
postgres10.1
pgbench
全部使用域套接字连接,避免网络影响
基准测试[0]
测试模型
数据库默认参数模版
create database etest;
\c etest
?
CREATE TABLE user_info (userid int, engname text, cnname text, occupation text, birthday date, signname text, email text, qq numeric, crt_time TIMESTAMP WITHOUT time ZONE, mod_time TIMESTAMP WITHOUT time ZONE);
?
CREATE TABLE user_session (userid int, logintime TIMESTAMP(0) WITHOUT time ZONE, login_count bigint DEFAULT 0, logouttime TIMESTAMP(0) WITHOUT time ZONE, online_interval interval DEFAULT interval '0');
?
CREATE TABLE user_login_rec (userid int, login_time TIMESTAMP WITHOUT time ZONE, ip inet);
?
CREATE TABLE user_logout_rec (userid int, logout_time TIMESTAMP WITHOUT time ZONE, ip inet);
初始化数据
insert into user_info (userid,engname,cnname,occupation,birthday,signname,email,qq,crt_time,mod_time)
select generate_series(1,20000000), 'digoal.zhou', '德哥', 'DBA', '1970-01-01' ,E'公益是一辈子的事, I\'m Digoal.Zhou, Just do it!', 'digoal@126.com', 276732431, clock_timestamp(), NULL;
insert into user_session (userid) select generate_series(1,20000000);
set work_mem='2048MB';
set maintenance_work_mem='2048MB';
alter table user_info add constraint pk_user_info primary key (userid);
alter table user_session add constraint pk_user_session primary key (userid);
模拟业务场景登陆、登出
create or replace function f_user_login
(i_userid int,
OUT o_userid int,
OUT o_engname text,
OUT o_cnname text,
OUT o_occupation text,
OUT o_birthday date,
OUT o_signname text,
OUT o_email text,
OUT o_qq numeric
)
as $BODY$
declare
begin
select userid,engname,cnname,occupation,birthday,signname,email,qq
into o_userid,o_engname,o_cnname,o_occupation,o_birthday,o_signname,o_email,o_qq
from user_info where userid=i_userid;
insert into user_login_rec (userid,login_time,ip) values (i_userid,now(),inet_client_addr());
update user_session set logintime=now(),login_count=login_count+1 where userid=i_userid;
return;
end;
$BODY$
language plpgsql;
?
create or replace function f_user_logout
(i_userid int,
OUT o_result int
)
as $BODY$
declare
begin
insert into user_logout_rec (userid,logout_time,ip) values (i_userid,now(),inet_client_addr());
update user_session set logouttime=now(),online_interval=online_interval+(now()-logintime) where userid=i_userid;
o_result := 0;
return;
exception
when others then
o_result := 1;
return;
end;
$BODY$
language plpgsql;
pgbench测试脚本login
\set userid random(1,20000000)
select userid,engname,cnname,occupation,birthday,signname,email,qq from user_info where userid=:userid;
insert into user_login_rec (userid,login_time,ip) values (:userid,now(),inet_client_addr());
update user_session set logintime=now(),login_count=login_count+1 where userid=:userid;
pgbench测试脚本logout
\set userid random(1,20000000)
insert into user_logout_rec (userid,logout_time,ip) values (:userid,now(),inet_client_addr());
update user_session set logouttime=now(),online_interval=online_interval+(now()-logintime) where userid=:userid;
测试command
# client 8 threads 8 time 180s vacuum before test
pgbench -M simple -r -c 8 -f ./login.sql -j 8 -n -T 180 -P 1 -v etest > /tmp/pb_login_j8_0.log 2>&1
测试结果:312
transaction type: ./login.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
duration: 180 s
number of transactions actually processed: 56364
latency average = 25.582 ms
latency stddev = 56.738 ms
tps = 312.545965 (including connections establishing)
tps = 312.550425 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.002 \set userid random(1,20000000)
0.209 select userid,engname,cnname,occupation,birthday,signname,email,qq from user_info where userid=:userid;
12.635 insert into user_login_rec (userid,login_time,ip) values (:userid,now(),inet_client_addr());
12.737 update user_session set logintime=now(),login_count=login_count+1 where userid=:userid;
优化阶段[1] - 开启异步提交
瓶颈分析
测试发现IO瓶颈比较明显
iostat sdb -x 1 10
?
avg-cpu: %user %nice %system %iowait %steal %idle
0.16 0.00 0.11 0.73 0.00 99.00
?
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sdb 0.00 873.00 0.00 678.00 0.00 13256.00 19.55 48.62 87.26 1.47 99.60
?
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
?
备注:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
优化
sed -ir "s/#*synchronous_commit.*/synchronous_commit = off/" /home/mingjie.gmj/databases/data/pgdata8410/postgresql.conf
?
pg_ctl restart -m fast
psql -c 'show synchronous_commit'
synchronous_commit
--------------------
off
测试
pgbench -M simple -r -c 8 -f ./login.sql -j 8 -n -T 180 -P 1 -v etest > /tmp/pb_login_j8_1.log 2>&1
测试结果:717
transaction type: ./login.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
duration: 180 s
number of transactions actually processed: 132335
latency average = 11.151 ms
latency stddev = 267.181 ms
tps = 717.392391 (including connections establishing)
tps = 717.402489 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.002 \set userid random(1,20000000)
0.224 select userid,engname,cnname,occupation,birthday,signname,email,qq from user_info where userid=:userid;
5.579 insert into user_login_rec (userid,login_time,ip) values (:userid,now(),inet_client_addr());
4.950 update user_session set logintime=now(),login_count=login_count+1 where userid=:userid;
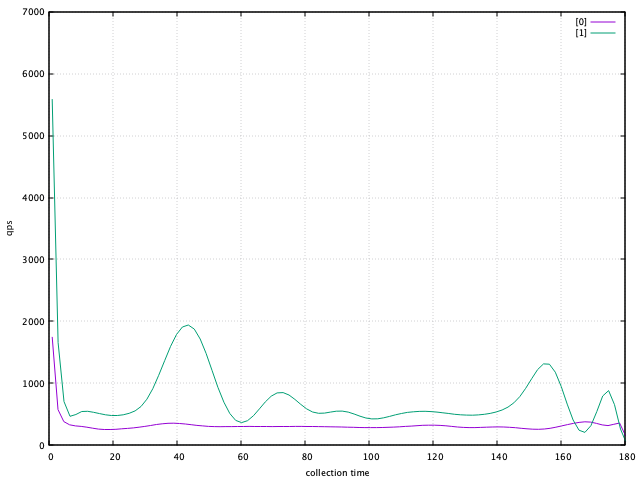
对比[1] —> [0]
set grid
set xlabel "collection time"
set xrange[0:180]
set ylabel "qps"
plot "pb_login_j8_0.log" using 2:4 w l lc 1 lw 1 title "[0]" smooth sbezier,\
"pb_login_j8_1.log" using 2:4 w l lc 2 lw 1 title "[1]" smooth sbezier
优化阶段[2] - 使用extended协议
瓶颈分析
-
simple协议:一个简单查询周期是由前端发送一条Query消息给后端进行初始化的。这条消息包含一个用 文本字符串表达的 SQL 命令(或者一些命令)。 后端根据查询命令串的内容发送一条或者 更多条响应消息给前端,并且最后是一条ReadyForQuery响应消息。ReadyForQuery通知前端 它可以安全地发送新命令了。
-
扩展查询:扩展查询协议把上面描述的简单协议分裂成若干个步骤。准备步骤的结果可以被多次复用以 提高效率。另外,还可以获得额外的特性, 比如可以把数据值作为独立的参数提供而不是必 须把它们直接插入一个查询字符串。
优化
extended协议
测试
pgbench -M extended -r -c 8 -f ./login.sql -j 8 -n -T 180 -P 1 -v etest > /tmp/pb_login_j8_2.log 2>&1
测试结果:846
transaction type: ./login.sql
scaling factor: 1
query mode: extended
number of clients: 8
number of threads: 8
duration: 180 s
number of transactions actually processed: 152398
latency average = 9.452 ms
latency stddev = 241.005 ms
tps = 846.397999 (including connections establishing)
tps = 846.410210 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.001 \set userid random(1,20000000)
0.226 select userid,engname,cnname,occupation,birthday,signname,email,qq from user_info where userid=:userid;
4.800 insert into user_login_rec (userid,login_time,ip) values (:userid,now(),inet_client_addr());
4.135 update user_session set logintime=now(),login_count=login_count+1 where userid=:userid;
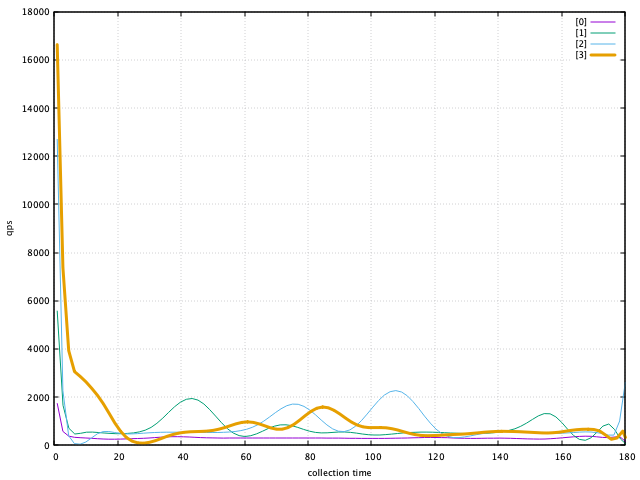
对比
set grid
set xlabel "collection time"
set xrange[0:180]
set ylabel "qps"
plot "pb_login_j8_0.log" using 2:4 w l lc 1 lw 1 title "[0]" smooth sbezier,\
"pb_login_j8_1.log" using 2:4 w l lc 2 lw 1 title "[1]" smooth sbezier,\
"pb_login_j8_2.log" using 2:4 w l lc 3 lw 3 title "[2]" smooth sbezier

优化阶段[3] - 使用prepared协议
http://www.postgres.cn/docs/10/protocol-flow.html#PROTOCOL-FLOW-EXT-QUERY
测试
pgbench -M prepared -r -c 8 -f ./login.sql -j 8 -n -T 180 -P 1 -v etest > /tmp/pb_login_j8_3.log 2>&1
测试结果:932
transaction type: ./login.sql
scaling factor: 1
query mode: prepared
number of clients: 8
number of threads: 8
duration: 180 s
number of transactions actually processed: 169299
latency average = 8.581 ms
latency stddev = 232.825 ms
tps = 932.300127 (including connections establishing)
tps = 932.313787 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.001 \set userid random(1,20000000)
0.132 select userid,engname,cnname,occupation,birthday,signname,email,qq from user_info where userid=:userid;
4.407 insert into user_login_rec (userid,login_time,ip) values (:userid,now(),inet_client_addr());
3.754 update user_session set logintime=now(),login_count=login_count+1 where userid=:userid;
对比
set grid
set xlabel "collection time"
set xrange[0:180]
set ylabel "qps"
plot "pb_login_j8_0.log" using 2:4 w l lc 1 lw 1 title "[0]" smooth sbezier,\
"pb_login_j8_1.log" using 2:4 w l lc 2 lw 1 title "[1]" smooth sbezier,\
"pb_login_j8_2.log" using 2:4 w l lc 3 lw 1 title "[2]" smooth sbezier,\
"pb_login_j8_3.log" using 2:4 w l lc 4 lw 3 title "[3]" smooth sbezier
优化阶段[4] - 使用函数
http://www.postgres.cn/docs/10/protocol-flow.html#idp57579680
优化
loginfunc.sql
\set userid random(1,20000000)
SELECT f_user_login(:userid);
测试
pgbench -M prepared -r -c 8 -f ./loginfunc.sql -j 8 -n -T 180 -P 1 -v etest > /tmp/pb_login_j8_4.log 2>&1
测试结果:987
transaction type: ./loginfunc.sql
scaling factor: 1
query mode: prepared
number of clients: 8
number of threads: 8
duration: 180 s
number of transactions actually processed: 182872
latency average = 8.100 ms
latency stddev = 230.179 ms
tps = 987.645074 (including connections establishing)
tps = 987.658690 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.001 \set userid random(1,20000000)
7.750 SELECT f_user_login(:userid);
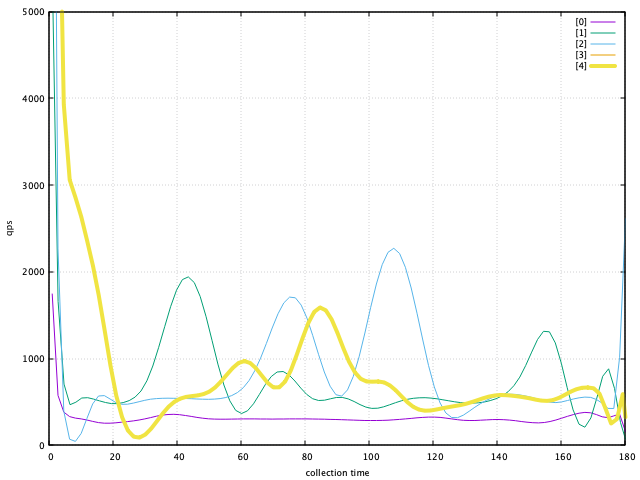
对比
set grid
set xlabel "collection time"
set xrange[0:180]
set ylabel "qps"
set yrange[0:5000]
plot "pb_login_j8_0.log" using 2:4 w l lc 1 lw 1 title "[0]" smooth sbezier,\
"pb_login_j8_1.log" using 2:4 w l lc 2 lw 1 title "[1]" smooth sbezier,\
"pb_login_j8_2.log" using 2:4 w l lc 3 lw 1 title "[2]" smooth sbezier,\
"pb_login_j8_3.log" using 2:4 w l lc 4 lw 1 title "[3]" smooth sbezier,\
"pb_login_j8_3.log" using 2:4 w l lc 5 lw 4 title "[4]" smooth sbezier
总结
-
使用SSD
-
异步提交
-
增加并发,经验值当活跃的进程数等于核数的2倍时可以发挥CPU的最大能力
-
批次提交
-
关闭pg_log
-
使用prepared协议
-
使用函数封装业务逻辑
-
COPY
-
拆表
-
hotstandby读写分离
-
分区表(主表并发有性能问题)PG11后可用或者使用PGPATHMAN -
连接池:短连接大量并发

